







论文:DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
图源:https://github.com/deepseek-ai/DeepSeek-R1 & https://arxiv.org/pdf/2402.03300
在大型语言模型(LLM)的微调过程中,强化学习(Reinforcement Learning, RL)已成为关键技术,尤其是通过人类反馈进行强化学习(RLHF)的方法。近年来,Group Relative Policy Optimization(GRPO)作为一种新兴的强化学习算法,逐渐引起了广泛关注。本文将深入探讨GRPO的背景、原理及其在LLM中的应用。
GRPO的背景与起源
在语言模型的应用中,无论是让模型解决数学问题,还是使其在对话中更好地满足人类偏好(例如避免不当输出或提供更详细的解释),我们通常首先通过大规模的无监督或自监督训练为模型打下基础。随后,通过“监督微调”(Supervised Fine-Tuning, SFT),模型能够初步学习到符合特定需求的行为。然而,SFT 往往难以显式地整合人类或高层目标的复杂偏好,例如对答案质量、安全性或多样性的要求。这时,“强化学习微调”便成为了一种更强大的工具,它能够通过反馈信号直接优化模型的输出,使其更好地对齐人类期望和目标任务。
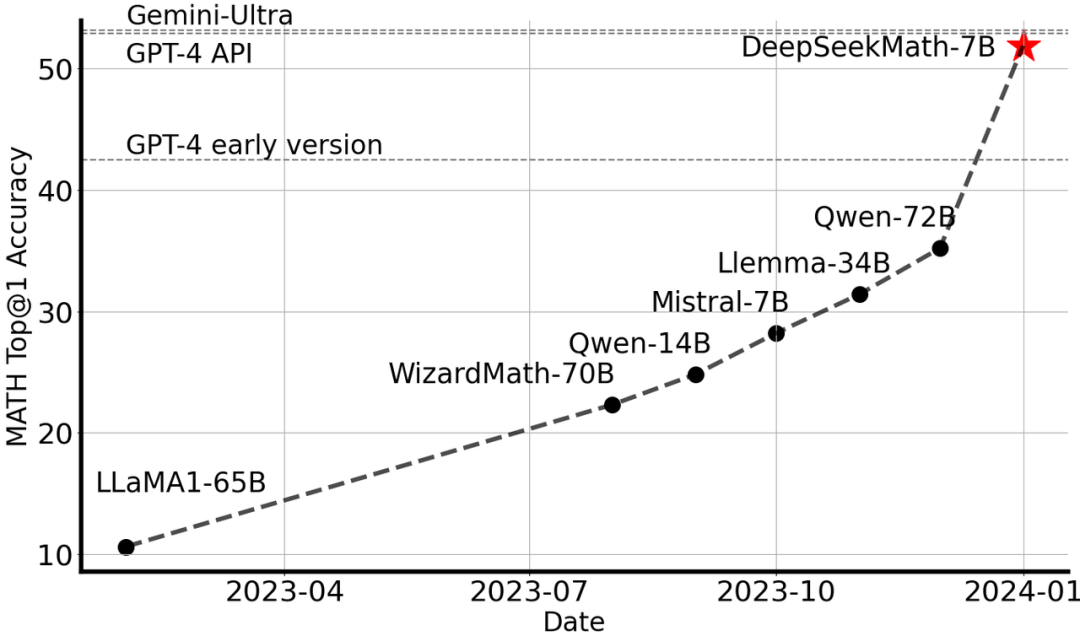
GRPO算法于2024年4月在DeepSeek-AI、清华大学和北京大学的论文《DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models》中首次提出。它是对 Proximal Policy Optimization(PPO)算法的改进,PPO自2017年由OpenAI引入后,因其稳定性和高效性在强化学习任务中广受欢迎。然而,随着模型规模的扩大和任务复杂度的增加,PPO的内存开销和计算成本问题日益凸显,GRPO应运而生。
GRPO的核心思想
GRPO的核心目标是通过简化算法结构,提高计算效率,同时增强模型在特定任务(如数学推理)中的表现。与PPO相比,GRPO在以下几个方面进行了优化:
