






160.相交链表 esay
思路
双指针
方法一:
遍历得到两链表的的长度
指针从长度相等的地方开始同时移动
指针相等时就是相交节点
方法二: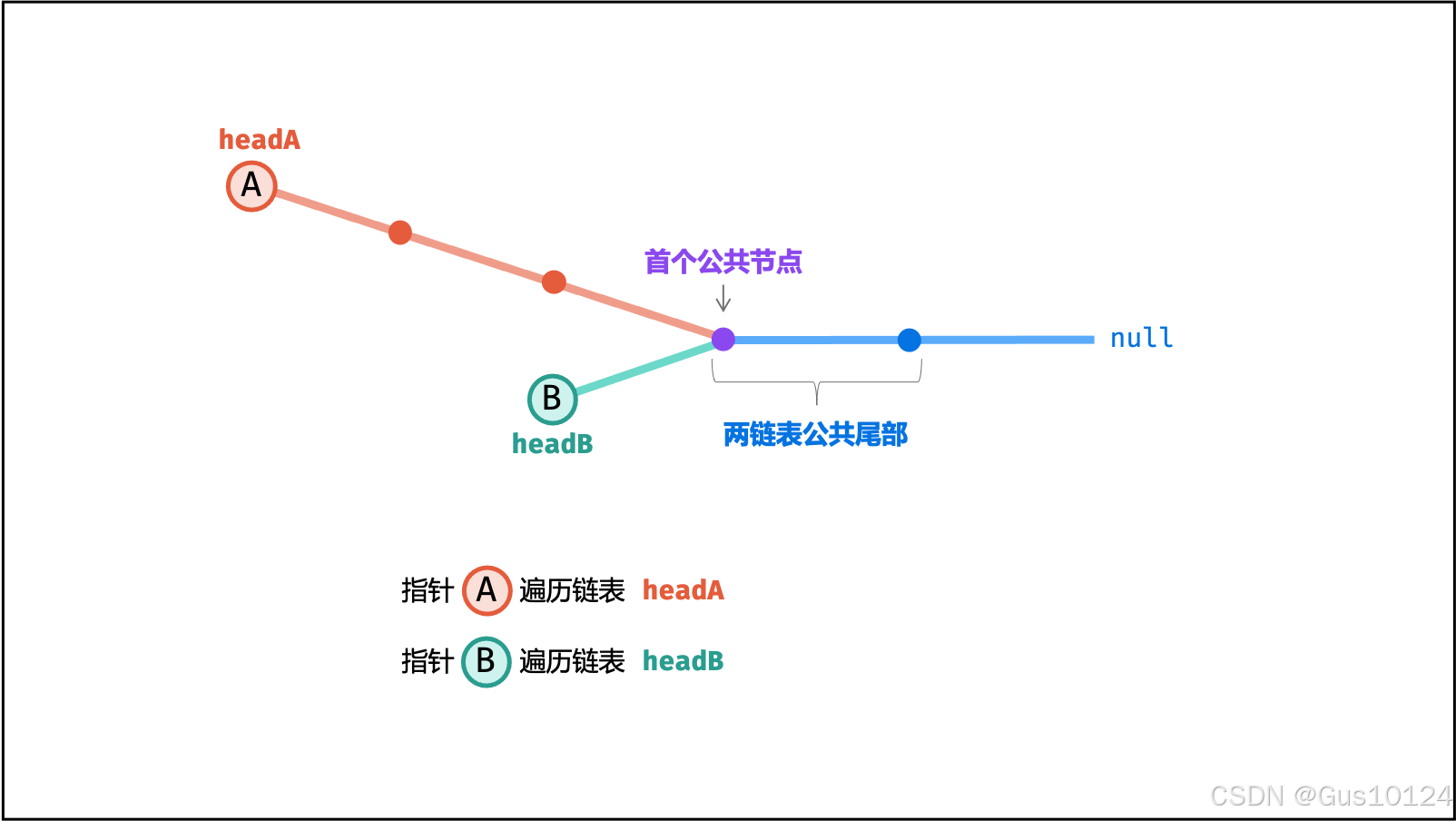

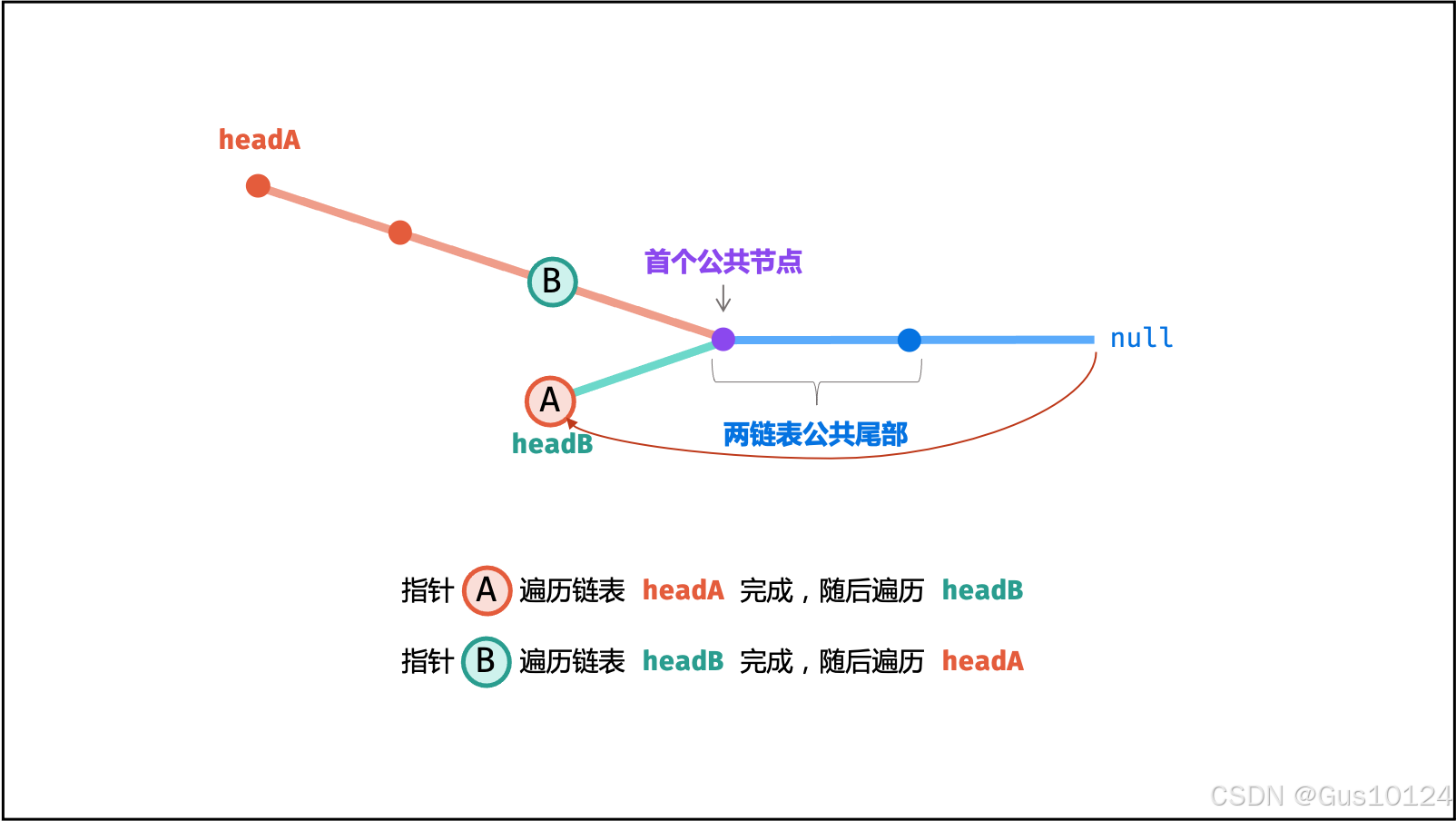
若两链表 有 公共尾部 (即 c>0 ) :指针 A , B 同时指向「第一个公共节点」node 。
若两链表 无 公共尾部 (即 c=0 ) :指针 A , B 同时指向 null 。
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
ListNode A = headA, B = headB;
while (A != B) {
A = A != null ? A.next : headB;
B = B != null ? B.next : headA;
}
return A;
}
}
作者:Krahets
链接:https://leetcode.cn/problems/intersection-of-two-linked-lists/solutions/12624/intersection-of-two-linked-lists-shuang-zhi-zhen-l/
来源:力扣(LeetCode)
206.反转链表 easy
方法一:迭代(双指针)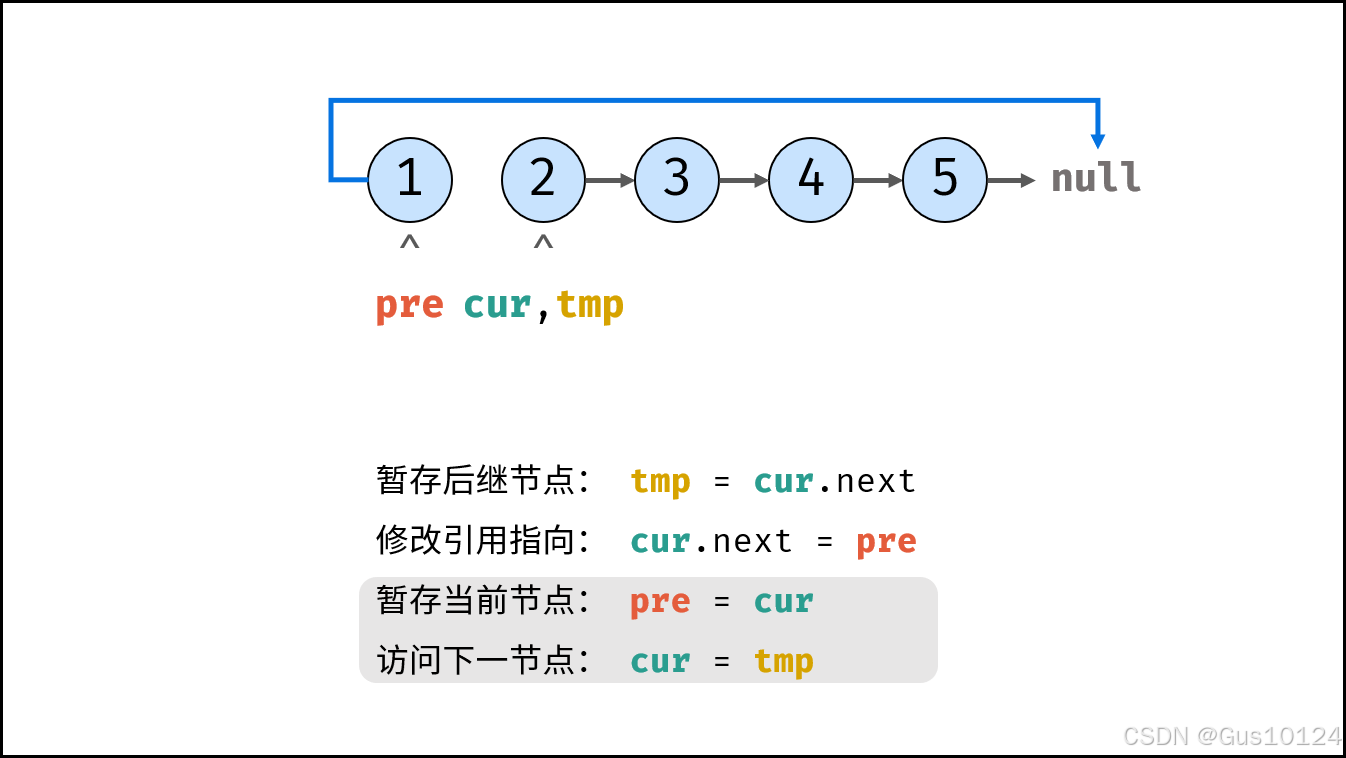
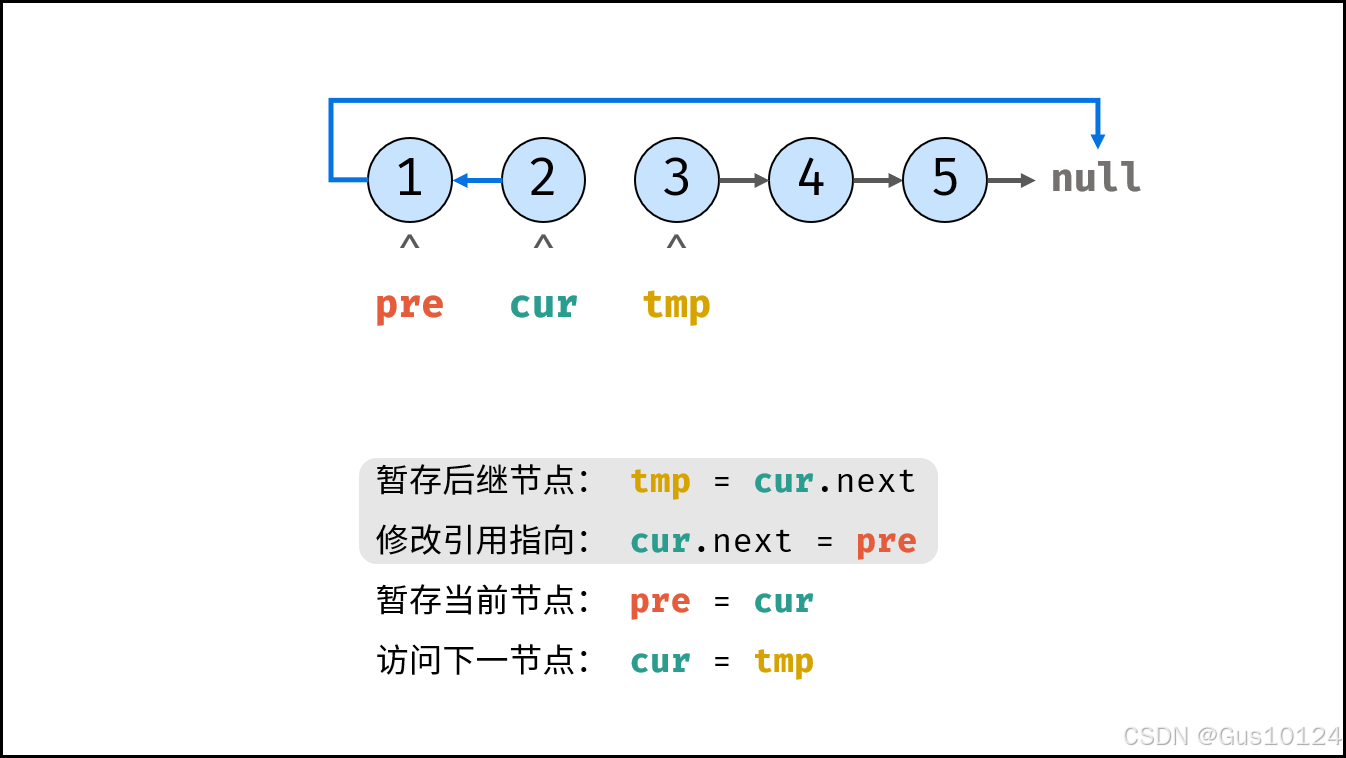
class Solution {
public ListNode reverseList(ListNode head) {
ListNode cur = head, pre = null;
while(cur != null) {
ListNode tmp = cur.next; // 暂存后继节点 cur.next
cur.next = pre; // 修改 next 引用指向
pre = cur; // pre 暂存 cur
cur = tmp; // cur 访问下一节点
}
return pre;
}
}
复杂度分析
- 时间复杂度 O(N) : 遍历链表使用线性大小时间。
- 空间复杂度 O(1) : 变量
