 Model Context Protocol (MCP)全面解析
Model Context Protocol (MCP)全面解析





目录
- 摘要
- MCP理论
- MCP快速开始
- fastmcp2.x
- Quickstart快速开始
- FastMCP 命令行工具(CLI)
- Server组件
- 基础知识
- 核心组件
- 高级功能
- MCP 上下文(Context)
- 代理服务器(Proxy Servers)
- 服务器组合(Server Composition)
- 资源前缀格式(Resource Prefix Formats)
- 用户引导输入(User Elicitation)
- 服务器日志记录(Server Logging)
- **进度报告(Progress Reporting)**
- LLM 采样
- MCP 中间件(MCP Middleware)
- Authentication
- FAQ
摘要
Model Context Protocol(MCP,模型上下文协议)是由 Anthropic 于 2024 年 11 月推出的一项开放标准,旨在解决大型语言模型(LLMs)与外部工具和数据源集成的复杂性问题。在 MCP 出现之前,开发者通常需要为每个数据源或工具编写定制的连接器,导致集成工作繁琐且难以维护。(维基百科,自由的百科全书, Wikipedia)
MCP 的核心理念是提供一个统一的通信协议,使得 LLMs 能够通过标准化的方式访问外部资源、调用工具函数,并利用预设提示模板来增强其功能。该协议基于 JSON-RPC 2.0,支持多种通信方式,包括本地的标准输入输出(stdio)和网络传输(如 HTTP 和 Server-Sent Events)。(维基百科,自由的百科全书, Wikipedia)
自发布以来,MCP 得到了广泛的支持和应用。例如,开发者可以通过 MCP 让 AI 助手直接访问 GitHub 仓库,执行代码检索和提交操作;或连接企业内部的数据库,实现实时数据查询和分析。目前,已有多家知名公司和开源项目采用 MCP,包括 OpenAI、Google DeepMind、Replit 和 Sourcegraph 等。(全栈开发网, Wikipedia)
MCP 的出现标志着 AI 系统向更高效、可扩展和标准化方向发展的重要一步,为构建更智能、灵活的 AI 应用奠定了坚实的基础。(维基百科,自由的百科全书)
MCP理论
MCP 是一个开放协议,用于标准化应用程序向大语言模型(LLMs)提供上下文的方式。
可以将 MCP 想象成 AI 应用中的 USB-C 接口。就像 USB-C 提供了一个标准化的方式,让设备可以连接各种外设和配件一样,MCP 提供了一个统一的标准,使 AI 模型能够连接到不同的数据源和工具。
为什么选择 MCP?
MCP 帮助你在 LLM 之上构建智能代理和复杂的工作流。由于 LLM 通常需要集成数据和工具,MCP 提供了以下优势:
- 越来越多的预构建集成,可供你的 LLM 直接连接使用
- 在不同的 LLM 提供商和厂商之间灵活切换的能力
- 实现数据在你自有基础设施内安全使用的最佳实践
通用架构:
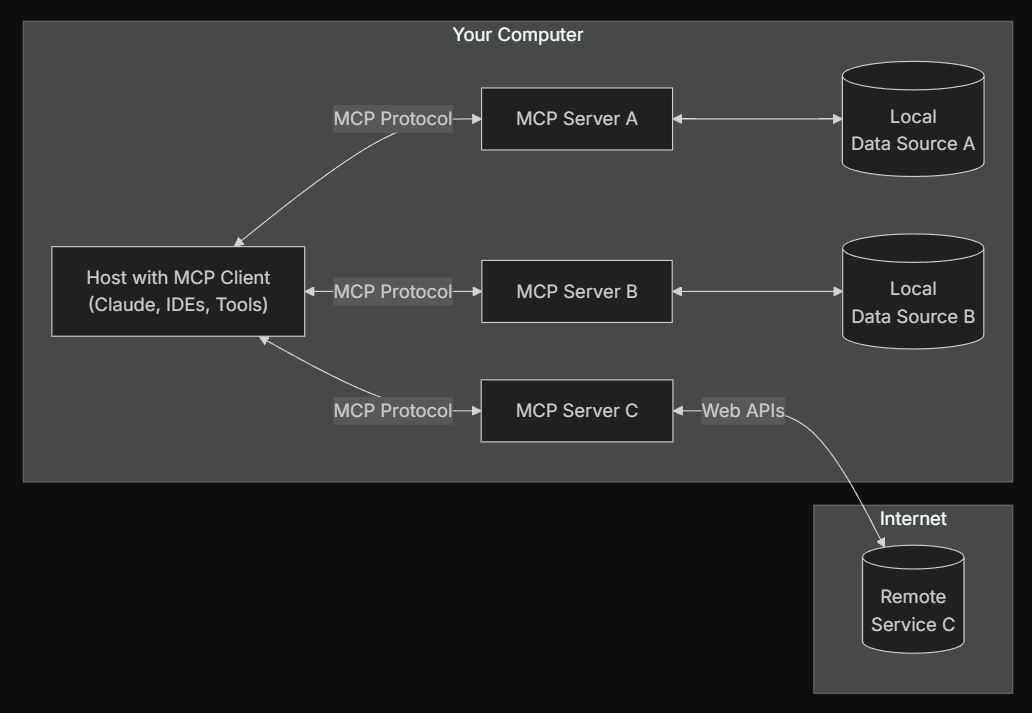
从本质上讲,MCP 采用的是一种客户端-服务器架构,其中一个宿主应用可以连接多个服务器:
- MCP 宿主(MCP Hosts):如 Claude Desktop、集成开发环境(IDEs)或其他希望通过 MCP 访问数据的 AI 工具
- MCP 客户端(MCP Clients):协议客户端,负责与每个服务器建立 1:1 的连接
- MCP 服务器(MCP Servers):轻量级程序,每个服务器通过标准化的 Model Context Protocol 提供特定功能
- 本地数据源(Local Data Sources):如计算机上的文件、数据库和服务,MCP 服务器可以安全地访问这些资源
- 远程服务(Remote Services):可通过互联网访问的外部系统(例如通过 API 提供服务),MCP 服务器可以与其建立连接
假设你正在使用支持 MCP(Model Context Protocol)的 AI 应用(如 Claude Desktop)询问“明天天气怎么样?”时,整个请求的处理流程如下:
-
用户输入请求
你在 Claude Desktop 中输入:“明天天气怎么样?” -
LLM 解析意图并生成函数调用
Claude 的语言模型(LLM)解析你的自然语言请求,识别出需要获取天气预报的信息。它生成一个结构化的函数调用请求,例如:{ "method": "get-forecast", "arguments": { "location": "Osaka", "date": "2025-05-06" } } -
MCP 客户端转发请求
Claude Desktop 内置的 MCP 客户端接收到这个函数调用请求,并通过 MCP 协议将其转发给已连接的 MCP 服务器。 -
MCP 服务器处理请求
MCP 服务器是一个轻量级程序,专门处理特定功能。在本例中,它提供了一个名为get-forecast的工具,用于获取天气预报。服务器接收到请求后,调用相应的天气 API(如 OpenWeatherMap)获取大阪市 2025 年 5 月 6 日的天气预报数据。 -
MCP 服务器返回响应
MCP 服务器将获取到的天气信息封装成响应,返回给 MCP 客户端。例如:{ "forecast": "2025年5月6日,大阪市多云,最高气温22°C,最低气温15°C,有小雨。" } -
LLM 生成自然语言回复
Claude 的语言模型接收到天气信息后,将其转化为自然语言回复,例如:“明天大阪市多云,最高气温22°C,最低气温15°C,有小雨。” -
用户收到回复
最终,你在 Claude Desktop 中看到 AI 的回复,完成整个请求流程。
MCP的作用
上文提到,MCP定义了应用程序和 AI 模型之间交换上下文信息的方式。
这就使得开发者能够以一致的方式将各种数据源、工具和功能连接到 AI 模型,就像 USB-C 让不同设备能够通过相同的接口连接一样。MCP 的目标是创建一个通用标准,使 AI 应用程序的开发和集成变得更加简单和统一。
想象一下没有 MCP 之前我们会怎么做?
我们可能会人工从数据库中筛选或者使用工具检索可能需要的信息,手动的粘贴到 prompt 中。随着我们要解决的问题越来越复杂,手工把信息引入到 prompt 中会变得越来越困难。
为了克服手工 prompt 的局限性,许多 LLM 平台(如 OpenAI、Google)引入了 function call 功能。这一机制允许模型在需要时调用预定义的函数来获取数据或执行操作,显著提升了自动化水平。
但是 function call 也有其局限性,不同 LLM 平台的 function call API 实现差异较大。例如,OpenAI 的函数调用方式与 Google 的不兼容,开发者在切换模型时需要重写代码,增加了适配成本。再比如,虽然许多 LLM 提供商都采用了类似的 JSON schema 来定义函数调用,但在具体实现上仍存在一些关键差异。
-
OpenAI:使用符合 OpenAPI JSON schema 的结构,函数定义包含
name、description和parameters等字段。(DEV Community) -
Anthropic Claude:采用类似的结构,但参数定义字段为
input_schema,而不是 OpenAI 的parameters。(Superface: Connect AI agents) -
Cohere Command-R:使用
parameter_definitions字段,并在每个参数中显式指定是否为必需项,而不是使用单独的required数组。(DEV Community) -
Google Gemini:遵循 OpenAPI JSON schema,但在请求结构上有所不同,例如使用
function_declarations来包装函数,并在tool_config中指定函数调用配置。(Medium)
这些差异意味着,开发者在从一个平台切换到另一个平台时,可能需要调整函数定义的结构,以确保兼容性。除此之外,还有安全性,交互性等问题。
-
安全性:研究表明,LLM 的函数调用功能可能被滥用,导致执行未经授权的操作。例如,攻击者可能通过精心设计的输入诱导模型调用敏感函数,如删除用户账户等。
-
交互性:早期的实现中,模型通常在每次交互中只能调用一个函数,这限制了多步骤工作流的实现。虽然一些平台已经开始支持并行或多函数调用,但仍需开发者手动协调函数之间的依赖关系。(mikelev.in)
API 就像一扇扇独立的门——每扇门都有各自的钥匙和规则
MCP 传输机制 Stdio 与 SSE
Model Context Protocol (MCP) 支持两种主要的传输机制,用于 Cline 和 MCP 服务器之间的通信:标准输入/输出 (STDIO) 和服务器发送事件 (SSE)。每种机制都有其独特的特点、优势和适用场景。
STDIO
STDIO 传输在本地机器上运行,并通过标准输入/输出流进行通信:
- 客户端 (Cline) 将 MCP 服务器作为子进程启动
- 通信通过进程流进行:客户端写入服务器的 STDIN,服务器通过 STDOUT 响应
- 每条消息以换行符分隔
- 消息格式为 JSON-RPC 2.0
客户端 服务器
| |
|<---- JSON消息 ----->| (通过STDIN)
| | (处理请求)
|<---- JSON消息 ------| (通过STDOUT)
| |
STDIO 特性:
- 本地性:与 Cline 在同一台机器上运行
- 性能:非常低的延迟和开销(不涉及网络栈)
- 简单性:无需网络配置的直接进程通信
- 关系:客户端和服务器之间是一对一关系
- 安全性:由于没有网络暴露,因此本质上更安全
STDIO 传输适用于:
- 在同一机器上运行的本地集成和工具
- 安全敏感操作
- 低延迟需求
- 单客户端场景(每个服务器一个 Cline 实例)
- 命令行工具或 IDE 扩展
SSE 传输
服务器发送事件 (SSE) 传输在远程服务器上运行,并通过 HTTP/HTTPS 进行通信:
- 客户端 (Cline) 通过 HTTP GET 请求连接到服务器的 SSE 端点
- 这建立了一个持久连接,服务器可以通过该连接向客户端推送事件
- 对于客户端到服务器的通信,客户端向单独的端点发出 HTTP POST 请求
- 通信通过两个通道进行:
- 事件流 (GET):服务器到客户端的更新
- 消息端点 (POST):客户端到服务器的请求
客户端 服务器
| |
|---- HTTP GET /events ----------->| (建立 SSE 连接)
|<---- SSE 事件流 --------------| (持久连接)
| |
|---- HTTP POST /message -------->| (客户端请求)
|<---- 带响应的 SSE 事件 ---------| (服务器响应)
| |
SSE 特性
- 远程访问:可以托管在与您的 Cline 实例不同的机器上
- 可扩展性:可以同时处理多个客户端连接
- 协议:通过标准 HTTP 工作(不需要特殊协议)
- 持久性:为服务器到客户端的消息维持持久连接
- 认证:可以使用标准 HTTP 认证机制
SSE 传输更适合:
- 跨网络的远程访问
- 多客户端场景
- 公共服务
- 许多用户需要访问的集中式工具
- 与 Web 服务集成
部署模式
MCP 支持两种主要的传输方式:STDIO 与 SSE,它们决定了服务器的部署模式——是本地运行,还是作为远程服务托管运行。
🖥️ STDIO:本地部署模型
STDIO 模式下,MCP 服务作为 子进程 与客户端运行在 同一台机器,适合本地模型接入场景。
✅ 特点:
- 安装:每台用户机器都需要安装服务器(例如通过 pip、npm、pkg)
- 分发:需要为不同平台打包安装器(Windows/macOS/Linux)
- 更新:每台设备需要手动或自动更新
- 资源占用:使用本地 CPU、内存、磁盘资源
- 权限控制:继承本地文件系统的访问权限
- 系统集成:方便访问文件、运行 shell 命令、控制本地服务等
- 生命周期:随着客户端进程一起启动与销毁
- 依赖管理:服务所需依赖必须安装在用户的本地环境
📌 示例:
本地文件搜索工具:
- 安装在用户机器
- 直接访问本地磁盘
- 用户点击时自动调用
- 不需要网络
- 与前端一起打包或通过包管理器安装
☁️ SSE:托管部署模型
SSE 模式通过 HTTP 网络通信,允许 MCP 服务运行在远程服务器、容器或云平台上,适合集中管理和多用户共享场景。
✅ 特点:
- 安装:仅需在服务端部署一次
- 分发:一个服务支持多个客户端连接
- 更新:服务端统一更新即生效
- 资源使用:使用远程服务器资源
- 权限控制:使用认证/授权机制(如 Token、OAuth)
- 集成能力:访问受控远程资源(如数据库、API)
- 运行模式:常驻后台服务,持续运行
- 依赖管理:集中在服务端维护依赖,客户端无需关心
📌 示例:
数据库查询工具:
- 运行在远程服务器
- 使用统一配置连接数据库
- 多用户共享服务
- 需要网络访问
- 可通过 Docker/K8s 等方式部署
🔁 混合部署(Hybrid)
根据需求,您还可以使用混合策略:
- STDIO + 网络访问:本地代理连接远程服务
- SSE + 本地回调:远程服务通过回调控制本地操作
- 网关模式:本地服务器代理访问多个远程功能模块
📊 STDIO vs SSE 对比表
| 考虑因素 | STDIO(本地) | SSE(托管) |
|---|---|---|
| 位置 | 本地机器 | 本地或远程服务器 |
| 客户端 | 单客户端 | 多客户端共享 |
| 性能 | 低延迟,无网络开销 | 网络延迟可能较高 |
| 部署复杂度 | 简单(无服务端) | 高(需要 HTTP 服务) |
| 安全性 | 继承本地权限,安全性好 | 需配置认证/授权 |
| 网络要求 | 无需网络 | 需要稳定网络连接 |
| 可扩展性 | 有限,受限于本机资源 | 高,可水平扩展 |
| 更新管理 | 每台机器各自更新 | 服务端集中更新 |
| 资源占用 | 使用客户端资源 | 使用服务器资源 |
| 依赖管理 | 安装在本地 | 安装在服务器端 |
模型是如何确定工具的选用的?
当你在使用支持 MCP(Model Context Protocol)的 AI 应用(如 Claude Desktop 或 Cursor)提出问题时,例如“明天天气怎么样?”,整个请求的处理流程可以分为两个主要阶段:
🧠 阶段一:LLM 决策与工具选择
-
用户输入请求
你在 Claude Desktop 中输入:“明天天气怎么样?” -
LLM 解析意图
Claude 的语言模型(LLM)解析你的自然语言请求,识别出需要获取天气预报的信息。 -
工具选择
LLM 检查可用的 MCP 工具列表,决定使用哪个工具来获取所需信息。例如,选择名为get-forecast的天气预报工具。
⚙️ 阶段二:工具调用与结果处理
-
MCP 客户端转发请求
Claude Desktop 内置的 MCP 客户端将函数调用请求通过 MCP 协议转发给相应的 MCP 服务器。 -
MCP 服务器处理请求
MCP 服务器接收到请求后,调用相应的天气 API(如 OpenWeatherMap)获取天气预报数据。 -
返回响应
MCP 服务器将获取到的天气信息封装成响应,返回给 MCP 客户端。 -
LLM 生成回复
Claude 的语言模型接收到天气信息后,将其转化为自然语言回复,例如:“明天大阪市多云,最高气温22°C,最低气温15°C,有小雨。” -
用户收到回复
最终,你在 Claude Desktop 中看到 AI 的回复,完成整个请求流程。
🔄 总结:两阶段协同工作
- 阶段一(决策层):由 LLM 解析用户意图并选择合适的工具。
- 阶段二(执行层):通过 MCP 协议调用选定的工具,获取并处理结果。
这种架构使得 AI 应用能够高效、安全地与各种数据源和工具集成,实现如获取天气信息等功能,提升用户体验。

模型如何确定该使用哪些工具?这里以 MCP 官方提供的 client example 为例。通过阅读代码,可以发现模型是通过 prompt 来确定当前有哪些工具。
async def start(self):
# 初始化所有的 mcp server
for server in self.servers:
await server.initialize()
# 获取所有的 tools 命名为 all_tools
all_tools = []
for server in self.servers:
tools = await server.list_tools()
all_tools.extend(tools)
# 将所有的 tools 的功能描述格式化成字符串供 LLM 使用
# tool.format_for_llm() 我放到了这段代码最后,方便阅读。
tools_description = "\n".join(
[tool.format_for_llm() for tool in all_tools]
)
# 这里就不简化了,以供参考,实际上就是基于 prompt 和当前所有工具的信息
# 询问 LLM(Claude) 应该使用哪些工具。
system_message = (
"You are a helpful assistant with access to these tools:\n\n"
f"{tools_description}\n"
"Choose the appropriate tool based on the user's question. "
"If no tool is needed, reply directly.\n\n"
"IMPORTANT: When you need to use a tool, you must ONLY respond with "
"the exact JSON object format below, nothing else:\n"
"{\n"
' "tool": "tool-name",\n'
' "arguments": {\n'
' "argument-name": "value"\n'
" }\n"
"}\n\n"
"After receiving a tool's response:\n"
"1. Transform the raw data into a natural, conversational response\n"
"2. Keep responses concise but informative\n"
"3. Focus on the most relevant information\n"
"4. Use appropriate context from the user's question\n"
"5. Avoid simply repeating the raw data\n\n"
"Please use only the tools that are explicitly defined above."
)
messages = [{"role": "system", "content": system_message}]
...
class Tool:
"""Represents a tool with its properties and formatting."""
def __init__(
self, name: str, description: str, input_schema: dict[str, Any]
) -> None:
self.name: str = name
self.description: str = description
self.input_schema: dict[str, Any] = input_schema
def format_for_llm(self) -> str:
"""Format tool information for LLM.
Returns:
A formatted string describing the tool.
"""
args_desc = []
if "properties" in self.input_schema:
for param_name, param_info in self.input_schema["properties"].items():
arg_desc = (
f"- {param_name}: {param_info.get('description', 'No description')}"
)
if param_name in self.input_schema.get("required", []):
arg_desc += " (required)"
args_desc.append(arg_desc)
return f"""
Tool: {self.name}
Description: {self.description}
Arguments:
{chr(10).join(args_desc)}
"""
"""
那 tool 的描述和代码中的 input_schema 是从哪里来的呢?通过进一步分析 MCP 的 Python SDK 源代码可以发现:大部分情况下,当使用装饰器 @mcp.tool() 来装饰函数时,对应的 name 和 description 等其实直接源自用户定义函数的函数名以及函数的 docstring 等。
@classmethod
def from_function(
cls,
fn: Callable,
name: str | None = None,
description: str | None = None,
context_kwarg: str | None = None,
) -> "Tool":
"""Create a Tool from a function."""
func_name = name or fn.__name__ # 获取函数名
if func_name == "<lambda>":
raise ValueError("You must provide a name for lambda functions")
func_doc = description or fn.__doc__ or ""
is_async = inspect.iscoroutinefunction(fn)
总结:模型是通过 prompt engineering,即提供所有工具的结构化描述和 few-shot 的 example 来确定该使用哪些工具。
写到这里突然想到了langChain的Tool抽象,就是为了更方便的定义工具,让LLM可以正常使用。从函数创建工具可能足以满足大多数用例,可以通过简单的 @tool 装饰器 来完成。
比如我们要生成一个加法计算的工具,我们可以这样做:
from langchain_core.tools import tool
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
# Let's inspect some of the attributes associated with the tool.
print(multiply.name)
print(multiply.description)
print(multiply.args)
multiply
Multiply two numbers.
{'a': {'title': 'A', 'type': 'integer'}, 'b': {'title': 'B', 'type': 'integer'}}
而一个tool最重要的三要素:参数,name,描述,也是通过函数签名部分可以直接拿到。那么至此,我们就可以总结出 Function calling x MCP x LangChain的关系!
Fc x MCP x LangChain
🔧 Function Calling:LLM 与外部函数的桥梁
Function Calling 是 OpenAI 于 2023 年推出的功能,允许大语言模型(LLM)生成结构化的函数调用请求。开发者可以预定义函数的名称、参数和描述,模型在解析用户输入后,生成相应的函数调用请求,开发者再根据请求调用实际的后端函数或 API。
特点:
- 结构化调用:模型生成的函数调用请求为 JSON 格式,易于解析和处理。
- 平台依赖性:不同平台(如 OpenAI、Anthropic、Google)的函数调用实现存在差异,可能导致兼容性问题。
- 适用于简单任务:适合处理单步、明确的任务调用。
🧰 LangChain:构建 LLM 应用的开发框架
LangChain 是一个用于构建由 LLM 驱动的应用程序的开发框架。它提供了工具、链(Chains)和代理(Agents)等组件,帮助开发者管理与 LLM 的交互,并集成外部工具和数据源。(优快云博客)
特点:
- 模块化设计:通过工具、链和代理等组件,支持构建复杂的应用逻辑。
- 工具集成:允许开发者将外部函数或 API 封装为工具,供代理在任务执行中调用。
- 支持多模型:兼容多种 LLM 提供商,提供统一的接口。
🔌 MCP(Model Context Protocol):标准化的模型上下文协议
MCP 是 Anthropic 提出的开放协议,旨在标准化 LLM 与外部工具和数据源的交互方式。它采用客户端-服务器架构,允许 LLM 通过 MCP 客户端与多个 MCP 服务器通信,从而访问各种工具和数据。(优快云博客)
特点:
- 标准化接口:定义统一的协议和数据格式,促进工具和数据源的互操作性。
- 多样化工具接入:支持通过 MCP 服务器接入本地或远程的工具和数据源。
- 灵活的传输协议:支持多种通信方式,如 HTTP、WebSocket、标准输入输出等。(优快云博客)
🔄 三者关系总结
| 维度 | Function Calling | LangChain | MCP(Model Context Protocol) | |
|---|---|---|---|---|
| 定位 | LLM 与外部函数的桥梁 | 构建 LLM 应用的开发框架 | 标准化的模型上下文协议 | |
| 核心功能 | 结构化函数调用 | 工具集成、链式处理、代理任务管理 | 标准化工具和数据源的接入与通信 | |
| 扩展性 | 受限于平台实现 | 高度模块化,支持自定义扩展 | 支持多种工具和数据源的接入 | |
| 适用场景 | 简单、单步的函数调用 | 构建复杂的 LLM 应用 | 构建具备上下文感知的智能代理系统 | |
| 与其他组件关系 | 可作为 LangChain 工具的调用方式 | 可集成 Function Calling 和 MCP 工具 | 可通过适配器集成到 LangChain 中 |
🧩 实际应用中的协同方式
在实际应用中,Function Calling、LangChain 和 MCP 可以协同工作,构建功能强大的 LLM 应用。例如:
-
Function Calling 与 LangChain:开发者可以将 Function Calling 定义的函数封装为 LangChain 的工具,供代理在任务执行中调用。
-
MCP 与 LangChain:通过使用如
langchain-mcp-adapters这样的适配器库,开发者可以将 MCP 服务器提供的工具和资源转换为 LangChain 可用的格式,实现无缝集成 。(优快云博客) -
综合应用:在一个复杂的 LLM 应用中,LangChain 作为框架,集成了通过 Function Calling 定义的函数和通过 MCP 接入的工具,代理根据任务需求调用相应的工具,完成多步骤的任务执行。
说到协同就涉及到传统的开发范式和MCP下的开发范式了:
在传统的开发模式中,工具函数通常被直接集成在应用程序的代码库中,作为内部函数存在。而在 MCP 架构中,工具被定义在 MCP 服务器中,并通过标准化的接口向 MCP 客户端(如 Claude Desktop、Cursor 等)暴露。这种设计允许 LLM(大语言模型)通过 MCP 客户端调用这些外部工具,实现与外部系统的交互、数据处理等功能。
具体而言,MCP 工具的定义包括:
MCP 客户端可以通过 tools/list 接口获取可用工具列表,并通过 tools/call 接口调用特定工具。 (首页)
传统的工具集成方式通常将工具函数直接嵌入到应用程序中,这种方式的特点是:
- 紧耦合:工具函数与应用程序代码紧密集成,修改或替换工具可能需要更改应用程序代码。
- 扩展性差:添加新工具或修改现有工具可能涉及到应用程序的重新部署。
而 MCP 的外部化机制具有以下优势:
- 模块化:工具作为独立服务存在,便于开发、测试和部署。
- 灵活性:可以根据需要动态添加、修改或移除工具,而无需修改主应用程序。
- 可扩展性:支持多种通信协议(如 HTTP、WebSocket 等),便于与不同系统集成。
以 mcp_function_call_server 项目为例,该项目实现了一个兼容 MCP 协议的工具服务器,提供了如 Web 搜索、天气查询等功能。这些工具被定义在服务器的 tools/ 目录中,并通过 MCP 协议向外部暴露。LLM 应用程序可以通过 MCP 客户端调用这些工具,实现相应的功能。 (MCP)
同时langChain也提供了langchain_mcp_adapters用于连接MCP Server将远程的服务转为本地的Tool:
from langgraph.prebuilt import create_react_agent
from langchain_openai import ChatOpenAI
from langchain_mcp_adapters.client import MultiServerMCPClient
import asyncio
async def main():
async with MultiServerMCPClient(
{
"weather": {
# make sure you start your weather server on port 8000
"url": "http://localhost:8990/sse",
"transport": "sse",
}
}
) as client:
avTools = client.get_tools()
print(avTools)
if __name__ == "__main__":
asyncio.run(main())
通过 MCP 的架构设计,工具函数被外部化为独立的服务,主应用程序通过标准化的协议与这些工具进行交互。这种方式提高了系统的模块化程度,增强了灵活性和可扩展性,适应了现代 AI 应用对动态集成和快速迭代的需求。
MCP快速开始
MCP 和 LLMs 没有直接关系,只要模型具备一定的指令遵循能力,就可以使用 MCP,这也是 MCP 区别于 Function Call 的地方,就是为了更通用。
MCP 虽然是 Anthropic 提出来的,但完全可以脱离 Claude 的环境和生态进行使用,也就是说,你既不需要用 Claude 的服务器或客户端,也不需要用 Claude 的模型或 API,可以自己写 MCP Server,可以用第三方的 Client,可以用任何一个模型进行对话和工具调用。
这里我们使用官方的python案例:
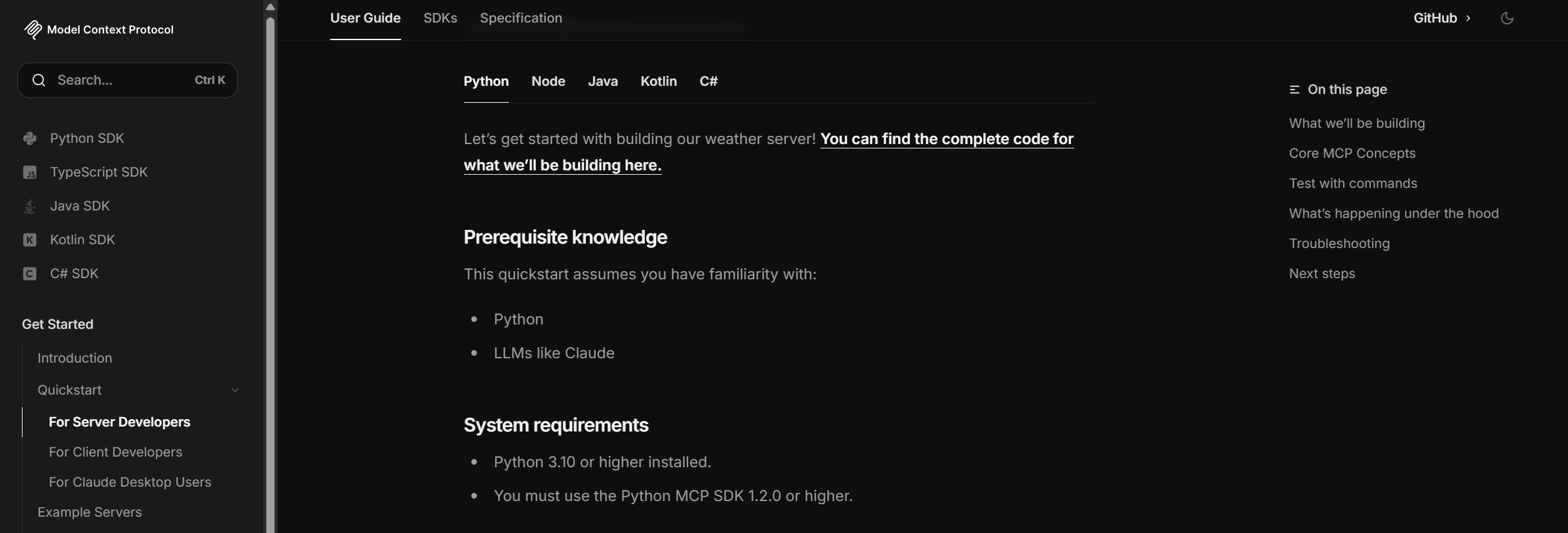
使用pip快速安装MCP的python实现:pip install mcp,然后我们可以集成一系列操作到app中,比如物联网设备的操作,网络请求web search,数据库查询操作,宿主机操作…
除此之外还需要:uv工具,uv是一个Python依赖管理工具,可以通过pip install uv来安装!
from mcp.server.fastmcp import FastMCP
# Initialize FastMCP server
mcp_app = FastMCP("weather")
@mcp_app.tool()
async def get_forecast(latitude: float, longitude: float) -> str:
"""Get weather forecast for a location.
