




 本文介绍了如何利用Python爬虫技术定时抓取知乎热榜,通过requests库获取HTML,BeautifulSoup解析内容,发现新标题并打印。关键步骤包括网络请求、HTML解析和内容比较。
本文介绍了如何利用Python爬虫技术定时抓取知乎热榜,通过requests库获取HTML,BeautifulSoup解析内容,发现新标题并打印。关键步骤包括网络请求、HTML解析和内容比较。
任务概述
这次的任务是定时的爬取知乎热榜前十的标题,如果当前爬取的热榜较上一次有所变动,则将新增的标题打印出来。
一、网页的爬取和解析
爬取网页可以选择用urllib库,也可以选择使用request库,这里选用request。
爬取热榜网页后获得页面的html内容,随后要做的就是解析些内容,获取热点标题和链接,这里用bs4中的BeautifulSoup进行解析。
import time
import requests
from bs4 import BeautifulSoup
# 设置headers,复制headers的时候注意不要搞错了
url = 'https://www.zhihu.com/hot'
headers = {
'cookie':'...', # 填入你的cookie
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.3',
}
# python的接口很方便,这么几行就能完成热榜标题的提取
def getHot()->list:
try:
# 简单直接的方法获取页面内容
res = requests.get(url,headers=headers)
html = res.text
# 处理网页内容,提取热榜标题和链接
soup = BeautifulSoup(html, 'lxml')
hot_list = soup.select('#TopstoryContent > div > div > div.HotList-list > section > div.HotItem-content > a')
hot_list = [hot['title'] + "\n" + hot['href'] +'\n' for hot in hot_list]
return hot_list[0:10]
# 如果断网了,则上面这段代码会抛出异常,需进行处理
except:
print("[",cur_time(),"]:当前网络不可用,60s后将再次尝试连接网络\n")
time.sleep(60)
return []
二、定时更新
获取热榜标题后任务就已经完成大半了,剩下的就是定时的爬取热榜并将更新的内容打印出来。
# 检查,每隔一段时间检查一次热榜,将新增的标题打印出来
def checkUpdate():
# 每10分钟检查一次更新
print("\n*********************知乎热榜*********************\n")
hot_list_old = []
while hot_list_old == []:
hot_list_old = getHot()
print("当前热榜前十\t [time:" + cur_time() +']\n')
for hot in hot_list_old:
print(hot)
print("\n\n********************每分钟刷新一次********************\n")
while(1):
time.sleep(60)
hot_list_new = getHot()
flag = 0
while(hot_list_new == []):
flag = 1
hot_list_new = getHot()
if flag == 1:
print("[",cur_time(),"]:网络连接已恢复")
# 对比两次热榜是否相同,将新榜中新增的标题提取出来
for hot_new in hot_list_new:
flag = 0 # 更新标记
for hot_old in hot_list_old:
if hot_new == hot_old:
flag = 1
if flag == 0:
print(cur_time(),"\t",hot_new)
hot_list_old = hot_list_new
# 获取当前时间
def cur_time():
return time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
这里其实并不复杂,只是为了打印的效果更好看一些,添加较多的print语句。
三、生成可执行文件
最后的话将这份代码打包成可执行文件,需要用到pyinstaller库。
在终端中进入到代码文件所在目录,然后执行pyinstaller -F XXX.py,等待十来秒后在当前目录下生成disk文件夹,里面的文件即为可执行文件。
双击可执行文件,效果如下: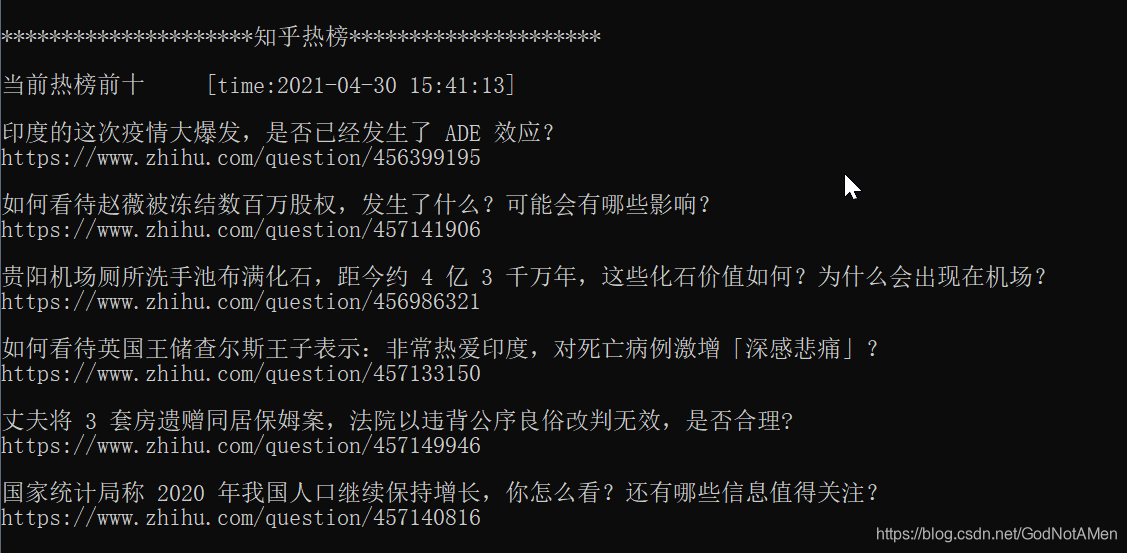


















 1814
1814




 到【灌水乐园】发言
到【灌水乐园】发言