pre和cur使用常数大小额外空间。
方法二:递归法
public ListNode reverseList(ListNode head) {
// 从头节点开始调用递归方法,前驱节点初始化为 null
return dfs(null, head);
}
// 定义递归方法 dfs
public ListNode dfs(ListNode pre, ListNode cur) {
// 基本情况:如果当前节点 cur 为 null,说明已经到达链表的末尾
if (cur == null) {
// 返回前驱节点 pre,作为新的头节点
return pre;
}
// 递归调用 dfs,当前节点 cur 作为前驱节点,cur.next 作为当前节点
ListNode res = dfs(cur, cur.next);
// 将当前节点 cur 的 next 指向前驱节点 pre,反转链表的一部分
cur.next = pre;
// 返回反转后的链表头
return res;
}
解析
-
反转链表的方法 (
reverseList):- 方法接收链表的头节点
head作为参数。 - 调用辅助的递归函数
dfs,并传入null作为前驱节点(因为反转时,头节点的next会指向null),以及传入当前节点head。
- 方法接收链表的头节点
-
辅助递归方法 (
dfs):- 参数:
pre:反转后的链表的前驱节点。cur:当前正在处理的节点。
- 基本情况:
- 当
cur为null时,表示递归到链表末尾,此时返回pre,即新的链表头。
- 当
- 递归调用:
- 递归调用
dfs方法,将当前节点cur作为新的前驱节点,将cur.next作为新的当前节点。
- 递归调用
- 反转操作:
- 在返回时,将当前节点
cur的next指向前驱节点pre,实现链表的反转。
- 在返回时,将当前节点
- 返回值:
- 返回反转后的链表头
res。
- 返回反转后的链表头
- 参数:
递归过程
通过递归的方式,该函数会遍历到链表的末尾,然后在返回时逐步将每个节点的 next 指向前一个节点,从而实现链表的反转。
时间复杂度为 O(n),空间复杂度为 O(n)(主要是由于递归调用栈的使用)。
关键点
- 尾递归:由于是递归处理,每个节点的
next在函数返回时都被反转。 - 链表反转:通过反向指向实现链表的反转,改变了节点的连接关系。