Args:
latitude: Latitude of the location
longitude: Longitude of the location
"""
return f"--{latitude}°--{longitude}°--的温度是: 37°C"
@mcp_app.tool()
def read_file(file_path: str) -> str:
"""
读取指定路径的文件内容。
Args:
file_path: 文件的完整路径
Returns:
文件的内容
"""
with open(file_path, 'r', encoding='utf-8') as file:
return file.read()
@mcp_app.tool()
def open_the_fucking_door(ip: str) -> str:
"""
打开指定ip的智能门
Args:
ip: ip地址
"""
return f"ip为:{ip}的门已打开!"
if __name__ == "__main__":
# Initialize and run the server
mcp_app.run(transport='stdio')
然后我们启动服务,如果没有node和npm可能需要提前安装:
这些命令会将 npm 的全局安装路径和缓存路径分别设置为您指定的目录:
npm config set prefix "D:\nodejs\node_global"
npm config set cache "D:\nodejs\node_cache"
验证:
npm config get prefix
npm config get cache

打开上文地址:http://127.0.0.1:6274/,就可以看到开发者模式下的看板:
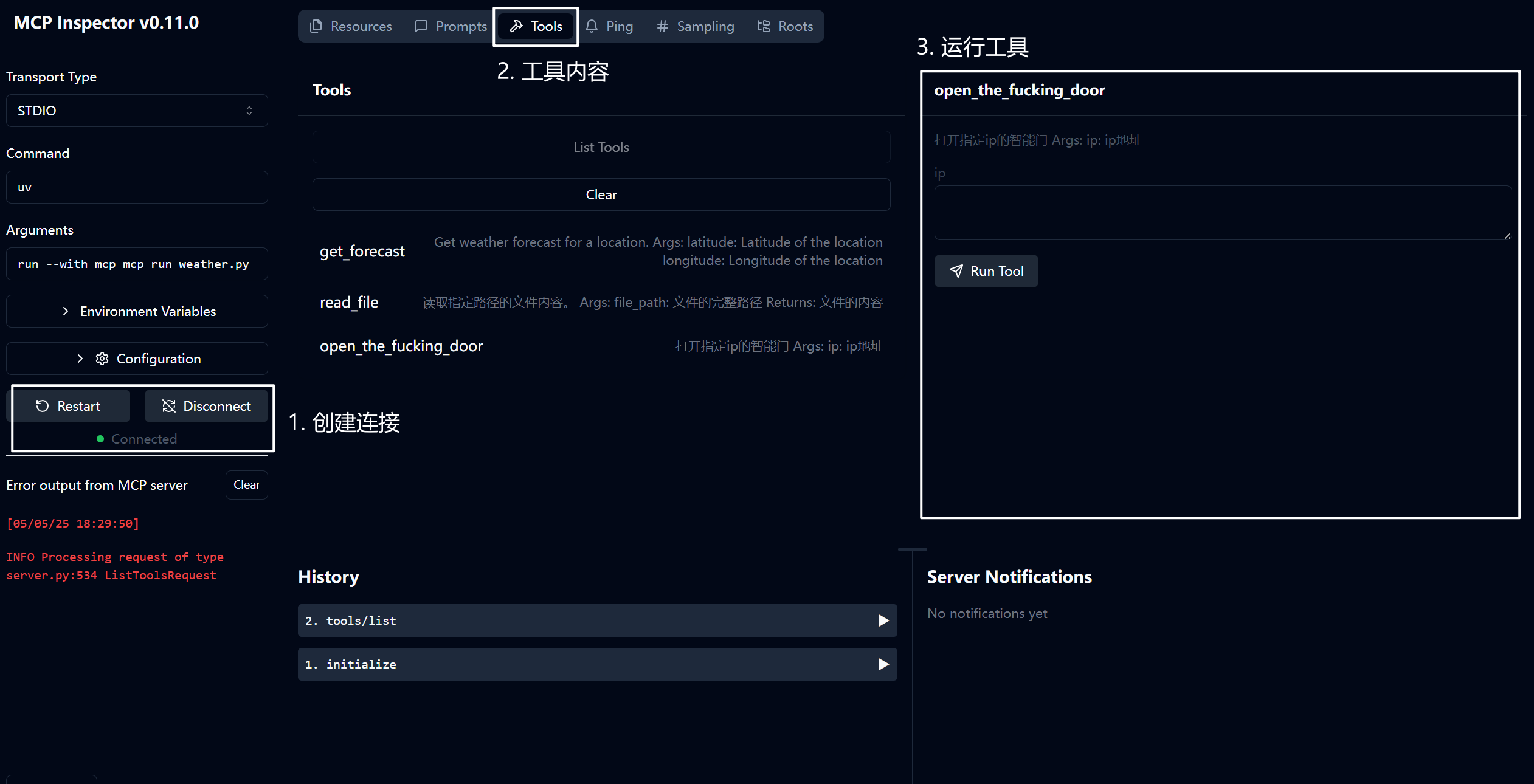
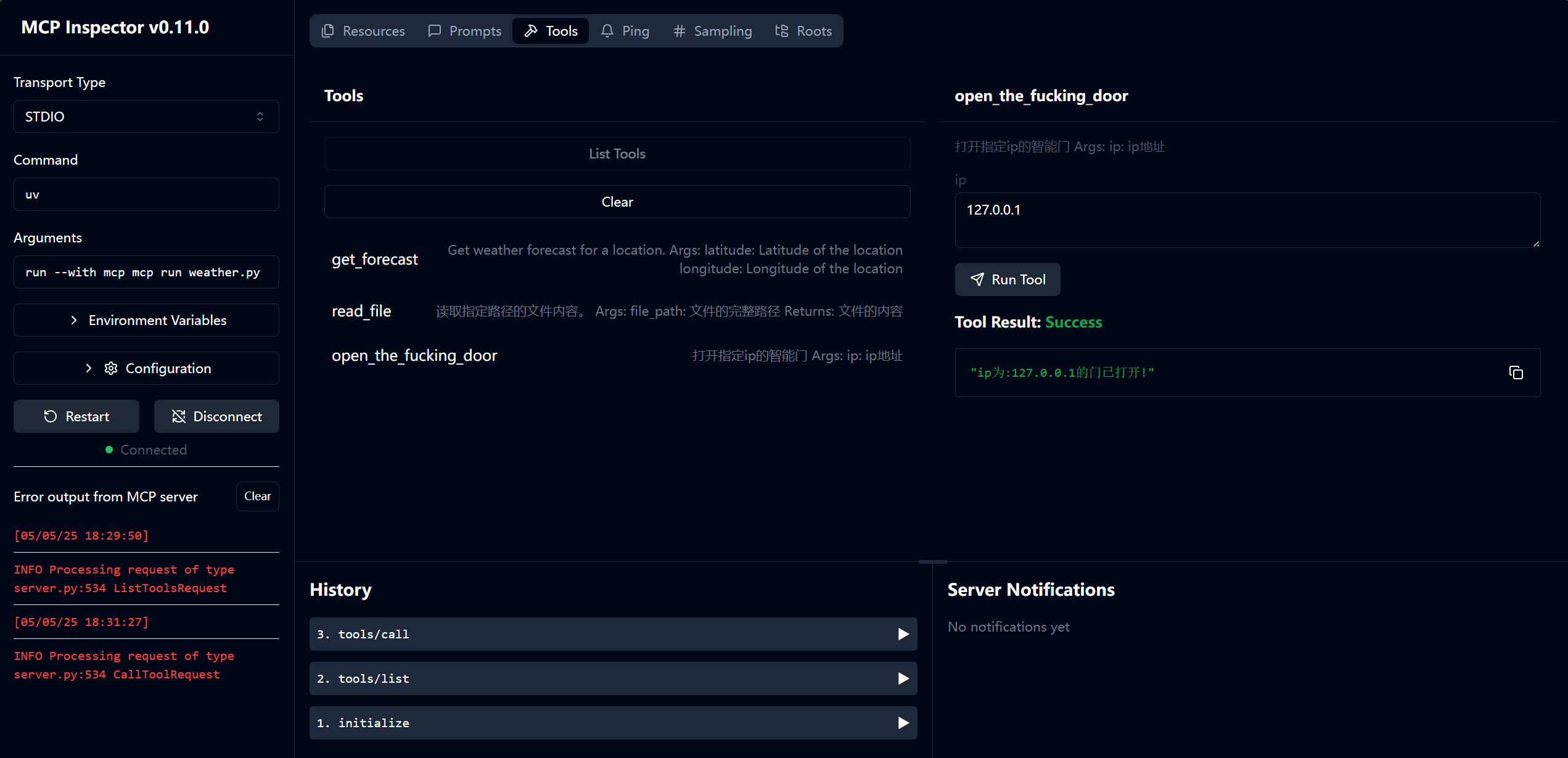
我们让其打开一扇门,可以看到右边输出了我们的debug信息!
编写客户端
MCP是典型的C/S架构! 我们作为开发者,除了要写MCP Server外,还需要编写客户端将工具|模型|用户输入糅和在一起产生一个理想的输出!
import asyncio
from typing import Optional
from contextlib import AsyncExitStack
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
class MCPClient:
def __init__(self):
# Initialize session and client objects
self.session: Optional[ClientSession] = None
self.exit_stack = AsyncExitStack()
# 暂时不初始化
self.llm = None
async def connect_to_server(self):
server_script_path = "./weather.py"
is_python = server_script_path.endswith('.py')
is_js = server_script_path.endswith('.js')
if not (is_python or is_js):
raise ValueError("Server script must be a .py or .js file")
command = "python" if is_python else "node"
server_params = StdioServerParameters(
command=command,
args=[server_script_path],
env=None
)
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))
self.stdio, self.write = stdio_transport
self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write))
await self.session.initialize()
# List available tools
response = await self.session.list_tools()
tools = response.tools
print("\nConnected to server with tools:", [tool.name for tool in tools])
async def process_query(self, query: str) -> str:
"""Process a query using Claude and available tools"""
messages = [
{
"role": "user",
"content": query
}
]
response = await self.session.list_tools()
available_tools = [{
"name": tool.name,
"description": tool.description,
"input_schema": tool.inputSchema
} for tool in response.tools]
# Initial Claude API call
response = self.anthropic.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1000,
messages=messages,
tools=available_tools
)
# Process response and handle tool calls
final_text = []
assistant_message_content = []
for content in response.content:
if content.type == 'text':
final_text.append(content.text)
assistant_message_content.append(content)
elif content.type == 'tool_use':
tool_name = content.name
tool_args = content.input
# Execute tool call
result = await self.session.call_tool(tool_name, tool_args)
final_text.append(f"[Calling tool {tool_name} with args {tool_args}]")
assistant_message_content.append(content)
messages.append({
"role": "assistant",
"content": assistant_message_content
})
messages.append({
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": content.id,
"content": result.content
}
]
})
# Get next response from Claude
response = self.anthropic.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1000,
messages=messages,
tools=available_tools
)
final_text.append(response.content[0].text)
return "\n".join(final_text)
async def chat_loop(self):
"""Run an interactive chat loop"""
print("\nMCP Client Started!")
print("Type your queries or 'quit' to exit.")
while True:
try:
query = input("\nQuery: ").strip()
if query.lower() == 'quit':
break
response = await self.process_query(query)
print("\n" + response)
except Exception as e:
print(f"\nError: {str(e)}")
async def cleanup(self):
"""Clean up resources"""
await self.exit_stack.aclose()
async def main():
client = MCPClient()
try:
await client.connect_to_server()
await client.chat_loop()
finally:
await client.cleanup()
if __name__ == "__main__":
asyncio.run(main())
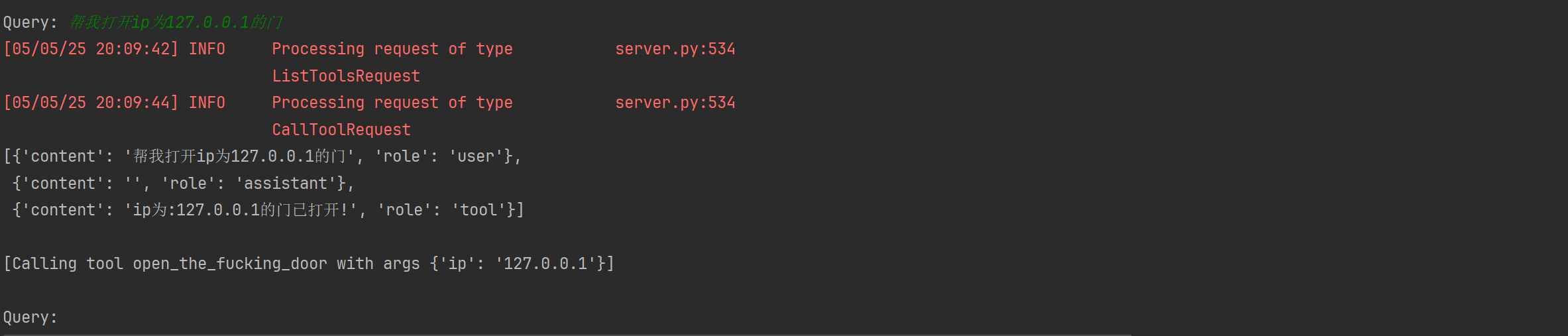
[05/05/25 19:16:40] INFO Processing request of type server.py:534
ListToolsRequest
Connected to server with tools: ['get_forecast', 'read_file', 'open_the_fucking_door']
MCP Client Started!
Type your queries or 'quit' to exit.
Query: quit
这样我们就可以连接到MCP Server,接下来就是搞定模型的问题!(MCP 和 LLMs 没有直接关系,只要模型具备一定的指令遵循能力,就可以使用 MCP)
上文我们定义的工具实际上会生成如下schema:
[{'description': 'Get weather forecast for a location.\n'
'\n'
' Args:\n'
' latitude: Latitude of the location\n'
' longitude: Longitude of the location\n'
' ',
'input_schema': {'properties': {'latitude': {'title': 'Latitude',
'type': 'number'},
'longitude': {'title': 'Longitude',
'type': 'number'}},
'required': ['latitude', 'longitude'],
'title': 'get_forecastArguments',
'type': 'object'},
'name': 'get_forecast'},
{'description': '\n'
' 读取指定路径的文件内容。\n'
'\n'
' Args:\n'
' file_path: 文件的完整路径\n'
'\n'
' Returns:\n'
' 文件的内容\n'
' ',
'input_schema': {'properties': {'file_path': {'title': 'File Path',
'type': 'string'}},
'required': ['file_path'],
'title': 'read_fileArguments',
'type': 'object'},
'name': 'read_file'},
{'description': '\n 打开指定ip的智能门\n\n Args:\n ip: ip地址\n ',
'input_schema': {'properties': {'ip': {'title': 'Ip', 'type': 'string'}},
'required': ['ip'],
'title': 'open_the_fucking_doorArguments',
'type': 'object'},
'name': 'open_the_fucking_door'}]
查询Qwen官方,我们需要的格式是这样的:
TOOLS = [
{
"type": "function",
"function": {
"name": "get_current_temperature",
"description": "Get current temperature at a location.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": 'The location to get the temperature for, in the format "City, State, Country".',
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": 'The unit to return the temperature in. Defaults to "celsius".',
},
},
"required": ["location"],
},
},
},
{
"type": "function",
"function": {
"name": "get_temperature_date",
"description": "Get temperature at a location and date.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": 'The location to get the temperature for, in the format "City, State, Country".',
},
"date": {
"type": "string",
"description": 'The date to get the temperature for, in the format "Year-Month-Day".',
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": 'The unit to return the temperature in. Defaults to "celsius".',
},
},
"required": ["location", "date"],
},
},
},
]
因此,我们改为Qwen适配的格式:
qwen_tools = [
{
"type": "function",
"function": {
"name": tool.name,
"description": tool.description,
"parameters": tool.inputSchema
}
}
for tool in response.tools
]
当我们询问经纬度为x的地区天气状况时,模型已经可以给出正确的函数调用了!
model='qwen2.5:7b' created_at='2025-05-05T11:45:09.210411Z' done=True done_reason='stop' total_duration=8104453800 load_duration=3359794600 prompt_eval_count=347 prompt_eval_duration=569000000 eval_count=108 eval_duration=3811000000 message=Message(role='assistant', content='', images=None, tool_calls=[ToolCall(function=Function(name='get_forecast', arguments={'latitude': 1, 'longitude': 1}))])
最后改造为:
import asyncio
from typing import Optional
from contextlib import AsyncExitStack
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from ollama import AsyncClient
from pprint import pprint
from ollama import ChatResponse
class MCPClient:
def __init__(self):
# Initialize session and client objects
self.session: Optional[ClientSession] = None
self.exit_stack = AsyncExitStack()
# 暂时不初始化
self.llm = AsyncClient()
async def connect_to_server(self):
server_script_path = "./weather.py"
is_python = server_script_path.endswith('.py')
is_js = server_script_path.endswith('.js')
if not (is_python or is_js):
raise ValueError("Server script must be a .py or .js file")
command = "python" if is_python else "node"
server_params = StdioServerParameters(
command=command,
args=[server_script_path],
env=None
)
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))
self.stdio, self.write = stdio_transport
self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write))
await self.session.initialize()
# List available tools
response = await self.session.list_tools()
tools = response.tools
print("\nConnected to server with tools:", [tool.name for tool in tools])
async def process_query(self, query: str) -> str:
"""Process a query using Claude and available tools"""
messages = [
{
"role": "user",
"content": query
}
]
response = await self.session.list_tools()
qwen_tools = [
{
"type": "function",
"function": {
"name": tool.name,
"description": tool.description,
"parameters": tool.inputSchema
}
}
for tool in response.tools
]
ollama_response: ChatResponse = await self.llm.chat(
model="qwen2.5:7b", messages=messages, tools=qwen_tools
)
# Process response and handle tool calls
final_text = []
# 得到对话内容
message = ollama_response.message
messages.append({
"content": message.content,
"role": message.role
})
# 函数调用
for t in message.tool_calls or []:
fn = t.function
result = await self.session.call_tool(fn.name, fn.arguments)
final_text.append(f"[Calling tool {fn.name} with args {fn.arguments}]")
messages.append({
"role": "tool",
"content": result.content[0].text,
})
pprint(messages)
return "\n".join(final_text)
async def chat_loop(self):
"""Run an interactive chat loop"""
print("\nMCP Client Started!")
print("Type your queries or 'quit' to exit.")
while True:
try:
query = input("\nQuery: ").strip()
if query.lower() == 'quit':
break
response = await self.process_query(query)
print("\n" + response)
except Exception as e:
print(f"\nError: {str(e)}")
async def cleanup(self):
"""Clean up resources"""
await self.exit_stack.aclose()
async def main():
client = MCPClient()
try:
await client.connect_to_server()
await client.chat_loop()
finally:
await client.cleanup()
if __name__ == "__main__":
asyncio.run(main())
基于golang的mcp
目前官方没有给出对golang的实现,不过你可以在awesome-mcp-servers项目中找到基于go的SDK,如foxy-contexts、mcp-go、mcp-golang、当前这些库使用的golang版本均比较高,使用的时候需要注意下,目前,MCP 的 Golang 实现主要由 mark3labs/mcp-go 提供。这个库为开发者提供了一套完整的工具,用于创建和管理 MCP Server。它支持工具定义、参数处理、工具调用等功能,并且提供了丰富的配置选项和日志记录功能。
以https://github.com/mark3labs/mcp-go为例,下载:go get github.com/mark3labs/mcp-go
package main
import (
"context"
"errors"
"fmt"
"github.com/mark3labs/mcp-go/mcp"
"github.com/mark3labs/mcp-go/server"
)
func main() {
// Create a new MCP server
s := server.NewMCPServer(
"Calculator Demo",
"1.0.0",
server.WithResourceCapabilities(true, true),
server.WithLogging(),
server.WithRecovery(),
)
// Add a calculator tool
calculatorTool := mcp.NewTool("calculate",
mcp.WithDescription("Perform basic arithmetic operations"),
mcp.WithString("operation",
mcp.Required(),
mcp.Description("The operation to perform (add, subtract, multiply, divide)"),
mcp.Enum("add", "subtract", "multiply", "divide"),
),
mcp.WithNumber("x",
mcp.Required(),
mcp.Description("First number"),
),
mcp.WithNumber("y",
mcp.Required(),
mcp.Description("Second number"),
),
)
// Add the calculator handler
s.AddTool(calculatorTool, func(ctx context.Context, request mcp.CallToolRequest) (*mcp.CallToolResult, error) {
op := request.Params.Arguments["operation"].(string)
x := request.Params.Arguments["x"].(float64)
y := request.Params.Arguments["y"].(float64)
var result float64
switch op {
case "add":
result = x + y
case "subtract":
result = x - y
case "multiply":
result = x * y
case "divide":
if y == 0 {
return mcp.NewToolResultError("cannot divide by zero"), nil
}
result = x / y
}
return mcp.NewToolResultText(fmt.Sprintf("%.2f", result)), nil
})
// Start the server
if err := server.ServeStdio(s); err != nil {
fmt.Printf("Server error: %v\n", err)
}
}
在实现 MCP Server 后,需要将其配置到客户端插件中。以下是一个在 Windows 系统中配置cline插件的 MCP Server 的示例 JSON 文件:
{
"mcpServers": {
"culculate_server": {
"command": "C:\\Users\\Administrator\\go\\bin\\calculator.exe",
"args": [
],
"env": {
"GOPATH": "C:\\Users\\Administrator\\go",
"GOMODCACHE": "C:\\Users\\Administrator\\go\\pkg\\mod"
}
}
}
}
配置完成后,你可以通过对话框向大语言模型提问,例如计算 89989 + 4378247 的结果。大语言模型会自动调用 MCP Server 来完成计算任务,并返回结果。
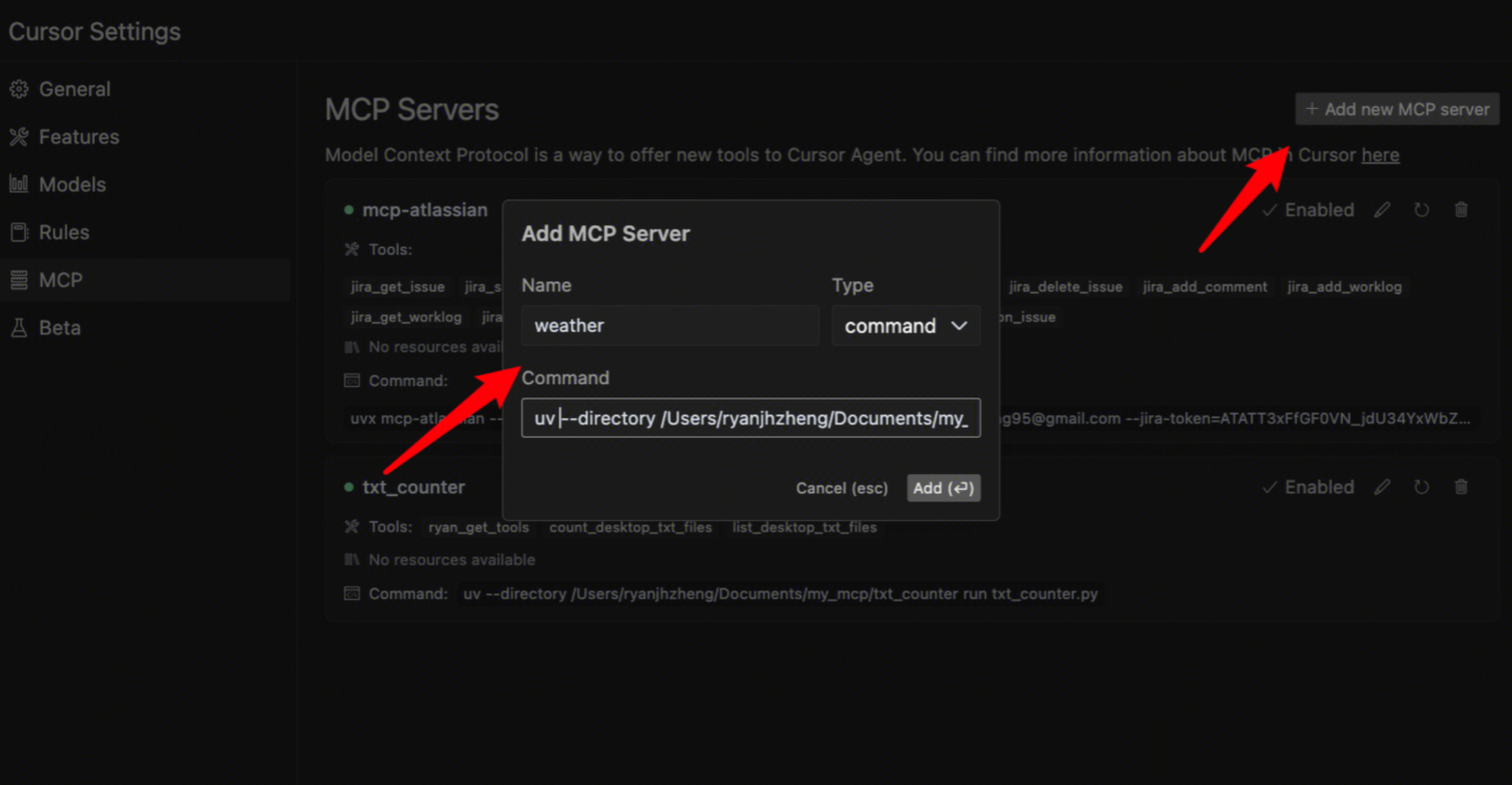
除此之外,也可以通过一些支持 MCP Server 的客户端(AI代码编辑器)进行调试,比如Cursor,cline。
比如上面的python代码可以配置到Cursor:
uv --directory /Users/ryanjhzheng/Documents/my_mcp/weather run weather.py
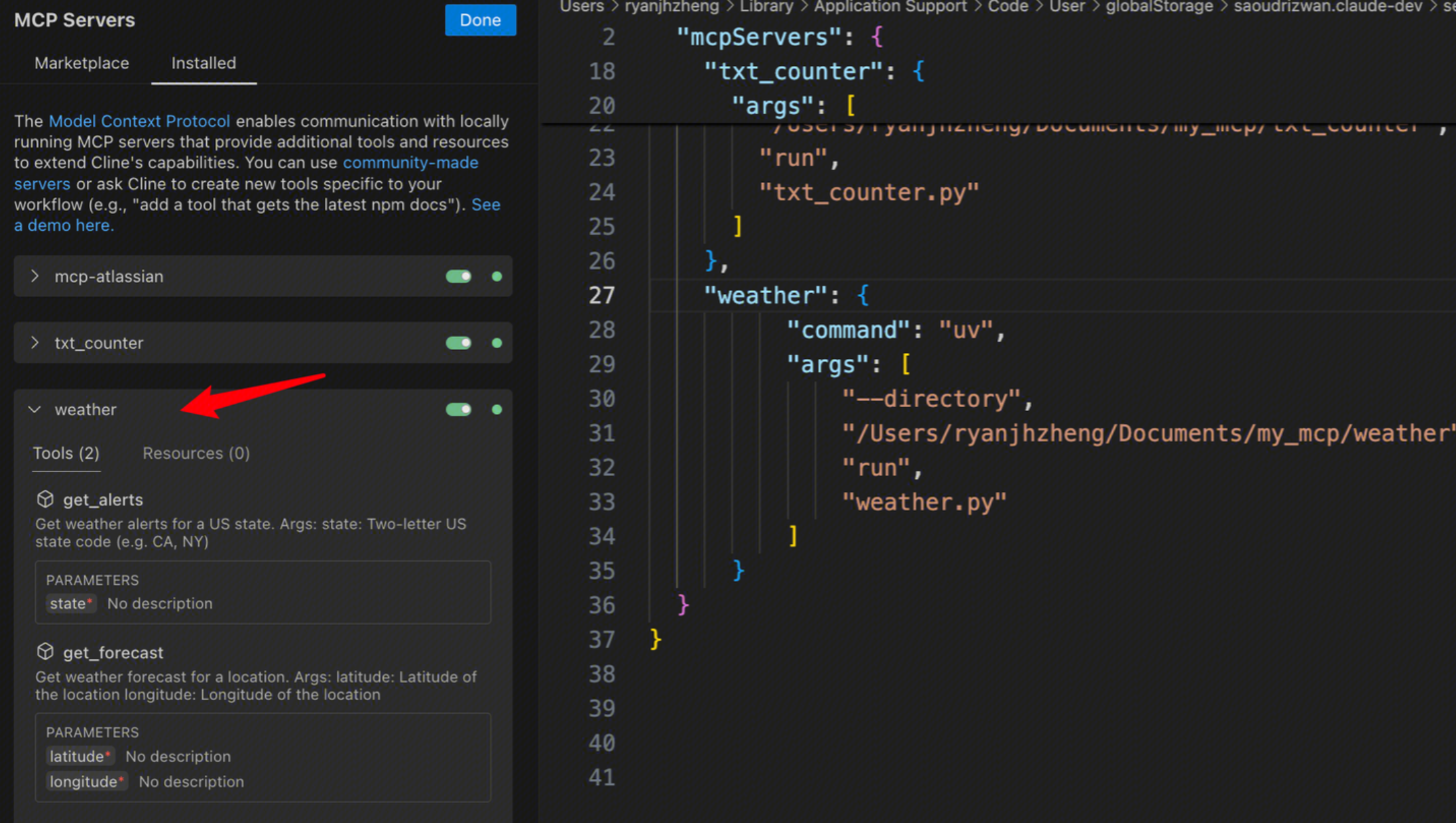
cline则需要添加配置文件:
{
"mcpServers": {
"weather": {
"command": "uv",
"args": [
"--directory",
"/ABSOLUTE/PATH/TO/PARENT/FOLDER/weather",
"run",
"weather.py"
]
}
}
}
fastmcp2.x
FastMCP 是与模型上下文协议(MCP)配套使用的标准框架。FastMCP 1.0 已在 2024 年并入官方 MCP Python SDK。
而 FastMCP 2.0 是当前在维护的版本,提供了完整工具集以支持 MCP 生态系统的构建与交互。
FastMCP 2.0 的功能远远超出 MCP 协议规范本身,目标是为产品落地提供最简单的路径。这些功能包括:
- 部署支持
- 鉴权机制
- 客户端库
- 服务器代理与组合
- 基于 REST API 自动生成服务
- 动态工具重写
- 内置测试工具
- 各类平台集成
什么是 MCP?
