







 这篇博客介绍了YOLO系列的发展,从YOLOv1到YOLOv3的优化方法,包括DarkNet53网络结构、多尺度预测和 Anchor 的设计。YOLOv3通过多尺度输出提升了小物体检测精度,同时保持了较高的推理速度,适合实时应用。在PaddleDetection中,YOLOv3模型的一键式训练、预测和评估功能也得到了详细阐述。
这篇博客介绍了YOLO系列的发展,从YOLOv1到YOLOv3的优化方法,包括DarkNet53网络结构、多尺度预测和 Anchor 的设计。YOLOv3通过多尺度输出提升了小物体检测精度,同时保持了较高的推理速度,适合实时应用。在PaddleDetection中,YOLOv3模型的一键式训练、预测和评估功能也得到了详细阐述。
单阶段YOLO系列模型:
一、YOLO发展史
单阶段模型:YOLO, SSD, Retina-Net
两阶段模型:RCNN, SPPNet
yolo系列:精度并不是最高的,但推理运行速度高
FPS:帧/s
精度、速度性价比高
1、YOLOv1
将目标检测当作一个单一的回归任务
-
将图片分成s*s个网格
-
物体中心点落在哪个网格上,就由该网格对应锚框负责检测该物体
2、YOLOv2
-
优化方法
骨干网络:224*224 -> 448 *448 ,DarkNet19
全卷积网络结构:Conv+Batch Norm
Kmeans聚类Anchor
多尺度训练
-
优化效果
推理速度由40FPS到67FPS
-
待改进点
小目标召回率不高
靠近的群体目标检测效果不好
检测精度需要进一步优化
3、YOLOv3
-
优化方法
骨干网络:DarkNet53
多尺度预测,跨尺度特征融合
COCO数据集聚类9种不同尺度的Anchor,每个尺度三个
-
优化效果
COCO数据集精度33.0
推理速度高于SSD 3倍
推理速度高于RetinaNet 3.8倍
-
待改进的点
召回率相对较低
定位精度优化
靠近群体目标检测效果差
整体网络构造:
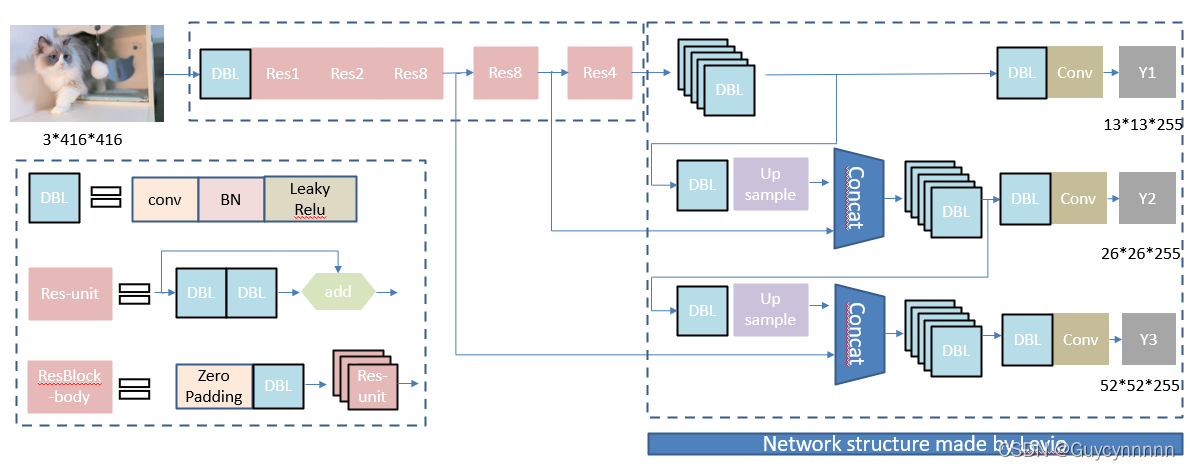
首先输入图片,然后Darknet53特征提取,其中经过五次下采样,还使用了残差结构,目的是使网络结构在很深的情况下,仍能收敛并继续训练下去。
然后经过DBL特征提取得到第一个尺度特征图:然后接着用DBL后特征图上采样后与倒数第二次下采样的结果相加,得到第二个尺度特征图; 最后的特征图上采样后与倒数第三次下采样的特征图相加得到第三个尺度的特征图;
总的来说会输出3个不同尺度的特征图,每个尺度的特征图负责预测不同大小的目标。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









