





大家好,欢迎阅读这份《智能体(AI+Agent)开发指南》!
在大模型和智能体快速发展的今天,很多朋友希望学习如何从零开始搭建一个属于自己的智能体。本教程的特点是 完全基于国产大模型与火山推理引擎实现,不用翻墙即可上手,非常适合国内开发者快速实践。
通过循序渐进的讲解,你将学会从 环境配置、基础构建、进阶功能到实际案例 的完整流程,逐步掌握智能体开发的核心技能。无论你是初学者还是有经验的工程师,相信这份教程都能为你带来启发。
一. 什么是AI Agent
• 与普通 AI 的区别: 传统的 AI 应用遵循“一个口令,一个动作”的模式,而 AI Agent 则是“人类只给目标,AI 自己找路”。例如,对于“研究 AI Agent 的定义”这个任务,普通 AI 可能只会回答其定义,而 AI Agent 则会主动规划并执行一系列动作来完成整个研究任务。
• 工作循环 (Working Cycle): AI Agent 的工作流程是一个循环,包含以下几个步骤:
以 AlphaGo 为例,其目标是赢得棋局,它通过观察棋盘状态(Observation),决定下一步的落子位置(Action),对手的回应改变了棋盘状态(Environment Change),AlphaGo 再次观察、行动,如此循环,直至分出胜负。
目标 (Goal):确定最终需要达成的任务。
观察 (Observation):感知当前的环境状态。
行动 (Action):根据观察和目标,决定并执行下一步动作。
环境变化 (Environment Change):行动会改变环境,并产生新的状态。
循环 (Loop):Agent 再次观察新环境,重复上述过程,直到目标达成。
二. LLM驱动的AI Agent
• 工作原理:
由 LLM 驱动的 Agent 通过自然语言接收任务目标。它将环境信息(如文本、图片)作为输入,以文字形式输出决策和行动,并在循环中不断迭代直至任务完成。与需要专门训练的强化学习模型不同,LLM 凭借其强大的语言理解和生成能力,可以直接“推断”出下一步应该做什么。
• 优缺点:
◦ 优点:灵活性极高,能处理各种开放式任务;无需为每个任务定义复杂的奖励函数;行动空间几乎没有限制。
◦ 缺点:有时可能会做出未经深思熟虑的“猜测”;其决策质量高度依赖于对环境描述的准确理解,模糊或不完整的描述可能导致错误。
三. AI Agent的三大关键能力
- 根据经验调整行为: Agent 需要根据外部反馈来调整后续行动。LLM 主要通过“上下文学习”(In-context Learning)来实现这一点,即将历史行动和反馈作为新的输入,从而影响后续的输出。这面临着“记忆爆炸”的挑战——如果将所有历史记录都输入给 LLM,计算成本会急剧增加。解决方案通常包括引入 写入 (Write)、读取 (Read) 和 反思 (Reflection) 等记忆模块来高效管理历史信息。
- 使用工具 (Tool Using): LLM 自身存在短板(如无法进行实时计算、访问外部网站等),需要借助外部工具来扩展能力。Agent 通过学习如何调用工具(API)来弥补这些不足。当面对复杂任务时,Agent 需要一个“工具选择模块”来决定调用哪个最合适的工具。同时,Agent 也需要具备一定的判断力,以识别并处理工具可能返回的错误信息。
- 制定计划 (Planning): 计划能力指的是先思考并规划好所有步骤,再依次执行。LLM 具备一定的规划能力,但往往在细节上表现不佳。提升其规划能力的方法包括 试错法 (Trial and Error)、脑内模拟 (Internal Simulation) 和 借助工具辅助规划。
四. 使用 LangGraph 构建 Agent 实战