模型上下文协议(Model Context Protocol,简称 MCP)让你可以构建以安全标准化方式将数据与功能暴露给 LLM 应用的服务器。它常被比喻为 AI 的 “USB-C 接口”,为大语言模型统一提供可调用的资源。你也可以将它理解为专为 LLM 交互设计的 API。
一个 MCP 服务器可以:
- 通过 Resources(资源)暴露数据(类似于 GET 接口,作用是将信息加载到 LLM 上下文中)
- 通过 Tools(工具)提供功能(类似 POST 接口,用于执行代码或产生副作用)
- 通过 Prompts(提示模板)定义交互模式(用于复用的 LLM 提示)
FastMCP 提供了构建、管理、交互上述元素的高级 Python 接口。
尽管 MCP 协议本身非常强大,但实现起来会涉及大量样板代码:服务器搭建、协议处理器、内容类型管理、错误处理等。而 FastMCP 帮你封装了所有协议细节和服务器管理流程,你只需专注于构建有价值的工具。在大多数情况下,只需装饰一个函数即可完成功能注册。
FastMCP 2.0 不仅仅是协议实现框架,更是一个完整的平台。它提供:
- 客户端库
- 认证系统
- 部署工具
- 与主流 AI 平台集成
- 测试框架
- 面向生产的基础设施模式
FastMCP 的目标是:
🚀 快速:高层接口,减少代码量,加快开发速度
🍀 简单:构建 MCP 服务几乎无需样板代码
🐍 Pythonic:自然贴合 Python 开发者的习惯
🔍 完整:涵盖从开发到生产的全方位解决方案
Quickstart快速开始
安装 FastMCP
推荐使用 uv 来安装和管理 FastMCP。如果你计划在项目中使用 FastMCP,可以通过以下命令将其添加为依赖项:
uv add fastmcp
或者,你也可以直接使用 pip 或 uv pip 安装:
uv pip install fastmcp
你可以运行以下命令,验证 FastMCP 是否安装成功:
fastmcp version
你应该会看到类似如下输出:
$ fastmcp version
FastMCP version: 0.4.2.dev41+ga077727.d20250410
MCP version: 1.6.0
Python version: 3.12.2
Platform: macOS-15.3.1-arm64-arm-64bit
FastMCP root path: ~/Developer/fastmcp
从官方 MCP SDK(FastMCP 1.0)升级到 FastMCP 2.0 通常非常简单。核心的服务端 API 兼容性很好,很多情况下,只需要将导入语句:
# 原先
# from mcp.server.fastmcp import FastMCP
# 改为
from fastmcp import FastMCP
mcp = FastMCP("My MCP Server")
在 fastmcp==2.3.0 和 mcp==1.8.0 之前,FastMCP 2.x 的 API 基本等同于官方 1.0 API。然而,随着项目的演进,这种兼容性无法完全保证。如果你在 FastMCP 2.x 中继续使用 1.0 的 API,可能会看到弃用警告。
创建一个 FastMCP 服务器
一个 FastMCP 服务器是由工具(Tools)、资源(Resources)及其他 MCP 组件组成的集合。创建服务器的第一步是实例化 FastMCP 类。
创建一个新文件 my_server.py,添加以下代码:
from fastmcp import FastMCP
mcp = FastMCP("My MCP Server")
到这里你已经成功创建了一个 FastMCP 服务器,虽然它目前还啥也不会。接下来我们添加一个工具,让它有点用处。
添加一个工具(Tool)
要添加一个返回简单问候语的工具,只需定义一个函数,并使用 @mcp.tool 装饰器注册到服务器中:
from fastmcp import FastMCP
mcp = FastMCP("My MCP Server")
@mcp.tool
def greet(name: str) -> str:
return f"Hello, {name}!"
运行服务器
为了使用 Python 启动服务器,我们需要在文件末尾添加如下运行语句:
from fastmcp import FastMCP
mcp = FastMCP("My MCP Server")
@mcp.tool
def greet(name: str) -> str:
return f"Hello, {name}!"
if __name__ == "__main__":
mcp.run()
这样就可以通过以下命令运行服务器:
python my_server.py
默认会使用 stdio 作为传输方式,这是 MCP 客户端与服务器交互的标准方法。
为什么需要 if __name__ == "__main__" 这行?
在 FastMCP 生态中,这行代码不是必须的。但为了确保不同用户、客户端的行为一致,推荐保留它作为最佳实践。
与 Python 服务器交互
现在我们可以通过 python my_server.py 启动服务器,也就能像使用其他 MCP 服务器一样与它交互。
在新文件中创建一个客户端,并指向服务器文件:
my_client.py:
import asyncio
from fastmcp import Client
client = Client("my_server.py")
async def call_tool(name: str):
async with client:
result = await client.call_tool("greet", {"name": name})
print(result)
asyncio.run(call_tool("Ford"))
几点说明:
- 客户端是异步的,因此我们需要使用
asyncio.run来执行; - 使用客户端之前必须进入上下文环境(
async with client:),你可以在同一个上下文中调用多个工具。
使用 FastMCP CLI 启动服务器
你也可以通过 CLI 命令让 FastMCP 来启动服务器:
fastmcp run my_server.py:mcp
这将启动服务器,并持续运行直到手动终止。默认仍使用 stdio 协议与客户端通信。
几点说明:
- FastMCP CLI 不依赖
__main__块,即使存在也会忽略; - CLI 会寻找命令中指定的服务器对象(如上述例子中的
mcp); - 如果没有显式指定,CLI 会自动在文件中查找名为
mcp、app或server的对象。
我们上面是让客户端直接指向
my_server.py文件,FastMCP 会识别它为一个 Python MCP 服务器,并默认以python my_server.py启动。这会执行文件中的__main__代码块。
FastMCP 命令行工具(CLI)
FastMCP 提供了一个命令行界面(CLI),用于轻松运行、开发和安装 MCP 服务器。安装 FastMCP 后,CLI 会自动安装。
fastmcp --help
| 命令 | 作用 | 依赖管理方式 |
|---|---|---|
run | 直接运行一个 FastMCP 服务器 | 使用当前环境,你需要自行确保依赖已安装 |
dev | 启动带 MCP Inspector 面板的测试服务器 | 创建隔离环境,依赖需通过 --with 和/或 --with-editable 指定 |
install | 将 MCP 服务器安装到 MCP 客户端应用中 | 创建隔离环境,依赖需通过 --with 和/或 --with-editable 指定 |
inspect | 生成 MCP 服务器的 JSON 报告 | 使用当前环境,自行管理依赖 |
version | 显示 FastMCP 的版本信息 | 无依赖 |
run
直接运行 MCP 服务器,或代理一个远程服务器。
fastmcp run server.py
此命令在当前 Python 环境中运行服务器,你需要确保依赖已安装。
常用参数:
| 参数 | 简写 | 说明 |
|---|---|---|
--transport | -t | 使用的传输协议(支持:stdio、http、sse) |
--host | 使用 HTTP 传输时绑定的主机(默认:127.0.0.1) | |
--port | -p | HTTP 模式下的端口(默认:8000) |
--path | HTTP 模式下的路径(默认:/mcp/ 或 /sse/) | |
--log-level | -l | 日志等级(DEBUG、INFO、WARNING 等) |
--no-banner | 禁用启动横幅 |
服务器对象指定方式(自 v2.3.5 起支持):
server.py:自动查找名为mcp、server或app的 FastMCP 对象server.py:my_server:指定对象名http://...或https://...:连接远程服务器并作为代理运行
示例:
# 使用 HTTP 模式启动本地服务
fastmcp run server.py --transport http --port 8000
# 代理远程服务器并作为本地 stdio 服务
fastmcp run https://example.com/mcp-server
# 设置日志级别为 DEBUG
fastmcp run server.py --log-level DEBUG
dev
使用 MCP Inspector(调试面板)运行一个 MCP 服务器进行测试。
fastmcp dev server.py
该命令会在一个隔离环境中运行你的服务器,所有依赖必须通过 --with 和/或 --with-editable 明确指定。
dev 命令是为了通过 STDIO 快速测试服务器的快捷方式。当 MCP Inspector 启动后,你可能需要:
- 从传输方式下拉框中手动选择 “STDIO”
- 手动点击 连接按钮
⚠️ 此命令不支持 HTTP 或 SSE 传输测试。
🌐 如果你想测试 HTTP/SSE 模式,请手动运行服务器:
使用命令行设置传输方式:
fastmcp run server.py --transport http
或在代码中设置传输方式后运行:
python server.py # 假设你的 __main__ 块中设置了 HTTP 模式
然后,手动打开 MCP Inspector 并连接到你正在运行的服务器。
🧩 可用参数
| 参数名称 | 简写 | 说明 |
|---|---|---|
--with-editable | -e | 指定包含 pyproject.toml 的目录,以“可编辑模式”安装当前项目 |
--with | 无 | 安装额外依赖包(可重复使用多次) |
--inspector-version | 无 | 指定 MCP Inspector 的版本 |
--ui-port | 无 | MCP Inspector Web UI 的端口号 |
--server-port | 无 | MCP Inspector 代理服务器的端口号 |
示例
# 以可编辑模式运行,并附加额外依赖
fastmcp dev server.py -e . --with pandas --with matplotlib
| 用途 | 是否支持 |
|---|---|
| MCP Inspector 调试面板 | ✅ 支持 |
| STDIO 传输 | ✅ 支持 |
| HTTP / SSE 测试 | ❌ 不支持(需改用 run 命令) |
| 隔离环境 + 自动安装依赖 | ✅ 支持 |
install
✅ 新增于版本 2.10.3
用于将 MCP 服务器安装到各种 MCP 客户端应用中。目前 FastMCP 支持以下客户端:
- Claude Code:通过其内建的 MCP 管理系统进行安装
- Claude Desktop:通过修改配置文件安装
- Cursor:通过 deeplink 安装,用户需确认
- MCP JSON:生成标准 MCP JSON 配置,供手动或通用使用
示例命令:
fastmcp install claude-code server.py
fastmcp install claude-desktop server.py
fastmcp install cursor server.py
fastmcp install mcp-json server.py
⚠️ 注意事项
-
出于安全性考虑,MCP 客户端会在完全隔离的环境中运行每个服务器。
- 所有依赖必须通过
--with和/或--with-editable显式声明(遵循uv的语法) - 或者在代码中通过
dependencies参数绑定依赖
- 所有依赖必须通过
-
不应假设 MCP 服务器可以访问你的本地开发环境。
-
uv必须在系统的 PATH 中可用:-
macOS 用户可使用 Homebrew 安装:
brew install uv
-
-
install命令主要适用于本地以 STDIO 方式运行的服务器。- 如果是远程 HTTP 或 SSE 服务,应使用目标客户端的原生配置方式。
- FastMCP 的
install命令核心价值是简化本地依赖环境与隔离部署的配置。
📦 服务器对象指定方式
与 run 命令一致,支持以下两种方式:
server.py:自动查找mcp、server或app命名的 FastMCP 实例server.py:custom_name:显式指定 MCP 实例名
🧩 可用选项
| 参数名 | 简写 | 说明 |
|---|---|---|
--name | -n | 设置自定义服务器名称(默认使用 FastMCP 名称或文件名) |
--with-editable | -e | 指定包含 pyproject.toml 的目录,使用可编辑模式安装依赖 |
--with | 无 | 指定额外依赖包(可重复使用) |
--env-var | -v | 设置环境变量(格式:KEY=VALUE,可重复) |
--env-file | -f | 从 .env 文件加载环境变量 |
🧪 使用示例
# 自动检测 FastMCP 实例(查找 mcp/server/app)
fastmcp install claude-desktop server.py
# 指定 MCP 对象
fastmcp install claude-desktop server.py:my_server
# 自定义名称并安装依赖
fastmcp install claude-desktop server.py:my_server -n "My Analysis Server" --with pandas
# 安装到 Claude Code 并设置环境变量
fastmcp install claude-code server.py --env-var API_KEY=secret --env-var DEBUG=true
# 安装到 Cursor 并加载 .env 文件
fastmcp install cursor server.py --env-file .env
# 生成 MCP JSON 配置
fastmcp install mcp-json server.py --name "My Server" --with pandas
# 将 JSON 配置复制到剪贴板
fastmcp install mcp-json server.py --copy
🧾 MCP JSON 生成
mcp-json 子命令用于生成标准化的 MCP JSON 配置,适用于所有兼容 MCP 的客户端,包括:
- Claude Desktop
- VS Code
- Cursor
- 自定义工具链、CI/CD、共享配置等
生成后的 JSON 配置示例:
{
"mcpServers": {
"server-name": {
"command": "uv",
"args": [
"run",
"--with",
"fastmcp",
"fastmcp",
"run",
"/path/to/server.py"
],
"env": {
"API_KEY": "value"
}
}
}
}
专属选项:
| 参数名 | 说明 |
|---|---|
--copy | 将生成结果复制到剪贴板,而非输出到控制台 |
| 功能 | 是否支持 | 说明 |
|---|---|---|
| 安装到 Claude Code | ✅ 支持 | 通过内置管理器安装 |
| 安装到 Claude Desktop | ✅ 支持 | 修改配置文件 |
| 安装到 Cursor | ✅ 支持 | 调起客户端确认 |
| 生成 MCP JSON 配置 | ✅ 支持 | 可用于通用客户端 |
| 自动安装依赖 | ✅ 支持 | 通过 uv 配合 --with 使用 |
适用于需要快速将服务器部署到主流 LLM IDE 的用户。
inspect
✅ 新增于版本:2.9.0
用于生成关于 FastMCP 服务器的详细 JSON 报告,其中包含该服务器的工具(tools)、提示词(prompts)、资源(resources)及其能力等信息。
fastmcp inspect server.py
该命令支持与 run 和 install 命令相同的服务器对象指定格式:
# 自动识别 FastMCP 实例(查找 mcp/server/app)
fastmcp inspect server.py
# 指定特定的 FastMCP 实例对象
fastmcp inspect server.py:my_server
# 指定自定义输出路径
fastmcp inspect server.py --output analysis.json
✅ 使用 inspect 可以方便地查看 MCP 服务有哪些可调用工具、定义的提示词、资源接口等内容,适合调试和文档生成。
version
显示 FastMCP 及相关组件的版本信息:
fastmcp version
可选参数:
| 参数名 | 简写 | 说明 |
|---|---|---|
--copy | 无 | 将版本信息复制到剪贴板,而非打印到控制台 |
✅ 使用 version 可以检查当前安装的 FastMCP 版本及兼容性情况。
version
显示当前安装的 FastMCP、MCP 版本及 Python 环境信息。
fastmcp version
参数:
--copy:将版本信息复制到剪贴板
总结
| 目的 | 推荐命令 |
|---|---|
| 快速启动服务 | fastmcp run server.py |
| 调试带 UI 面板 | fastmcp dev server.py |
| 安装到客户端工具 | fastmcp install cursor server.py 等 |
| 查看服务器结构报告 | fastmcp inspect server.py |
| 查看当前版本 | fastmcp version |
Server组件
基础知识
FastMCP 服务器:用于构建 MCP 应用程序的核心类,支持工具(tools)、资源(resources)和提示词(prompts)。
FastMCP 应用的核心组件是 FastMCP 服务器类。它是你应用中所有工具、资源和提示词的主要容器,并负责与 MCP 客户端的通信。
创建服务器
实例化服务器非常简单。你通常需要为服务器提供一个名称,以便在客户端应用或日志中识别它。
from fastmcp import FastMCP
# 创建一个基础的服务器实例
mcp = FastMCP(name="MyAssistantServer")
# 你也可以添加一些说明,指导如何与服务器交互
mcp_with_instructions = FastMCP(
name="HelpfulAssistant",
instructions="""
该服务器提供数据分析工具。
调用 get_average() 来分析数值数据。
""",
)
FastMCP 构造函数参数
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
name | str | "FastMCP" | 服务器的人类可读名称,用于识别服务器 |
instructions | str | None | 无 | 向客户端描述如何与该服务器交互的说明文字 |
lifespan | AsyncContextManager | None | 无 | 用于处理服务器启动和关闭的异步上下文管理器 |
tags | set[str] | None | 无 | 服务器的标签集 |
tools | list[Tool | Callable] | None | 无 | 要添加到服务器的工具列表,也可用函数动态添加,替代 @mcp.tool 装饰器 |
**settings | 任意类型 | 无 | 传递给 ServerSettings 的其他配置项 |
组件类型
FastMCP 服务器向客户端暴露几种类型的组件:
✅ 工具(Tools)
工具是客户端可以调用的函数,用于执行操作或访问外部系统。
@mcp.tool
def multiply(a: float, b: float) -> float:
"""将两个数相乘"""
return a * b
✅ 资源(Resources)
资源用于向客户端暴露可读的数据源。
@mcp.resource("data://config")
def get_config() -> dict:
"""提供应用配置"""
return {"theme": "dark", "version": "1.0"}
✅ 资源模板(Resource Templates)
资源模板是参数化资源,允许客户端请求特定数据。
@mcp.resource("users://{user_id}/profile")
def get_user_profile(user_id: int) -> dict:
"""根据用户 ID 获取用户资料"""
return {"id": user_id, "name": f"User {user_id}", "status": "active"}
📌 {user_id} 是从 URI 中提取的参数,并传递给函数。
✅ 提示词(Prompts)
提示词是可复用的消息模板,用于引导大语言模型(LLM)的行为。
@mcp.prompt
def analyze_data(data_points: list[float]) -> str:
"""构建一个提示词,请求对数值数据进行分析"""
formatted_data = ", ".join(str(point) for point in data_points)
return f"请分析以下数据点:{formatted_data}"
基于标签的过滤(Tag-Based Filtering)
新增于版本:2.8.0
FastMCP 支持基于标签的过滤机制,可根据配置的包含/排除标签集合,选择性地暴露组件。此功能适用于为不同环境或用户创建不同的服务器视图。
在定义组件时,可以通过 tags 参数为其添加标签:
@mcp.tool(tags={"public", "utility"})
def public_tool() -> str:
return "这是一个公开工具"
@mcp.tool(tags={"internal", "admin"})
def admin_tool() -> str:
return "这是一个仅供管理员使用的工具"
📌 过滤逻辑如下:
- 包含标签(include tags):如果指定了,只有至少包含一个匹配标签的组件才会被暴露;
- 排除标签(exclude tags):包含任意一个排除标签的组件将被过滤掉;
- 优先级(Precedence):排除标签始终优先于包含标签。
⚠️ 如果你希望某个组件永远不被暴露,可以直接对组件设置 enabled=False。
⚙️ 在创建服务器时配置过滤:
# 仅暴露带有 "public" 标签的组件
mcp = FastMCP(include_tags={"public"})
# 隐藏带有 "internal" 或 "deprecated" 标签的组件
mcp = FastMCP(exclude_tags={"internal", "deprecated"})
# 组合用法:显示带 "admin" 标签的组件,但排除 "deprecated" 的
mcp = FastMCP(include_tags={"admin"}, exclude_tags={"deprecated"})
该过滤机制适用于所有组件类型(工具、资源、资源模板和提示词),影响组件的列出与访问行为。
运行服务器
FastMCP 服务器需要一个传输机制(transport)与客户端进行通信。通常你会在 FastMCP 实例上调用 mcp.run() 方法来启动服务器,通常放在主脚本的 if __name__ == "__main__": 块中。这种写法可以确保与各种 MCP 客户端的兼容性。
# my_server.py
from fastmcp import FastMCP
mcp = FastMCP(name="MyServer")
@mcp.tool
def greet(name: str) -> str:
"""根据用户姓名打招呼。"""
return f"Hello, {name}!"
if __name__ == "__main__":
# 启动服务器,默认使用 STDIO 传输方式
mcp.run()
# 若要使用其他传输方式,例如 Streamable HTTP:
# mcp.run(transport="http", host="127.0.0.1", port=9000)
✅ FastMCP 支持的传输选项包括:
- STDIO(默认,适用于本地工具)
- Streamable HTTP(推荐用于 Web 服务)
- SSE(旧版 Web 传输,已弃用)
你也可以使用 FastMCP CLI 启动服务器。
组合服务器(Composing Servers)
新增于版本:2.2.0
FastMCP 支持通过 import_server(静态复制)和 mount(实时挂载)将多个服务器组合在一起。这样可以将大型应用拆分成模块化组件,或复用已有的服务器。
# 示例:导入子服务器
from fastmcp import FastMCP
import asyncio
main = FastMCP(name="Main")
sub = FastMCP(name="Sub")
@sub.tool
def hello():
return "hi"
# 直接挂载
main.mount(sub, prefix="sub")
代理服务器(Proxying Servers)
新增于版本:2.0.0
FastMCP 可以通过 FastMCP.as_proxy 将任意 MCP 服务器(本地或远程)作为代理使用,使你可以桥接不同的传输方式,或为已有服务器添加前端接口。例如,可以将远程的 SSE 服务器通过本地 STDIO 暴露出来,反之亦然。
代理服务器在使用“非连接式客户端”时会为每个请求自动创建新的会话,从而安全地并发处理操作。
from fastmcp import FastMCP, Client
backend = Client("http://example.com/mcp/sse")
proxy = FastMCP.as_proxy(backend, name="ProxyServer")
# 现在可以像普通 FastMCP 服务器一样使用 proxy
OpenAPI 集成
新增于版本:2.0.0
FastMCP 可以通过 FastMCP.from_openapi() 或 FastMCP.from_fastapi(),根据 OpenAPI 规范或已有的 FastAPI 应用自动生成 MCP 服务器。
这让你可以立即将现有的 API 转换为 MCP 服务器,无需手动创建工具(tool)。
import httpx
from fastmcp import FastMCP
# 从 OpenAPI 规范创建服务器
spec = httpx.get("https://api.example.com/openapi.json").json()
mcp = FastMCP.from_openapi(openapi_spec=spec, client=httpx.AsyncClient())
# 从 FastAPI 应用创建服务器
from fastapi import FastAPI
app = FastAPI()
mcp = FastMCP.from_fastapi(app=app)
服务器配置(Server Configuration)
FastMCP 服务器可以通过初始化参数、全局设置和传输层设置进行配置。
服务器专属配置(Server-Specific Configuration)
服务器专属设置在创建 FastMCP 实例时传入,用于控制服务器行为:
from fastmcp import FastMCP
# 配置服务器参数
mcp = FastMCP(
name="ConfiguredServer",
dependencies=["requests", "pandas>=2.0.0"], # 可选的依赖包列表
include_tags={"public", "api"}, # 仅暴露包含这些标签的组件
exclude_tags={"internal", "deprecated"}, # 隐藏包含这些标签的组件
on_duplicate_tools="error", # 冲突的工具注册处理策略
on_duplicate_resources="warn", # 冲突的资源注册处理策略
on_duplicate_prompts="replace", # 冲突的提示词注册处理策略
)
构造参数说明(Constructor Parameters)
dependencies
- 类型:
list[str] | None - 用于指定服务器运行所需的依赖包(支持版本号)
include_tags
- 类型:
set[str] | None - 仅暴露至少包含一个指定标签的组件
exclude_tags
- 类型:
set[str] | None - 隐藏任何包含这些标签的组件
on_duplicate_tools
-
类型:
"error" | "warn" | "replace"(默认值:"error") -
冲突的工具(tool)注册处理策略:
error:抛出错误warn:记录警告replace:用新的覆盖旧的
on_duplicate_resources
- 类型:同上(默认值:
"warn") - 冲突的资源(resource)注册处理策略
on_duplicate_prompts
- 类型:同上(默认值:
"replace") - 冲突的提示词(prompt)注册处理策略
以下是你提供内容的中文翻译:
全局设置(Global Settings)
全局设置会影响所有 FastMCP 服务器,可通过环境变量(以 FASTMCP_ 为前缀)或 .env 文件进行配置:
import fastmcp
# 访问全局设置
print(fastmcp.settings.log_level) # 默认值: "INFO"
print(fastmcp.settings.mask_error_details) # 默认值: False
print(fastmcp.settings.resource_prefix_format) # 默认值: "path"
常见的全局设置包括:
- log_level:日志等级(可选值:“DEBUG”、“INFO”、“WARNING”、“ERROR”、“CRITICAL”),通过
FASTMCP_LOG_LEVEL设置 - mask_error_details:是否向客户端隐藏详细错误信息,使用
FASTMCP_MASK_ERROR_DETAILS设置 - resource_prefix_format:资源前缀格式(“path” 或 “protocol”),通过
FASTMCP_RESOURCE_PREFIX_FORMAT设置
传输层配置(Transport-Specific Configuration)
传输设置在运行服务器时提供,用于控制网络行为:
# 使用 mcp.run 配置传输方式
mcp.run(
transport="http",
host="0.0.0.0", # 绑定所有网络接口
port=9000, # 自定义端口
log_level="DEBUG", # 覆盖全局日志等级
)
# 或用于异步方式运行
await mcp.run_async(
transport="http",
host="127.0.0.1",
port=8080,
)
设置全局配置(Setting Global Configuration)
FastMCP 全局设置可通过设置环境变量完成,变量需以 FASTMCP_ 为前缀:
# 配置 FastMCP 的全局行为
export FASTMCP_LOG_LEVEL=DEBUG
export FASTMCP_MASK_ERROR_DETAILS=True
export FASTMCP_RESOURCE_PREFIX_FORMAT=protocol
自定义工具序列化(Custom Tool Serialization)
新增于版本 2.2.7
默认情况下,当工具的返回值需要转换为文本时,FastMCP 会将其序列化为 JSON。你可以通过在创建服务器时提供 tool_serializer 函数,来自定义这一行为:
import yaml
from fastmcp import FastMCP
# 定义一个自定义序列化函数,将字典格式化为 YAML
def yaml_serializer(data):
return yaml.dump(data, sort_keys=False)
# 创建带有自定义序列化器的服务器
mcp = FastMCP(name="MyServer", tool_serializer=yaml_serializer)
@mcp.tool
def get_config():
"""以 YAML 格式返回配置。"""
return {"api_key": "abc123", "debug": True, "rate_limit": 100}
该序列化函数接收任意数据对象,并返回其字符串形式。它会应用于所有非字符串的工具返回值。若工具本身已返回字符串,则不会调用该序列化器。
自定义序列化器在以下情况下非常有用:
- 希望以特定格式输出数据(如 YAML 或自定义格式)
- 控制序列化行为(如缩进、键排序等)
- 在返回给客户端前添加元数据或转换数据
如果自定义序列化函数抛出异常,FastMCP 会自动回退使用默认的 JSON 序列化方式,以避免导致服务器崩溃。
运行你的 FastMCP 服务
FastMCP 服务器可以根据应用需求以不同方式运行,从本地命令行工具到持久化 Web 服务。本指南将重点介绍通过各种传输协议运行服务器的主要方法:STDIO、可流式 HTTP、SSE。
你可以在 Python 中通过调用 FastMCP 实例的 run() 方法来直接运行服务器。
为保证兼容性,推荐将 run() 方法放入 if __name__ == "__main__": 块中,这样确保该脚本仅在直接执行时启动服务,而非被导入时启动。
示例:my_server.py
from fastmcp import FastMCP
mcp = FastMCP(name="MyServer")
@mcp.tool
def hello(name: str) -> str:
return f"Hello, {name}!"
if __name__ == "__main__":
mcp.run()
执行 python my_server.py 即可启动 MCP 服务器。
你可以通过给 run() 传递 transport 和其他关键参数,配置不同的传输方式以满足不同场景需求。
FastMCP 也提供命令行工具,无需修改源码即可运行服务:
fastmcp run server.py
⚠️ 注意:使用
fastmcp run时,会忽略if __name__ == "__main__"块,而是寻找名为mcp、server或app的FastMCP对象,并直接调用其run()方法。
你可以通过 CLI 覆盖源码中指定的传输方式,适合测试或无需更改代码地部署新方法:
fastmcp run server.py --transport sse --port 9000
开发或测试中,也可使用 dev 命令并配合 MCP Inspector 工具运行:
fastmcp dev server.py
当服务支持命令行参数(如通过 argparse 或 click),可在命令末尾添加 -- 来传递参数:
fastmcp run config_server.py -- --config config.json
fastmcp run database_server.py -- --database-path /tmp/db.sqlite --debug
传输协议选项对比
| 传输方式 | 使用场景 | 推荐情况 |
|---|---|---|
| STDIO | 本地工具、命令行脚本、Claude Desktop 等客户端 | 最适合本地工具和客户端启动服务 |
| 可流式 HTTP | Web 服务部署、微服务、对外公开的 MCP 接口 | 推荐用于 Web 服务部署 |
| SSE | 基于 SSE 的旧服务部署 | 已弃用,建议改用 HTTP |
STDIO 是本地运行 MCP 服务的默认传输方式,适用于本地工具、脚本、或 Claude Desktop 这类客户端。
from fastmcp import FastMCP
mcp = FastMCP()
if __name__ == "__main__":
mcp.run(transport="stdio")
通常你无需手动运行服务进程,客户端会为每次会话自动启动新服务。
可流式 HTTP(推荐)
新增于 v2.3.0
这是推荐的 Web 部署方式。默认绑定地址为 127.0.0.1:8000,路径为 /mcp/:
from fastmcp import FastMCP
mcp = FastMCP()
if __name__ == "__main__":
mcp.run(transport="http")
import asyncio
from fastmcp import Client
async def example():
async with Client("http://127.0.0.1:8000/mcp/") as client:
await client.ping()
if __name__ == "__main__":
asyncio.run(example())
自定义端口、路径等:
mcp.run(
transport="http",
host="127.0.0.1",
port=4200,
path="/my-custom-path",
log_level="debug"
)
import asyncio
from fastmcp import Client
async def example():
async with Client("http://127.0.0.1:4200/my-custom-path") as client:
await client.ping()
if __name__ == "__main__":
asyncio.run(example())
可使用别名 "streamable-http" 替代 "http"。
这里的 path 指的是服务器在 HTTP 服务中绑定的 URL 路径前缀。也就是说,当你通过浏览器或客户端访问你的 MCP 服务器时,URL 中需要包含这个路径部分。
举个例子:
- 你设置
path="/my-custom-path" - 服务器地址是
http://127.0.0.1:4200
那么客户端访问时的完整 URL 就是 http://127.0.0.1:4200/my-custom-path,FastMCP 会监听这个路径下的请求。
这个配置主要用于区分不同服务或避免路径冲突,尤其在同一台机器上运行多个 HTTP 服务时非常有用。
SSE(已弃用)
虽然仍支持,但不推荐新项目使用。使用方法如下:
mcp.run(transport="sse")
也可配置端口、路径等:
mcp.run(
transport="sse",
host="127.0.0.1",
port=4200,
path="/my-custom-sse-path",
log_level="debug"
)
异步运行(Async)
如果你在异步上下文中运行应用,应使用 run_async() 方法:
from fastmcp import FastMCP
import asyncio
mcp = FastMCP(name="MyServer")
@mcp.tool
def hello(name: str) -> str:
return f"Hello, {name}!"
