






AI的广泛可用特性,也引发软件研发团队思考,如何使用这一工具更好更快的完成日常工作。这里对AI在软件测试过程中所能起到的作用做了一个调研。
软件测试是软件交付质量保障的重要手段。测试行业对软件测试中的效率和质量提升保持长期的关注,总结出了各种理论和实践方案,以应对外部对测试的期望和挑战。随着人工智能的发展,尤其是大模型的广泛应用,使得软件测试又多了一种方法来更好应对这些期望和挑战。因此探索AI能力对软件测试的提升就很有必要。
测试当前面对哪些挑战,测试内部和外部分别有什么期盼和痛点。
AI在应对这些挑战时能发挥什么作用
在具体场景的选择上如何去思考,有哪些方式去使用AI,以通用的场景去思考。
不同的场景,需求满足的条件是什么,AI能力需要达到什么程度。
实际使用AI去做一个场景,看看效果。
思考当前公司的AI策略,结合实际思考落地方式,同时参考外部公司的AI测试落地方式
具体的选择上,如何去做,使用什么模型,使用什么ai能力,会有什么样子的效果,挑战是什么,满足什么条件,风险是什么,可行性是多少,当前可以做哪些内容。落地结果怎么去看。成熟的外部厂商有没有,自建还是引用。
动态去看AI能力,当前AI发展。
测试团队对AI的接受程度,研发团队对AI的接受程度。
软件测试应对的挑战
在需求实现过程中,软件的测试人员对需求质量负责是大家的共识。要保证软件的高质量,就需要测试覆盖全面、测试结果可靠。同时团队也希望测试效率尽可能的高,能快速给出测试结果。
外部挑战
- 测试覆盖全面
- 测试结果可靠
外部期望
- 测试效率尽可能高
对测试人员来说,软件系统复杂程度、测试人员自身经验、需求文档澄清程度,这三个因素都会影响测试覆盖全面、测试结果准确。而面对测试效率提升,除了测试人员自身提升能力,通常的做法是借助自动化测试工具来实现。
应对外部挑战的影响因素
- 软件系统复杂程度
- 测试人员自身经验
- 需求文档澄清程度
应对外部期望的方法
- 自动化测试工具
面对挑战的实施策略
要做好对挑战的应当,就要思考每个影响因素。软件系统复杂程度是由业务决定,而需求文档澄清程度是由产品人员决定。前者客观存在几乎无法改变,而后者需要通过规范去约束,都不在测试本身工作范围内。测试人员自身经验同样无法短时间内提高,为了弥补差异,同时更好的协助测试工作,需要借助一些辅助工具来实现,例如在用例写作阶段借助团队力量做用例交叉评审,在测试回归阶段使用自动化工具等等,这里我们同样可以借助AI的能力提升测试的效率和质量。
面对外部期望的效率提升,自动化测试工具是很重要的手段,在此基础上加入AI能力,能进一步提升效率。例如在写作接口自动化用例时借助AI来实现用例自动生成。
可以看到AI能力在测试工作的多个环节都可以介入,考虑到测试工作有很多具体工作,这里尝试从一个一般的测试流程中去思考,AI可以在哪些方面带来收益。
AI在测试工作中应用探索
这里要先说明,这里是一个探索性的内容,实际在测试工作的某个环节是否适合使用AI能力还需要仔细讨论。那么我们首先需要了解当前AI大模型本身的能力。
大模型( Large Language Model,LLM)简介
大模型是指具有大规模参数和复杂计算结构的机器学习模型。本质上是一个使用海量数据训练而成的深度神经网络模型,拥有数十亿甚至数千亿个参数,其巨大的数据和参数规模,实现了智能的涌现展现出类似人类的智能。
大模型能力
- 生成(Generate) :这是LLM最核心的能力之一。LLM能够根据用户的提示生成连贯且原始的文本内容,这使得它在对话式人工智能、聊天机器人和代码助手等应用中非常有用。
- 总结(Summarize) :LLM可以生成摘要,包括抽象摘要和提取摘要。抽象摘要是新颖的文本,代表较长内容中的信息;提取摘要则是从相关事实中提取简洁的内容。
- 提取(Extract) :LLM能够从大量文本中提取关键信息,这对于信息检索和数据提取任务非常有效。