234.回文链表 easy
快慢指针,找到链表的中间,反转后半部分,然后对比
141.环形链表 easy
快慢指针,相遇说明有环
142.环形列表Ⅱ mid
快慢指针+数学证明
或者哈希
21.合并两个有序列表 easy
递归
- 终止条件:当两个链表都为空时,表示我们对链表已合并完成。
- 如何递归:我们判断
l1和l2头结点哪个更小,然后较小结点的next指针指向其余结点的合并结果。(调用递归)
public ListNode mergeTwoLists(ListNode list1, ListNode list2) {
if (list1 == null) return list2;
if (list2 == null) return list1;
if (list1.val < list2.val) {
list1.next = mergeTwoLists(list1.next, list2);
return list1;
} else {
list2.next = mergeTwoLists(list1, list2.next);
return list2;
}
}2. 两数相加 mid
-
结果链表初始化:
- 创建一个新的
ListNode对象res,用于存储结果链表的头节点。cur指针用于遍历和构建结果链表。
- 创建一个新的
-
进位初始化:
- 初始化
carry为 0,用于处理两个数字相加时可能产生的进位。
- 初始化
-
主循环:
- 当
l1或l2不为null时,持续进行循环。循环内部:- 获取当前节点的值,如果节点为空,则值为 0。
- 计算当前位的和,并考虑进位。
- 更新进位
carry和当前节点的值cur.val。 - 更新指针
l1和l2指向下一个节点(如果它们不为空)。 - 如果
l1或l2还有剩余节点,则创建一个新的ListNode作为cur.next,并移动cur指针。
- 当
-
处理剩余进位:
- 在循环结束后,如果
carry仍为 1,则在结果链表末尾添加一个新节点。
- 在循环结束后,如果
