




目录
- 日志收集系统选型
- docker搭建ELK
- k8s搭建EFK和ELFK
- 部署步骤
- 创建一个`elastic`名称空间
- 下载官方helm包:[https://github.com/elastic/helm-charts](https://github.com/elastic/helm-charts)
- 阅读配置 Elastic Stack 的安全性:[参考文档](https://www.elastic.co/guide/en/elasticsearch/reference/7.17/configuring-stack-security.html) 选择合适的安全策略
- 为 Elastic Stack 以及安全的 HTTPS 流量设置基本安全性
- 配置证书并启动es
- 启动kibana
- 启动filebeat
- FAQ
日志收集系统选型
ES是基于Lucene(一个全文检索引擎的架构)开发的分布式存储检索引擎,用来存储各类日志。
ES是用JAVA开发的,可通过RESTful Web接口,让用户可以通过浏览器与ES通信。
ES是个分布式搜索和分析引擎,优点是能对大容量的数据进行接近实时的存储、搜索和分析操作。
Kibana是基于Node.js开发的展示工具,可以为Logstash和ES提供图形化的日志分析Web界面展示,可以汇总、分析和搜索重要数据日志。
ELK
Logstash作为数据收集引擎。它支持动态的从各种数据源搜索数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置,一般会发送给ES。
Logstash由JAVA语言编写,运行在JAVA虚拟机(JVM)上,是一款强大的数据处理工具,可以实现数据传输、格式处理、格式化输出。Logstash具有强大的插件功能,常用于日志处理。
日志主要包括日志、应用程序日志和安全日志。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。
往往单台机器的日志使用grep、awk等工具就能基本实现简单分析,但是当日志被分散的储存不同的设备上。如果管理数十上百台服务器,日志的统计和检索又成为一件比较麻烦的事情,一般使用grep、awk和wc等linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
ELK工作流程
- 在所有需要收集日志的服务器上部署Logstash;或者先将日志进行集中化管理在日志服务器上,在日志服务器上部署Logstash。
- Logstash收集日志,将日志格式化并输出到es群集中。
- ES对格式化后的数据进行索引和存储。
- Kibana从ES群集中查询数据生成图表,并进行前端数据的显示。
ELFK
Filebeat是一款轻量级的开源日志文件数据搜索器。通常在需要采集数据的客户端安装Filebeat,并指定目录与日志格式,Filebeat就能快速收集数据,并发送给logstash进行解析,或是直接发给ES存储,性能上相比运行于JVM上的logstash优势明显,是对它的替代。
由于logstash会大量占用系统的内存资源,一般会使用filebeat(golang写的)替换logstash收集日志的功能,组成ELFK架构。

ELFK工作流程
- filebeat将日志收集后交由logstash处理
- logstash进行过滤、格式化等操作,满足过滤条件的数据将发送给ES
