




 本文介绍如何在Windows10环境下,使用IDEA和MavenScala搭建Spark词频统计项目。通过具体的代码示例,展示了从创建Scala类到实现词频统计的全过程,并解决了常见异常问题。
本文介绍如何在Windows10环境下,使用IDEA和MavenScala搭建Spark词频统计项目。通过具体的代码示例,展示了从创建Scala类到实现词频统计的全过程,并解决了常见异常问题。
本篇文章,讲解在Windows10下,使用IDEA搭建好的Maven Scala项目进行本地的Spark词频统计的项目开发工作。
数据依然存在于某个盘符文件下,具体看代码,内容是:
apple orange pear
banana lemon apple
pear peach orange
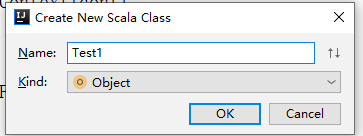
在上一篇文章中创建好的Module的package下,新建Scala类,选择object形式:
编写代码:
package com.alan
import org.apache.spark.{SparkConf, SparkContext}
object Test1 {
def main(args: Array[String]): Unit = {
//创建SparkContext
//本地运行,指定2个内核
val conf=new SparkConf().setMaster("local[2]").setAppName("WordCount")
//提交运行
//val conf=new SparkConf().setAppName("WordCound");
val sc=new SparkContext(conf)
//加载文件
val file=sc.textFile("file:///d:/test/words.txt")
//处理
val flatFile=file.flatMap(item=>item.split(" "))
val flatFileMap=flatFile.map(item=>(item,1))
val aggCount=flatFileMap.reduceByKey((curr,agg)=>curr+agg)
//得到结果
aggCount.foreach(item=>println(item))
}
}
观察代码,可见和Scala交互式在核心上是一致的,只是要自己建一个SparkContext对象。
结果:

异常参考:
1、如果要使用提交运行的方式,运行会报如下异常:
org.apache.spark.SparkException: A master URL must be set in your configuration
这是因为提交任务要告诉Spark运行的模式:
local 本地单线程
local[K] 本地多线程(指定K个内核)
local[*] 本地多线程(指定所有可用内核)
spark://HOST:PORT 连接到指定的 Spark standalone cluster master,需要指定端口
mesos://HOST:PORT 连接到指定的 Mesos 集群,需要指定端口
yarn-client客户端模式 连接到 YARN集群。需要配置 HADOOP_CONF_DIR
yarn-cluster集群模式 连接到 YARN 集群。需要配置HADOOP_CONF_DIR
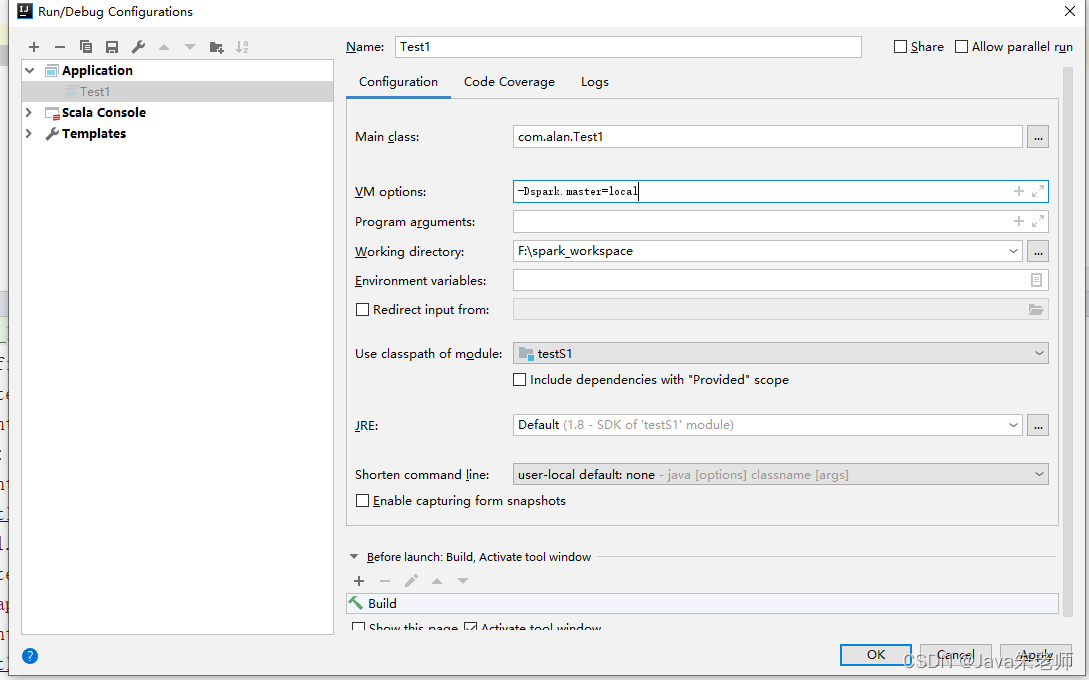
本次因为是在本地运行,可以编辑环境变量,设置参数:
-Dspark.master=local
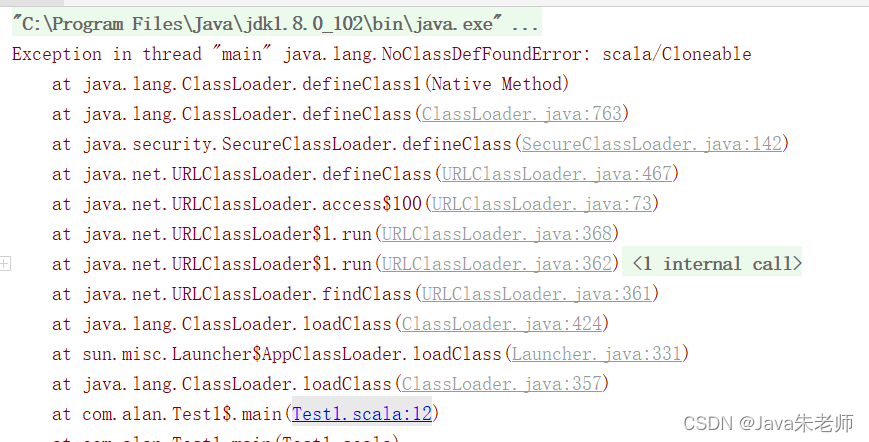
2、Exception in thread “main” java.lang.NoClassDefFoundError: scala/Cloneable
Scala版本不对导致,请修改为符合Spark3.1.2的版本,如Scala2.12.5

















 6705
6705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









