 MDAP:跨域推荐多视图偏好学习框架
MDAP:跨域推荐多视图偏好学习框架





MDAP:A Multi-view Disentangled and Adaptive Preference Learning Framework for Cross-Domain Recommendation
解决的问题
1 偏好异质性(preference heterogeneity):主要挑战。不同领域中的用户行为可能由不同的潜在偏好驱动。例如,用户可能在阅读小说时优先考虑类型,但在选择电影时首先考虑导演。这些偏好特征通常纠缠在一个域中,使得很难将行为从一个域推广到另一个域。在CDR中,解决这种偏好异质性对于更准确地捕获不同领域的用户偏好至关重要。【这是CDR专有的挑战】
2 特征空间差异:不同的领域可能具有显著不同的特征空间,使得直接迁移学习不太有效,并可能导致负迁移。
本文解决了偏好异质性:解耦和选择多视图用户的喜好,以减轻负转移,捕捉不同的用户偏好跨域与多视图编码器。
本文使用多视图编码器:使用Gumbel-Softmax技术,让编码器生成多个软分配矩阵,捕捉用户偏好的各方面,提高系统的适应性。
本文设计了特定于领域的门控机制:自适应地组合来自不同视图的嵌入,确保有效的解耦和转却的推荐匹配。
本文实施了知识迁移并进行了实验验证:通过跨域共享编码器和解码器实现迁移。
MADP模型
多视图编码器被设计成将用户编码成k个不同的嵌入,每个嵌入代表用户偏好的唯一视角。我们首先生成类别分类日志: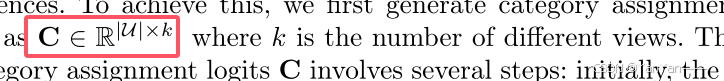
类别分配逻辑C的生成包括几个步骤:首先,将项嵌入和核心嵌入归一化。随后,对交互矩阵进行归一化,并应用丢弃。最后,通过归一化项嵌入和核嵌入的矩阵乘法生成类别分配
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 156
156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