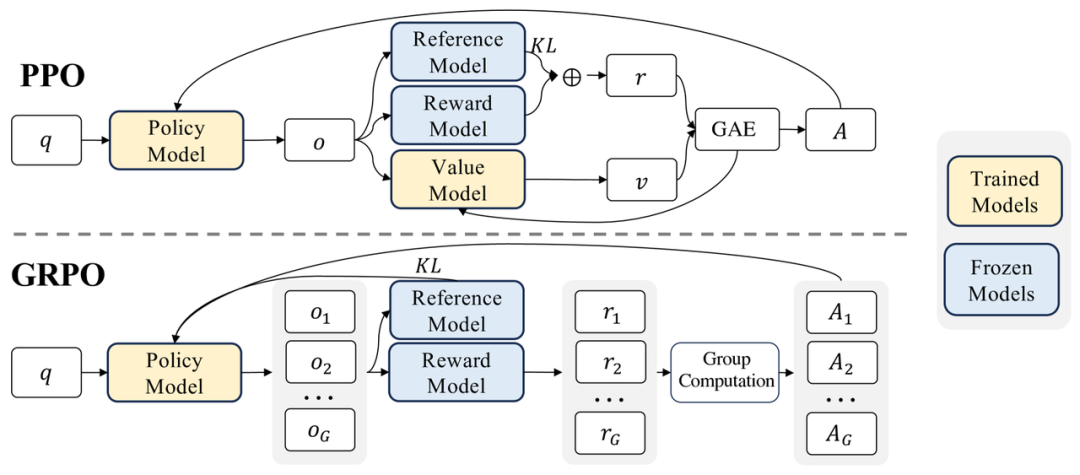
1. 组相对奖励机制(Group-Relative Reward)
分组采样:在训练过程中,将样本(例如模型生成的文本序列)按批次划分为多个小组(Group)。例如,一个批次可能包含 N 个样本,每组包含 M 个样本(N = k \times M)。
组内标准化:对每个小组内的样本奖励值进行标准化(如减去均值或除以标准差),将绝对奖励值转化为组内相对奖励值。这一步的目的是减少不同任务或不同训练阶段中奖励量纲不一致的影响。
相对比较:通过组内样本的相对比较,强调策略优化应关注同一组内样本之间的优劣差异,而非全局绝对奖励值。这与人类偏好学习中的“对比学习”思路类似。
2. 策略更新的简化
省略优势函数:传统 PPO 依赖优势函数(Advantage Function)来估计当前动作相对于平均表现的优劣,而 GRPO 通过组内相对奖励直接替代优势函数,减少了计算复杂度。
直接策略优化:GRPO 的目标函数直接基于组内相对奖励进行策略梯度更新,无需像 PPO 那样通过复杂的剪切(Clipping)机制限制更新幅度。
3. 内存与计算优化
减少中间变量存储:PPO 需要存储旧策略的概率分布(用于重要性采样),而 GRPO 通过组内对比机制减少了此类中间变量的依赖,从而降低内存占用。
并行化处理:组划分使得计算可以并行化,进一步提升了训练效率。
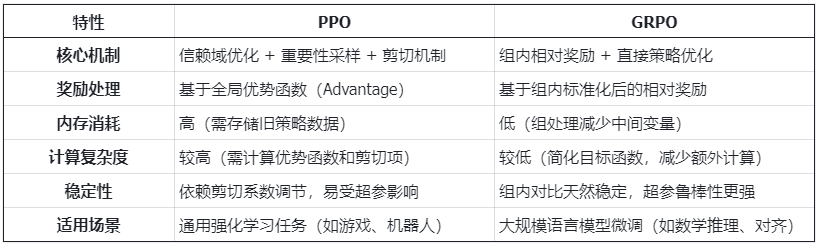
GRPO vs. PPO
以下从算法设计、训练效率和适用场景三个方面对比 GRPO 与 PPO:
GRPO:推动DeepSeek实现卓越性能
GRPO通过实现高效且可扩展的推理任务训练,为DeepSeek的性能提升提供了强大动力。以下是GRPO如何转化为实际成功的具体表现:
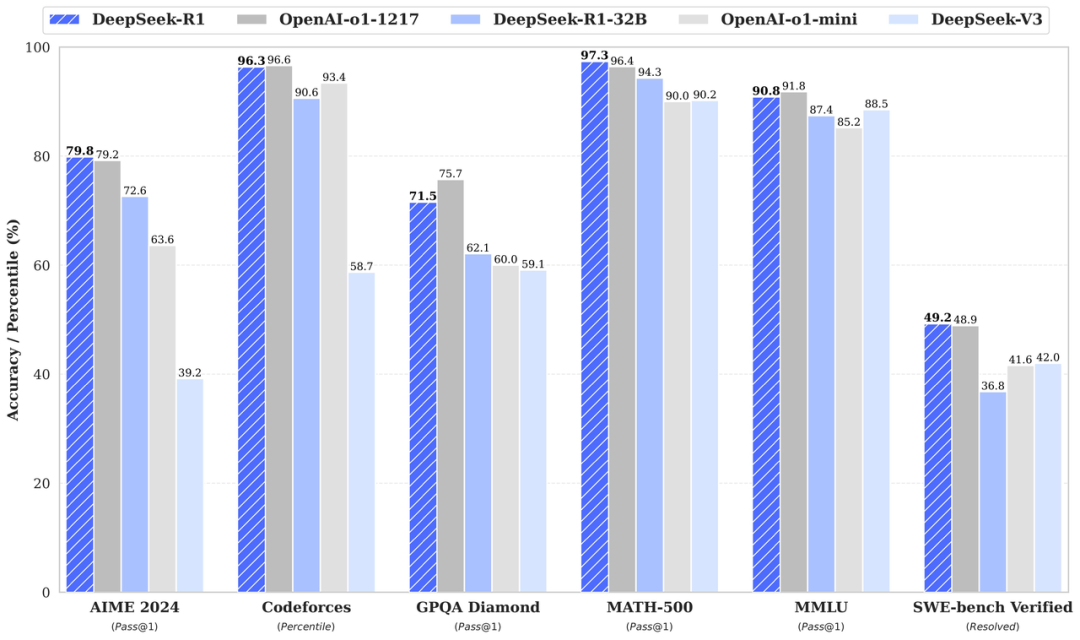
1. 显著提升推理能力