- 分类(Classify) :LLM可以执行文本分类任务,如情感分析和主题分类,这在机器学习和自然语言处理(NLP)任务中非常常见。
- 检索(Search) :LLM可以利用外部工具进行信息检索,以补充其知识库并提高任务完成的准确性。
- 改写(Rewrite) :LLM能够对文本进行改写,以适应不同的风格或格式。
- 推理与决策:LLM具备强大的上下文推理能力,能够理解复杂文本并进行逻辑推理。这种能力使其能够在法律分析、市场研究和科学发现等知识密集型任务中提供支持。
- 多语言能力:LLM能够理解和生成多种语言的内容,适应不同方言和社会用语的需求。
- 自适应学习与进化:LLM能够吸收新信息、分析数据中的新模式,并相应地调整其响应或行为。
- 工具使用:LLM可以有效利用各种工具,如API、计算器和搜索引擎,以增强其功能并提高特定任务的表现。
大模型分类
按照输入数据的不同,分为下面三种类型。
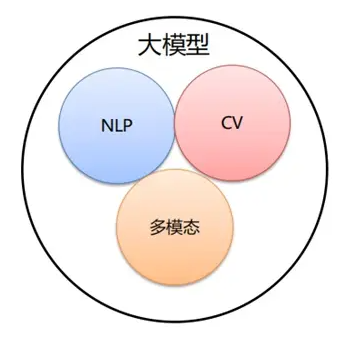
语言大模型(NLP)
语言大模型(NLP)是指在自然语言处理(Natural Language Processing,NLP)领域中的一类大模型,通常用于处理文本数据和理解自然语言。这类大模型的主要特点是它们在大规模语料库上进行了训练,以学习自然语言的各种语法、语义和语境规则。
视觉大模型(CV)
视觉大模型(CV):是指在计算机视觉(Computer Vision,CV)领域中使用的大模型,通常用于图像处理和分析。这类模型通过在大规模图像数据上进行训练,可以实现各种视觉任务,如图像分类、目标检测、图像分割2 、姿态估计、人脸识别等。例如:VIT 系列(Google)、Midjourney、DALL·E 3。
多模态大模型(MLLM)
多模态大模型(Multimodal Large Language Models, MLLM):是指能够处理多种不同类型数据的大模型,例如文本、图像、音频等多模态数据。这类模型结合了 NLP 和 CV 的能力,以实现对多模态信息的综合理解和分析,从而能够更全面地理解和处理复杂的数据。

大模型应用
围绕大模型能力,当前消费级应用有如下内容,借助的是大模型的语言理解、文字生成、信息提取、工具使用等能力。参考web的AI网站集合。
测试工作流中AI使用探索
这里从整个测试工作流去看哪些环节可以使用AI去实现,在AI可以参与的环节中,去看AI能做哪些具体的事情。之后去看AI能做到什么程度,对应需要满足的条件,投入是多少,收益如何,存在什么风险。
测试工作流
考虑一般常规的工作流程,从需求评审开始,要完成的工作内容如下:制定测试计划、写作测试用例、测试用例评审、测试执行(功能测试、专项测试)、缺陷提交及验证、输出测试报告。
1. 制定测试计划
在需求澄清之后,测试人员根据需求内容的影响范围、业务访问量大小、服务器资源信息,确定测试覆盖的边界及所需的资源,判断是否需要展开专项测试,最后制定测试方案。经过团队评审后作为后续测试工作的指导。AI的作用在这里是产出测试计划。
场景
制定测试计划,给出信息如下:1、当前需求上线依赖A,B两个系统,A系统还开发过程中,会在迭代截止前最后一天才能发布给到生产环境;2、此次需求会影响到C、D系统;3、当前系统比较卡顿,需求上线后日访问量在50万左右,需要优化服务器性能,满足web访问的顺畅体验。
投入
项目和系统信息的输入。了解到所有信息,包括系统间依赖关系, 当前迭代各相关系统发布时间节点,系统的服务架构依赖,服务器资源及资源使用情况,线上业务的预期访问量,用户访问web端的顺畅访问响应值。
收益
- 一份电子文档,字数在500左右,包含方案、流程、风险等
- 节省整理和写作时间2小时左右
风险
- 计划需要具体的项目和服务配置信息,存在信息泄露风险
