







一、Prometheus问题
在多集群,大集群等场景下,Prometheus 由于没有分片能力和多集群支持,还有Prometheus 不支持长期存储、不能自动水平扩缩容、大范围监控指标查询会导致 Prometheus 服务内存突增等。
单台的 Prometheus 存在单点故障的风险,随着监控规模的扩大,Prometheus 产生的数据量也会非常大,性能和存储都会面临问题。毋庸置疑,我们需要一套高可用的 Prometheus 集群。
二、高可用方案一: 基本HA
Promethues通过Pull机制进行数据采集,要确保Promethues服务的可用性,可以在不同的服务器上部署多个 Prometheus 实例,每个实例独立收集数据。
通过负载均衡访问多个prometheus实例, 即可实现基本的高可用功能。
- 使用负载均衡器(如 HAProxy、NGINX)来分发Prometheus的请求到不同的实例中。如果某个实例宕机,负载均衡器会自动切换到其他健康的实例。
- 配合 Kubernetes 部署时,可以通过 Service 或 Ingress 来实现流量的分发。
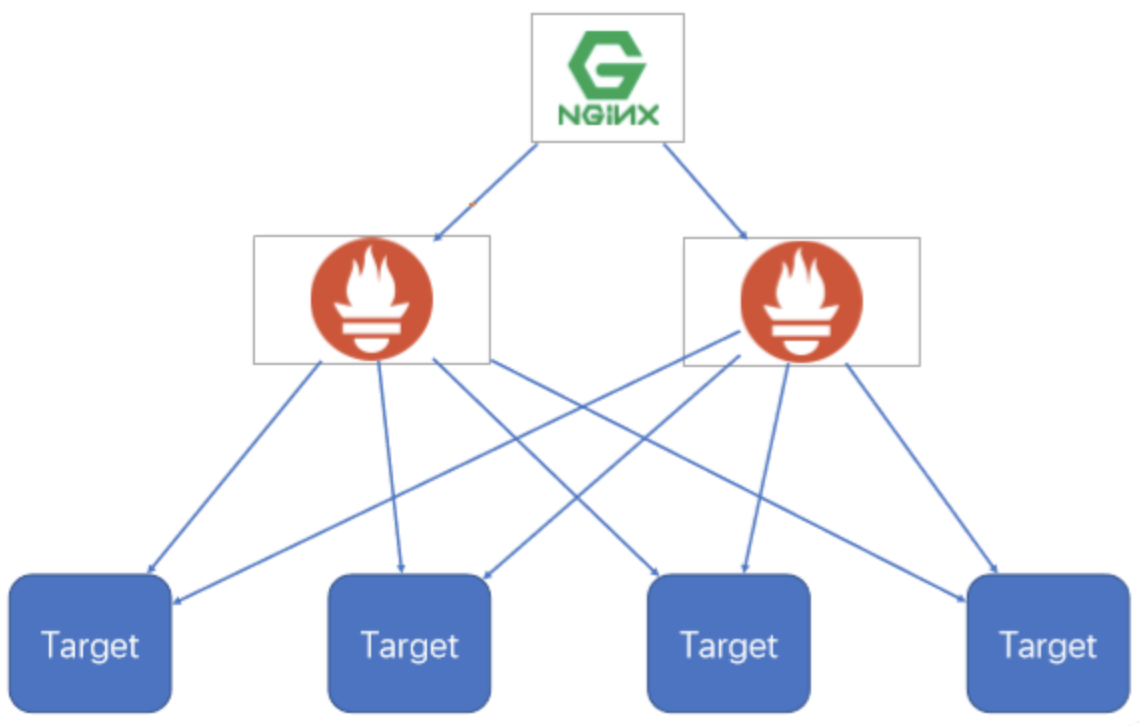
基本的HA模式只能确保Promethues服务的可用性问题,但是不解决Prometheus Server之间的数据一致性问题以及持久化问题,也无法进行动态的扩展。适合监控规模不大,Promethues Server也不会频繁发生迁移的情况,并且只需要保存短周期监控数据的场景。
三、高可用方案二: 基本HA+远程存储
在基本HA模式的基础上通过添加Remote Storage存储支持,将监控数据保存在第三方存储服务上。
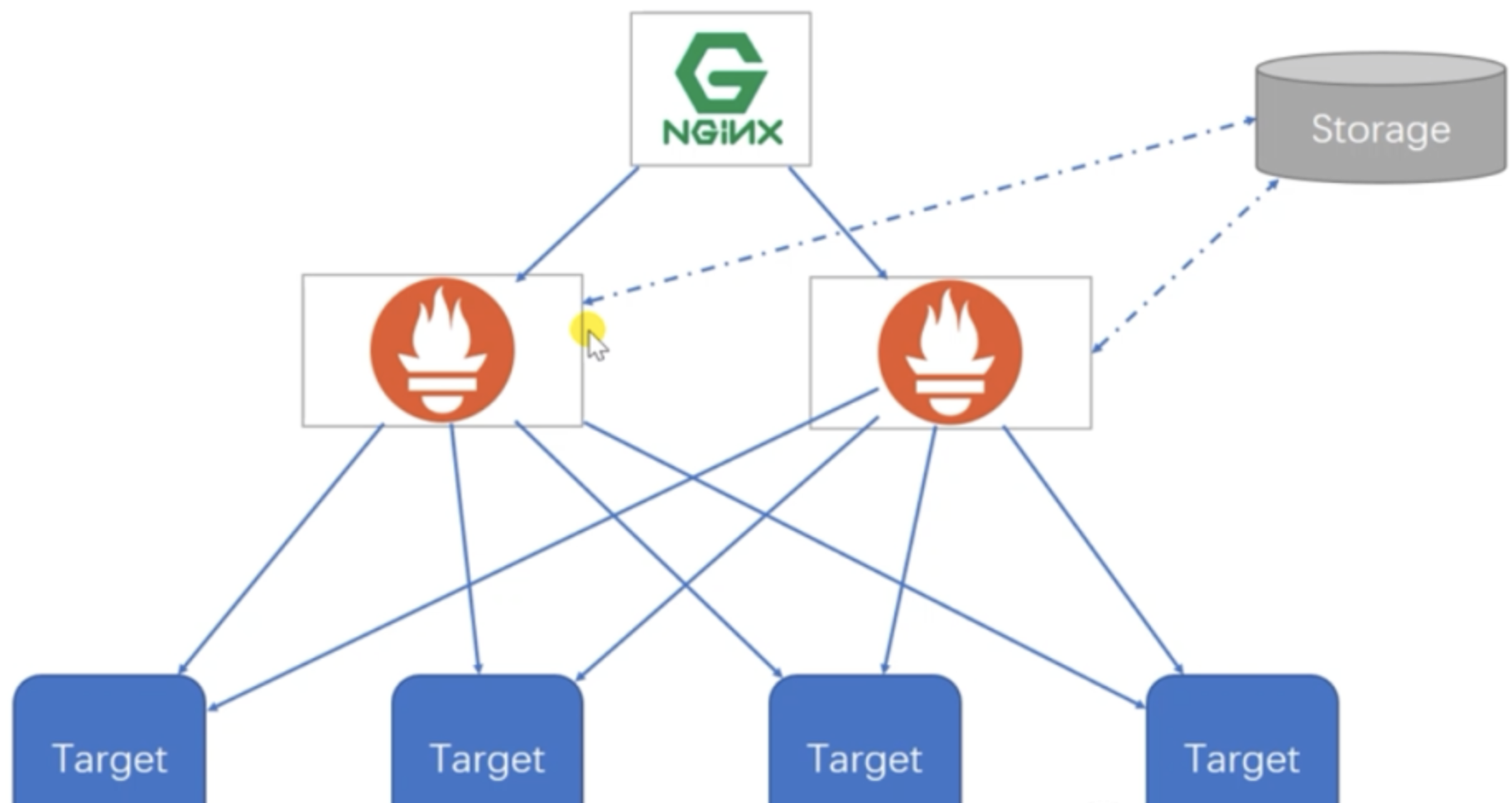