GRPO助力DeepSeek-R1-Zero在AIME 2024竞赛中取得了71.0%的Pass@1分数,通过多数投票后分数进一步提升至86.7%。这一表现使其在解决数学和逻辑问题方面能够与OpenAI等专有模型比肩,展现了GRPO在复杂推理任务中的强大优化能力。
2. 激发新兴能力
通过GRPO的优化,DeepSeek模型发展出了诸如自我验证、反思和长链思维等高级推理行为。这些能力对于解决复杂任务至关重要,进一步提升了模型在实际应用中的表现。
3. 卓越的可扩展性
GRPO基于组内相对表现的优化机制,消除了对复杂评论模型的需求,从而大幅降低了计算开销。这一特性使得大规模训练成为可能,为模型的扩展提供了高效且经济的解决方案。
4. 高效的模型蒸馏
从GRPO训练的检查点中蒸馏出的较小模型,依然保留了较高的推理能力。这一成果不仅使AI技术更易于普及,还显著降低了使用成本,为更广泛的应用场景提供了可能性。
通过聚焦于组内相对表现的优化,GRPO使DeepSeek在推理能力、长上下文理解和通用AI任务中不断刷新性能标准,同时保持了高效性和可扩展性。这一创新算法不仅为DeepSeek的成功奠定了基础,也为未来AI技术的发展开辟了新的道路。
总结
GRPO总结有以下创新点:
1. 组内对比机制:通过分组和组内标准化,将全局优化问题转化为局部对比问题,提升训练稳定性。
2. 计算轻量化:省略优势函数和剪切机制,减少计算量和超参数依赖。
3. 对齐任务优化:专为语言模型对齐设计,通过组内对比直接学习人类偏好,减少有害输出或错误推理。
GRPO作为一种新兴的强化学习算法,其潜力不仅限于数学推理任务。随着研究的深入,GRPO有望在更多复杂任务中展现出其优势,例如自然语言理解、对话生成等领域。此外,其高效的计算特性也为在资源受限的环境下应用RLHF提供了新的可能性。
GRPO的引入为强化学习算法的发展注入了新的活力。它不仅解决了PPO在计算资源和内存消耗上的局限性,还为LLM的微调和对齐提供了更高效的解决方案。未来,随着技术的不断演进,GRPO有望在更多领域大放异彩。
内容来源:IF实验室

















 967
967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