public ListNode addTwoNumbers(ListNode l1, ListNode l2) { // 创建一个新的 ListNode 作为结果链表的头节点 ListNode res = new ListNode(); // cur 是一个指针,初始化为结果链表的头节点 ListNode cur = res; // carry 用于保存进位,初始为 0 int carry = 0; // 遍历 l1 和 l2,直到两个链表都遍历完 while (l1 != null || l2 != null) { // 如果 l1 当前节点不为空,则取其值;否则取 0 int n1 = l1 != null ? l1.val : 0; // 如果 l2 当前节点不为空,则取其值;否则取 0 int n2 = l2 != null ? l2.val : 0; // 计算当前位的和,加上进位 cur.val = n1 + n2 + carry; // 更新进位 carry = cur.val / 10; // 更新当前节点的值为和的个位数 cur.val %= 10; // 移动到下一个节点,如果 l1 当前节点不为空 if (l1 != null) { l1 = l1.next; } // 移动到下一个节点,如果 l2 当前节点不为空 if (l2 != null) { l2 = l2.next; } // 如果还有剩余节点(l1 或 l2 不为空),则创建新的节点并移动 cur 指针 if (l1 != null || l2 != null) { cur.next = new ListNode(); // 创建一个新的节点 cur = cur.next; // 移动 cur 指针到新创建的节点 } } // 如果最后还有进位,则在结果链表末尾添加一个新节点 if (carry == 1) { cur.next = new ListNode(1); } // 返回结果链表的头节点(跳过初始的空节点) return res; }
19. 删除链表的倒数第N个结点 mid
快慢指针
让 快指针 领先 慢指针 n + 1 个结点
当 fast 到达链表末尾时,slow 就是待删除节点的前一个节点
注意特殊情况:删除的为第一个节点
设置哨兵结点,是关键
24.两两交换链表中的结点 mid
递归
25. K个一组翻转链表 hard
思路
- 每次翻转前,要确定翻转链表的范围,这个必须通过
k此循环来确定 - 需记录翻转链表前驱和后继,方便翻转完成后把已翻转部分和未翻转部分连接起来
- 初始需要两个变量
pre和end,pre代表待翻转链表的前驱,end代表待翻转链表的末尾 - 经过k此循环,