- 原本的计划制定人员对系统和项目的了解程度相对减弱,对后续测试不利
评价
- 整体是在思维层上考虑,缺少实际操作的指导。例如针对日访问50万场景,需要知道峰值,访问卡顿要排查卡顿点在那里做针对性测试,测试人员要做什么事情,没有具体的做法。另外依赖系统交付很晚导致的延期风险,是否考虑资源协调方案,合作测试,也未给出解决方案。
- 对AI产出的测试计划,可以隐去公司敏感信息,给出核心的问题,参考的其思路方向,弥补制定计划时考虑不全的地方,作为思考辅助。
思考
测试计划制定一般在较为复杂或者涉及系统较多的需求时进行制定,迭代中发生的频率不高,而给与AI大模型的信息都比较敏感,风险较高,实际的产出可以作为思考方向遗漏的参考,但在计划评审时完全可解决这部分问题。
使用AI制定测试计划当前收益较小,且存在较大风险,暂不考虑。
2. 编写测试用例
测试用例编写实际上是将需求转化为具体验证点的关键过程,是需求澄清程度和测试人员经验多少的叠加结果,需要测试人员花费整个测试中1/3左右的时间,并指导后续测试执行,决定测试质量的好坏,因此非常关键。这里AI可以发挥很重要的作用。
场景-功能测试(详细PRD)
内容如下

场景-功能测试(粗略PRD)
当前需要实现一个注册登录的场景,注册需要使用合法手机号,手机验证码5分钟发送一次。重发验证码需要做校验。
场景-功能测试(实际业务PRD)
业务系统 3.1部分
场景-接口测试
考虑到接口是涉及到公司的敏感信息,因此使用废弃接口做验证。
url:ke.com/apifile-center/o-file/upload
post请求,body体是form-data参数数据 guid:ofw1323 fileInfoList[0].file:文件路径 多个文件fileInfoList[0].file中的0改成1、2、3等正整数。你作为测试专家现在做接口逻辑验证,如何去做
场景-UI测试
ui的测试验证需要在实际的web端操作,当前通用问答式通用AI,暂不支持,通过截图等手段操作,并不能节省工作量,因此暂不考虑。
场景-思维导图
根据文字、图片生产思维导图,辅助测试执行。
总结
- 大模型有用例写作思路,可以输出覆盖主要流程的测试用例,并具有可执行性
- 但只有豆包等部分大模型可满足需要,其他大模型输出效果不佳
- 实际业务prd中截图等内容,大模型识别不够全面,因此逻辑上需要人工干预
- 输出的结果以文字形式呈现,需要进一步整理到用例系统中,补充细节才能使用
3. 测试执行
系统的测试验证AI在当前使用通用AI的情况不能满足,需要专门的一套本地化AI系统。包括功能测试用例执行,触发接口、UI自动化测试。
4. 缺陷跟踪
缺陷提交、修复、验证工作中有很多沟通的工作,同时需要能操作当前系统。因此AI暂时不能参与。
5. 编写测试报告
测试完成后,需要总结测试用例执行情况,缺陷情况,并给出风险提示。数据统计由用例平台可以完成,而风险提示内容需要沟通确认。这里AI发挥的作用有限,且收益不高。
研发流程
为了使大模型在实际项目中的测试应用更加完整,将代码整合到一个持续集成(CI)/持续交付(CD)管道中,以及如何处理和报告测试结果。这将确保我们的测试过程高效、自动化。考虑在研发几个流程阶段去看AI的使用。
需求阶段
需求的的文档编写消耗大量时间,部分编写工作可以由AI去完成,生产详细文档,在生成文档基础上做调整。
研发阶段
代码编写中使用AI做代码语法检查、代码修复、代码分析等。
测试阶段
使用AI阅读需求生成测试用例,提升测试场景覆盖。
发布阶段
发布过程中,交付物上线为主,此时考虑在运维端使用AI做异常信息定位并给修复建议,节省异常修复时间。
外部公司软件测试AI使用调研
使用场景

使用反馈
先抛砖引玉下,我们团队今年在 AI 方面主要的实践方向、挑战和基本成果如下:
1.功能用例生成