如何实现一个 Agent?关键步骤有两个:接入一个优秀的大模型 和 为其配置并调用工具。我们选择 LangGraph 作为构建 Agent 的框架。
GitHub:https://github.com/langchain-ai/langgraph
1. 环境配置
pip install -U langgraph
pip install langchain-openai
2. 代码实现
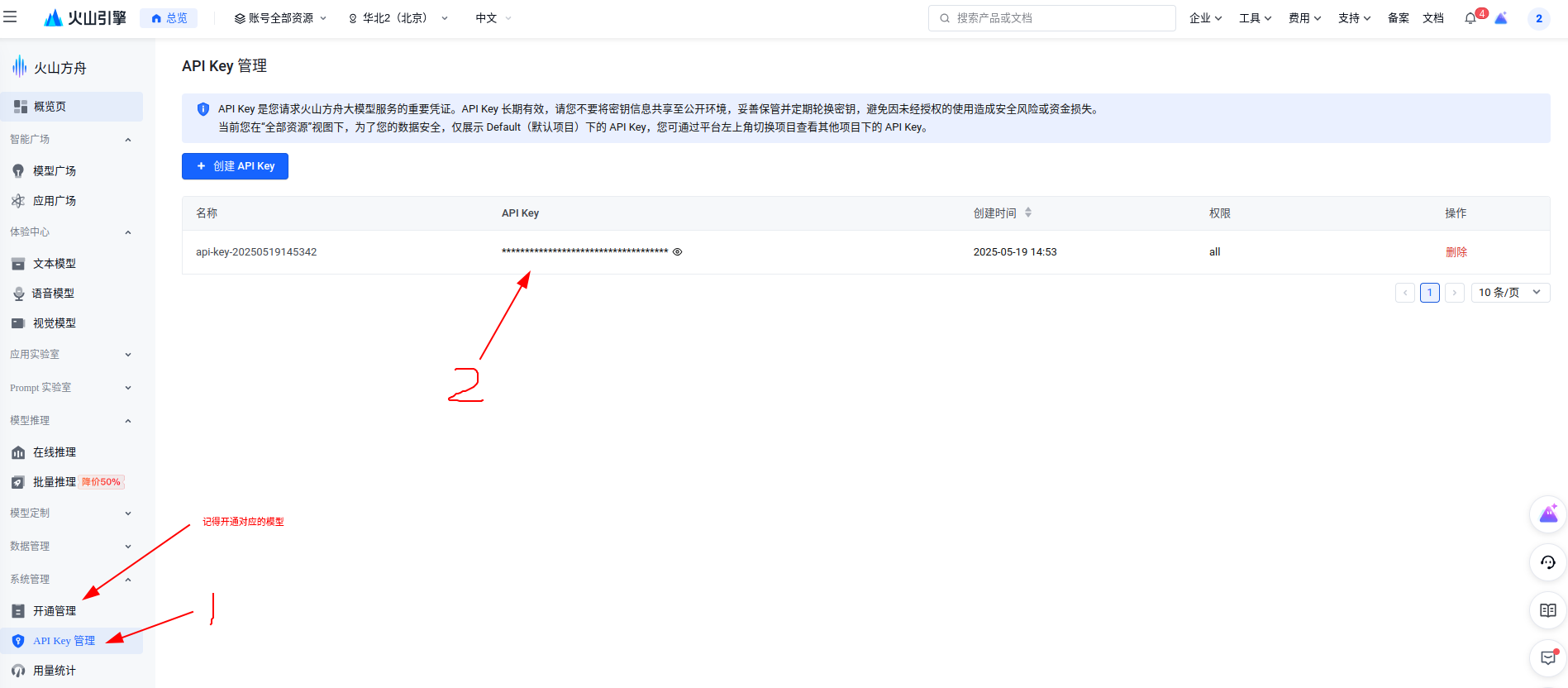
官方示例通常采用 Claude、GPT 或 Gemini 等模型,对新手可能不太友好。因此,我们这里改用字节的 doubao-1-5-pro-32k-250115 模型,该模型提供免费调用额度。
https://www.volcengine.com/
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
# 配置 火山引擎 的模型服务
# 从 火山引擎 官网获取 API Key 和 Base URL
base_url = 'https://ark.cn-beijing.volces.com/api/v3'
api_key = '02c62e9c-8d14-432a-97fb-4e34ecfe9c5c'
model_name = 'doubao-1-5-pro-32k-250115'
# 定义一个工具函数
@tool
def get_weather(city: str) -> str:
"""为一个给定的城市获取天气信息。"""
return f"{city}的天气是晴天"
# 初始化大语言模型
llm = ChatOpenAI(
api_key=api_key,
base_url=base_url,
model_name=model_name,
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
)
# 使用 LangGraph 创建一个 ReAct 风格的 Agent
# ReAct (Reasoning and Acting) 是一种让 LLM 通过思考和行动来解决问题的框架
agent = create_react_agent(
model=llm,
tools=[get_weather],
prompt="You are a helpful assistant"# 你可以根据需要调整提示词
)
# 运行 Agent
# 我们向 Agent 提问 "what is the weather in sf"
result = agent.invoke(
{"messages": [{"role": "user", "content": "what is the weather in Wuhan"}]}
)
# 打印最终的输出结果
# result 包含了完整的执行流程,我们这里只关心最终的回复内容
# 通常最终回复在消息列表的最后一条
print(result['messages'][-1].content)
结果输出:武汉目前的天气是晴天。
从结果可以看出,Agent 成功地理解了 "Wuhan 是 “武汉” ,并调用了 get_weather 工具,最终给出了正确的回复。这展示了一个最基本的 LLM Agent 的完整工作流程。
欢迎关注微信公众号:AIWorkshopLab,自动获取完整教程:智能体(AI+Agent)开发指南.pdf。



















 2020
2020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