在解决了Promethues服务可用性的基础上,同时确保了数据的持久化,当Promethues Server发生宕机或者数据丢失的情况下,可以快速的恢复。同时Promethues Server能很好的进行迁移. 该方案适用于监控规模不大,希望能够将监控数据持久化,同时能够确保Promethues Server的可迁移性的场景。
四、远程存储方案
Prometheus定义了同远端存储的读写接口,交互协议使用protocol buffer定义,传输基于HTTP;一个存储系统如果要支持Prometheus,仅需要实现一个adapter层,将Prometheus的的读写请求转换为其内部的格式来处理。
Influxdb是目前Prometheus支持的最好的时序型数据库,也是目前相对主流的时序数据库,选用Influxdb来作为Prometheus的远程存储是目前的最佳选择, 解锁本地存储的限制, 解决Prometheus server高可用的数据一致性和持久化问题。
不足之处是Influxdb的集群功能只有商业版本才支持, 开源版本只能部署单机版, 解决办法是使用公有云上的时序数据库产品。
远程存储InfluxDB如何处理重复数据点:measurement的名字、tag set和时间戳唯一标识一个数据点。
如果提交的数据点跟已有的数据点相比,具有相同measurement、tag set和时间戳,但具有不同field set,那么该数据点的field set会变为旧field set和新field set的并集,如果有任何冲突以新field set为准。
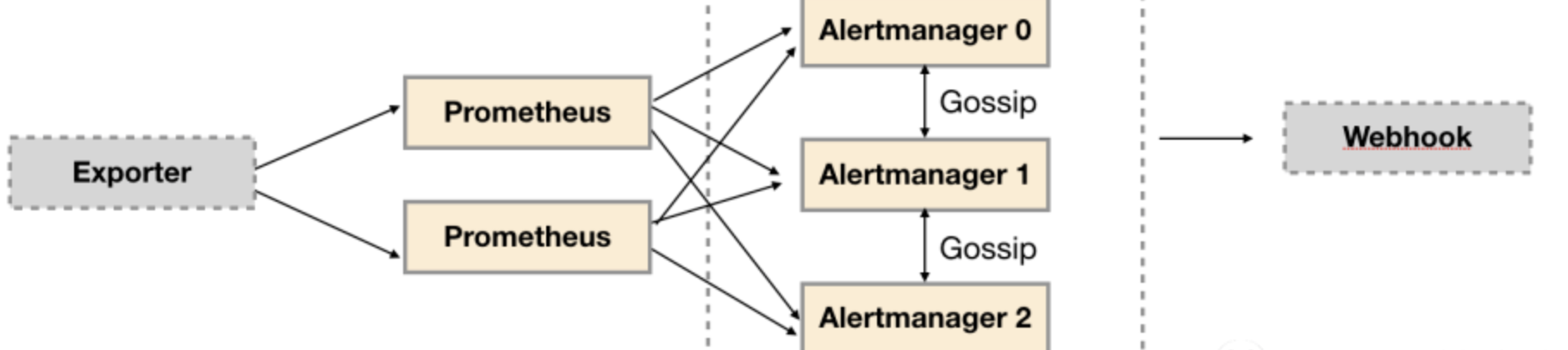
五、Promethues Server重复报警如何解决-Alertmanager