方案:基于产品需求和 prompt 生成功能用例(相关功能已集成到用例管理平台)
困难:
1).需求本身的质量(一句话需求、碎片化需求)
2).PRD 文档形式各异(原型图中标注、简单的截图标注等,需要 QA 人为转换为文本才能生成用例)
效果:
1).相对通用的需求(业务领域相关性弱),用例生成质量尚可
2).整体收益看鉴于需求本身的质量、即便提供了业务知识库的情况,效率和效果也谈不上有提升
2.接口自动化用例生成
方案:基于接口文档 + 接口框架知识库 +prompt 示例
效果:
1)接口文档规范性足够好的话,仿写的效果还是可以的
2)整体收益看,在有大量接口需要生成用例模版的背景下,效率上还是有所提升的
困难:
1.生成的用例数据部分仍需要手工替换(对于业务数据的依赖,这点 AI 似乎无能为力)
3.代码扫描
方案:针对历史线上问题,梳理出研发易犯错的代码问题,形成检查规则(同时会搭配开源扫描工具使用),集成到流水线结合代码 DIFF 和大模型对代码进行 check
效果:
1).成本低,收益还是可以的(目前主要应用在 C++ 项目上)
困难:
1).增量代码往往缺少上下文,会导致出现漏检的情况
2).生成的报告每次需要人工 check 排除干扰
4.测试报告生成
方案:
1).重点让 AI 基于 BUG 数据进行数据分析,给出风险提示和分析结果
效果:
1).由于给 AI 提供的信息有限,生成的结论比较泛,仍需要加入人为的分析结论
5.其它还有 AI 需求分析、需求评审、数据库表设计评审等
软件测试中使用AI工具面对的挑战
AI测试工具在软件测试中虽然具有显著的潜力,但也面临诸多挑战。
- 数据依赖性:AI模型的有效性很大程度上取决于训练数据的质量和数量。如果数据不准确或带有偏见,可能导致测试结果的质量低下,从而偏离项目目标。此外,获取高质量的训练数据可能非常困难且耗时。
- 模型适应性:AI模型需要适应不同类型的软件和多样化的测试场景。这要求处理复杂且不可预测的测试情况,同时确保模型能够适应数据分布的变化以保持有效性。
- 可解释性和透明度:深度学习算法往往难以解释其决策过程,这使得测试人员难以理解AI是如何生成测试用例和脚本的,也导致测试结果难以验证和复现。此外,AI系统的学习和决策过程通常难以解释,这增加了测试的复杂性。
- 隐私和安全问题:在生成测试案例和错误识别时,需要使用敏感数据,隐私和安全是一个现实问题。
- 计算资源需求:AI模型的训练和运行需要大量的计算资源,这可能限制了其在资源受限环境中的应用。
- 团队适应性:将AI引入现有的测试流程可能会遇到团队成员的抵制,他们可能更习惯于传统的测试方法。适当的培训、教育和展示AI的价值可以帮助缓解这一过渡期。
- 测试策略调整:整合AI需要从传统的测试方法转向新的方法,这要求QA团队具备灵活性与适应性。
- 复杂性和不确定性:AI系统的复杂性、不确定性和动态性使得测试更加困难。例如,AI系统可能具有概率性或与结果相关的不确定性,这使得定义预期结果变得更加困难。
- 法律和伦理问题:由于AI模型训练需要大量的数据,因此涉及伦理和法律问题。测试工程师在评估AI系统质量、管理相关风险以及确保决策的可信度方面面临挑战。
尽管AI在软件测试中带来了许多优势,如提高测试效率和准确性,但其实施过程中仍需克服上述挑战。通过系统性的方法和适当的策略,可以逐步克服这些挑战,从而更好地利用AI技术提升软件测试的质量和效率。
参考链接
【AI大模型】在测试中的深度应用与实践案例_ai大模型在测试中的应用-优快云博客
什么是大模型(LLMs)?一文读懂大型语言模型(Large Language Models)的基本概念 | AIGC工具导航


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