end到达末尾,记录待翻转链表的后继next = end.next

翻转链表,然后将三部分链表连接起来,然后重置 pre 和 end 指针,然后进入下一次循环
特殊情况,当翻转部分长度不足 k 时,在定位 end 完成后,end==null,已经到达末尾,说明题目已完成,直接返回即可
复杂度分析
- 时间复杂度为 O(n∗K) 最好的情况为 O(n) 最差的情况未 O(n2)
- 空间复杂度为 O(1) 除了几个必须的节点指针外,没有占用其他空间
作者:房建斌学算法
链接:https://leetcode.cn/problems/reverse-nodes-in-k-group/solutions/10416/tu-jie-kge-yi-zu-fan-zhuan-lian-biao-by-user7208t/
来源:力扣(LeetCode)
138.随机链表的复制 mid
借助 HashMap
第一次遍历 建立 “原节点 -> 新节点” 的 Map 映射
第二次遍历 构建新链表的 next 和 random 指向
148.排序链表 mid
自底向上的归并排序,复杂的很
23.合并 K 个升序链表 hard
方法一:分治,归并排序
public ListNode mergeKLists(ListNode[] lists) {
int i = 0;
int j = lists.length;
return mergeKList(lists, i, j);// 左闭右开区间
}
// 分治法合并链表
public ListNode mergeKList(ListNode[] lists, int i, int j) {
int m = j - i; // 计算当前处理的链表数量
if (m == 0) {
return null; // 如果没有链表,返回 null
}
if (m == 1) {
return lists[i]; // 如果只有一个链表,直接返回该链表
}
// 递归分治,合并左半部分链表
ListNode left = mergeKList(lists, i, i + m / 2);
// 递归分治,合并右半部分链表
ListNode right = mergeKList(lists, i + m / 2, j);
// 合并左右两部分的链表并返回结果