async def main():
await mcp.run_async(transport="http")
if __name__ == "__main__":
asyncio.run(main())
run() 方法不能在异步函数(async def)内部调用,因为它内部会创建自己的异步事件循环(async event loop)。
如果你在异步函数中调用 run(),将会报错,提示事件循环已在运行。
正确用法:
- 在 异步函数 中使用
run_async(); - 在 同步上下文 中使用
run()。
此外,run() 和 run_async() 都支持相同的传输参数(如 transport、host、port 等),因此上面的所有示例都适用于这两种方法。
你也可以为你的 FastMCP 服务器添加自定义的 Web 路由,这些路由会和 MCP 端点一起暴露。
实现方法是使用 @custom_route 装饰器。
需要注意的是,这种方式的灵活性不如完整的 ASGI 框架,但对于为独立服务器添加简单的接口(例如健康检查)非常有用。
from fastmcp import FastMCP
from starlette.requests import Request
from starlette.responses import PlainTextResponse
mcp = FastMCP("MyServer")
@mcp.custom_route("/health", methods=["GET"])
async def health_check(request: Request) -> PlainTextResponse:
return PlainTextResponse("OK")
if __name__ == "__main__":
mcp.run()
核心组件
Tools
将函数暴露为可供 MCP 客户端执行的功能。
工具是构建 LLM 与外部系统交互的核心组件。它们允许 LLM 执行代码、访问训练数据之外的信息或系统。在 FastMCP 中,工具就是通过 MCP 协议暴露给大模型的 Python 函数。
在 FastMCP 中,工具会将普通的 Python 函数转换为 LLM 在对话中可调用的能力。当 LLM 决定使用某个工具时:
- 它会根据工具的参数定义发送一个调用请求;
- FastMCP 会根据函数签名验证这些参数;
- 你的函数会使用验证后的参数被执行;
- 执行结果会返回给 LLM,由其用于进一步回答。
这使得 LLM 可以执行如:
- 查询数据库
- 调用 API
- 做数学计算
- 读取或写入文件
等任务,从而将其能力扩展到训练数据之外。
@tool 装饰器
创建工具只需使用 @mcp.tool 装饰一个 Python 函数即可:
from fastmcp import FastMCP
mcp = FastMCP(name="CalculatorServer")
@mcp.tool
def add(a: int, b: int) -> int:
"""Adds two integer numbers together."""
return a + b
当该工具被注册后,FastMCP 会自动:
- 使用函数名
add作为工具名; - 使用函数的文档字符串作为工具说明;
- 根据参数及类型注解自动生成输入参数 schema;
- 处理参数校验与错误报告。
你的函数如何定义,将决定该工具在 LLM 客户端中的展示与行为。
注意:不支持带有
*args或**kwargs的函数作为工具。这是因为 FastMCP 必须为 MCP 协议生成完整的参数 schema,而可变参数无法满足这一要求。
虽然 FastMCP 会自动推断工具的名称和描述,但你也可以通过 @mcp.tool 装饰器的参数覆盖这些默认值,并添加更多元数据:
@mcp.tool(
name="find_products", # 自定义工具名
description="Search the product catalog with optional category filtering.", # 自定义描述
tags={"catalog", "search"}, # 可选标签,用于分类/过滤
)
def search_products_implementation(query: str, category: str | None = None) -> list[dict]:
"""内部函数描述(如果上面有 description,此处将被忽略)"""
print(f"Searching for '{query}' in category '{category}'")
return [{"id": 2, "name": "Another Product"}]
@tool 装饰器参数说明:
| 参数 | 类型 | 说明 |
|---|---|---|
name | str | None | MCP 中暴露的工具名(默认使用函数名) |
description | str | None | MCP 中显示的工具说明(若提供,则忽略函数 docstring) |
tags | set[str] | None | 工具分类标签,便于客户端过滤与组织 |
enabled | bool,默认:True | 是否启用此工具(详见“禁用工具”) |
exclude_args | list[str] | None | 要从 schema 中隐藏的参数名(详见“排除参数”) |
annotations | ToolAnnotations | dict | None | 用于添加附加元信息的对象或字典 |
ToolAnnotations 的常见字段:
| 字段 | 类型 | 说明 |
|---|---|---|
title | str | None | 可读性强的工具标题 |
readOnlyHint | bool | None | 若为 true,表示工具不修改外部环境 |
destructiveHint | bool | None | 若为 true,表示工具可能对环境造成破坏性更改 |
idempotentHint | bool | None | 若为 true,表示重复调用工具不会产生额外副作用 |
openWorldHint | bool | None | 若为 true,工具可能与“开放世界”的外部实体交互;若为 false,工具的交互域是封闭的 |
工具参数(Tool Parameters)
📌 类型注解(Type Annotations)
参数的类型注解是 FastMCP 工具功能正常运行的基础,它们能够:
- 告诉 LLM 每个参数期望的数据类型;
- 让 FastMCP 能验证客户端传入的数据;
- 生成符合 MCP 协议的准确 JSON Schema。
你应使用标准的 Python 类型注解来定义参数类型:
@mcp.tool
def analyze_text(
text: str,
max_tokens: int = 100,
language: str | None = None
) -> dict:
"""分析所提供的文本。"""
# 实现...
📌 参数元数据(Parameter Metadata)
你可以通过 Pydantic 的 Field 类结合 Annotated 提供更多参数元信息。这种方式更现代,推荐使用。
from typing import Annotated
from pydantic import Field
from typing import Literal
@mcp.tool
def process_image(
image_url: Annotated[str, Field(description="要处理的图片 URL")],
resize: Annotated[bool, Field(description="是否调整图像大小")] = False,
width: Annotated[int, Field(description="目标宽度(像素)", ge=1, le=2000)] = 800,
format: Annotated[
Literal["jpeg", "png", "webp"],
Field(description="输出图片格式")
] = "jpeg"
) -> dict:
"""处理图像,可选调整大小。"""
# 实现...
你也可以将 Field 用作默认值,不过推荐使用 Annotated 的方式。
@mcp.tool
def search_database(
query: str = Field(description="搜索关键词"),
limit: int = Field(10, description="返回的最大结果数", ge=1, le=100)
) -> list:
"""使用给定关键词搜索数据库。"""
# 实现...
✅ Field 支持的常用属性:
description: 给 LLM 显示的参数描述;ge,gt,le,lt: 数值上下限;min_length,max_length: 字符串/集合长度限制;pattern: 正则表达式;default: 默认值。
📌 支持的类型(Supported Types)
FastMCP 支持各种类型注解,包括所有 Pydantic 类型:
| 类型类别 | 示例 | 说明 |
|---|---|---|
| 基本类型 | int, float, str | 简单标量类型 |
| 二进制数据 | bytes | 处理文件/图片等 |
| 日期时间 | datetime, date | 时间类型 |
| 集合类型 | list[str], dict | 列表、字典、集合 |
| 可选类型 | float | None | 参数可为 null 或省略 |
| 联合类型 | str | int | 多种类型选择 |
| 约束类型 | Literal["A", "B"] | 限定值域 |
| 路径类型 | Path | 文件路径 |
| UUID | UUID | 唯一标识符 |
| 数据模型 | UserData(Pydantic) | 结构化复杂对象 |
📌 可选参数(Optional Arguments)
FastMCP 遵循 Python 的标准函数参数约定:
- 没有默认值:为必填参数;
- 有默认值:为可选参数。
@mcp.tool
def search_products(
query: str, # 必需
max_results: int = 10, # 可选
sort_by: str = "relevance", # 可选
category: str | None = None # 可选,可为 None
) -> list[dict]:
"""搜索产品目录。"""
# 实现...
上述示例中,
query参数是必填的,其余参数若不传则使用默认值。
排除参数(Excluding Arguments)
2.6.0 版本新增功能
你可以从工具的参数 schema 中排除某些参数,使其不暴露给 LLM。这对于在运行时由服务器注入的参数(例如 state、user_id 或 credentials)非常有用,不应暴露给 LLM 或客户端。只有具有默认值的参数才能被排除,尝试排除必填参数会导致报错。
示例:
@mcp.tool(
name="get_user_details",
exclude_args=["user_id"]
)
def get_user_details(user_id: str = None) -> str:
# user_id 会由服务器在运行时注入,而不是由 LLM 提供
...
配置后,user_id 将不会出现在工具的参数 schema 中,但仍可以在运行时由服务器或框架设置。
禁用工具(Disabling Tools)
2.8.0 版本新增功能
你可以通过启用或禁用工具来控制其可见性和可用性。这对于功能开关控制、维护模式或根据不同客户端动态变更工具集非常有用。被禁用的工具不会出现在 list_tools 返回的可用工具列表中,调用禁用的工具会报错“Unknown tool”(未知工具),行为等同于该工具不存在。
默认情况下,所有工具都是启用的。你可以在定义时通过 enabled 参数禁用工具:
@mcp.tool(enabled=False)
def maintenance_tool():
"""此工具当前正在维护中。"""
return "This tool is disabled."
你也可以在程序运行时动态启用或禁用工具:
@mcp.tool
def dynamic_tool():
return "I am a dynamic tool."
# 禁用后再启用
dynamic_tool.disable()
dynamic_tool.enable()
异步工具(Async Tools)
FastMCP 同时支持标准函数(def)和异步函数(async def)作为工具。
# 同步工具(适合 CPU 密集型或快速任务)
@mcp.tool
def calculate_distance(lat1: float, lon1: float, lat2: float, lon2: float) -> float:
"""计算两个坐标之间的距离。"""
return 42.5
# 异步工具(适合 I/O 密集型任务)
@mcp.tool
async def fetch_weather(city: str) -> dict:
"""获取某城市当前天气状况。"""
async with aiohttp.ClientSession() as session:
async with session.get(f"https://api.example.com/weather/{city}") as response:
response.raise_for_status()
return await response.json()
当你的工具需要进行外部系统操作(如网络请求、数据库查询、文件访问等),建议使用 async def,以保持服务器响应性,避免阻塞事件循环。
返回值(Return Values)
FastMCP 工具可以返回两种互补格式的数据:传统内容块(如文本、图片)和结构化输出(可被机器解析的 JSON)。
当你为返回值添加类型注解时,FastMCP 会自动生成输出模式(schema),用于验证结构化数据,并让客户端能够将结果反序列化为 Python 对象。
理解这三个概念如何协作:
- 返回值(Return Values):你的 Python 函数返回的内容,决定了内容块和结构化数据的值。
- 结构化输出(Structured Outputs):伴随传统内容一起发送的 JSON 数据,供机器处理。
- 输出模式(Output Schemas):用于描述和验证结构化输出格式的 JSON Schema 定义。
内容块(Content Blocks)
FastMCP 会自动将工具的返回值转换为合适的 MCP 内容块:
| Python 返回类型 | 转换后的内容块类型 |
|---|---|
str | 作为 TextContent 发送 |
bytes | base64 编码后作为 EmbeddedResource 内的 BlobResourceContents 发送 |
fastmcp.utilities.types.Image | 作为 ImageContent 发送 |
fastmcp.utilities.types.Audio | 作为 AudioContent 发送 |
fastmcp.utilities.types.File | base64 编码后作为 EmbeddedResource 发送 |
list[上述类型之一] | 每个元素都会被相应转换 |
None | 结果为空响应 |
结构化输出(Structured Output)
2.10.0 版本新增功能
2025 年 6 月 18 日的 MCP 规范更新引入了结构化内容的概念,这是一种全新的工具返回数据的方式。结构化内容是一段 JSON 数据,会与传统内容一起发送。
当你的工具返回的数据具有 JSON 对象表示时,FastMCP 会自动创建结构化输出,提供可供机器读取的 JSON 数据,客户端可以直接将其反序列化为 Python 对象。
自动结构化输出规则:
- 对象类返回值(如 dict、Pydantic 模型、dataclass):始终生成结构化内容(即使没有输出 schema)
- 非对象返回值(如 int、str、list):仅在提供输出 schema 的情况下才生成结构化内容
- 所有返回值:总会生成传统内容块(用于兼容旧版客户端)
这使得 LLM 客户端在无需额外配置的情况下,也能接收人类可读内容 + 机器可读结构。
对象类返回值(自动结构化内容)
@mcp.tool
def get_user_data(user_id: str) -> dict:
"""不带类型注解地返回用户信息。"""
return {"name": "Alice", "age": 30, "active": True}
传统content:
"{\n \"name\": \"Alice\",\n \"age\": 30,\n \"active\": true\n}"
结构化content:
{
"name": "Alice",
"age": 30,
"active": true
}
即使没有显式类型注解,也会自动生成结构化内容。
如果你返回的是原始类型(如 int),则只有在添加了输出 schema 的情况下才生成结构化内容:
@mcp.tool
def calculate_sum(a: int, b: int):
return a + b # 仅返回传统内容,不生成结构化 JSON
传统content:
"8"
带有schema:
@mcp.tool
def calculate_sum(a: int, b: int) -> int:
"""Calculate sum with return annotation."""
return a + b # Returns 8
传统content:
"8"
结构化content:
{
"result": 8
}
复杂示例:
from dataclasses import dataclass
from fastmcp import FastMCP
mcp = FastMCP()
@dataclass
class Person:
name: str
age: int
email: str
@mcp.tool
def get_user_profile(user_id: str) -> Person:
"""Get a user's profile information."""
return Person(name="Alice", age=30, email="alice@example.com")
生成的schema:
{
"properties": {
"name": {"title": "Name", "type": "string"},
"age": {"title": "Age", "type": "integer"},
"email": {"title": "Email", "type": "string"}
},
"required": ["name", "age", "email"],
"title": "Person",
"type": "object"
}
结构化输出:
{
"name": "Alice",
"age": 30,
"email": "alice@example.com"
}
输出模式(Output Schemas)
2.10.0 版本新增功能
2025 年 6 月的 MCP 规范更新引入了输出模式(output schemas),用于描述工具的预期返回格式。
当你在函数中添加返回类型注解时,FastMCP 会自动生成对应的 JSON schema,帮助客户端验证和理解结构化数据。
原始类型包装(Primitive Type Wrapping),当返回的是原始类型(如 int、str、bool)时,FastMCP 会将其自动包装成如下格式:
@mcp.tool
def calculate_sum(a: int, b: int) -> int:
"""Add two numbers together."""
return a + b
{
"type": "object",
"properties": {
"result": {"type": "integer"}
},
"x-fastmcp-wrap-result": true
}
{
"result": 42
}
你也可以显式指定输出 schema:
@mcp.tool(output_schema={
"type": "object",
"properties": {
"data": {"type": "string"},
"metadata": {"type": "object"}
}
})
def custom_schema_tool() -> dict:
return {"data": "Hello", "metadata": {"version": "1.0"}}
支持自动生成输出模式的类型包括:基础类型、集合、联合类型、Pydantic 模型、TypedDict、dataclass 等。
⚠️ 注意事项:
- 输出 schema 必须是 JSON 对象(
"type": "object") - 如果指定了输出 schema,返回值必须符合这个 schema
- 即使没有 schema,也可以返回结构化内容(例如使用
ToolResult)
完全控制输出:ToolResult
如果你想完全控制返回的传统内容和结构化内容,可以返回一个 ToolResult 对象:
from fastmcp.tools.tool import ToolResult
@mcp.tool
def advanced_tool() -> ToolResult:
return ToolResult(
content=[TextContent(text="这是面向人类的内容")],
structured_content={"data": "value", "count": 42}
)
使用 ToolResult 的好处:
- 可以精确控制发送的内容和结构化数据
- 是否定义输出模式(schema)是可选的
- 客户端将收到内容块 + JSON 数据
如果你的返回类型无法转换为 JSON schema(例如自定义类,但未使用 Pydantic),那么输出 schema 会被忽略,但传统内容仍然可以正常使用。
错误处理(Error Handling)
新版本:2.4.1
当你的工具发生错误时,可以抛出标准的 Python 异常(如 ValueError、TypeError、FileNotFoundError,或自定义异常),也可以抛出 FastMCP 提供的 ToolError。
默认情况下,所有异常(包括详细信息)都会被记录并转换为 MCP 错误响应,返回给客户端 LLM,以帮助 LLM 识别失败原因并做出相应应对。
如果出于安全考虑希望隐藏内部错误细节,你可以:
-
✅ 使用
mask_error_details=True初始化 FastMCP 实例:mcp = FastMCP(name="SecureServer", mask_error_details=True) -
✅ 或者使用
ToolError明确指定要发送给客户端的错误信息:from fastmcp import FastMCP from fastmcp.exceptions import ToolError @mcp.tool def divide(a: float, b: float) -> float: """a 除以 b。""" if b == 0: raise ToolError("不允许除以 0。") if not isinstance(a, (int, float)) or not isinstance(b, (int, float)): raise TypeError("两个参数都必须是数字。") return a / b
若设置了
mask_error_details=True,只有ToolError的消息会暴露细节,其他异常将返回通用错误提示。
注解(Annotations)
新版本:2.2.7
FastMCP 允许你通过注解为工具添加专门的元数据。这些注解向客户端应用传达工具的行为方式,而不会占用 LLM 提示中的 token 上下文。
注解在客户端应用中有多种用途:
- 为显示目的添加用户友好的标题
- 指示工具是否会修改数据或系统
- 描述工具的安全特性(破坏性或非破坏性)
- 表明工具是否与外部系统交互
你可以通过 @mcp.tool 装饰器中的 annotations 参数为工具添加注解:
@mcp.tool(
annotations={
"title": "计算加法",
"readOnlyHint": True,
"openWorldHint": False
}
)
def calculate_sum(a: float, b: float) -> float:
"""Add two numbers together."""
return a + b
支持的标准注解:
| 注解名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
title | string | - | 工具在 UI 中显示的名称 |
readOnlyHint | boolean | false | 是否为只读工具(无状态更改) |
destructiveHint | boolean | true | 如果非只读,是否有破坏性更改 |
idempotentHint | boolean | false | 多次调用是否和一次调用效果一致 |
openWorldHint | boolean | true | 工具是否连接到外部系统 |
注解是提示性质的,仅帮助前端界面展示与交互,并不会强制实施安全策略。请准确表达工具行为以避免误导。
工具变更通知(Notifications)
新版本:2.9.1
FastMCP 会在工具被添加、移除、启用或禁用时自动发送 tools/list_changed 通知,帮助客户端实时同步工具列表,无需手动轮询。
@mcp.tool
def example_tool() -> str:
return "Hello!"
mcp.add_tool(example_tool) # 发送通知
example_tool.disable() # 发送通知
example_tool.enable() # 发送通知
mcp.remove_tool("example_tool") # 发送通知
只有在MCP 请求上下文中执行这些操作时才会发送通知(如:在某个工具内部调用)。服务器初始化期间执行这些操作不会触发通知。
客户端可监听这些通知以更新工具界面或工具列表。
这个意思是说:
-
通知触发时机有限制:只有当你在运行中的 MCP 请求过程中,比如某个工具正在被调用时,对工具进行添加、删除、启用、禁用等操作,才会触发通知发送给客户端。
-
启动时操作不触发通知:如果你在服务器刚启动初始化阶段,对工具进行类似操作(比如预先注册一些工具),这些操作不会触发通知。
-
客户端自动响应通知:客户端收到通知后,可以通过消息处理器(类似事件监听器)自动刷新它们的工具列表或更新界面,从而保证客户端显示的是最新的工具状态,无需手动刷新。
总结就是:通知机制设计成只针对“运行时动态变更”有效,帮助客户端实时同步工具变化;而初始化阶段的设置被认为是“静态配置”,不需要通知。 这样避免了初始化时的重复或无用通知,且保证客户端和服务器状态实时一致。你可以把通知看成是一种“热更新”提醒。
MCP 上下文
工具可以通过 Context 对象访问 MCP 功能,比如日志记录、读取资源或报告进度。使用时,只需在工具函数中添加一个类型标注为 Context 的参数。
示例代码:
from fastmcp import FastMCP, Context
mcp = FastMCP(name="ContextDemo")
@mcp.tool
async def process_data(data_uri: str, ctx: Context) -> dict:
"""处理资源中的数据并报告进度。"""
await ctx.info(f"正在处理来自 {data_uri} 的数据")
# 读取资源
resource = await ctx.read_resource(data_uri)
data = resource[0].content if resource else ""
# 报告进度
await ctx.report_progress(progress=50, total=100)
# 向客户端的 LLM 请求帮助示例
summary = await ctx.sample(f"用10个词总结以下内容: {data[:200]}")
await ctx.report_progress(progress=100, total=100)
return {
"length": len(data),
"summary": summary.text
}
Context 对象提供以下功能访问:
- 日志记录:
ctx.debug(),ctx.info(),ctx.warning(),ctx.error() - 进度报告:
ctx.report_progress(progress, total) - 资源访问:
ctx.read_resource(uri) - LLM 采样调用:
ctx.sample(...) - 请求信息:
ctx.request_id,ctx.client_id
参数类型详解
FastMCP 支持多种参数类型,方便你设计工具时灵活选择。
FastMCP 通常支持 Pydantic 支持作为字段的所有类型,包括所有 Pydantic 自定义类型。也就是说,你可以在工具参数中使用任何 Pydantic 能验证和解析的类型。
FastMCP 支持类型强制转换(type coercion)。当客户端发送的数据类型与期望类型不匹配时,FastMCP 会尝试转换为合适的类型。例如,如果客户端传入字符串但参数注解为 int,FastMCP 会尝试将其转换为整数;若无法转换,则返回验证错误。
内置类型
最常见的参数类型是 Python 的内置标量类型:
@mcp.tool
def process_values(
name: str, # 文本数据
count: int, # 整数
amount: float, # 浮点数
enabled: bool # 布尔值(True/False)
):
"""处理各种类型的值。"""
# 实现逻辑...
这些类型明确告诉 LLM 可接受的值类型,FastMCP 也能正确验证输入。即使客户端传了字符串 “42”,参数注解为 int 时也会被自动转换为整数。
日期和时间类型
FastMCP 支持来自 datetime 模块的多种日期和时间类型:
from datetime import datetime, date, timedelta
@mcp.tool
def process_date_time(
event_date: date, # ISO 格式日期字符串或 date 对象
event_time: datetime, # ISO 格式日期时间字符串或 datetime 对象
duration: timedelta = timedelta(hours=1) # 整数秒或 timedelta 对象
) -> str:
"""处理日期和时间信息。"""
assert isinstance(event_date, date)
assert isinstance(event_time, datetime)
assert isinstance(duration, timedelta)
return f"Event on {event_date} at {event_time} for {duration}"
datetime— 接受 ISO 格式字符串(如 “2023-04-15T14:30:00”)date— 接受 ISO 格式日期字符串(如 “2023-04-15”)timedelta— 接受整数秒数或 timedelta 对象
集合类型
FastMCP 支持所有标准 Python 集合类型:
@mcp.tool
def analyze_data(
values: list[float], # 数字列表
properties: dict[str, str], # 字符串键值对字典
unique_ids: set[int], # 唯一整数集合
coordinates: tuple[float, float], # 固定结构元组
mixed_data: dict[str, list[int]] # 嵌套集合
):
"""分析数据集合。"""
# 实现逻辑...
支持的集合类型:
list[T]— 有序序列dict[K, V]— 键值映射set[T]— 无序唯一元素集合tuple[T1, T2, ...]— 固定长度、类型可不同的序列
集合类型支持嵌套组合,符合结构的 JSON 字符串会自动解析转换为对应的 Python 集合类型。
联合和可选类型
对于允许多种类型或可选的参数:
@mcp.tool
def flexible_search(
query: str | int, # 可以是字符串或整数
filters: dict[str, str] | None = None, # 可选字典
sort_field: str | None = None # 可选字符串
):
"""支持灵活参数类型的搜索。"""
# 实现逻辑...
推荐使用现代 Python 语法 str | int 替代旧的 Union[str, int],str | None 替代 Optional[str]。
约束类型
当参数必须是预定义集合中的值时,可以使用 Literal 类型或枚举(Enum)。
字面量(Literals)
Literals 用于将参数限制为特定的一组值:
from typing import Literal
@mcp.tool
def sort_data(
data: list[float],
order: Literal["ascending", "descending"] = "ascending",
algorithm: Literal["quicksort", "mergesort", "heapsort"] = "quicksort"
):
"""使用特定选项对数据进行排序。"""
# 实现逻辑...
Literal 类型的作用:
- 在类型注解中直接指定允许的具体值
- 帮助 LLM 精确理解哪些值是可接受的
- 提供输入验证(无效值会报错)
- 为客户端创建清晰的参数结构
枚举(Enums)
对于更结构化的约束值集合,可以使用 Python 的 Enum 类:
from enum import Enum
class Color(Enum):
RED = "red"
GREEN = "green"
BLUE = "blue"
@mcp.tool
def process_image(
image_path: str,
color_filter: Color = Color.RED
):
"""使用颜色过滤器处理图像。"""
# 实现逻辑...
# color_filter 是 Color 枚举成员
使用 Enum 类型时需要注意:
- 客户端应传入枚举值(如 “red”),而不是枚举成员名(如 “RED”)
- FastMCP 会自动将字符串值转换为对应的 Enum 对象
- 你的函数实际接收到的是枚举成员(例如 Color.RED)
- 对于不在枚举中的值,会抛出验证错误
二进制数据
在工具参数中处理二进制数据有两种方式:
Bytes
@mcp.tool
def process_binary(data: bytes):
"""直接处理二进制数据。
客户端可以发送二进制字符串,会直接转换为 bytes 类型。
"""
# 使用二进制数据实现逻辑
data_length = len(data)
# ...
当你将参数标注为 bytes 时,FastMCP 会:
- 直接将原始字符串转换为 bytes
- 验证输入是否能被正确表示为 bytes
注意:FastMCP 不会自动对 base64 编码的字符串做解码。如果需要接受 base64 编码的数据,需要手动解码,如下所示。
Base64 编码字符串
from typing import Annotated
from pydantic import Field
@mcp.tool
def process_image_data(
image_data: Annotated[str, Field(description="Base64编码的图像数据")]
):
"""处理来自 base64 编码字符串的图像。
客户端预期提供 base64 编码的字符串数据。
你需要手动进行解码。
"""
import base64
binary_data = base64.b64decode(image_data)
# 处理 binary_data...
当预期客户端发送 base64 编码的二进制数据时,推荐使用此方式。
路径(Paths)
可以使用 pathlib 模块中的 Path 类型表示文件系统路径:
from pathlib import Path
@mcp.tool
def process_file(path: Path) -> str:
"""处理指定路径的文件。"""
assert isinstance(path, Path) # 路径已正确转换为 Path 对象
return f"正在处理路径 {path} 的文件"
客户端发送字符串路径时,FastMCP 会自动转换成 Path 对象。
UUID
可以使用 uuid 模块中的 UUID 类型表示唯一标识符:
import uuid
@mcp.tool
def process_item(
item_id: uuid.UUID # 字符串 UUID 或 UUID 对象
) -> str:
"""处理指定 UUID 的条目。"""
assert isinstance(item_id, uuid.UUID) # 已正确转换为 UUID 对象
return f"正在处理条目 {item_id}"
当客户端发送字符串形式的 UUID(例如 “123e4567-e89b-12d3-a456-426614174000”)时,FastMCP 会自动转换成 UUID 对象。
Pydantic 模型
对于复杂的结构化数据(带嵌套字段和验证),可以使用 Pydantic 模型:
from pydantic import BaseModel, Field
from typing import Optional
class User(BaseModel):
username: str
email: str = Field(description="用户的邮箱地址")
age: int | None = None
is_active: bool = True
@mcp.tool
def create_user(user: User):
"""在系统中创建新用户。"""
# 输入会自动根据 User 模型进行验证
# 即使输入是 JSON 字符串或字典也会自动转换
# 实现逻辑...
使用 Pydantic 模型带来的好处:
- 对复杂输入提供清晰、可自描述的结构
- 内置数据验证
- 自动生成详细的 JSON schema 供 LLM 使用
- 自动从 dict/JSON 输入转换
客户端可以用以下形式为 Pydantic 模型参数提供数据:
- JSON 对象(字符串形式)
- 具有相应结构的字典
- 嵌套的参数格式
FastMCP 通过 Pydantic 的 Field 类支持强大的参数验证,这特别有助于确保输入值满足除类型之外的特定要求。
字段也可以用在 Pydantic 模型外,为参数提供元数据和验证约束。推荐的做法是使用 Annotated 搭配 Field:
from typing import Annotated
from pydantic import Field
@mcp.tool
def analyze_metrics(
# 带范围约束的数字
count: Annotated[int, Field(ge=0, le=100)], # 0 <= count <= 100
ratio: Annotated[float, Field(gt=0, lt=1.0)], # 0 < ratio < 1.0
# 带正则和长度约束的字符串
user_id: Annotated[str, Field(
pattern=r"^[A-Z]{2}\d{4}$", # 必须匹配正则表达式
description="格式为 XX0000 的用户ID"
)],
# 带长度约束的字符串
comment: Annotated[str, Field(min_length=3, max_length=500)] = "",
# 数值约束
factor: Annotated[int, Field(multiple_of=5)] = 10, # 必须是5的倍数
):
"""用验证过的参数分析指标。"""
# 实现逻辑...
你也可以直接用 Field 作为默认值,虽然推荐用 Annotated 的方式:
@mcp.tool
def validate_data(
# 值约束
age: int = Field(ge=0, lt=120), # 0 <= age < 120
# 字符串约束
email: str = Field(pattern=r"^[\w\.-]+@[\w\.-]+\.\w+$"), # 邮箱格式
# 集合约束
tags: list[str] = Field(min_length=1, max_length=10) # 1-10 个标签
):
"""带字段验证处理数据。"""
# 实现逻辑...
常见的验证选项:
| 验证选项 | 类型 | 描述 |
|---|---|---|
| ge, gt | 数字 | 大于或等于 (greater or equal) |
| le, lt | 数字 | 小于或等于 (less or equal) |
| multiple_of | 数字 | 必须是该数字的倍数 |
| min_length, max_length | 字符串、列表等 | 长度限制 |
| pattern | 字符串 | 正则表达式约束 |
| description | 任意类型 | 可读的说明(显示在 schema 中) |
当客户端发送无效数据时,FastMCP 会返回验证错误,说明该参数为什么验证失败。
服务器行为
重复工具
新增于版本:2.1.0
你可以控制 FastMCP 服务器在尝试注册多个同名工具时的行为。通过创建 FastMCP 实例时传入参数 on_duplicate_tools 来配置:
from fastmcp import FastMCP
mcp = FastMCP(
name="StrictServer",
# 配置遇到重复工具名时的行为
on_duplicate_tools="error"
)
@mcp.tool
def my_tool(): return "版本 1"
# 由于 'my_tool' 已存在且 on_duplicate_tools 设置为 "error",
# 下面这段代码会抛出 ValueError。
# @mcp.tool
# def my_tool(): return "版本 2"
重复工具的行为选项包括:
"warn"(默认):记录警告,新工具替换旧工具。"error":抛出 ValueError,阻止重复注册。"replace":静默替换已有工具。"ignore":保留原有工具,忽略新注册请求。
移除工具
新增于版本:2.3.4
你可以动态地使用 remove_tool 方法从服务器中移除工具:
from fastmcp import FastMCP
mcp = FastMCP(name="DynamicToolServer")
@mcp.tool
def calculate_sum(a: int, b: int) -> int:
"""将两个数字相加。"""
return a + b
mcp.remove_tool("calculate_sum")
资源与模板——向你的 MCP 客户端暴露数据源和动态内容生成器
资源表示 MCP 客户端可以读取的数据或文件,而资源模板则扩展了这一概念,允许客户端根据 URI 中传入的参数请求动态生成的资源。
FastMCP 简化了静态和动态资源的定义,主要通过使用 @mcp.resource 装饰器来实现。
什么是资源?
