




 本文介绍了BERT模型的核心组件,包括BertTokenizer的使用,如何处理基本分词与WordPiece分词,以及BertModel内部的BertEmbeddings、BertEncoder和BertPooler结构。重点讲解了注意力机制、自注意力和跨注意力的区别,以及模型的前向传播过程和剪枝技术。
本文介绍了BERT模型的核心组件,包括BertTokenizer的使用,如何处理基本分词与WordPiece分词,以及BertModel内部的BertEmbeddings、BertEncoder和BertPooler结构。重点讲解了注意力机制、自注意力和跨注意力的区别,以及模型的前向传播过程和剪枝技术。
目录
基于 Transformers 版本 4.4.2(2021年3月19日发布)项目中pytorch版的BERT相关代码进行分析。
BertTokenizer
BertTokenizer是基于BasicTokenizer和WordPieceTokenizer的分词器。
- 源代码
- 调用
bt = BertTokenizer.from_pretrained('bert-base-uncased')
bt('I like natural language progressing!')
BasicTokenizer
BasicTokenizer负责处理的第一步——按标点、空格等分割句子,并处理是否统一小写,以及清理非法字符。
- 对于中文字符,通过预处理(加空格)来按字分割;
- 同时可以通过never_split指定对某些词不进行分割;
WordPieceTokenizer
WordPieceTokenizer在词的基础上,进一步将词分解为子词(subword)。subword 介于 char 和 word 之间,既在一定程度保留了词的含义,又能够照顾到英文中单复数、时态导致的词表爆炸和未登录词的 OOV(Out-Of-Vocabulary)问题,将词根与时态词缀等分割出来,从而减小词表,也降低了训练难度;
BertTokenizer 有以下常用方法:
- from_pretrained:从包含词表文件(vocab.txt)的目录中初始化一个分词器;
- tokenize:将文本(词或者句子)分解为子词列表;
- convert_tokens_to_ids:将子词列表转化为子词对应下标的列表;
- convert_ids_to_tokens :与上一个相反;
- convert_tokens_to_string:将 subword 列表按“##”拼接回词或者句子;
- encode:对于单个句子输入,分解词并加入特殊词形成“[CLS], x, [SEP]”的结构并转换为词表对应下标的列表;对于两个句子输入(多个句子只取前两个),分解词并加入特殊词形成“[CLS], x1, [SEP], x2, [SEP]”的结构并转换为下标列表;
- decode:可以将 encode 方法的输出变为完整句子。
BertModel
BertModel主要为transformer encoder结构,包含三个部分:
- BertEmbeddings类
- BertEncoder类
- BertPooler类(这一部分是可选的)
BertModel前向传播过程中各个参数的含义以及返回值:
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_values=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
)
- input_ids:经过 tokenizer 分词后的 subword 对应的下标列表;
- attention_mask:在 self-attention 过程中,这一块 mask 用于标记 subword所处句子和padding的区别,将padding部分填充为0;
- token_type_ids:标记 subword 当前所处句子(第一句/第二句/ padding);
- position_ids:标记当前词所在句子的位置下标;
- head_mask:用于将某些层的某些注意力计算无效化;
- inputs_embeds:如果提供了,那就不需要input_ids,跨过 embedding lookup 过程直接作为 Embedding 进入 Encoder 计算;
- encoder_hidden_states:这一部分在BertModel配置为decoder时起作用,将执行 cross-attention 而不是 self-attention;
- encoder_attention_mask:同上,在cross-attention中用于标记 encoder端输入的padding;
- past_key_values:把预先计算好的 K-V 乘积传入,以降低 cross-attention 的开销(因为原本这部分是重复计算);
- use_cache:将保存上一个参数并传回,加速 decoding;
- output_attentions:是否返回中间每层的 attention 输出;
- output_hidden_states:是否返回中间每层的输出;
- return_dict:是否按键值对的形式(ModelOutput 类,也可以当作 tuple 用)返回输出,默认为真。
BertModel 的其他方法:
- get_input_embeddings:提取embedding中的 word_embeddings 即词向量部分;
- set_input_embeddings:为embedding中的 word_embeddings赋值;
- _prune_heads:提供了将注意力头剪枝的函数,输入为{layer_num: list of heads to prune in this layer}的字典,可以将指定层的某些注意力头剪枝。
注:剪枝是一个复杂的操作,需要将保留的注意力头部分的 Wq、Kq、Vq 和拼接后全连接部分的权重拷贝到一个新的较小的权重矩阵(!先禁止 grad 再拷贝),并实时记录被剪掉的头以防下标出错。具体参考BertAttention部分的prune_heads方法。
BertEmbeddings类
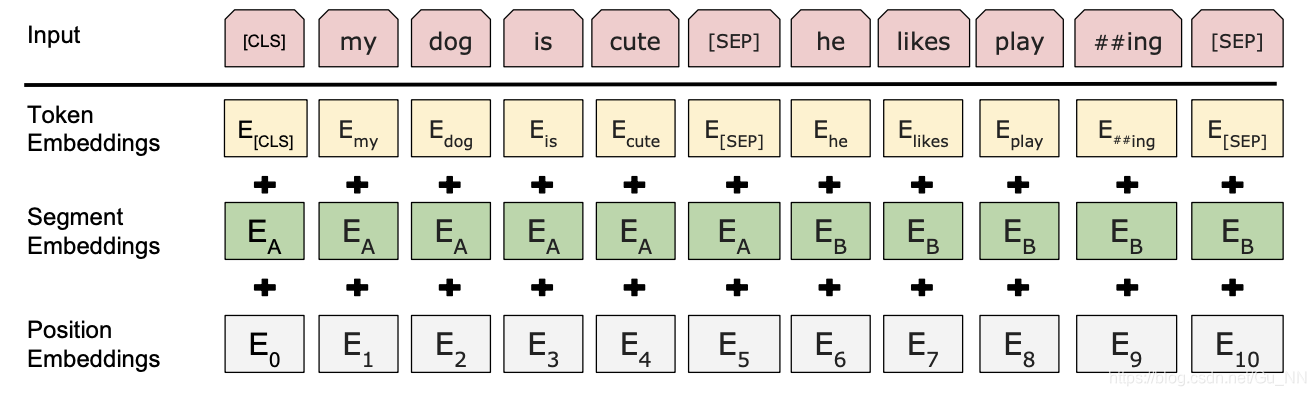 From:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
From:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5315
5315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