通常会部署两个或者两个以上的Promthus Server,它们具有完全相同的配置包括Job配置,以及告警配置等, 这样就导致Alertmanager会收到多个相同的报警信息, 但是基于Alertmanager的告警分组机制, 即使不同的Prometheus Sever分别发送相同的告警给Alertmanager,Alertmanager也可以自动将这些告警合并为一个通知向receiver发送。
当Alertmanager接收到来自多个Prometheus的告警消息后,会按照以下流程对告警进行处理:

- 在第一个阶段Silence中,Alertmanager会判断当前通知是否匹配到任何的静默规则,如果没有则进入下一个阶段,否则则中断流水线不发送通知。
- 在第二个阶段Wait中,Alertmanager会根据当前Alertmanager在集群中所在的顺序(index)等待index * 5s的时间。
- 当前Alertmanager等待阶段结束后,Dedup阶段则会判断当前Alertmanager数据库中该通知是否已经发送,如果已经发送则中断流水线,不发送告警,否则则进入下一阶段Send对外发送告警通知。
- Send阶段完成对报警的发送
- 告警发送完成后该Alertmanager进入最后一个阶段Gossip,Gossip会通知其他Alertmanager实例当前告警已经发送。其他实例接收到Gossip消息后,则会在自己的数据库中保存该通知已发送的记录。
六、Alertmanager单点问题
虽然Alertmanager能够同时处理多个相同的Prometheus Server所产生的告警。但是由于单个Alertmanager的存在,当前的部署结构存在明显的单点故障风险,当Alertmanager单点失效后,告警的后续所有业务全部失效。
解决方案是部署多套Alertmanager。但是由于Alertmanager之间并不了解彼此的存在,因此则会出现告警通知被不同的Alertmanager重复发送多次的问题。
