




 本文介绍了Neo4j的Graph Data Science (GDS) 1.4版本,该版本引入了图嵌入和图学习功能。GDS支持Node2Vec、FastRP和GraphSAGE等图嵌入算法,提供机器学习模型目录用于存储和应用预测模型。此外,GDS还包括丰富的图算法集合,旨在推动图数据库从图查询向图学习的发展。
本文介绍了Neo4j的Graph Data Science (GDS) 1.4版本,该版本引入了图嵌入和图学习功能。GDS支持Node2Vec、FastRP和GraphSAGE等图嵌入算法,提供机器学习模型目录用于存储和应用预测模型。此外,GDS还包括丰富的图算法集合,旨在推动图数据库从图查询向图学习的发展。
(本文部分内容来自Neo4j.com: https://neo4j.com/blog/announcing-graph-native-machine-learning-in-neo4j/ )
作为全球领先的图数据库平台软件开发者,Neo4j率先发布全球第一个“原生图机器学习库” GDS :Graph Data Science 版本1.4。在这一版本中,除了增加更多图算法外,还第一次引入并实现了面向“图学习”(Graph Machine Learning)的企业级“图嵌入”(Graph Embedding)和图表示的机器学习模型算法过程。下面我们来逐一看一下GDS中到底有哪些“干货”吧。
1、原生(Native)属性图(Label PropertyGraph)
现实世界可以用属性图(Property Graph),即包含节点、边和属性的图结构来描述和存储。例如,在一个社交网络中,人、地方、活动等可以用节点来表示,人群之间的关系诸如亲属、朋友、同事等则可以用关系来表示;代表“人”的节点的属性则可以是姓名、出生年月、性别等,代表“朋友”的关系的属性则可以有“成为朋友的日期”等。
从上面的简单例子可以看出,以属性图表示复杂的网络其最大的优点是自然、简洁、易于理解;而基于原生(Native)图数据库存储和处理网络则能为图的遍历提供最佳的查询性能。在原生的图数据库中,数据以图的方式存储、查询、展现。下图对不同的存储模式做了比较。
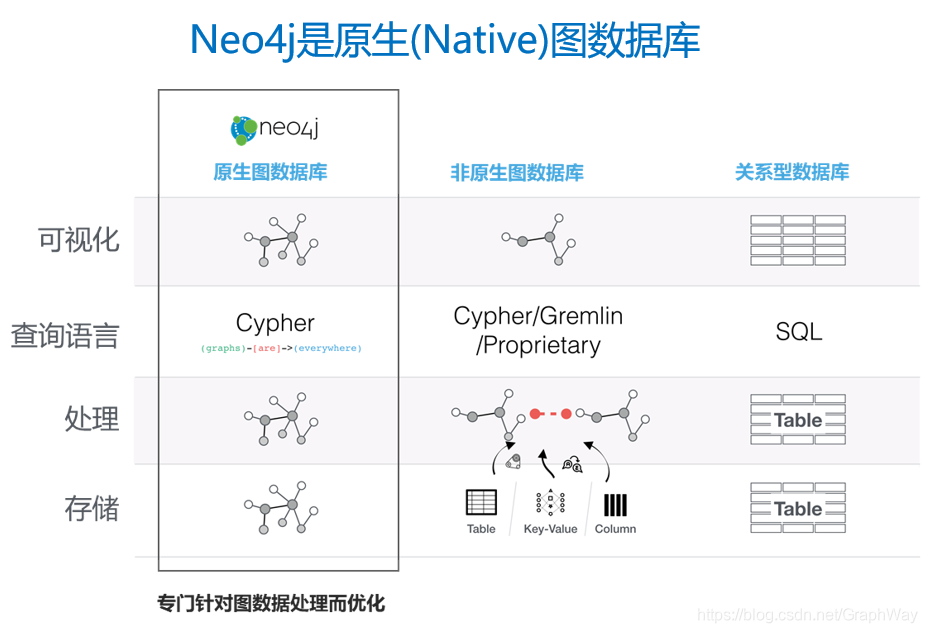
关于图的模式,还有另外一种流行的标准是RDF(Resource Description Framework - 资源描述框架),这个是W3C制订的标准,使用三元组(可以简单
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6008
6008





 到【灌水乐园】发言
到【灌水乐园】发言