资源为 LLM 或客户端应用提供只读的数据访问。当客户端请求资源 URI 时:
- FastMCP 查找对应的资源定义。
- 如果资源是动态的(由函数定义),则执行该函数。
- 返回内容(文本、JSON、二进制数据)给客户端。
这使得 LLM 能够访问文件、数据库内容、配置或与对话相关的动态生成信息。
@resource 装饰器
定义资源最常用的方法是装饰一个 Python 函数。装饰器需要资源的唯一 URI。
import json
from fastmcp import FastMCP
mcp = FastMCP(name="DataServer")
# 基本的动态资源,返回字符串
@mcp.resource("resource://greeting")
def get_greeting() -> str:
"""提供一个简单的问候信息。"""
return "Hello from FastMCP Resources!"
# 返回 JSON 数据的资源(dict 会自动序列化)
@mcp.resource("data://config")
def get_config() -> dict:
"""以 JSON 形式提供应用配置。"""
return {
"theme": "dark",
"version": "1.2.0",
"features": ["tools", "resources"],
}
关键概念:
-
URI:
@resource的第一个参数是资源的唯一 URI(例如"resource://greeting"),客户端通过该 URI 请求数据。 -
延迟加载:被装饰的函数(如
get_greeting,get_config)仅在客户端通过resources/read明确请求该 URI 时执行。 -
推断元数据:默认情况下:
- 资源名称取自函数名(如
get_greeting)。 - 资源描述取自函数的 docstring。
- 资源名称取自函数名(如
你可以通过 @mcp.resource 装饰器的参数自定义资源属性:
from fastmcp import FastMCP
mcp = FastMCP(name="DataServer")
# 示例:指定元数据
@mcp.resource(
uri="data://app-status", # 明确的 URI(必填)
name="ApplicationStatus", # 自定义名称
description="Provides the current status of the application.", # 自定义描述
mime_type="application/json", # 明确 MIME 类型
tags={"monitoring", "status"} # 分类标签
)
def get_application_status() -> dict:
"""内部函数描述(如果上面提供了 description 则忽略此处)"""
return {"status": "ok", "uptime": 12345, "version": mcp.settings.version} # 示例返回
@resource 装饰器参数说明:
-
uri
类型:str(必填)
资源的唯一标识符。 -
name
类型:str | None
资源的人类可读名称。如果未提供,默认为函数名。 -
description
类型:str | None
资源的说明文字。如果未提供,默认为函数的 docstring。 -
mime_type
类型:str | None
指定内容类型。FastMCP 通常会自动推断默认值,如text/plain或application/json,但非文本类型最好显式指定。 -
tags
类型:set[str] | None
用于分类的一组字符串,客户端可能会用来过滤。 -
enabled
类型:bool,默认值:True
用于启用或禁用该资源。详情见“禁用资源”部分。
返回值
FastMCP 会自动将函数的返回值转换为适当的 MCP 资源内容:
- str:作为
TextResourceContents发送(默认mime_type="text/plain")。 - dict, list, pydantic.BaseModel:自动序列化为 JSON 字符串,作为
TextResourceContents发送(默认mime_type="application/json")。 - bytes:进行 Base64 编码后作为
BlobResourceContents发送。你应指定合适的mime_type(例如"image/png"、"application/octet-stream")。 - None:返回空的资源内容列表。
禁用资源
新增于版本 2.8.0
你可以通过启用或禁用资源和模板来控制其可见性和可用性。被禁用的资源不会出现在可用资源或模板列表中,尝试读取被禁用的资源会返回“Unknown resource”错误。
默认情况下,所有资源均为启用状态。你可以在创建时通过装饰器的 enabled 参数禁用资源:
@mcp.resource("data://secret", enabled=False)
def get_secret_data():
"""此资源当前被禁用。"""
return "Secret data"
你也可以在创建后通过编程方式切换资源的状态:
@mcp.resource("data://config")
def get_config():
return {"version": 1}
# 禁用并重新启用资源
get_config.disable()
get_config.enable()
访问 MCP 上下文
新增于版本 2.2.5
资源和资源模板可以通过 Context 对象访问更多 MCP 信息和功能。要访问它,只需在资源函数中添加一个带有 Context 类型注解的参数:
from fastmcp import FastMCP, Context
mcp = FastMCP(name="DataServer")
@mcp.resource("resource://system-status")
async def get_system_status(ctx: Context) -> dict:
"""提供系统状态信息。"""
return {
"status": "operational",
"request_id": ctx.request_id
}
@mcp.resource("resource://{name}/details")
async def get_details(name: str, ctx: Context) -> dict:
"""获取指定名称的详情。"""
return {
"name": name,
"accessed_at": ctx.request_id
}
异步资源
对于执行 I/O 操作(如读取数据库或网络)的资源函数,建议使用 async def,以避免阻塞服务器。
import aiofiles
from fastmcp import FastMCP
mcp = FastMCP(name="DataServer")
@mcp.resource("file:///app/data/important_log.txt", mime_type="text/plain")
async def read_important_log() -> str:
"""异步读取特定日志文件内容。"""
try:
async with aiofiles.open("/app/data/important_log.txt", mode="r") as f:
content = await f.read()
return content
except FileNotFoundError:
return "Log file not found."
资源类
虽然使用 @mcp.resource 适合定义动态内容,但你也可以通过 mcp.add_resource() 以及具体的 Resource 子类,直接注册预定义资源(比如静态文件或简单文本)。
from pathlib import Path
from fastmcp import FastMCP
from fastmcp.resources import FileResource, TextResource, DirectoryResource
mcp = FastMCP(name="DataServer")
# 1. 直接暴露一个静态文件
readme_path = Path("./README.md").resolve()
if readme_path.exists():
# 使用 file:// URI 方案
readme_resource = FileResource(
uri=f"file://{readme_path.as_posix()}",
path=readme_path, # 真实文件路径
name="README 文件",
description="项目的 README。",
mime_type="text/markdown",
tags={"documentation"}
)
mcp.add_resource(readme_resource)
# 2. 暴露简单预定义文本
notice_resource = TextResource(
uri="resource://notice",
name="重要通知",
text="系统维护计划在周日进行。",
tags={"notification"}
)
mcp.add_resource(notice_resource)
# 3. 使用与 URI 不同的自定义存储键
special_resource = TextResource(
uri="resource://common-notice",
name="特别通知",
text="这是一个带有自定义存储键的特别通知。",
)
mcp.add_resource(special_resource, key="resource://custom-key")
# 4. 暴露目录列表
data_dir_path = Path("./app_data").resolve()
if data_dir_path.is_dir():
data_listing_resource = DirectoryResource(
uri="resource://data-files",
path=data_dir_path, # 目录路径
name="数据目录列表",
description="列出数据目录中可用的文件。",
recursive=False # 设置为 True 列出子目录
)
mcp.add_resource(data_listing_resource) # 返回文件的 JSON 列表
常用资源类:
TextResource:用于简单字符串内容。BinaryResource:用于原始字节内容。FileResource:从本地文件路径读取内容,支持文本/二进制模式和延迟读取。HttpResource:从 HTTP(S) URL 获取内容(依赖 httpx)。DirectoryResource:列出本地目录中的文件(返回 JSON)。FunctionResource:内部类,供@mcp.resource使用。
当内容是静态或直接来源于文件/URL 时,使用这些资源类可以省去编写专门 Python 函数的麻烦。
自定义资源键
新增于版本 2.2.0
通过 mcp.add_resource() 直接添加资源时,可以选择提供自定义的存储键:
# 使用标准 URI 作为键创建资源
resource = TextResource(uri="resource://data")
mcp.add_resource(resource) # 以 "resource://data" 存储和访问
# 使用自定义键创建资源
special_resource = TextResource(uri="resource://special-data")
mcp.add_resource(special_resource, key="internal://data-v2") # 以 "internal://data-v2" 存储和访问
注意:这个自定义键参数仅在直接使用 add_resource() 时有效,通过 @resource 装饰器注册资源时无效,因为 URI 是直接明确提供的。
通知机制
新增于版本 2.9.1
当资源或模板被添加、启用或禁用时,FastMCP 会自动向连接的客户端发送 notifications/resources/list_changed 通知。这样客户端无需手动轮询,即可保持资源列表的最新状态。
@mcp.resource("data://example")
def example_resource() -> str:
return "Hello!"
# 以下操作会触发通知:
mcp.add_resource(example_resource) # 发送 resources/list_changed 通知
example_resource.disable() # 发送 resources/list_changed 通知
example_resource.enable() # 发送 resources/list_changed 通知
通知只在这些操作发生于一个活跃的 MCP 请求上下文中时发送(例如,在工具或其他 MCP 操作内部调用时)。服务器初始化阶段的操作不会触发通知。
客户端可以通过消息处理器接收这些通知,从而自动刷新资源列表或更新界面。
资源模板
资源模板允许客户端请求内容依赖于 URI 中嵌入参数的资源。定义资源模板时,使用与普通资源相同的 @mcp.resource 装饰器,但在 URI 字符串中包含 {parameter_name} 占位符,并在函数签名中添加对应的参数。
资源模板共享大部分与普通资源相同的配置选项(如 name、description、mime_type、tags),但增加了定义 URI 参数并映射到函数参数的能力。
资源模板会为每组唯一参数生成一个新资源,意味着资源可以按需动态创建。例如,注册资源模板 "user://profile/{name}" 后,MCP 客户端可以请求 "user://profile/ford" 或 "user://profile/marvin",来获取对应用户的资料,而无需单独注册每个资源。
函数不支持 *args 作为资源模板参数,但资源模板支持 **kwargs,因为 URI 模板定义了具体参数名,这些参数会作为关键字参数传入。
示例:
from fastmcp import FastMCP
mcp = FastMCP(name="DataServer")
# URI 模板包含 {city} 占位符
@mcp.resource("weather://{city}/current")
def get_weather(city: str) -> dict:
"""提供特定城市的天气信息。"""
return {
"city": city.capitalize(),
"temperature": 22,
"condition": "Sunny",
"unit": "celsius"
}
# 多参数模板
@mcp.resource("repos://{owner}/{repo}/info")
def get_repo_info(owner: str, repo: str) -> dict:
"""获取 GitHub 仓库信息。"""
return {
"owner": owner,
"name": repo,
"full_name": f"{owner}/{repo}",
"stars": 120,
"forks": 48
}
客户端可请求不同资源,例如:
weather://london/current→ 获取伦敦天气weather://paris/current→ 获取巴黎天气repos://jlowin/fastmcp/info→ 获取 jlowin/fastmcp 仓库信息repos://prefecthq/prefect/info→ 获取 prefecthq/prefect 仓库信息
通配符参数
新增于版本 2.2.4
FastMCP 支持扩展的通配符参数,用于匹配多个路径段。标准参数 {param} 只匹配单个路径段(不跨越斜杠“/”),而通配符参数 {param*} 可匹配多个路径段,包括斜杠。通配符匹配后续所有路径段,直到 URI 模板的固定部分(字面值或其他参数)。这样可以在单个 URI 模板中使用多个通配符参数。
示例:
from fastmcp import FastMCP
mcp = FastMCP(name="DataServer")
# 标准参数,只匹配一个路径段
@mcp.resource("files://{filename}")
def get_file(filename: str) -> str:
return f"File content for: {filename}"
# 通配符参数,匹配多个路径段
@mcp.resource("path://{filepath*}")
def get_path_content(filepath: str) -> str:
return f"Content at path: {filepath}"
# 混合标准和通配符参数
@mcp.resource("repo://{owner}/{path*}/template.py")
def get_template_file(owner: str, path: str) -> dict:
return {
"owner": owner,
"path": path + "/template.py",
"content": f"File at {path}/template.py in {owner}'s repository"
}
通配符参数适用于:
- 处理文件路径或层级数据
- 需要捕获可变长度路径段的 API
- 构建类似 REST API 的 URL 模式
注意:每个通配符参数仍需在函数签名中作为命名参数出现,且所有必需参数必须出现在 URI 模板中。
默认值
新增于版本 2.2.0
FastMCP 对 URI 模板参数和函数参数的关系有两条规则:
- 所有无默认值的函数参数(必需参数)必须出现在 URI 模板中。
- URI 模板中的所有参数必须对应函数参数。
但带默认值的函数参数可以不出现在 URI 模板中。请求时:
- 从 URI 提取模板中出现的参数值
- 使用函数参数的默认值填充未出现在 URI 模板中的参数
示例:
from fastmcp import FastMCP
mcp = FastMCP(name="DataServer")
@mcp.resource("search://{query}")
def search_resources(query: str, max_results: int = 10, include_archived: bool = False) -> dict:
results = perform_search(query, limit=max_results, archived=include_archived)
return {
"query": query,
"max_results": max_results,
"include_archived": include_archived,
"results": results
}
通过这个模板,客户端可以请求 search://python,此时函数将以参数 query="python"、max_results=10、include_archived=False 被调用。MCP 开发者仍然可以直接调用底层的 search_resources 函数,并传入更具体的参数。
一种更强大的模式是:为同一个函数注册多个 URI 模板,从而允许以不同方式访问同一份数据。
from fastmcp import FastMCP
mcp = FastMCP(name="DataServer")
@mcp.resource("users://email/{email}")
@mcp.resource("users://name/{name}")
def lookup_user(name: str | None = None, email: str | None = None) -> dict:
if email:
return find_user_by_email(email)
elif name:
return find_user_by_name(name)
else:
return {"error": "No lookup parameters provided"}
现在,LLM 或客户端可以通过两种方式获取用户信息:
users://email/alice@example.com→ 通过邮箱查找用户(此时name=None)users://name/Bob→ 通过用户名查找用户(此时email=None)
在这种叠加装饰器的模式中:
- 只有使用
users://name/{name}模板时才会提供name参数 - 只有使用
users://email/{email}模板时才会提供email参数 - 如果 URI 中未包含某个参数,该参数将默认为
None - 函数逻辑将根据实际提供的参数进行处理
模板提供了一种强大的方式,可按照类似 REST 的原则,公开带参数的数据访问接口。
错误处理(Error Handling)
新增于版本 2.4.1
当你的资源函数遇到错误时,可以抛出标准的 Python 异常(如 ValueError、TypeError、FileNotFoundError,或自定义异常),也可以抛出 FastMCP 提供的 ResourceError。
默认情况下,所有异常(包括详细信息)都会被记录日志,并转换为 MCP 错误响应返回给客户端 LLM。这样有助于 LLM 理解失败原因并作出相应处理。
如果你希望出于安全原因隐藏内部错误详情,可以选择以下方式:
-
方式一:全局配置隐藏错误详情
在创建 FastMCP 实例时设置
mask_error_details=True:mcp = FastMCP(name="SecureServer", mask_error_details=True) -
方式二:使用 ResourceError 精确控制向客户端返回的错误信息
from fastmcp import FastMCP from fastmcp.exceptions import ResourceError mcp = FastMCP(name="DataServer") @mcp.resource("resource://safe-error") def fail_with_details() -> str: """该资源提供详细的错误信息。""" raise ResourceError("无法获取数据:文件未找到") @mcp.resource("resource://masked-error") def fail_with_masked_details() -> str: """当 mask_error_details=True 时,该资源的错误信息将被隐藏。""" raise ValueError("敏感路径信息:/etc/secrets.conf") @mcp.resource("data://{id}") def get_data_by_id(id: str) -> dict: """资源模板同样支持错误处理。""" if id == "secure": raise ValueError("无法访问安全数据") elif id == "missing": raise ResourceError("数据库中未找到 ID 为 'missing' 的数据") return {"id": id, "value": "data"}
✅ 当
mask_error_details=True时,只有ResourceError抛出的错误信息会被发送给客户端,其他类型的异常都会被转换为通用的错误提示信息。
服务器行为:资源重复处理(Duplicate Resources)
新增于版本 2.1.0
你可以通过 on_duplicate_resources 参数来配置 FastMCP 服务器在遇到重复注册相同 URI 的资源或模板时的行为。
from fastmcp import FastMCP
mcp = FastMCP(
name="ResourceServer",
on_duplicate_resources="error" # 检测到重复资源时抛出错误
)
@mcp.resource("data://config")
def get_config_v1(): return {"version": 1}
# 再次注册同一 URI 将抛出 ValueError
# @mcp.resource("data://config")
# def get_config_v2(): return {"version": 2}
重复资源的处理选项包括:
| 选项 | 行为说明 |
|---|---|
"warn"(默认) | 记录警告日志,并使用新资源替换旧资源 |
"error" | 抛出 ValueError,阻止重复注册 |
"replace" | 不提示,静默地用新资源替换旧资源 |
"ignore" | 保留原资源,忽略新的注册尝试 |
这样可以帮助你在开发或部署阶段更好地管理资源冲突和版本控制。
与工具的区别
在 FastMCP 中,资源(resource) 和 工具(tool) 虽然看起来都可以“提供数据”或者“处理逻辑”,但它们的定位不同、语义不同,服务于 不同类型的交互场景。
✅ 本质区别:动词 vs 名词
| 对比项 | 工具(Tool) | 资源(Resource) |
|---|---|---|
| 核心语义 | 像函数一样:执行一段操作(动词) | 像文件或数据项:读取某个内容(名词) |
| 请求意图 | 执行某个任务(可能有副作用) | 获取一个值(纯读取,无副作用) |
| 通常行为 | 运行逻辑、改变状态、计算、调用 API | 读取 JSON、文本、图片、配置、文件等 |
| 调用方式 | @mcp.tool | @mcp.resource(uri) |
| 调用参数 | 通过函数参数传入 | 通过 URI 模板参数传入 |
| 返回值格式 | 任意(通常是结构化数据) | 特定格式(文本、字节、JSON、Pydantic) |
| 是否是幂等 | ❌ 可能不是(如发请求、写入) | ✅ 是(同样的 URI 总是返回同样的数据) |
| 是否缓存友好 | ❌ 通常不是 | ✅ 可以缓存 |
📦 使用场景区别
✅ 工具(Tool)适用场景
-
请求执行一个动作、操作、过程,例如:
- 创建用户
- 生成报告
- 调用外部 API
- 执行搜索或变换逻辑
🛠 工具 = 执行某个**“功能”**。
✅ 资源(Resource)适用场景
-
提供一个可直接读取的数据项或文件,例如:
- 读取某个用户的 JSON 配置
- 获取天气信息快照
- 访问某张图片或文档
- 枚举数据目录
📄 资源 = 暴露一个可以通过 URI 访问的**“内容”**。
🔄 为什么不能只用工具?
你当然可以用工具来实现所有逻辑,但:
- 工具没有统一的 URI 命名体系,不便于 LLM 缓存和导航
- 资源天然支持懒加载、目录式结构、层级请求(像 RESTful API)
- 工具更强调执行行为,而资源强调数据可公开访问性
- 资源可以静态注册(比如图片、文档)而无需写函数逻辑
- LLM 能更好地组织已知资源列表(像文件浏览器一样)
🌐 类比:Web 世界的 API 与静态资源
| 角色 | 类比于 Web |
|---|---|
@mcp.tool | POST /api/action,提交数据做事 |
@mcp.resource | GET /data/config.json,获取数据 |
✅ 推荐设计原则
- 如果是纯读取、幂等、可缓存、命名明确的内容,优先用 Resource
- 如果是行为性操作、参数复杂、非幂等、有副作用,使用 Tool
🔚 总结
| 类别 | Tool(工具) | Resource(资源) |
|---|---|---|
| 核心作用 | 做事(执行逻辑) | 提供数据(被读取) |
| 幂等性 | 可能不幂等 | 幂等 |
| 可缓存性 | 通常不适合缓存 | 适合缓存 |
| 调用方式 | 函数调用 | URI 请求 |
| LLM 语义 | 函数、动作、操作指令 | 文件、数据、引用内容 |
如果你能统一使用两者,LLM 的对话体验会更自然(例如先列出资源 URI,再调用工具处理结果),也方便资源可视化、分发、权限控制和缓存机制。
Prompts(提示模板)——为 MCP 客户端创建可复用、可参数化的提示模板
Prompt 是一种可复用的消息模板,用于帮助大语言模型(LLM)生成结构化、有目的性的响应。FastMCP 通过 @mcp.prompt 装饰器简化了这些模板的定义。
什么是 Prompt?
Prompt(提示模板)是为 LLM 提供的、支持参数化的消息内容。当客户端请求某个 prompt 时:
- FastMCP 会找到对应的 prompt 定义;
- 如果有参数,系统会对参数进行校验,确保符合函数签名;
- 你的函数会以这些校验后的输入执行;
- 生成的消息将被返回给 LLM,以引导其生成最终回复。
这样,你就可以定义出 一致性强、可复用的提示模板,供 LLM 在不同客户端和上下文中调用。
@prompt 装饰器
定义 Prompt 的最常见方式是使用 Python 函数并通过 @mcp.prompt 装饰器进行修饰。装饰器默认使用函数名作为 prompt 的标识符。
from fastmcp import FastMCP
from fastmcp.prompts.prompt import Message, PromptMessage, TextContent
mcp = FastMCP(name="PromptServer")
# 基本 prompt:返回字符串(会自动转为 user 消息)
@mcp.prompt
def ask_about_topic(topic: str) -> str:
"""生成一个向用户提问某个主题的提示消息"""
return f"Can you please explain the concept of '{topic}'?"
# 返回特定消息类型的 prompt
@mcp.prompt
def generate_code_request(language: str, task_description: str) -> PromptMessage:
"""生成一个请求代码生成的用户提示消息"""
content = f"Write a {language} function that performs the following task: {task_description}"
return PromptMessage(role="user", content=TextContent(type="text", text=content))
核心概念:
-
名称(Name):默认使用函数名作为 prompt 名称。
-
参数(Parameters):函数参数用于定义 prompt 所需的输入。
-
推断元信息:
- Prompt 名称:取自函数名(如
ask_about_topic) - Prompt 描述:取自函数的 docstring
- Prompt 名称:取自函数名(如
注意:Prompt 函数不支持
*args或**kwargs,因为 FastMCP 需要为 MCP 协议生成完整的参数 schema,无法支持不定参数列表。
装饰器参数(Decorator Arguments)
虽然 FastMCP 会默认从函数中推断出名称和描述,但你也可以通过 @mcp.prompt 的参数覆盖这些默认值,并添加额外元信息:
@mcp.prompt(
name="analyze_data_request", # 自定义 prompt 名称
description="Creates a request to analyze data with specific parameters", # 自定义描述
tags={"analysis", "data"} # 可选的分类标签
)
def data_analysis_prompt(
data_uri: str = Field(description="包含数据的资源 URI"),
analysis_type: str = Field(default="summary", description="分析类型")
) -> str:
"""当提供了 description 时,此 docstring 会被忽略"""
return f"Please perform a '{analysis_type}' analysis on the data found at {data_uri}."
@prompt 装饰器参数说明:
| 参数 | 类型 | 说明 | |
|---|---|---|---|
name | `str | None` | 设置 prompt 的名称(MCP 公开的名称),默认为函数名 |
description | `str | None` | 设置 prompt 的描述,如果设置,会忽略函数的 docstring |
tags | `set[str] | None` | 用于对 prompt 进行分类,客户端可能用标签进行筛选 |
enabled | bool (默认 True) | 是否启用该 prompt。可参考“禁用 Prompt”章节 |
参数类型
新增于版本 2.9.0
MCP 规范要求所有 prompt 的参数都以字符串形式传递,但 FastMCP 为了提升开发体验,允许你使用类型注解(如 list[int] 或 dict[str, str])。当你使用这些复杂类型时,FastMCP 会:
- 自动将来自 MCP 客户端的字符串参数转换为预期的类型
- 自动生成更清晰的说明,展示所需的 JSON 字符串格式
- 仍然支持直接传入已类型化的参数进行调用
由于 MCP 只支持字符串类型的参数,客户端需要知道如何以字符串表示复杂类型。FastMCP 通过自动增强参数说明为开发者和 LLM 提供所需的格式说明。
@mcp.prompt
def analyze_data(
numbers: list[int],
metadata: dict[str, str],
threshold: float
) -> str:
"""Analyze numerical data."""
avg = sum(numbers) / len(numbers)
return f"Average: {avg}, above threshold: {avg > threshold}"
prompt:
{
"name": "analyze_data",
"description": "Analyze numerical data.",
"arguments": [
{
"name": "numbers",
"description": "Provide as a JSON string matching the following schema: {\"items\":{\"type\":\"integer\"},\"type\":\"array\"}",
"required": true
},
{
"name": "metadata",
"description": "Provide as a JSON string matching the following schema: {\"additionalProperties\":{\"type\":\"string\"},\"type\":\"object\"}",
"required": true
},
{
"name": "threshold",
"description": "Provide as a JSON string matching the following schema: {\"type\":\"number\"}",
"required": true
}
]
}
MCP 客户端的调用方式(以字符串形式传参):
{
"numbers": "[1, 2, 3, 4, 5]",
"metadata": "{\"source\": \"api\", \"version\": \"1.0\"}",
"threshold": "2.5"
}
但你依然可以这样直接调用(传入真实类型):
result = await prompt.render({
"numbers": [1, 2, 3, 4, 5],
"metadata": {"source": "api", "version": "1.0"},
"threshold": 2.5
})
提示:保持类型注解简单。复杂嵌套结构或自定义类可能无法可靠地从 JSON 字符串转换。自动生成的参数说明是客户端(尤其是 LLM)理解参数格式的唯一来源。
- 推荐类型:
list[int]、dict[str, str]、float、bool - 避免使用:复杂的 Pydantic 模型、深度嵌套结构、自定义类
返回值类型
FastMCP 会智能处理 prompt 函数的返回值类型:
| 返回类型 | 处理方式 | |
|---|---|---|
str | 自动转为单条 PromptMessage | |
PromptMessage | 原样使用(你也可以使用更简单的 Message(...) 构造方式) | |
| `list[PromptMessage | str]` | 作为对话消息序列使用 |
其他类型 | 尝试转换为字符串并作为单条 PromptMessage 使用 |
from fastmcp.prompts.prompt import Message
@mcp.prompt
def roleplay_scenario(character: str, situation: str) -> list[Message]:
"""构建角色扮演场景的起始消息"""
return [
Message(f"让我们开始角色扮演。你是 {character},情境如下:{situation}"),
Message("好的,我明白。我准备好了,接下来会发生什么?", role="assistant")
]
必填参数 vs 可选参数
函数签名中的参数,如果没有默认值,则为必填;有默认值的参数为可选。
示例:
@mcp.prompt
def data_analysis_prompt(
data_uri: str, # 必填
analysis_type: str = "summary", # 可选
include_charts: bool = False # 可选
) -> str:
"""生成分析数据的请求提示"""
prompt = f"请对 {data_uri} 中的数据执行 '{analysis_type}' 分析。"
if include_charts:
prompt += " 请附带相关图表和可视化。"
return prompt
在这个例子中,客户端必须提供 data_uri,而 analysis_type 和 include_charts 可以省略,届时会使用默认值。
禁用 Prompts
新增于版本:2.8.0
你可以通过启用或禁用来控制 Prompt 的可见性和可用性。被禁用的 prompt 不会出现在可用 prompt 列表中,并且客户端尝试调用时会返回 “Unknown prompt(未知提示)” 错误。
默认情况下,所有 prompt 都是启用状态。你可以在创建时通过装饰器的 enabled 参数来禁用:
@mcp.prompt(enabled=False)
def experimental_prompt():
"""此 prompt 尚未准备好上线使用"""
return "这是一个实验性提示。"
你也可以在运行时通过代码动态启用或禁用 prompt:
@mcp.prompt
def seasonal_prompt():
return "节日快乐!"
# 禁用再重新启用 prompt
seasonal_prompt.disable()
seasonal_prompt.enable()
异步 Prompts(Async Prompts)
FastMCP 同时支持同步(def)和异步(async def)函数作为 prompt 定义。
# 同步 prompt
@mcp.prompt
def simple_question(question: str) -> str:
"""生成向 LLM 提问的简单提示语"""
return f"问题:{question}"
# 异步 prompt
@mcp.prompt
async def data_based_prompt(data_id: str) -> str:
"""基于外部数据生成提示"""
# 实际场景中可以从数据库或 API 获取数据
async with aiohttp.ClientSession() as session:
async with session.get(f"https://api.example.com/data/{data_id}") as response:
data = await response.json()
return f"请分析以下数据:{data['content']}"
当 prompt 函数涉及 I/O 操作(如网络请求、数据库查询、文件读取或外部服务调用)时,请使用 async def 定义。
访问 MCP 上下文(Context)
新增于版本:2.2.5
Prompt 函数可以通过 Context 对象访问 MCP 请求信息与功能支持。你只需在函数参数中添加带有类型注解的 Context 参数即可:
from fastmcp import FastMCP, Context
mcp = FastMCP(name="PromptServer")
@mcp.prompt
async def generate_report_request(report_type: str, ctx: Context) -> str:
"""生成报告请求的提示语"""
return f"请生成一份 {report_type} 报告。请求 ID:{ctx.request_id}"
通知机制
新增于版本:2.9.1
FastMCP 会在 prompt 被添加、启用或禁用时,自动向已连接的客户端发送 notifications/prompts/list_changed 通知。
这使得客户端可以无需轮询就及时获知 prompt 列表的更新。
@mcp.prompt
def example_prompt() -> str:
return "Hello!"