为解决Alertmanager集群带来的告警重复发送问题, Alertmanager引入了Gossip机制。Gossip机制为多个Alertmanager之间提供了信息传递的机制。确保即使在多个Alertmanager分别接收到相同告警信息的情况下,也只有一个告警通知被发送给Receiver。
七、如何解决Promethues Server单台瓶颈-邦联集群
当单台Promethues Server无法处理大量的采集任务时,可以考虑基于Prometheus联邦集群的方式将监控采集任务划分到不同的Promethues实例当中, 即在任务级别做功能分区。
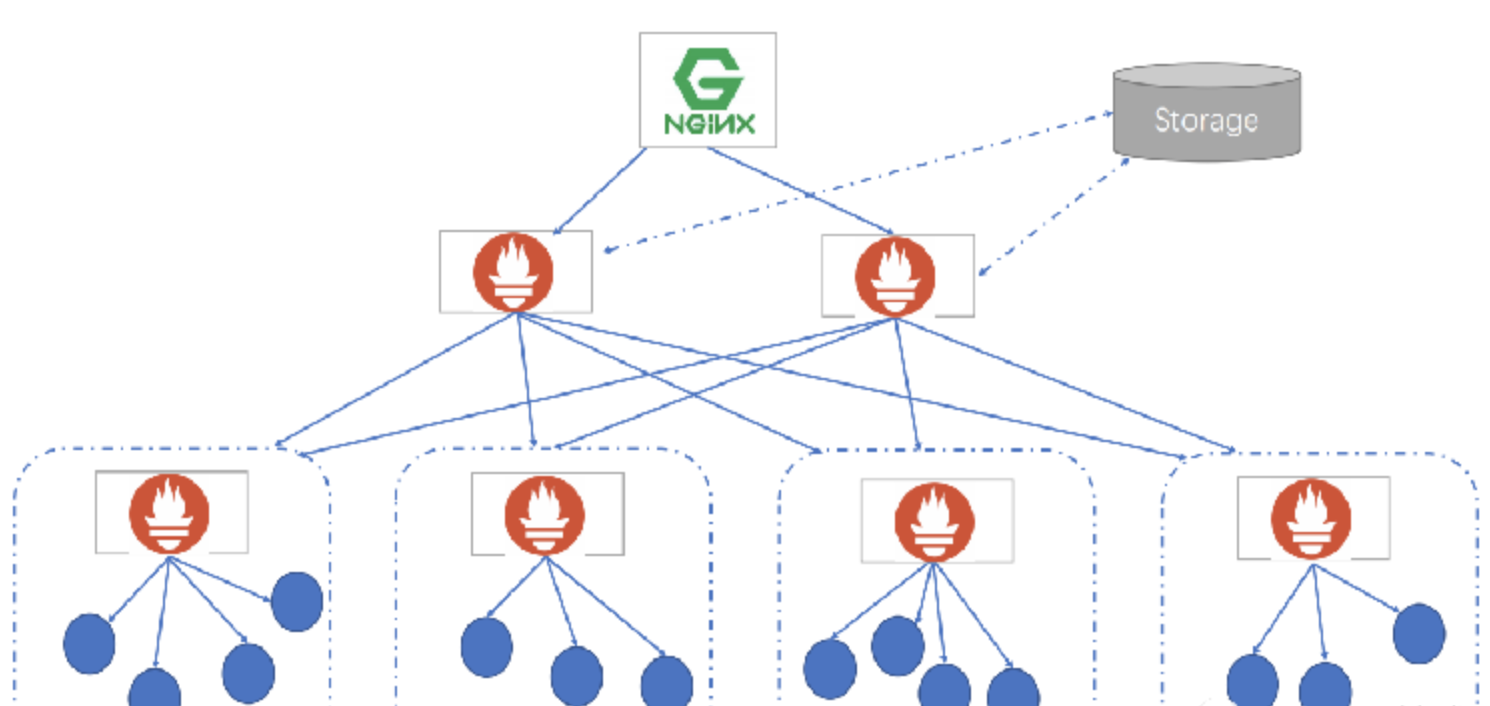
利用Prometheus联邦集群的特性,将不同类型的采集任务划分到不同的Promethues子服务中,从而实现功能分区。例如一个Promethues Server负责采集基础设施相关的监控指标,另外一个Prometheus Server负责采集应用监控指标。再由上层Prometheus Server实现对数据的汇聚。
八、邦联集群的另一个优势
这种模式也适合于多数据中心的情况,当Promethues Server无法直接与数据中心中的Exporter进行通讯时,在每一个数据中部署一个单独的Promethues Server负责当前数据中心的采集任务,这样可以避免进行大量的网络配置。
只需要确保主Promethues Server实例能够与当前数据中心的Prometheus Server通讯即可。中心Promethues Server负责实现对多数据中心数据的聚合。


















 1554
1554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