return mergeTwoKLists(left, right);
}方法二:优先队列
详细解释
-
优先队列的初始化:
PriorityQueue<ListNode> pq = new PriorityQueue<>((a, b) -> a.val - b.val);- 使用
PriorityQueue来存储链表的节点,构造时通过比较节点的值(a.val - b.val)来维护小根堆的性质,以便每次都能快速获取最小的节点。
- 使用
-
将非空节点加入优先队列:
for (ListNode node : lists) { if (node != null) pq.offer(node); }- 遍历所有输入的链表头节点,如果节点不为空,则将其加入优先队列。
-
使用虚拟头节点简化合并操作:
ListNode dummy = new ListNode(); ListNode cur = dummy;- 创建一个虚拟头节点
dummy。cur指针用来构建新的合并链表,最开始指向dummy。
- 创建一个虚拟头节点
-
合并链表:
while (!pq.isEmpty()) { ListNode node = pq.poll(); cur.next = node; if (node.next != null) { pq.offer(node.next); } cur = cur.next; }- 当优先队列不为空时,不断从中提取出最小节点
node,并将其连接到合并链表的尾部。 - 如果
node还有下一个节点,则将其下一个节点加入优先队列。
- 当优先队列不为空时,不断从中提取出最小节点
-
返回合并后的链表
时间复杂度为 O(N log k),其中 N 是所有链表中节点的总数,而 k 是链表的数量。这是因为每个节点最多会被加入和移除优先队列一次,因此处理 N 个节点的总时间与优先队列的操作(大小为 k)成正比。使用优先队列使得在合并过程中能够始终保持节点的有序性。
146.LRU 缓存 mid
需要的数据结构
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行
查找借助HashMap
删除移动操作使用双向链表

















 765
765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