以下操作将触发通知:
mcp.add_prompt(example_prompt) # 发送 prompts/list_changed 通知
example_prompt.disable() # 发送 prompts/list_changed 通知
example_prompt.enable() # 发送 prompts/list_changed 通知
⚠️ 只有在“处于活跃的 MCP 请求上下文中”执行上述操作才会发送通知,也就是说:在工具调用或其他 MCP 操作中修改 prompt 才会发通知。如果是在服务器初始化阶段注册 prompt,则不会触发通知。
客户端可通过消息处理器(message handler)自动刷新 prompt 列表或更新界面。
服务器行为
重复 Prompt 注册
新增于版本:2.1.0
你可以配置 FastMCP 如何处理“尝试注册多个同名 prompt”的情况,
通过 on_duplicate_prompts 参数设置(FastMCP 初始化时传入):
from fastmcp import FastMCP
mcp = FastMCP(
name="PromptServer",
on_duplicate_prompts="error" # 遇到重复 prompt 名时抛出错误
)
@mcp.prompt
def greeting(): return "你好,有什么可以帮您?"
# 以下注册将抛出 ValueError,因为 prompt 名称 "greeting" 已被注册
# @mcp.prompt
# def greeting(): return "您好,需要我做什么?"
可选策略包括:
| 选项值 | 说明 |
|---|---|
"warn" | 默认值,记录警告日志,并用新的 prompt 覆盖旧的 |
"error" | 抛出 ValueError 错误,禁止重复注册 |
"replace" | 静默地用新 prompt 替换旧的 |
"ignore" | 忽略新的 prompt 注册,保留原有的 |
高级功能
MCP 上下文(Context)
Context 对象为你的函数提供了一个干净的接口,可以访问 MCP 的功能,包括:
- 日志记录:将调试、信息、警告和错误消息发送回客户端
- 进度上报:在执行耗时操作时向客户端更新进度
- 资源访问:读取已在服务器上注册的资源数据
- LLM 采样:请求客户端的大模型(LLM)基于提供的消息生成文本
- 用户引导:在工具执行期间请求用户输入结构化数据
- 请求信息:访问当前请求的元数据
- 服务器访问:在需要时访问底层的 FastMCP 服务器实例
如何访问 Context?
通过依赖注入
你只需在函数签名中添加一个参数,并使用类型注解 Context,FastMCP 会在调用该函数时自动注入上下文实例。
关键点:
- 参数名称(如
ctx、context)不重要,重要的是类型注解为Context context参数可以出现在函数签名的任意位置,它不会被暴露给 MCP 客户端作为有效参数context是可选的,不需要的函数可以不添加此参数Context的方法是异步的,因此你的函数通常也需要是async- 类型注解可以是联合类型(如
Context | None),也可以使用Annotated[],都能正常工作 Context只能在请求期间使用,在请求外调用其方法将抛出错误- 如果需要在请求外调试或调用
context方法,可使用默认值None来避免缺少参数错误:例如ctx: Context | None = None
工具(Tools)
from fastmcp import FastMCP, Context
mcp = FastMCP(name="Context Demo")
@mcp.tool
async def process_file(file_uri: str, ctx: Context) -> str:
"""处理文件,使用上下文进行日志记录和资源访问"""
# 上下文通过参数 ctx 提供
return "Processed file"
资源与模板(Resources and Templates)
自版本 2.2.5 起支持
from fastmcp import FastMCP, Context
mcp = FastMCP(name="Context Demo")
@mcp.resource("resource://user-data")
async def get_user_data(ctx: Context) -> dict:
"""根据请求上下文获取个性化用户数据"""
return {"user_id": "example"}
@mcp.resource("resource://users/{user_id}/profile")
async def get_user_profile(user_id: str, ctx: Context) -> dict:
"""通过上下文记录日志并获取用户资料"""
return {"id": user_id}
提示(Prompts)
自版本 2.2.5 起支持
from fastmcp import FastMCP, Context
mcp = FastMCP(name="Context Demo")
@mcp.prompt
async def data_analysis_request(dataset: str, ctx: Context) -> str:
"""生成包含上下文信息的数据分析请求"""
return f"Please analyze the following dataset: {dataset}"
通过依赖函数获取上下文
自版本 2.2.11 起支持
虽然通过函数参数注入是最简单的方式,但在某些情况下(例如深层嵌套的函数或第三方代码中),无法轻易传递 Context 参数。FastMCP 提供了依赖函数 get_context,允许你在服务器请求的任意执行路径中获取当前活动的上下文。
from fastmcp import FastMCP
from fastmcp.server.dependencies import get_context
mcp = FastMCP(name="Dependency Demo")
# 工具函数需要上下文但不接受其作为参数
async def process_data(data: list[float]) -> dict:
# 获取当前上下文(仅在请求中调用有效)
ctx = get_context()
await ctx.info(f"Processing {len(data)} data points")
@mcp.tool
async def analyze_dataset(dataset_name: str) -> dict:
# 调用使用上下文的工具函数
data = load_data(dataset_name)
await process_data(data)
注意事项:
get_context只能在服务器请求的上下文中调用,否则会抛出RuntimeErrorget_context是仅限服务器端的功能,不应在客户端代码中使用
Context 能力
FastMCP 通过 Context 对象提供了多个高级功能。
日志记录(Logging)
将调试、信息、警告和错误消息发送回 MCP 客户端,用于跟踪函数执行情况。
await ctx.debug("Starting analysis")
await ctx.info(f"Processing {len(data)} items")
await ctx.warning("Deprecated parameter used")
await ctx.error("Processing failed")
客户端引导(Client Elicitation)
自版本 2.10.0 起支持
此功能在 2025 年 6 月 18 日的 MCP 规范中首次引入
在工具执行过程中请求客户端提供结构化输入,支持交互式流程和逐步揭示。
result = await ctx.elicit("Enter your name:", response_type=str)
if result.action == "accept":
name = result.data
LLM 采样(LLM Sampling)
自版本 2.0.0 起支持
请求客户端的大语言模型(LLM)基于提供的消息生成文本,可在工具中调用 AI 能力。
response = await ctx.sample("Analyze this data", temperature=0.7)
进度上报(Progress Reporting)
向客户端报告长时间运行任务的进度,支持显示进度指示器,提升用户体验。
await ctx.report_progress(progress=50, total=100) # 已完成 50%
资源访问(Resource Access)
从注册在 FastMCP 服务器上的资源中读取数据,支持访问文件、配置或动态内容。
content_list = await ctx.read_resource("resource://config")
content = content_list[0].content
方法签名:
ctx.read_resource(uri: str | AnyUrl) -> list[ReadResourceContents]
返回:包含资源内容部分的列表。
变更通知(Change Notifications)
自版本 2.9.1 起支持
FastMCP 会在组件(如工具、资源或提示)被添加、移除、启用或禁用时自动发送变更通知。如在极少数情况下需要手动触发通知,可使用以下方法:
@mcp.tool
async def custom_tool_management(ctx: Context) -> str:
"""手动发送工具变更通知的示例"""
# 在自定义修改工具后
await ctx.send_tool_list_changed()
await ctx.send_resource_list_changed()
await ctx.send_prompt_list_changed()
return "Notifications sent"
这些方法主要用于 FastMCP 的内部自动通知机制,大多数用户无需手动调用。
FastMCP 服务器访问(FastMCP Server)
若需访问底层的 FastMCP 服务器实例,可使用 ctx.fastmcp 属性:
@mcp.tool
async def my_tool(ctx: Context) -> None:
# 访问 FastMCP 服务器实例
server_name = ctx.fastmcp.name
...
MCP 请求信息(MCP Request)
可访问当前请求及客户端的元数据:
@mcp.tool
async def request_info(ctx: Context) -> dict:
"""返回当前请求的信息"""
return {
"request_id": ctx.request_id,
"client_id": ctx.client_id or "Unknown client"
}
可用属性说明:
ctx.request_id -> str:当前 MCP 请求的唯一 IDctx.client_id -> str | None:发起请求的客户端 ID(如果初始化时提供)ctx.session_id -> str | None:当前 MCP 会话 ID(仅在 HTTP 传输中用于共享会话数据)
MCP 请求属于 MCP SDK 的底层功能,适用于高级使用场景。大多数用户不需要直接使用它。
代理服务器(Proxy Servers)
使用 FastMCP 作为其他 MCP 服务器的中间层或传输桥接工具。
新增于版本 2.0.0
FastMCP 提供了一种强大的代理能力,可以使一个 FastMCP 实例充当前端,代理另一个 MCP 服务器(该后端服务器可以是远程的、使用不同传输协议的,甚至是另一个 FastMCP 实例)。这个功能是通过类方法 FastMCP.as_proxy() 实现的。
什么是代理(Proxying)?
代理是指设置一个 FastMCP 服务器,它本身不直接实现工具(tools)或资源(resources)。当它接收到一个请求(如 tools/call 或 resources/read)时,会将该请求转发给后端 MCP 服务器,接收响应后再将响应转发回原始客户端。
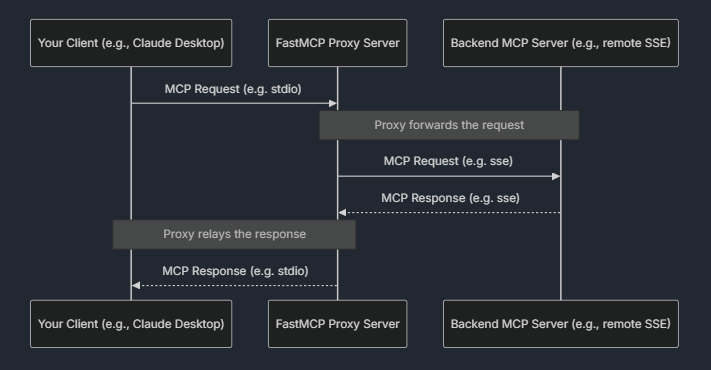
关键优势
新增于版本 2.10.3
- 会话隔离(Session Isolation):每个请求拥有独立的隔离会话,确保并发操作安全可靠
- 传输桥接(Transport Bridging):将运行在一种传输协议上的服务器通过不同协议暴露给客户端
- 高级 MCP 功能支持:自动代理 LLM 采样、用户引导、日志记录和进度上报等操作
- 安全性(Security):作为受控网关限制访问后端 MCP 服务器
- 简化配置(Simplicity):无论后端服务器地址或传输方式如何变化,客户端只需访问一个统一的代理入口
快速开始(Quick Start)
新增于版本 2.10.3
推荐的方式是使用 ProxyClient 来创建代理,它提供完整的 MCP 功能支持,并自动实现会话隔离。
from fastmcp import FastMCP
from fastmcp.server.proxy import ProxyClient
# 创建一个支持完整 MCP 功能的代理
proxy = FastMCP.as_proxy(
ProxyClient("backend_server.py"),
name="MyProxy"
)
# 启动代理(例如用于 Claude Desktop 的 stdio 模式)
if __name__ == "__main__":
proxy.run()
这个简单的配置可以为你提供:
- 安全的并发请求处理
- 自动转发高级 MCP 功能(如采样、引导等)
- 会话隔离,防止上下文混淆
- 完整兼容所有 MCP 客户端
你也可以将 FastMCP 客户端传输(或可以推断为传输的参数)传给 as_proxy(),它会自动创建一个 ProxyClient 实例。
此外,也可以直接传入一个常规的 FastMCP Client 实例给 as_proxy()。这种方式适用于很多场景,但当服务器端调用了诸如采样(sampling)或引导(elicitation)等高级功能时,可能会失效。
会话隔离与并发(Session Isolation & Concurrency)
新增于版本 2.10.3
FastMCP 代理提供会话隔离机制,确保并发操作的安全性。具体策略取决于代理的配置方式!
独立会话(Fresh Sessions)
当你传入一个“未连接”的客户端(常见情况)时,每个请求都会创建一个独立的后端会话:
from fastmcp.server.proxy import ProxyClient
# 每个请求都会创建新的后端会话(推荐)
proxy = FastMCP.as_proxy(ProxyClient("backend_server.py"))
# 多个客户端可同时使用此代理,互不影响:
# - 客户端 A 调用工具 -> 获取一个独立的后端会话
# - 客户端 B 调用工具 -> 获取另一个独立的后端会话
# - 请求之间不会混淆上下文
会话复用(Session Reuse)——连接状态下的客户端
当你传入一个“已连接”的客户端时,所有请求将复用同一个后端会话:
from fastmcp import Client
# 创建并连接客户端
async with Client("backend_server.py") as connected_client:
# 这个代理将复用该会话处理所有请求
proxy = FastMCP.as_proxy(connected_client)
# ⚠️ 警告:所有请求共享同一个后端会话
# 在并发场景下可能引起上下文混淆
重要提示:
当多个客户端并发请求并共享同一个后端会话时,可能会出现上下文混淆或竞态条件。此方法仅推荐用于单线程场景或显式同步控制下使用。
传输桥接(Transport Bridging)
一个常见用途是传输桥接:将运行在某种传输方式上的服务器通过另一种方式暴露。例如,把远程的 SSE 服务器通过本地 stdio 方式提供给客户端访问:
from fastmcp import FastMCP
from fastmcp.server.proxy import ProxyClient
# 将远程 SSE 服务器桥接为本地 stdio 接口
remote_proxy = FastMCP.as_proxy(
ProxyClient("http://example.com/mcp/sse"),
name="Remote-to-Local Bridge"
)
# 本地通过 stdio 运行(适配 Claude Desktop)
if __name__ == "__main__":
remote_proxy.run() # 默认为 stdio 传输
也可以将本地服务器通过 HTTP 暴露给远程客户端:
# 将本地服务器桥接为 HTTP 接口
local_proxy = FastMCP.as_proxy(
ProxyClient("local_server.py"),
name="Local-to-HTTP Bridge"
)
# 通过 HTTP 运行,供远程客户端访问
if __name__ == "__main__":
local_proxy.run(transport="http", host="0.0.0.0", port=8080)
服务器组合(Server Composition)
通过挂载(mount)和导入(import),将多个 FastMCP 服务器组合成一个更大的应用。
新增于版本 2.2.0
随着 MCP 应用的扩展,你可能希望将工具、资源和提示组织成逻辑模块,或者复用已有的服务器组件。FastMCP 提供两种服务器组合方式:
import_server:一次性复制子服务器的组件,并可添加前缀(静态组合)mount:创建主服务器与子服务器之间的“实时链接”,由主服务器动态转发请求(动态组合)
为什么要组合服务器?
- 模块化:将大型应用拆分为更小、更专注的服务器(如
WeatherServer、DatabaseServer、CalendarServer) - 复用性:构建通用的工具服务器(如
TextProcessingServer),按需在不同场景中挂载 - 团队协作:不同团队可以各自开发独立的 FastMCP 服务器,最后统一整合
- 逻辑清晰:将相关功能逻辑地组织在一起
导入 vs 挂载(Importing vs Mounting)
你应该根据使用场景和需求选择导入还是挂载。
| 功能特性 | 导入 Importing | 挂载 Mounting |
|---|---|---|
| 方法 | FastMCP.import_server(server, prefix=None) | FastMCP.mount(server, prefix=None) |
| 组合方式 | 一次性复制(静态组合) | 实时链接(动态组合) |
| 更新反映 | 子服务器更改 不会 自动反映 | 子服务器更改会 即时反映 |
| 前缀处理 | 可选(不指定前缀则保留原始名称) | 可选(不指定前缀则保留原始名称) |
| 最适合场景 | 打包稳定组件 | 运行时模块化组合 |
代理服务器与组合(Proxy Servers)
FastMCP 支持 MCP 代理机制,可以将本地或远程服务器镜像到本地 FastMCP 实例中。代理服务器与 import_server 和 mount 机制完全兼容。
新增于版本 2.4.0
你也可以基于配置字典创建代理,只需符合 MCPConfig 模式。这对于快速连接一个或多个远程服务器非常实用。
⚠️ 注意:MCPConfig 遵循的是一项正在发展的标准,其格式未来可能会有所调整。
导入(Importing) - 静态组合(Static Composition)
import_server() 方法会将所有组件(包括工具、资源、模板、提示)从一个 FastMCP 实例(子服务器)复制到另一个实例(主服务器)。你可以选择性地提供前缀来避免命名冲突。如果不提供前缀,组件会按原样导入。
当多个子服务器使用相同的前缀(或都不使用前缀)被导入时,最近导入的服务器的组件将覆盖已有的同名组件。
from fastmcp import FastMCP
import asyncio
# 定义子服务器
weather_mcp = FastMCP(name="WeatherService")
@weather_mcp.tool
def get_forecast(city: str) -> dict:
"""获取天气预报"""
return {"city": city, "forecast": "Sunny"}
@weather_mcp.resource("data://cities/supported")
def list_supported_cities() -> list[str]:
"""列出支持的城市"""
return ["London", "Paris", "Tokyo"]
# 定义主服务器
main_mcp = FastMCP(name="MainApp")
# 导入子服务器
async def setup():
await main_mcp.import_server(weather_mcp, prefix="weather")
# 导入后的结果:主服务器包含以下前缀组件:
# - 工具:weather_get_forecast
# - 资源:data://weather/cities/supported
if __name__ == "__main__":
asyncio.run(setup())
main_mcp.run()
导入的工作机制
当你执行 await main_mcp.import_server(subserver, prefix={你的前缀}) 时:
-
工具(Tools):子服务器中的所有工具会以
{prefix}_作为前缀加入主服务器。
例如:subserver.tool(name="my_tool")→main_mcp.tool(name="prefix_my_tool") -
资源(Resources):资源 URI 会加上前缀,格式为
protocol://{prefix}/路径
例如:subserver.resource("data://info")→main_mcp.resource("data://prefix/info") -
资源模板(Resource Templates):处理方式与资源一致
例如:data://{id}→data://prefix/{id} -
提示(Prompts):提示名会加上前缀
{prefix}_
例如:subserver.prompt("my_prompt")→main_mcp.prompt("prefix_my_prompt")
⚠️ 注意:
import_server是一次性复制组件的操作,导入后对子服务器的修改不会同步到主服务器。- 子服务器的生命周期上下文(如
@mcp.on_startup)不会在主服务器中执行。 prefix参数是可选的,若不传,则原始名称、URI 保留不变。
无前缀导入(Importing Without Prefixes)
新增于版本 2.9.0
你也可以在不指定前缀的情况下导入服务器,组件将以原始名称导入:
from fastmcp import FastMCP
import asyncio
# 定义子服务器
weather_mcp = FastMCP(name="WeatherService")
@weather_mcp.tool
def get_forecast(city: str) -> dict:
"""获取天气预报"""
return {"city": city, "forecast": "Sunny"}
@weather_mcp.resource("data://cities/supported")
def list_supported_cities() -> list[str]:
"""列出支持的城市"""
return ["London", "Paris", "Tokyo"]
# 定义主服务器
main_mcp = FastMCP(name="MainApp")
# 导入子服务器
async def setup():
# 不加前缀导入 —— 保留原始名称
await main_mcp.import_server(weather_mcp)
# 导入后的结果:
# - 工具名:get_forecast(保持原名)
# - 资源 URI:data://cities/supported(保持原 URI)
if __name__ == "__main__":
asyncio.run(setup())
main_mcp.run()
命名冲突解决(Conflict Resolution)
新增于版本 2.9.0
当多个服务器使用相同的前缀,或都未指定前缀进行导入时,最后导入的服务器的组件会覆盖前面已导入的同名组件。
挂载(Mounting) - 实时链接(Live Linking)
mount() 方法在主服务器(main_mcp)和子服务器之间建立一个实时链接。与 import_server 不同,它不会复制组件,而是在运行时将匹配特定前缀的请求委托给子服务器。
如果未提供前缀,子服务器的组件将以原始名称直接可用。
当多个子服务器使用相同前缀(或都不使用前缀)挂载时,最近挂载的服务器的组件会覆盖已有的同名组件。
import asyncio
from fastmcp import FastMCP, Client
# 定义子服务器
dynamic_mcp = FastMCP(name="DynamicService")
@dynamic_mcp.tool
def initial_tool():
"""初始工具演示"""
return "Initial Tool Exists"
# 挂载子服务器(同步操作)
main_mcp = FastMCP(name="MainAppLive")
main_mcp.mount(dynamic_mcp, prefix="dynamic")
# 在挂载后新增工具 —— 主服务器会实时感知
@dynamic_mcp.tool
def added_later():
"""挂载后动态添加的工具"""
return "Tool Added Dynamically!"
# 测试访问挂载的工具
async def test_dynamic_mount():
tools = await main_mcp.get_tools()
print("可用工具列表:", list(tools.keys()))
# 输出:['dynamic_initial_tool', 'dynamic_added_later']
async with Client(main_mcp) as client:
result = await client.call_tool("dynamic_added_later")
print("结果:", result.data)
# 输出:Tool Added Dynamically!
if __name__ == "__main__":
asyncio.run(test_dynamic_mount())
挂载机制说明
当你调用 mount() 时,会发生以下行为:
- 实时链接(Live Link):主服务器建立到子服务器的动态连接。
- 动态更新(Dynamic Updates):子服务器上的修改会即时反映在主服务器上。
- 前缀访问(Prefixed Access):主服务器使用前缀将请求路由到子服务器。
- 请求委托(Delegation):所有匹配前缀的组件请求,都会在运行时委托给子服务器处理。
前缀的命名规则与 import_server 完全一致(适用于工具、资源、模板、提示等)。
⚠️ 前缀是可选的。如果省略,组件将直接通过原始名称访问。
无前缀挂载
新增于版本 2.9.0
你也可以不指定前缀进行挂载,这会使子服务器的组件在主服务器中以原名可用。行为与“无前缀导入”一致,包括命名冲突时以最近挂载为准的规则。
直接挂载 vs 代理挂载(Direct vs. Proxy Mounting)
新增于版本 2.2.7
FastMCP 支持两种挂载模式:
| 模式 | 描述 |
|---|---|
| 直接挂载(默认) | 主服务器直接访问子服务器的内存对象。 不执行客户端生命周期事件,生命周期上下文(如 @on_startup)不会触发,通信通过方法调用完成。 |
代理挂载(as_proxy=True) | 主服务器将子服务器视为独立实体,并通过客户端接口通信。 客户端生命周期事件会完整触发,子服务器生命周期上下文会执行,通信基于内存中的客户端连接。 |
示例:
# 直接挂载(默认行为)
main_mcp.mount(api_server, prefix="api")
# 使用代理挂载(保留完整生命周期行为)
main_mcp.mount(api_server, prefix="api", as_proxy=True)
# 无前缀挂载(组件按原名访问)
main_mcp.mount(api_server)
如果被挂载的服务器定义了自定义生命周期(如
@on_startup、@on_shutdown),FastMCP 会自动采用代理挂载。你也可以通过as_proxy参数显式指定挂载方式。
与代理服务器的结合使用(Interaction with Proxy Servers)
当你使用 FastMCP.as_proxy() 创建一个代理服务器实例时,该服务器挂载时会自动采用代理挂载模式。
示例:
# 为远程服务器创建一个代理
remote_proxy = FastMCP.as_proxy(Client("http://example.com/mcp"))
# 挂载代理服务器(始终使用代理挂载)
main_server.mount(remote_proxy, prefix="remote")
资源前缀格式(Resource Prefix Formats)
新增于版本:2.4.0
在挂载或导入服务器时,资源 URI 通常会添加前缀以避免命名冲突。FastMCP 支持两种不同的资源前缀格式:
1. 路径格式(Path Format,默认)
在路径格式中,前缀被添加到 URI 的路径部分:
resource://prefix/path/to/resource
这是从 FastMCP 2.4 开始的默认格式。推荐使用该格式,因为它避免了 URI 协议限制的问题(例如,协议名中不允许使用下划线等字符)。
2. 协议格式(Protocol Format,旧版)
在协议格式中,前缀作为协议的一部分添加:
prefix+resource://path/to/resource
这是 FastMCP 2.4 之前的默认格式。虽然仍然受支持,但不建议在新代码中使用,因为前缀中可能包含不符合 URI 协议命名规范的字符,会导致解析问题。
3. 配置前缀格式(Configuring the Prefix Format)
你可以通过以下几种方式配置资源前缀格式:
全局设置(代码中设置):
import fastmcp
fastmcp.settings.resource_prefix_format = "protocol" # 或 "path"
使用环境变量设置:
FASTMCP_RESOURCE_PREFIX_FORMAT=protocol
针对某个服务器设置:
from fastmcp import FastMCP
# 使用旧版“协议格式”的服务器
server = FastMCP("LegacyServer", resource_prefix_format="protocol")
# 使用新版“路径格式”的服务器
server = FastMCP("NewServer", resource_prefix_format="path")
📌 注意:
无论是挂载还是导入服务器,始终采用父服务器的前缀格式(即 main_mcp 的格式为准)。
用户引导输入(User Elicitation)
新增于版本:2.10.0
用户引导输入功能允许 MCP 服务器在工具执行过程中向用户请求结构化输入。与一次性提供所有参数不同,工具函数可以在执行中动态地请求缺失的参数、需要的说明或额外的上下文信息。
什么是引导输入(Elicitation)?
引导输入允许工具函数在执行中暂停,并向用户请求特定信息,适用于以下场景:
- 缺失参数:请求运行所需但尚未提供的信息
- 澄清说明:在信息不明确时请求用户确认或选项
- 逐步收集信息:逐步获取复杂数据
- 动态工作流:根据用户响应调整工具行为
例如:
文件管理工具可能会询问:“要在哪个目录中创建文件?”
数据分析工具可能会请求:“你要分析哪个日期范围的数据?”
基本用法
使用 ctx.elicit() 方法在任意工具函数中请求用户输入:
from fastmcp import FastMCP, Context
from dataclasses import dataclass
mcp = FastMCP("Elicitation Server")
@dataclass
class UserInfo:
name: str
age: int
@mcp.tool
async def collect_user_info(ctx: Context) -> str:
"""通过交互方式收集用户信息。"""
result = await ctx.elicit(
message="请提供你的信息",
response_type=UserInfo
)
if result.action == "accept":
user = result.data
return f"你好 {user.name},你今年 {user.age} 岁"
elif result.action == "decline":
return "未提供信息"
else:
return "操作已取消"
方法签名
上下文提问方法(Context Elicitation Method) ctx.elicit 是一个异步方法:
参数说明:
-
message(
str)
要显示给用户的提示信息。 -
response_type(默认值为
None)
定义期望响应结构的 Python 类型(可以是dataclass、基本类型等)。
注意:提问响应必须符合 JSON Schema 的受限子集。
返回值:
- ElicitationResult(对象)
包含用户响应结果的对象。
属性:
-
action:
Literal['accept', 'decline', 'cancel']
用户对请求的响应方式:"accept":用户提供了有效输入"decline":用户选择不提供信息"cancel":用户取消了整个操作
-
data:
response_type | None
用户提供的输入数据(仅在action为"accept"时存在)
用户操作结果类型(Elicitation Actions)
返回结果的 action 字段表明用户的操作方式:
accept:用户提供了有效输入,数据存储在data字段中decline:用户拒绝提供信息,data为Nonecancel:用户取消整个操作,data为None
@mcp.tool
async def my_tool(ctx: Context) -> str:
result = await ctx.elicit("请选择一个操作")
if result.action == "accept":
return "已接受!"
elif result.action == "decline":
return "已拒绝!"
else:
return "已取消!"
你也可以使用 FastMCP 提供的类型模式匹配方式处理结果:
from fastmcp.server.elicitation import (
AcceptedElicitation,
DeclinedElicitation,
CancelledElicitation,
)
@mcp.tool
async def pattern_example(ctx: Context) -> str:
result = await ctx.elicit("请输入你的名字:", response_type=str)
match result:
case AcceptedElicitation(data=name):
return f"你好,{name}!"
case DeclinedElicitation():
return "未提供姓名"
case CancelledElicitation():
return "操作取消"
响应类型(Response Types)
服务器在发起请求时必须告知客户端希望接收的数据结构。如果用户选择接受,则返回值必须符合此结构。
MCP 协议当前仅支持包含基本字段(字符串、数字、布尔值、枚举)的一层 JSON 对象结构。
FastMCP 可让你请求更广泛的类型(如标量值或无需响应的情况),并自动包装为 MCP 支持的对象格式。
标量类型(Scalar Types)
你可以请求简单的标量数据类型作为基本输入,例如字符串(string)、整数(integer)或布尔值(boolean)。
当你请求标量类型时,FastMCP 会自动将其包装成一个对象结构,以符合 MCP 规范的要求。客户端将看到一个对应的 schema,请求包含一个名为 "value" 的字段,其类型为你指定的标量类型。一旦客户端做出响应,FastMCP 会“解包”该对象,并将标量值作为 ElicitationResult 对象中的 data 字段返回给你的工具函数。
对开发者而言,这意味着:当你只需要一个简单值时,不必手动创建或访问结构化对象。
@mcp.tool
async def get_user_name(ctx: Context) -> str:
"""获取用户名"""
result = await ctx.elicit("你的名字?", response_type=str)
if result.action == "accept":
return f"你好,{result.data}!"
return "未提供姓名"
@mcp.tool
async def pick_a_number(ctx: Context) -> str:
"""Pick a number."""
result = await ctx.elicit("Pick a number!", response_type=int)
if result.action == "accept":
return f"You picked {result.data}"
return "No number provided"
@mcp.tool
async def pick_a_boolean(ctx: Context) -> str:
"""Pick a boolean."""
result = await ctx.elicit("True or false?", response_type=bool)
if result.action == "accept":
return f"You picked {result.data}"
return "No boolean provided"
无需响应(No Response)
有时,发起提问的目的只是为了让用户批准或拒绝某个操作。在这种情况下,你可以将 response_type 设置为 None,表示不需要用户提供具体输入。
为了符合 MCP 规范,客户端会看到一个请求响应的 schema,其中要求提交一个空对象。如果用户接受该提问请求,ElicitationResult 对象中的 data 字段将为 None。
@mcp.tool
async def approve_action(ctx: Context) -> str:
"""请求用户批准操作"""
result = await ctx.elicit("是否批准该操作?", response_type=None)
if result.action == "accept":
return do_action()
else:
raise ValueError("操作被拒绝")
限定选项(Constrained Options)
在很多情况下,你可能希望限制用户的响应为一组特定的值。你可以通过以下方式实现这一点:
- 使用
Literal类型作为response_type; - 使用 Python 的
enum枚举类型; - 或者,作为一种便捷方式,直接向
response_type参数传入一个字符串列表。
这些方法都可以用来限定用户只能从指定选项中选择。
@mcp.tool
async def set_priority(ctx: Context) -> str:
"""设置任务优先级"""
result = await ctx.elicit(
"选择优先级",
response_type=["low", "medium", "high"],
)
if result.action == "accept":
return f"优先级已设为:{result.data}"
-----
from typing import Literal
@mcp.tool
async def set_priority(ctx: Context) -> str:
"""Set task priority level."""
result = await ctx.elicit(
"What priority level?",
response_type=Literal["low", "medium", "high"]
)
if result.action == "accept":
return f"Priority set to: {result.data}"
return "No priority set"
------
from enum import Enum
class Priority(Enum):
LOW = "low"
MEDIUM = "medium"
HIGH = "high"
@mcp.tool
async def set_priority(ctx: Context) -> str:
"""Set task priority level."""
result = await ctx.elicit("What priority level?", response_type=Priority)
if result.action == "accept":
return f"Priority set to: {result.data.value}"
return "No priority set"
结构化响应(Structured Responses)
你可以通过将响应类型设置为 dataclass(数据类)、TypedDict(类型化字典) 或 Pydantic 模型,来请求包含多个字段的结构化数据。
需要注意的是,MCP 规范只支持“浅层对象”,即字段类型只能是标量(如字符串、数字、布尔值)或枚举类型,不支持嵌套的复杂结构。
from dataclasses import dataclass
from typing import Literal
@dataclass
class TaskDetails:
title: str
description: str
priority: Literal["low", "medium", "high"]
due_date: str
@mcp.tool
async def create_task(ctx: Context) -> str:
"""创建新任务"""
result = await ctx.elicit(
"请输入任务详情",
response_type=TaskDetails
)
if result.action == "accept":
task = result.data
return f"任务已创建:{task.title}(优先级:{task.priority})"
return "任务创建取消"
多轮对话引导(Multi-Turn Elicitation)
工具函数可以多次调用 elicit(),逐步收集信息:
@mcp.tool
async def plan_meeting(ctx: Context) -> str:
"""逐步计划会议"""
title_result = await ctx.elicit("会议标题?", response_type=str)
if title_result.action != "accept":
return "会议取消"
duration_result = await ctx.elicit("会议时长(分钟)?", response_type=int)
if duration_result.action != "accept":
return "会议取消"
priority_result = await ctx.elicit("是否紧急?", response_type=Literal["yes", "no"])
if priority_result.action != "accept":
return "会议取消"
urgent = priority_result.data == "yes"
return f"已安排会议“{title_result.data}”,时长 {duration_result.data} 分钟(紧急:{urgent})"
客户端要求(Client Requirements)
使用引导输入功能时,客户端必须实现相应的引导处理器。详情见 Client Elicitation 部分。
如果客户端不支持引导输入,调用 ctx.elicit() 将会抛出错误,提示“不支持引导请求”。
如何理解用户引导
用户引导(elicitation)是 MCP 机制中用于在工具执行期间暂停流程并向用户请求输入的功能。这与在 LangChain 或 LangGraph 中使用 input() 等方式让 Agent 暂停区别在于它是由 MCP 协议标准化控制的,通过 MCP 客户端(例如 langchain‑mcp‑adapters)自动弹出消息给大模型前端界面或终端客户。
🧭 使用场景对比
-
MCP 内部引导
- Agent 在执行工具
ctx.elicit(...)时,工具在服务器端发出一个“引导请求”。 - 客户端(如 langchain‑mcp‑adapters)检测到该请求,会给前端用户展示交互界面(比如 CLI 提示、前端弹窗)。
- 用户输入后,MCP 客户端将该输入封装成符合协议的 JSON 发回 MCP 服务器,流程继续。
此时不会自动调用一次新的大语言模型生成内容,除非引导之后再触发
ctx.sample()/工具调用。 - Agent 在执行工具
-
LangChain / LangGraph 的中断等待
- LangChain Agent 在 prompt chain 中可以通过
input()、PromptTemplate或LLMChain设置多轮变量,等待用户输入。这是一种应用代码级别的控制流。 - 这些方式是由你在 Python 端控制 同步地 阻塞等待输入,直至程序继续执行。
- LangChain Agent 在 prompt chain 中可以通过
| 特性 | MCP ctx.elicit() | LangChain input() /多轮 Prompt |
|---|---|---|
| 流程控制 | MCP 协议内部 pause/resume,由客户端响应触发 | 普通 Python 层顺序阻塞与 resume |
| 是否调用 LLM | 仅 await 输入,无额外 LLM 调用(除非 tool 或 sample 随后调用) | 可根据设计再次 call LLM 或继续使用已有 context |
| 标准化支持 | MCP 客户端自动识别并渲染对话/表单 | 依赖开发者手工接入 CLI/UI |
| 集成场景 | 与 langchain‑mcp‑adapters 配合,Agent 调用 MCP 工具时自动支持用户交互 | 你必须在 Agent 流程中手动插入用户输入环节 |
举个用 langchain-mcp-adapters 的 Agent 例子
# MCP 工具定义
@mcp.tool
async def set_priority(...):
result = await ctx.elicit("Set priority", response_type=["low","medium","high"])
...
通过 load_mcp_tools 和 initialize_agent(...) 集成时,当 Agent 执行这个工具,客户端会自动弹出选项表单。用户选完后,结果被 MCP 客户端传回,再继续调用后续逻辑。这完全由 MCP 协议控制,无需写阻塞代码。
✅ 总结
- MCP 引导 是一个由协议驱动、客户端自动支持的规范化机制。
- 它不是一个“大模型调用”,也不是
LangChain的中断等待。 - 与 LangChain/Graph 的等待方式相比,MCP 引导更适合前端兼容、UI 交互统一、协议标准化的流程控制。
服务器日志记录(Server Logging)
通过上下文(Context)将日志消息发送回 MCP 客户端。
本节文档介绍 MCP 客户端日志记录,即如何从你的服务器向 MCP 客户端发送消息。若需进行标准的服务器端日志记录(例如输出到文件、控制台等),可使用 fastmcp.utilities.logging.get_logger() 或 Python 内建的 logging 模块。
服务器日志记录允许 MCP 工具向客户端发送 debug(调试)、info(信息)、warning(警告)和 error(错误)级别的日志消息。这在开发与运行期间提供了工具执行过程的可见性,有助于调试。
✅ 为什么使用服务器日志?
服务器日志记录的主要用途包括:
- 调试:发送详细的执行信息,帮助定位问题。
- 进度可见性:向用户展示工具当前正在执行的内容。
- 错误报告:告知客户端问题及其上下文。
- 审计追踪:记录工具执行流程,便于合规检查或分析。
与 Python 标准日志不同,MCP 服务器日志是直接发送给客户端的,客户端界面或其日志系统可立即显示这些消息。
🔧 基本用法
你可以在工具函数中使用 ctx(上下文)对象的方法记录日志:
from fastmcp import FastMCP, Context
mcp = FastMCP("LoggingDemo")
@mcp.tool
async def analyze_data(data: list[float], ctx: Context) -> dict:
"""使用详细日志分析数值数据。"""
await ctx.debug("开始分析数值数据")
await ctx.info(f"正在分析 {len(data)} 个数据点")
try:
if not data:
await ctx.warning("提供了空数据列表")
return {"error": "数据为空"}
result = sum(data) / len(data)
await ctx.info(f"分析完成,平均值为:{result}")
return {"average": result, "count": len(data)}
except Exception as e:
await ctx.error(f"分析失败:{str(e)}")
raise
🧱 日志方法
ctx.debug 用于发送调试级别的日志消息,适用于详细执行信息。
message: str- 要发送给客户端的调试信息
ctx.info 用于发送信息级别的日志,适合描述正常流程状态。
message: str- 要发送的普通信息
ctx.warning 用于发送警告级别的日志,用于潜在问题但流程仍能继续。
message: str- 警告信息内容
ctx.error 用于发送错误级别的日志,用于流程中出现的问题。
message: str- 错误信息内容
ctx.log 通用日志方法,可自定义级别和日志器名称。
level: 'debug' | 'info' | 'warning' | 'error'message: strlogger_name: str | None = None
🔢 日志级别说明与示例
Debug
适用于开发时需要的详细内部信息:
@mcp.tool
async def process_file(file_path: str, ctx: Context) -> str:
await ctx.debug(f"开始处理文件:{file_path}")
await ctx.debug("检查文件权限")
# ...
await ctx.debug("文件处理成功")
return "处理完成"
Info
用于正常流程的信息提示:
@mcp.tool
async def backup_database(ctx: Context) -> str:
await ctx.info("启动数据库备份")
await ctx.info("连接数据库中...")
await ctx.info("备份成功")
return "数据库已备份"
Warning
用于流程中存在风险但可继续的情况:
@mcp.tool
async def validate_config(config: dict, ctx: Context) -> dict:
if "old_api_key" in config:
await ctx.warning("使用了已废弃字段 'old_api_key',请改用 'api_key'")
if config.get("timeout", 30) > 300:
await ctx.warning("超时时间设置过高(>5 分钟),可能会有问题")
return {"status": "valid", "warnings": "请查看日志"}
Error
用于捕获并报告错误(流程可能仍继续):
@mcp.tool
async def batch_process(items: list[str], ctx: Context) -> dict:
successful = 0
failed = 0
for item in items:
try:
# 假设处理逻辑
successful += 1
except Exception as e:
await ctx.error(f"处理 '{item}' 失败:{str(e)}")
failed += 1
return {"successful": successful, "failed": failed}
🖥️ 客户端处理方式
日志消息会通过 MCP 协议发送给客户端。客户端对这些日志的处理方式视其实现而定:
- 开发客户端:通常会实时显示日志,方便调试。
- 生产客户端:可能会将日志记录下来,用于后续查看或展示。
- 集成客户端:可能会将日志转发到外部日志系统中。
详见文档中的「Client Logging」部分,了解客户端如何接收和处理这些日志。
进度报告(Progress Reporting)
通过 MCP 上下文(context)向客户端实时汇报长时间运行操作的进度。
📌 什么是进度报告?
进度报告允许 MCP 工具在执行耗时操作时,向客户端发送进度更新。这样可以让客户端显示进度条或其他反馈,改善用户体验。
✅ 为什么使用进度报告?
- 用户体验: 让用户了解长时间运行的操作正在执行
- 进度指示器: 支持客户端显示进度条或百分比
- 避免超时: 显示操作仍在进行中,防止被误判为“无响应”
- 调试辅助: 跟踪操作流程,帮助性能分析
🧪 基本用法
通过 ctx.report_progress() 报告当前进度:
from fastmcp import FastMCP, Context
import asyncio
mcp = FastMCP("ProgressDemo")
@mcp.tool
async def process_items(items: list[str], ctx: Context) -> dict:
total = len(items)
results = []
for i, item in enumerate(items):
await ctx.report_progress(progress=i, total=total)
await asyncio.sleep(0.1) # 模拟处理
results.append(item.upper())
await ctx.report_progress(progress=total, total=total)
return {"processed": len(results), "results": results}
📘 方法签名
await ctx.report_progress(progress: float, total: float | None = None)
progress: 当前进度值(可以是整数或浮点)total: 总进度值(可选),如果提供,客户端可自动计算百分比
🧭 支持的进度模式
1. 百分比进度(0-100)
适用于已知百分比情况:
@mcp.tool
async def download_file(url: str, ctx: Context) -> str:
"""Download a file with percentage progress."""
total_size = 1000 # KB
downloaded = 0
while downloaded < total_size:
# Download chunk
chunk_size = min(50, total_size - downloaded)
downloaded += chunk_size
# Report percentage progress
percentage = (downloaded / total_size) * 100
await ctx.report_progress(progress=percentage, total=100)
await asyncio.sleep(0.1) # Simulate download time
return f"Downloaded file from {url}"
2. 绝对进度(如:表数量、文件个数)
适用于有确定数量但非百分比的操作:
@mcp.tool
async def backup_database(ctx: Context) -> str:
"""Backup database tables with absolute progress."""
tables = ["users", "orders", "products", "inventory", "logs"]
for i, table in enumerate(tables):
await ctx.info(f"Backing up table: {table}")
# Report absolute progress
await ctx.report_progress(progress=i + 1, total=len(tables))
# Simulate backup time
await asyncio.sleep(0.5)
return "Database backup completed"
3. 不确定进度(Indeterminate Progress)
用于未知终点的任务,如目录扫描:
@mcp.tool
async def scan_directory(directory: str, ctx: Context) -> dict:
"""Scan directory with indeterminate progress."""
files_found = 0
# Simulate directory scanning
for i in range(10): # Unknown number of files
files_found += 1
# Report progress without total for indeterminate operations
await ctx.report_progress(progress=files_found)
await asyncio.sleep(0.2)
return {"files_found": files_found, "directory": directory}
4. 多阶段进度(Multi-Stage Progress)
可将整体进度人为划分为多个阶段,每阶段占不同百分比区间:
# 阶段 1:0% - 25%
# 阶段 2:25% - 60%
# 阶段 3:60% - 80%
# 阶段 4:80% - 100%
@mcp.tool
async def data_migration(source: str, destination: str, ctx: Context) -> str:
"""Migrate data with multi-stage progress reporting."""
# Stage 1: Validation (0-25%)
await ctx.info("Validating source data")
for i in range(5):
await ctx.report_progress(progress=i * 5, total=100)
await asyncio.sleep(0.1)
# Stage 2: Export (25-60%)
await ctx.info("Exporting data from source")
for i in range(7):
progress = 25 + (i * 5)
await ctx.report_progress(progress=progress, total=100)
await asyncio.sleep(0.1)
# Stage 3: Transform (60-80%)
await ctx.info("Transforming data format")
for i in range(4):
progress = 60 + (i * 5)
await ctx.report_progress(progress=progress, total=100)
await asyncio.sleep(0.1)
# Stage 4: Import (80-100%)
await ctx.info("Importing to destination")
for i in range(4):
progress = 80 + (i * 5)
await ctx.report_progress(progress=progress, total=100)
await asyncio.sleep(0.1)
# Final completion
await ctx.report_progress(progress=100, total=100)
return f"Migration from {source} to {destination} completed"
💡 客户端支持要求
进度报告功能要求客户端支持进度处理:
- 客户端必须在初始请求中携带
progressToken,才能接收进度更新。 - 如果未提供进度 token,则服务器端的
progress调用将不会生效(但也不会报错)。 - 有关客户端如何实现进度处理的详细信息,请参阅 Client Progress 文档。
LLM 采样
通过 MCP 上下文请求客户端的 LLM(大语言模型)基于提供的消息生成文本。
版本新特性:2.0.0
LLM 采样允许 MCP 工具请求客户端的 LLM 根据提供的消息生成文本。当工具需要利用 LLM 的能力来处理数据、生成响应或进行基于文本的分析时,这非常有用。
为什么使用 LLM 采样?
LLM 采样使工具能够:
- 利用 AI 能力:使用客户端的 LLM 进行文本生成和分析
- 卸载复杂推理:让 LLM 处理需要自然语言理解的任务
- 生成动态内容:基于数据创建响应、摘要或转换
- 维护上下文:使用用户已在交互的同一 LLM 实例
基本用法
使用 ctx.sample() 向客户端的 LLM 请求文本生成:
from fastmcp import FastMCP, Context
mcp = FastMCP("SamplingDemo")
@mcp.tool
async def analyze_sentiment(text: str, ctx: Context) -> dict:
"""使用客户端的 LLM 分析文本情感。"""
prompt = f"""请分析以下文本的情感,判断为正面、负面或中性。
只输出一个词——'positive'、'negative' 或 'neutral'。
待分析文本:{text}"""
# 请求 LLM 分析
response = await ctx.sample(prompt)
# 处理 LLM 的响应
sentiment = response.text.strip().lower()
# 映射为标准情感值
if "positive" in sentiment:
sentiment = "positive"
elif "negative" in sentiment:
sentiment = "negative"
else:
sentiment = "neutral"
return {"text": text, "sentiment": sentiment}
方法签名
上下文采样方法ctx.sample异步方法 请求客户端 LLM 生成文本:
参数:
-
messages(str | list[str | SamplingMessage])
发送给 LLM 的字符串或字符串/消息对象列表 -
system_prompt(str | None,默认 None)
可选的系统提示,用于引导 LLM 行为 -
temperature(float | None,默认 None)
可选的采样温度(控制随机性,通常在 0.0~1.0 之间) -
max_tokens(int | 默认 512)
可选的最大生成 token 数 -
model_preferences(ModelPreferences | str | list[str] | None,默认 None)
可选的模型选择偏好(如模型提示字符串、提示列表或 ModelPreferences 对象)
返回值:
response(TextContent | ImageContent)
LLM 的响应内容(通常为具有.text属性的 TextContent)
简单文本生成
基本提示
使用简单字符串提示生成文本:
@mcp.tool
async def generate_summary(content: str, ctx: Context) -> str:
"""生成所提供内容的摘要。"""
prompt = f"请对以下内容做简明总结:\n\n{content}"
response = await ctx.sample(prompt)
return response.text
系统提示
使用系统提示引导 LLM 行为:
@mcp.tool
async def generate_code_example(concept: str, ctx: Context) -> str:
"""为指定概念生成 Python 代码示例。"""
response = await ctx.sample(
messages=f"编写一个演示'{concept}'的简单 Python 代码示例。",
system_prompt="你是资深 Python 程序员。提供简洁、可运行的代码示例,不要附加解释。",
temperature=0.7,
max_tokens=300
)
code_example = response.text
return f"```python\n{code_example}\n```"
模型偏好
为不同用例指定模型偏好:
@mcp.tool
async def creative_writing(topic: str, ctx: Context) -> str:
"""使用指定模型生成创意内容。"""
response = await ctx.sample(
messages=f"写一篇关于{topic}的创意短篇故事",
model_preferences="claude-3-sonnet", # 偏好特定模型
include_context="thisServer", # 使用服务器上下文
temperature=0.9, # 高创造力
max_tokens=1000
)
return response.text
@mcp.tool
async def technical_analysis(data: str, ctx: Context) -> str:
"""使用注重推理的模型进行技术分析。"""
response = await ctx.sample(
messages=f"分析以下技术数据并提供见解:{data}",
model_preferences=["claude-3-opus", "gpt-4"], # 偏好推理模型
temperature=0.2, # 低随机性保证一致性
max_tokens=800
)
return response.text
复杂消息结构
使用结构化消息实现更复杂的交互:
from fastmcp.client.sampling import SamplingMessage
@mcp.tool
async def multi_turn_analysis(user_query: str, context_data: str, ctx: Context) -> str:
"""使用多轮对话结构进行分析。"""
messages = [
SamplingMessage(role="user", content=f"我有这些数据:{context_data}"),
SamplingMessage(role="assistant", content="我看到了你的数据。你希望我分析什么?"),
SamplingMessage(role="user", content=user_query)
]
response = await ctx.sample(
messages=messages,
system_prompt="你是数据分析师。根据对话上下文提供详细见解。",
temperature=0.3
)
return response.text
客户端要求
LLM 采样需要客户端支持:
- 客户端必须实现采样处理器来处理请求
- 如果客户端不支持采样,调用 ctx.sample() 会失败
使用场景
Sampling(采样)在MCP中的使用场景主要是利用客户端的大语言模型(LLM)进行文本生成和智能推理,适用于需要调用AI能力辅助处理的场景。具体来说,常见使用场景包括:
-
文本生成
- 生成内容摘要、报告、总结、描述等文本
- 自动写作,比如生成故事、邮件、文案等
-
自然语言理解与分析
- 进行情感分析、意图识别、关键词提取
- 技术文档解析、数据解读等复杂文本分析
-
对话和交互
- 实现多轮对话,智能问答助手
- 根据上下文动态生成回复内容
-
代码生成与示例
- 自动生成代码片段、示例程序
- 代码解释和调试辅助
-
决策辅助和推理
- 通过语言模型帮助做推断和建议
- 复杂场景下的辅助决策支持
-
动态内容生成
- 根据用户输入或数据实时生成个性化内容
- 适应多变的需求,灵活响应用户
总结:Sampling使MCP工具能够“借助”客户端的强大语言模型,动态生成文本或智能分析,而无需服务器端自行实现复杂的自然语言处理逻辑。这既节省了服务器资源,也提升了交互的智能化水平。
在实际生产环境中,MCP 的 Sampling 功能被广泛应用于多种场景,尤其是在需要结合语言模型生成、数据处理和用户交互的复杂任务中。以下是几个典型的生产案例,展示了 Sampling 在实际业务中的应用:
-
微博内容情感分析与数据查询
在社交媒体数据分析平台中,MCP 被用于处理用户的自然语言查询,结合数据库查询结果并进行情感分析。通过 Sampling,服务端将查询结果传递给 LLM 进行情感分类,返回“积极”、“消极”或“中性”的分析结果。这种方式使得用户能够以自然语言提问并获取结构化的分析反馈。(优快云)
代码示例:
from fastmcp import FastMCP, Context from fastmcp.client.sampling import SamplingMessage mcp = FastMCP("SentimentAnalysis") @mcp.tool async def analyze_sentiment(text: str, ctx: Context) -> dict: """Analyze sentiment of text using LLM""" prompt = f"Analyze the sentiment of the following text: {text}" response = await ctx.sample(messages=prompt) sentiment = response.text.strip().lower() return {"sentiment": sentiment} -
多轮对话式数据分析
在数据分析助手中,MCP 允许通过多轮对话结构与用户交互。通过 Sampling,系统可以生成多轮对话的提示,获取用户的反馈,并基于此进行进一步的数据分析。这种方式增强了用户体验,使得数据查询更加自然和互动。
代码示例:
from fastmcp import FastMCP, Context from fastmcp.client.sampling import SamplingMessage mcp = FastMCP("DataAnalysisAssistant") @mcp.tool async def multi_turn_analysis(user_query: str, context_data: str, ctx: Context) -> str: """Perform analysis using multi-turn conversation structure.""" messages = [ SamplingMessage(role="user", content=f"Here is the data: {context_data}"), SamplingMessage(role="assistant", content="What would you like me to analyze?"), SamplingMessage(role="user", content=user_query) ] response = await ctx.sample(messages=messages) return response.text -
生成式内容创作与代码示例
在内容创作平台中,MCP 被用于根据用户提供的主题生成创意内容或代码示例。通过 Sampling,系统可以根据预设的提示生成符合用户需求的文本或代码,提升创作效率。
代码示例:
from fastmcp import FastMCP, Context mcp = FastMCP("CreativeWriting") @mcp.tool async def generate_code_example(concept: str, ctx: Context) -> str: """Generate a Python code example for a given concept.""" prompt = f"Write a Python code example demonstrating '{concept}'." response = await ctx.sample(messages=prompt) return response.text -
数据迁移与多阶段进度报告
在数据迁移任务中,MCP 结合 Sampling 和进度报告功能,分阶段执行数据迁移操作,并在每个阶段报告进度。通过 Sampling,系统可以生成每个阶段的提示,指导迁移过程,并确保用户了解当前进度。
代码示例:
from fastmcp import FastMCP, Context import asyncio mcp = FastMCP("DataMigration") @mcp.tool async def data_migration(source: str, destination: str, ctx: Context) -> str: """Migrate data with multi-stage progress reporting.""" stages = ["Validation", "Export", "Transform", "Import"] for i, stage in enumerate(stages): await ctx.info(f"Starting {stage} stage") await ctx.report_progress(progress=i + 1, total=len(stages)) await asyncio.sleep(1) # Simulate stage duration await ctx.report_progress(progress=len(stages), total=len(stages)) return f"Data migration from {source} to {destination} completed"
这些案例展示了 MCP Sampling 在实际生产环境中的多样化应用,包括自然语言处理、数据分析、内容生成和任务进度管理等方面。通过 Sampling,开发者可以构建更加智能和互动的系统,提升用户体验和业务效率。
如需进一步了解 MCP Sampling 的实现细节或获取完整的代码示例,建议参考以下资源:
- 基于MCP的数据智能查询应用实现:利用Sampling技术实现微博内容的情感分析
- A Journey from AI to LLMs and MCP - 10 - Sampling and Prompts in MCP
- MCP Examples — Model Context Protocol (MCP) Python SDK documentation
MCP 中间件(MCP Middleware)
为你的 MCP 服务器添加横切功能(cross-cutting functionality),使用中间件来拦截、修改并响应所有 MCP 请求与响应。
新增于版本:2.9.0
MCP 中间件是一个强大的概念,它允许你为 FastMCP 服务器添加横切功能。不同于传统 Web 中间件,MCP 中间件是专为模型上下文协议(Model Context Protocol, MCP)设计的,提供了可插入钩子,用于处理各种 MCP 操作,比如工具调用(tool calls)、资源读取(resource reads)和提示请求(prompt requests)。
MCP 中间件是 FastMCP 专属概念,它不属于官方 MCP 协议规范的一部分。该中间件系统专为 FastMCP 服务器设计,可能与其他 MCP 实现不兼容。
由于 MCP 中间件是一个全新功能,在未来版本中可能会有不兼容的改动。
什么是 MCP 中间件?
MCP 中间件可以让你在请求和响应流经服务器时拦截并修改它们。你可以将其想象成一个“处理管道”,每个中间件组件都可以:
- 检查当前发生了什么(请求内容和上下文)
- 对其进行修改
- 然后将控制权传递给管道中的下一个中间件
MCP 中间件的常见用途包括:
- 认证与授权:在执行操作前验证客户端权限
- 日志记录与监控:追踪使用模式与性能指标
- 请求限流:根据客户端或操作类型限制请求频率
- 请求/响应转换:在数据到达工具前或离开之后进行修改
- 缓存机制:存储频繁访问的数据以提升性能
- 错误处理:在整个服务器范围内提供统一的错误响应
中间件的工作原理
FastMCP 中间件基于管道模型运作。当一个请求进入服务器时,它会按照你注册中间件的顺序依次通过每个中间件。每个中间件可以:
- 检查传入请求及其上下文;
- 在传递给下一个中间件或处理器之前,修改请求;
- 通过调用
call_next()执行下一个中间件或处理器; - 在返回响应之前检查和修改响应;
- 处理请求处理过程中的错误。
关键在于:中间件形成一条链,每个中间件都可以决定是否继续传递,或终止整个处理流程。
如果你熟悉 ASGI 中间件,FastMCP 中间件的基本结构对你来说会非常熟悉。本质上,中间件是一个可调用类,它接收一个包含当前 JSON-RPC 消息信息的上下文对象(context)和一个用于继续中间件链的处理函数(call_next())。
需要注意的是,MCP 基于 JSON-RPC 协议。虽然 FastMCP 提供了类 HTTP 的请求和响应接口,但它本质上处理的是 JSON-RPC 消息,而不是传统的 HTTP 请求/响应对。FastMCP 中间件支持所有传输类型,包括本地 stdio 和 HTTP,但并非所有中间件都适用于所有传输方式(例如:检查 HTTP 头信息的中间件在 stdio 传输中将无效)。
实现中间件最基础的方式是重写 Middleware 基类中的 __call__ 方法,例如:
from fastmcp.server.middleware import Middleware, MiddlewareContext
class RawMiddleware(Middleware):
async def __call__(self, context: MiddlewareContext, call_next):
# 该方法会接收所有类型的消息
print(f"处理中间件:{context.method}")
result = await call_next(context)
print(f"完成中间件:{context.method}")
return result
这种方式给你对服务中所有消息的完全控制权,但也意味着你需要手动处理所有消息类型。
中间件钩子(Middleware Hooks)
为了让开发者更方便地精确定位想要拦截的消息类型,FastMCP 提供了多个专用钩子方法。你可以选择重写这些特定钩子,而不必实现原始的 __call__ 方法,从而使中间件逻辑更加清晰、聚焦。
钩子调用的层级与执行顺序
FastMCP 提供了多个具有不同“粒度”的钩子(hook),从通用到特定。理解它们的调用顺序对于编写高效中间件至关重要。
当一个请求进入时,FastMCP 会按以下层次结构触发多个钩子(从最通用到最具体):
on_message:处理所有 MCP 消息(包括请求和通知)on_request或on_notification:根据消息类型进一步分类- 操作级钩子(如
on_call_tool):仅处理特定 MCP 操作类型
例如:当客户端调用某个工具时,中间件会触发如下钩子链:
-
工具发现阶段(如
list_tools):触发on_message和on_request; -
工具实际调用时:
- 触发
on_message(因为它是任何 MCP 消息) - 触发
on_request(因为工具调用会有返回值) - 触发
on_call_tool(因为调用的是工具)
- 触发
注意:MCP SDK 可能会因缓存等内部目的触发额外的操作,比如自动调用 list_tools,这会产生额外的中间件调用。
这个分层机制让你可以根据需要精确控制中间件逻辑的生效范围:
- 用
on_message做全局日志记录; - 用
on_request做权限控制; - 用
on_call_tool做性能统计或参数校验。
可用钩子一览:
| 钩子名 | 触发条件 |
|---|---|
on_message | 所有 MCP 消息(请求和通知) |
on_request | 所有 MCP 请求(期望返回响应) |
on_notification | 所有 MCP 通知(不期望返回响应) |
on_call_tool | 执行工具时触发 |
on_read_resource | 读取资源时触发 |
on_get_prompt | 获取 prompt 时触发 |
on_list_tools | 获取可用工具列表时触发 |
on_list_resources | 获取资源列表时触发 |
on_list_resource_templates | 获取资源模板列表时触发 |
on_list_prompts | 获取提示词(prompt)列表时触发 |
中间件中的组件访问
在中间件中了解如何访问组件信息(工具、资源、提示词)对于构建强大功能非常关键。列举操作和执行操作的访问方式有显著不同。
列举操作 vs 执行操作
FastMCP 中间件以不同方式处理两类操作:
✅ 列举操作(如 on_list_tools、on_list_resources、on_list_prompts 等):
- 中间件接收到的是包含完整元数据的 FastMCP 组件对象。
- 这些对象包含 FastMCP 特有的属性(如
tags标签),它们并不属于官方 MCP 协议。 - 处理时返回的是组件的完整信息,在最终返回给 MCP 客户端前会转换为标准格式。
- 在返回给客户端时,FastMCP 特有的元数据(如
tags)会被自动剥离。
⚙️ 执行操作(如 on_call_tool、on_read_resource、on_get_prompt):
- 中间件在组件实际执行之前运行。
- 你可以决定是否继续执行或抛出错误(如组件未找到、无权限等)。
- 钩子参数中不直接包含组件的元数据。
在执行过程中访问组件元数据
如果你在执行阶段需要检查组件属性(比如标签 tags),可以通过 context 获取 FastMCP 实例来访问组件元数据:
from fastmcp.server.middleware import Middleware, MiddlewareContext
from fastmcp.exceptions import ToolError
class TagBasedMiddleware(Middleware):
async def on_call_tool(self, context: MiddlewareContext, call_next):
if context.fastmcp_context:
try:
tool = await context.fastmcp_context.fastmcp.get_tool(context.message.name)
# 拒绝调用带有 "private" 标签的工具
if "private" in tool.tags:
raise ToolError("拒绝访问:该工具为 private")
# 禁用状态工具不可调用
if not tool.enabled:
raise ToolError("该工具当前已禁用")
except Exception:
# 工具不存在或其他异常,交由正常流程处理
pass
return await call_next(context)
你也可以用类似方式处理资源和提示词(prompt):
from fastmcp.server.middleware import Middleware, MiddlewareContext
from fastmcp.exceptions import ResourceError, PromptError
class ComponentAccessMiddleware(Middleware):
async def on_read_resource(self, context: MiddlewareContext, call_next):
if context.fastmcp_context:
try:
resource = await context.fastmcp_context.fastmcp.get_resource(context.message.uri)
if "restricted" in resource.tags:
raise ResourceError("拒绝访问:受限资源")
except Exception:
pass
return await call_next(context)
async def on_get_prompt(self, context: MiddlewareContext, call_next):
if context.fastmcp_context:
try:
prompt = await context.fastmcp_context.fastmcp.get_prompt(context.message.name)
if not prompt.enabled:
raise PromptError("该提示词当前已禁用")
except Exception:
pass
return await call_next(context)
处理列举操作的结果
对于列举操作,中间件中的 call_next() 会返回尚未转换为 MCP 格式的 FastMCP 组件列表。你可以直接对这些对象进行过滤或修改,然后返回给客户端。
例如,过滤掉带有 private 标签的工具:
from fastmcp.server.middleware import Middleware, MiddlewareContext
class ListingFilterMiddleware(Middleware):
async def on_list_tools(self, context: MiddlewareContext, call_next):
result = await call_next(context)
# 过滤掉带有 "private" 标签的工具
filtered_tools = [
tool for tool in result
if "private" not in tool.tags
]
return filtered_tools
这种过滤发生在组件被转换成标准 MCP 格式之前,因此 FastMCP 特有字段(如 tags)会在最终返回中自动剥离。
钩子结构解剖(Hook Anatomy)
每个中间件钩子都遵循相同的处理模式。下面以 on_message 为例,展示基本结构:
async def on_message(self, context: MiddlewareContext, call_next):
# 1. 前置处理:检查请求内容
print(f"处理中:{context.method}")
# 2. 调用链继续:执行下一个中间件或最终处理逻辑
result = await call_next(context)
# 3. 后置处理:检查或修改响应
print(f"完成处理:{context.method}")
# 4. 返回结果(可修改)
return result
钩子参数说明,每个钩子都接收两个参数:
| 参数名 | 说明 |
|---|---|
context | MiddlewareContext 实例,包含当前请求的上下文信息:- context.method:MCP 方法名(如 "tools/call")- context.source:请求来源(如 "client" 或 "server")- context.type:消息类型(如 "request" 或 "notification")- context.message:完整的 MCP 消息体- context.timestamp:接收请求的时间戳- context.fastmcp_context:FastMCP 的上下文对象(如可用) |
call_next | 一个函数,用于继续执行后续中间件或处理器。你必须调用它来继续处理,除非你打算终止处理流程。 |
控制流能力
你拥有完整的请求控制权:
- ✅ 继续处理:调用
await call_next(context) - ✏️ 修改请求:在调用前修改
context - ✏️ 修改响应:在调用后修改
result - ⛔ 终止链:不调用
call_next(较少使用) - ⚠️ 错误处理:用 try/catch 包裹
call_next调用
创建中间件
在 FastMCP 中,你可以通过继承 Middleware 基类并重写所需钩子方法来实现中间件功能。你只需要实现与你的使用场景相关的钩子即可。
from fastmcp import FastMCP
from fastmcp.server.middleware import Middleware, MiddlewareContext
class LoggingMiddleware(Middleware):
"""记录所有 MCP 操作的中间件"""
async def on_message(self, context: MiddlewareContext, call_next):
"""处理所有 MCP 消息的钩子函数"""
print(f"正在处理:{context.method}(来源:{context.source})")
result = await call_next(context)
print(f"已完成处理:{context.method}")
return result
# 将中间件添加到服务器
mcp = FastMCP("MyServer")
mcp.add_middleware(LoggingMiddleware())
这段代码创建了一个基本的日志中间件,它会打印所有流经服务器的请求信息。
向服务器添加中间件
✅ 添加单个中间件
向服务器添加中间件非常简单:
mcp = FastMCP("MyServer")
mcp.add_middleware(LoggingMiddleware())
✅ 添加多个中间件
多个中间件会按添加顺序依次执行:
- 添加顺序决定了请求进入(pre-processing)时的调用顺序;
- 同样也决定了响应返回(post-processing)时的逆序调用顺序。
mcp = FastMCP("MyServer")
mcp.add_middleware(AuthenticationMiddleware("secret-token"))
mcp.add_middleware(PerformanceMiddleware())
mcp.add_middleware(LoggingMiddleware())
该配置的执行流程如下:
请求进入阶段:
1. AuthenticationMiddleware(前置处理)
2. PerformanceMiddleware(前置处理)
3. LoggingMiddleware(前置处理)
4. 实际的工具 / 资源处理逻辑
响应返回阶段:
5. LoggingMiddleware(后置处理)
6. PerformanceMiddleware(后置处理)
7. AuthenticationMiddleware(后置处理)
服务组合与中间件(Server Composition and Middleware)
当你使用 mount 或 import_server 来进行服务组合时,中间件的行为遵循以下规则:
- 父服务器的中间件会处理所有请求,包括那些被路由到挂载子服务器的请求;
- 子服务器的中间件只会处理由该子服务器处理的请求;
- 每个服务器内部的中间件执行顺序保持添加顺序;
这意味着你可以创建分层中间件架构:
- 父服务器负责处理全局性的问题(例如:认证、权限验证);
- 子服务器则专注于领域特定的中间件逻辑(例如:日志记录、数据校验等)。
# 父服务器添加认证中间件
parent = FastMCP("Parent")
parent.add_middleware(AuthenticationMiddleware("token"))
# 子服务器添加日志中间件
child = FastMCP("Child")
child.add_middleware(LoggingMiddleware())
@child.tool
def child_tool() -> str:
return "from child"
# 挂载子服务器到父服务器
parent.mount(child, prefix="child")
请求执行流程:
当客户端调用 child_tool 时,请求将按以下顺序执行中间件:
- 父服务器的 AuthenticationMiddleware —— 验证身份;
- 请求被路由到子服务器;
- 子服务器的 LoggingMiddleware —— 记录日志;
- 最终调用
child_tool工具函数。
这套机制非常适合构建模块化、可插拔的中间件体系。例如,你可以将认证逻辑集中在父服务中,而将业务逻辑相关的限流、审计等中间件放在子服务中,彼此职责清晰。
内置中间件示例(Built-in Middleware Examples)
FastMCP 提供了多个内置中间件示例,展示了最佳实践,并可立即用于实际项目。
一、性能监控中间件(Timing Middleware)
性能监控对于理解服务器行为和识别性能瓶颈至关重要。FastMCP 在 fastmcp.server.middleware.timing 中内置了时间中间件。
简化示例:
import time
from fastmcp.server.middleware import Middleware, MiddlewareContext
class SimpleTimingMiddleware(Middleware):
async def on_request(self, context: MiddlewareContext, call_next):
start_time = time.perf_counter()
try:
result = await call_next(context)
duration_ms = (time.perf_counter() - start_time) * 1000
print(f"Request {context.method} completed in {duration_ms:.2f}ms")
return result
except Exception as e:
duration_ms = (time.perf_counter() - start_time) * 1000
print(f"Request {context.method} failed after {duration_ms:.2f}ms: {e}")
raise
完整版本使用方式:
from fastmcp.server.middleware.timing import (
TimingMiddleware,
DetailedTimingMiddleware
)
mcp.add_middleware(TimingMiddleware()) # 基础时间记录
mcp.add_middleware(DetailedTimingMiddleware()) # 针对工具/资源/提示的详细耗时
内置版本包括自定义日志记录器支持和规范的格式输出,此外 DetailedTimingMiddleware 还提供了如 on_call_tool 和 on_read_resource 等针对具体操作的钩子方法,用于实现更精细的耗时统计。
二、日志记录中间件(Logging Middleware)
日志记录对于调试、监控和了解服务器使用模式至关重要。FastMCP 在 fastmcp.server.middleware.logging 中提供了强大的日志中间件。
简化示例:
from fastmcp.server.middleware import Middleware, MiddlewareContext
class SimpleLoggingMiddleware(Middleware):
async def on_message(self, context: MiddlewareContext, call_next):
print(f"Processing {context.method} from {context.source}")
try:
result = await call_next(context)
print(f"Completed {context.method}")
return result
except Exception as e:
print(f"Failed {context.method}: {e}")
raise
完整版本使用方式:
from fastmcp.server.middleware.logging import (
LoggingMiddleware,
StructuredLoggingMiddleware
)
mcp.add_middleware(LoggingMiddleware(
include_payloads=True,
max_payload_length=1000
))
mcp.add_middleware(StructuredLoggingMiddleware(include_payloads=True)) # JSON结构化日志
内置版本支持负载日志记录、结构化的 JSON 输出、自定义日志记录器、负载大小限制,以及用于精细控制的操作级钩子方法。
三、限流中间件(Rate Limiting Middleware)
限流对于保护服务器免受滥用、确保资源公平使用以及在高负载下维持性能至关重要。FastMCP 在 fastmcp.server.middleware.rate_limiting 中包含了复杂的限流中间件。
下面是一个示例,展示了它的工作原理:
import time
from collections import defaultdict
from fastmcp.server.middleware import Middleware, MiddlewareContext
from mcp import McpError
from mcp.types import ErrorData
class SimpleRateLimitMiddleware(Middleware):
def __init__(self, requests_per_minute: int = 60):
self.requests_per_minute = requests_per_minute
self.client_requests = defaultdict(list)
async def on_request(self, context: MiddlewareContext, call_next):
current_time = time.time()
client_id = "default" # 实际中应从 headers/context 获取
# 清除过期请求
cutoff_time = current_time - 60
self.client_requests[client_id] = [
t for t in self.client_requests[client_id] if t > cutoff_time
]
if len(self.client_requests[client_id]) >= self.requests_per_minute:
raise McpError(ErrorData(code=-32000, message="Rate limit exceeded"))
self.client_requests[client_id].append(current_time)
return await call_next(context)
完整版本使用方式:
from fastmcp.server.middleware.rate_limiting import (
RateLimitingMiddleware,
SlidingWindowRateLimitingMiddleware
)
mcp.add_middleware(RateLimitingMiddleware(
max_requests_per_second=10.0,
burst_capacity=20
))
mcp.add_middleware(SlidingWindowRateLimitingMiddleware(
max_requests=100,
window_minutes=1
))
内置版本包括令牌桶算法、基于客户端的识别、全局限流,以及支持异步安全的实现,并且提供可配置的客户端识别功能。
四、错误处理中间件(Error Handling Middleware)
一致的错误处理机制对构建稳定的 MCP 服务非常关键。FastMCP 提供了功能全面的错误处理中间件。
简化示例:
import logging
from fastmcp.server.middleware import Middleware, MiddlewareContext
class SimpleErrorHandlingMiddleware(Middleware):
def __init__(self):
self.logger = logging.getLogger("errors")
self.error_counts = {}
async def on_message(self, context: MiddlewareContext, call_next):
try:
return await call_next(context)
except Exception as error:
error_key = f"{type(error).__name__}:{context.method}"
self.error_counts[error_key] = self.error_counts.get(error_key, 0) + 1
self.logger.error(f"Error in {context.method}: {type(error).__name__}: {error}")
raise
完整版本使用方式:
from fastmcp.server.middleware.error_handling import (
ErrorHandlingMiddleware,
RetryMiddleware
)
mcp.add_middleware(ErrorHandlingMiddleware(
include_traceback=True,
transform_errors=True,
error_callback=my_error_callback
))
mcp.add_middleware(RetryMiddleware(
max_retries=3,
retry_exceptions=(ConnectionError, TimeoutError)
))
内置版本包括错误转换、自定义回调、可配置的重试逻辑,以及规范的 MCP 错误格式化。
五、组合中间件使用(Combining Middleware)
这些中间件可以无缝组合使用:
from fastmcp import FastMCP
from fastmcp.server.middleware.timing import TimingMiddleware
from fastmcp.server.middleware.logging import LoggingMiddleware
from fastmcp.server.middleware.rate_limiting import RateLimitingMiddleware
from fastmcp.server.middleware.error_handling import ErrorHandlingMiddleware
mcp = FastMCP("Production Server")
# 合理顺序添加中间件
mcp.add_middleware(ErrorHandlingMiddleware())
mcp.add_middleware(RateLimitingMiddleware(max_requests_per_second=50))
mcp.add_middleware(TimingMiddleware())
mcp.add_middleware(LoggingMiddleware())
@mcp.tool
def my_tool(data: str) -> str:
return f"Processed: {data}"
此配置提供了全面的监控、保护与可观测性。
六、自定义中间件示例(Custom Middleware Example)
你也可以通过继承基础类自定义中间件:
from fastmcp.server.middleware import Middleware, MiddlewareContext
class CustomHeaderMiddleware(Middleware):
async def on_request(self, context: MiddlewareContext, call_next):
print(f"Processing {context.method}")
result = await call_next(context)
print(f"Completed {context.method}")
return result
mcp.add_middleware(CustomHeaderMiddleware())
这可以帮助你快速添加特定逻辑,例如添加自定义 Header、统计信息、校验字段等。
Authentication
Bearer Auth
使用 JWT Bearer Token 对 FastMCP 服务器的 HTTP 接口进行安全认证。
新增于版本:2.6.0
⚠️ 认证与授权机制仅适用于基于 HTTP 的传输方式(如 http 和 sse)。
根据 MCP 协议规范,服务器应支持完整的 OAuth 2.1 流程,包括:
- 动态客户端注册
- 授权服务器元数据发现
- 完整的 token 获取端点
但这些流程往往对服务间通信(如微服务架构)来说过于繁琐。因此,FastMCP 提供了一种更简洁实用的替代方案:直接验证预签发的 JWT Token。
这在自动化程序环境下尤其实用(如系统对系统调用),并符合当前 MCP 实际生态的发展趋势。
但请注意,由于未实现完整 OAuth 2.1 流程,该方式并不严格符合 MCP 官方规范。
什么是 Bearer Token?
Bearer Token 是一种常见的 HTTP API 安全认证方式,流程如下:
-
客户端通过 HTTP 请求头中的
Authorization字段携带 Token:Authorization: Bearer <JWT> -
服务器接收到后,验证该 Token 的合法性:
- 签名是否有效
- Token 是否过期
- Token 中的权限范围是否允许访问当前资源等
-
验证通过则允许访问,否则拒绝。
FastMCP 的认证策略
FastMCP 使用 非对称加密 来验证 JWT Token,具有如下优势:
- ✅ 无共享密钥:FastMCP 服务不需要知道任何私钥或客户端密钥
- ✅ 公钥校验:只需一个公钥(或 JWKS 端点)即可验证 token 签名
- ✅ 令牌签发安全:Token 是由外部服务使用私钥签发的,私钥不会泄露给 FastMCP
- ✅ 支持水平扩展:多个 FastMCP 实例可同时验证 token,无需共享密钥或协调状态
这种架构允许你在不破坏安全边界的前提下,将 FastMCP 集成到已有认证体系中。
配置
要在你的 FastMCP 服务器上启用 Bearer Token 验证,需要使用 BearerAuthProvider 类。该提供者通过验证签名、检查过期时间,以及(可选的)验证声明,来校验传入的 JWT。
BearerAuthProvider 只负责验证 Token,不负责签发 Token(也不实现任何 OAuth 流程)。你需要另行生成 Token,可以使用 FastMCP 提供的工具,或者使用外部身份提供者(IdP)或 OAuth 2.1 授权服务器。
配置 Bearer Token 认证时,实例化一个 BearerAuthProvider,并将其传入 FastMCP 实例的 auth 参数。
BearerAuthProvider 需要提供静态公钥(public key)或 JWKS URI(两者只能二选一),用于验证 Token 签名。其他参数都是可选的,如果提供,将作为附加验证条件。
from fastmcp import FastMCP
from fastmcp.server.auth import BearerAuthProvider
auth = BearerAuthProvider(
jwks_uri="https://my-identity-provider.com/.well-known/jwks.json",
issuer="https://my-identity-provider.com/",
algorithm="RS512",
audience="my-mcp-server"
)
mcp = FastMCP(name="My MCP Server", auth=auth)
BearerAuthProvider 配置
| 参数名 | 类型 | 说明 |
|---|---|---|
public_key | str | 用于静态密钥验证的 RSA 公钥,PEM 格式。如果未提供 jwks_uri,则必填。 |
jwks_uri | str | JSON Web Key Set 的 URL 地址。如果未提供 public_key,则必填。 |
issuer | str 或 None | 预期的 JWT iss(发行者)声明值。 |
algorithm | str 或 None | 用于解码 JWT Token 的算法,默认为 RS256。 |
audience | str 或 None | 预期的 JWT aud(受众)声明值。 |
required_scopes | list[str] 或 None | 所有请求必须具备的全局权限范围。 |
静态公钥示例
如果你有 PEM 格式的公钥,可以直接以字符串形式传入 BearerAuthProvider:
from fastmcp.server.auth import BearerAuthProvider
import inspect
public_key_pem = inspect.cleandoc(
"""
-----BEGIN PUBLIC KEY-----
MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAy...
-----END PUBLIC KEY-----
"""
)
auth = BearerAuthProvider(public_key=public_key_pem)
JWKS URI 示例
provider = BearerAuthProvider(
jwks_uri="https://idp.example.com/.well-known/jwks.json"
)
推荐在生产环境使用 JWKS,因为它支持自动密钥轮换和多重签名密钥管理。
生成 Token
为了方便开发和测试,FastMCP 提供了 RSAKeyPair 工具类,可以在无需外部 OAuth 提供者的情况下生成 Token。
RSAKeyPair 工具仅适用于开发和测试环境,生产环境应使用正规的 OAuth 2.1 授权服务器或身份提供者。
from fastmcp import FastMCP
from fastmcp.server.auth import BearerAuthProvider
from fastmcp.server.auth.providers.bearer import RSAKeyPair
# 生成一对新的密钥
key_pair = RSAKeyPair.generate()
# 使用公钥配置认证提供者
auth = BearerAuthProvider(
public_key=key_pair.public_key,
issuer="https://dev.example.com",
audience="my-dev-server"
)
mcp = FastMCP(name="Development Server", auth=auth)
# 生成一个用于测试的 Token
token = key_pair.create_token(
subject="dev-user",
issuer="https://dev.example.com",
audience="my-dev-server",
scopes=["read", "write"]
)
print(f"Test token: {token}")
Token 创建参数说明
| 参数名 | 类型 | 说明 | 默认值 |
|---|---|---|---|
subject | str | JWT 的 subject 声明(通常是用户 ID) | “fastmcp-user” |
issuer | str | JWT 的 issuer 声明 | “https://fastmcp.example.com” |
audience | str 或 None | JWT 的 audience 声明 | 无 |
scopes | list[str] 或 None | 要包含的 OAuth 权限范围 | 无 |
expires_in_seconds | int | Token 的过期时间(秒) | 3600 |
additional_claims | dict 或 None | 额外需要包含在 Token 中的声明 | 无 |
kid | str 或 None | JWKS 查找用的密钥 ID | 无 |
访问 Token 声明
认证通过后,你的工具、资源或提示(prompts)可以通过依赖函数 get_access_token() 访问 Token 信息:
from fastmcp import FastMCP, Context, ToolError
from fastmcp.server.dependencies import get_access_token, AccessToken
@mcp.tool
async def get_my_data(ctx: Context) -> dict:
access_token: AccessToken = get_access_token()
user_id = access_token.client_id # 来自 JWT 的 'sub' 或 'client_id' 声明
user_scopes = access_token.scopes
if "data:read_sensitive" not in user_scopes:
raise ToolError("权限不足:需要 'data:read_sensitive' 范围。")
return {
"user": user_id,
"sensitive_data": f"{user_id} 的私有数据",
"granted_scopes": user_scopes
}
AccessToken 属性说明
| 属性 | 类型 | 说明 |
|---|---|---|
token | str | 原始 JWT 字符串 |
client_id | str | 认证主体标识符 |
scopes | list[str] | 授权范围(Scopes) |
expires_at | datetime 或 None | Token 过期时间戳 |
基于已有鉴权中心进行认证
笔者这里有个golang OPENAPI项目,打算写一个mcp服务暴露出去,这样就不用每次和别的项目组开发了。但接口需要一个token参数,这个参数应该由mcp调用方传入,那么就不适用于提供的Bearer auth流程!
这个需求可以总结为两步:
- 调用方通过 MCP 调用你的 Tool / Prompt / Resource 时,把自己的 token 传给 FastMCP server
- 你在 FastMCP 服务端的 Tool 函数中获取这个 token,并转发给你的 Go 接口调用
这个流程 FastMCP 是支持的,不过它默认是用于认证用的 token,比如 JWT。但你完全可以把它当作普通的业务参数来传,也可以自定义方案。
✅ 方案一:让调用方通过 MCP 的 Context header 传 token(推荐)
FastMCP 的请求上下文 Context 支持读取调用时的 headers,如果你让调用方把 token 放在 MCP 请求的 headers 里,例如:
{
"headers": {
"x-auth-token": "abc123"
}
}
然后你在 Tool 函数中这样取出:
from fastmcp import Context
@mcp.tool
async def call_my_go_api(ctx: Context) -> dict:
token = ctx.headers.get("x-auth-token") # 自定义 header
if not token:
raise ToolError("缺少认证 token")
# 拿 token 去请求你的 Go 接口
response = requests.get("http://go-api.example.com/data", headers={
"Authorization": f"Bearer {token}"
})
return response.json()
✅ 优点:
- 安全:调用方不会把 token 放在参数里,而是放在 headers 里,符合接口调用习惯。
- 灵活:你可以支持多种 header,例如
x-auth-token、authorization、x-api-key等。 - 支持复用:比如多个 tool 都可以读取这个 token。
🟡 方案二:把 token 当作参数传给 Tool 函数
调用方可以直接传参:
{
"token": "abc123"
}
然后你定义函数:
@mcp.tool
async def call_go_api(token: str) -> dict:
response = requests.get("http://go-api.example.com/data", headers={
"Authorization": f"Bearer {token}"
})
return response.json()
缺点:
- 不符合“Token 是认证信息,不应该作为普通参数”的惯例
- 如果 LLM 自动调用,会被误引导以为 token 是 prompt 参数
- 暴露 token 风险更高(容易在日志、训练数据中泄漏)
具体调用链是这样的:
LangGraph Agent ──(Function Call + Token)──▶ FastMCP Tool ──(带 Token 请求)──▶ 你的 Go 后端服务
✅ 推荐方案:要求 Agent 在 MCP 请求中添加 Token header,你用 Context 读取
✅ 第一步:Agent 添加自定义 Header
你可以要求 LangGraph 代理在执行 MCP Function Call 时添加自定义 header,比如:
POST /mcp/tool/call
Authorization: Bearer <token> <-- 或你自己定义的 header,如 X-API-Token
LangGraph 中可以通过 Tool Call Chain 的 context 或 request headers 设置来添加:
from langgraph.graph import END
from openai import OpenAI
client = OpenAI()
tools = [
{
"type": "function",
"function": {
"name": "call_go_api",
"description": "调用外部服务",
"parameters": {
"type": "object",
"properties": {}
}
}
}
]
# 加 token 到请求头
client.headers.update({
"x-auth-token": "my-user-token"
})
✅ 第二步:FastMCP 中读取 token 并调用你 Go API
from fastmcp import Context
import requests
@mcp.tool
async def call_go_api(ctx: Context) -> dict:
token = ctx.headers.get("x-auth-token") # 从调用上下文 header 获取 token
if not token:
raise ToolError("Missing x-auth-token")
# 调用你后端的 Go 接口
resp = requests.get("http://your-go-api.internal/data", headers={
"Authorization": f"Bearer {token}"
})
if not resp.ok:
raise ToolError(f"Backend error: {resp.status_code}")
return resp.json()
🧠 说明:为什么不用直接在参数里传 token?
你 可以 让 Agent 把 token 当作参数传入,例如:
{
"token": "abc123"
}
然后:
@mcp.tool
def xxx(token: str): ...
但这样的问题是:
- 不安全(容易被暴露在日志、数据中)
- LangGraph Agent 不会自动知道
token是敏感信息(它可能随便填一个) - token 会作为 Function Schema 参数暴露给 LLM —— 这很危险!
✅ 如果你希望做身份校验(不是纯转发)
可以开启 FastMCP 的认证机制:
from fastmcp.server.auth import BearerAuthProvider
auth = BearerAuthProvider(
jwks_uri="https://your-idp.com/.well-known/jwks.json",
audience="your-mcp-server"
)
mcp = FastMCP(name="MyMCP", auth=auth)
然后你在 tool 里用:
from fastmcp.server.dependencies import get_access_token
token = get_access_token()
print(token.client_id)
print(token.scopes)
这样就可以实现 基于 Token 的权限控制 + 安全验证。
FAQ
如何在中间件提前返回Json数据
假设我们针对tool写了一些认证中间件,那么如何在认证失败的时候统一返回一个Json数据呢?
可以看到对于中间件,要求的返回值是:mt.CallToolResult,但你如果直接拼接CallToolResult返回会报错,
class CallToolResult(Result):
"""The server's response to a tool call."""
content: list[ContentBlock]
structuredContent: dict[str, Any] | None = None
"""An optional JSON object that represents the structured result of the tool call."""
isError: bool = False
因为对于工具,fastmcp会调用他的to_mcp_result方法来格式化为协议接受的格式,因此我们可以再往下走一层:
from fastmcp.tools.tool import ToolResult
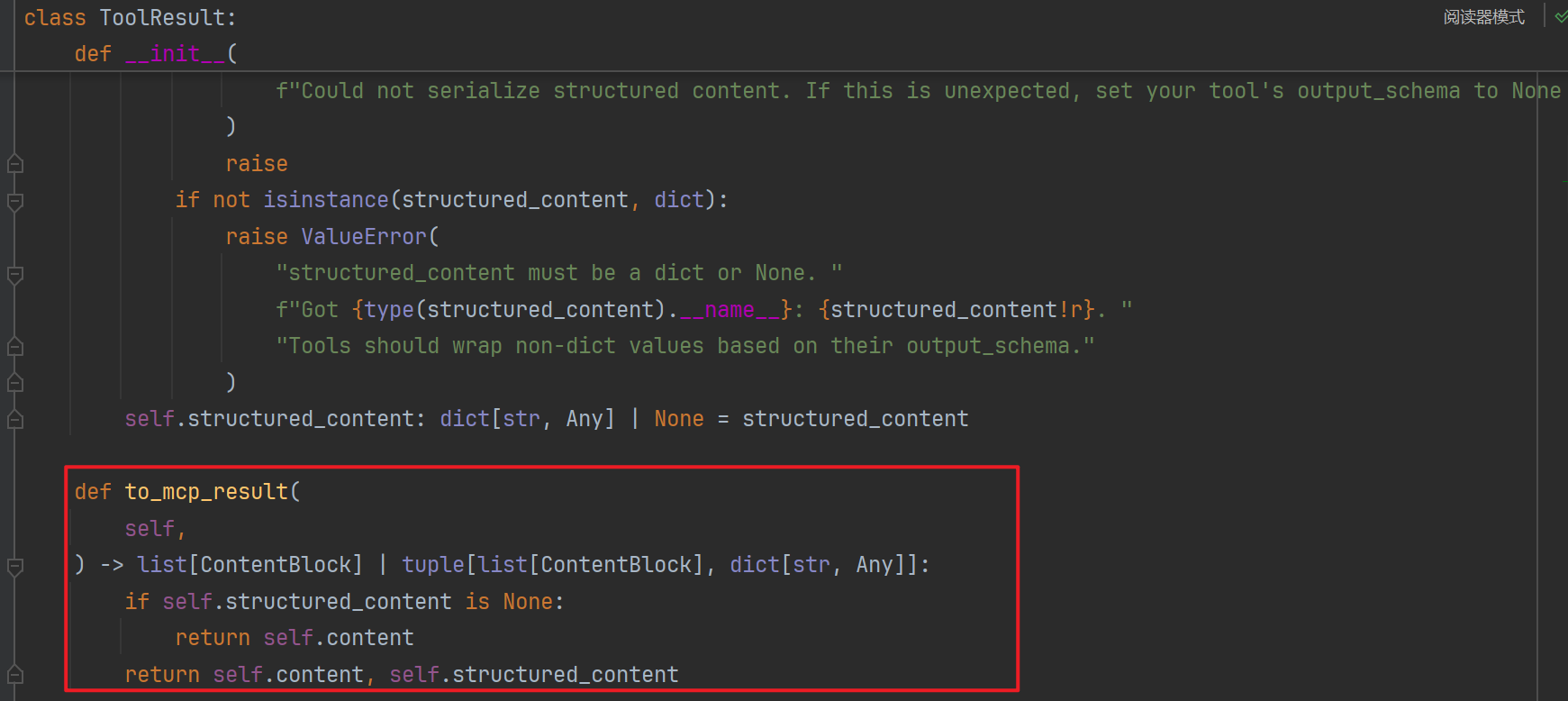
可以看到ToolResult是有这个方法的,因此我们需要返回的实际上是ToolResult:
ToolResult(structured_content={"code":1,"data":[],"msg":"invalid token"})
这样就可以伪造tool结果,替换raise ToolError!
如何发现ToolResult的呢?只需要在middleware打个断点,打开调试模式一步步步入,就可以发现最后工具结果被封装了一层,然后调用他的to_mcp_result。


















 2479
2479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