- ES对数据进行分片存储,并提供索引功能
- kibana对数据进行图形化的web展示,并提供索引接口
配置差异
提供一个简单的filebeat主配置文件:
[root@filebeat filebeat]# vim filebeat.yml
filebeat.prospectors:
##21行,指定log类型,从日志文件中读取消息
- type: log
##24行,开启日志收集功能,默认为false
enabled: true
##28行,指定监控的日志文件
- /var/log/*.log
##29行,添加收集/var/log/messages
- /var/log/messages
##31行,添加以下内容,注意格式
fields:
service_name: filebeat
log_type: log
service_id: 192.168.122.13
#-------------------------- Elasticsearch output ------------------------------
该区域内容全部注释
#----------------------------- Logstash output --------------------------------
##157行,取消注释
output.logstash:
##159行,取消注释,指定logstash的IP和端口号
hosts: ["192.168.122.12:5044"]
[root@filebeat filebeat]# ./filebeat -e -c filebeat.yml
#启动filebeat,-e记录到stderr并禁用syslog /文件输出,-c指定配置文件
然后将日志输出到logstash
[root@apache conf.d]# vim logstash.conf
input {
beats {
port => "5044"
}
}
output {
elasticsearch {
hosts => ["192.168.122.10:9200", "192.168.122.11:9200"]
index => "%{[fields][service_name]}-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
[root@apache conf.d]# /usr/share/logstash/bin/logstash -f apache_log.conf
抛弃logstash
由于filebeat是由Go构建的,所以部署简单且轻量级,并且可以直接将日志发给ES存储,所以可以不使用logstash。
下载一个filebeat,查看/etc/filebeat/filebeat.yml配置文件:
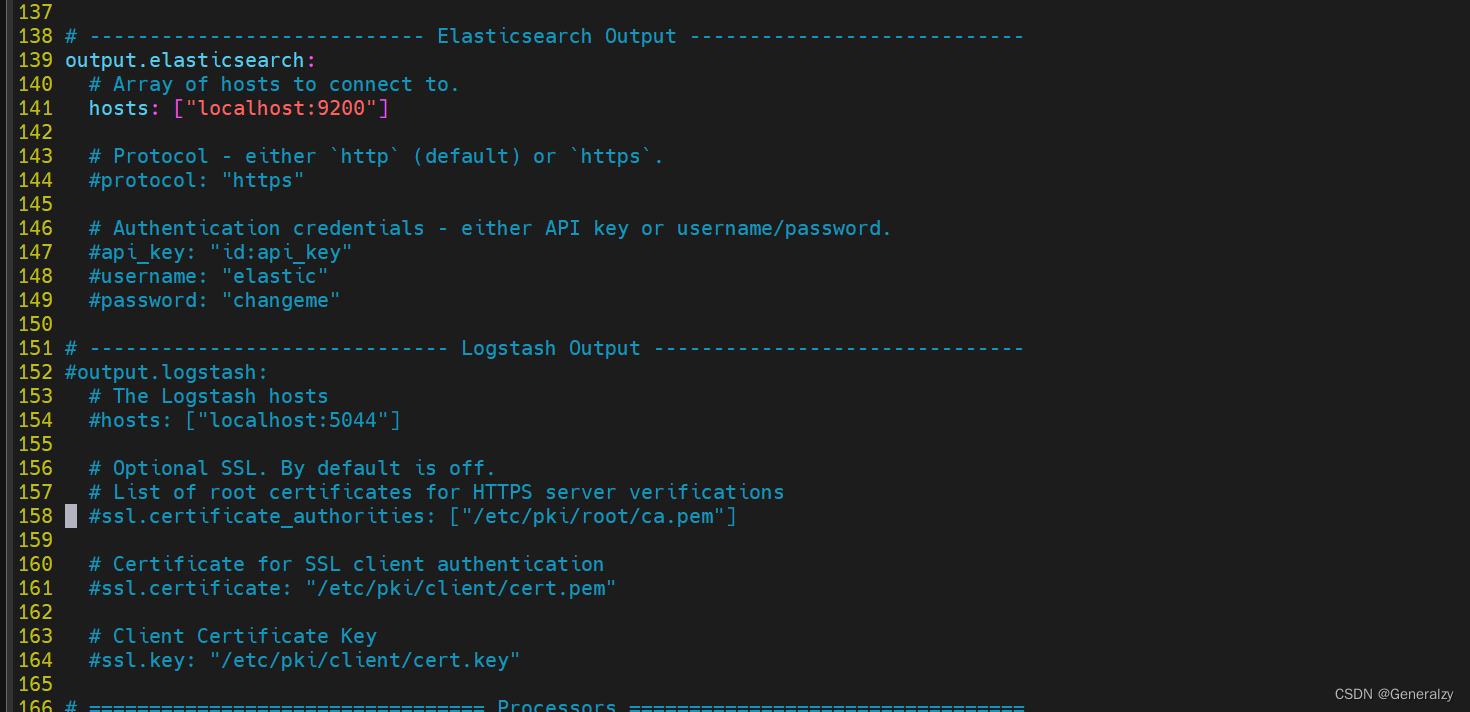
可以看出,此处是可以配置传输到es的协议,用户名密码,CA证书的。
EFK
Fluentd 是一个高效的日志聚合器,是用 Ruby 编写的,并且可以很好地扩展。对于大部分企业来说,Fluentd 足够高效并且消耗的资源相对较少,另外一个工具Fluent-bit更轻量级,占用资源更少,但是插件相对 Fluentd 来说不够丰富,所以整体来说,Fluentd 更加成熟,使用更加广泛。
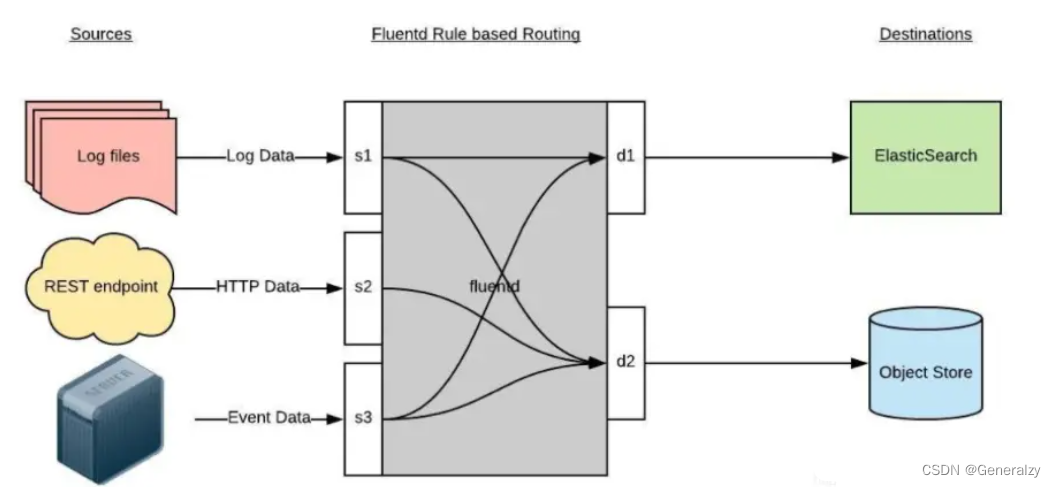
Fluentd 通过一组给定的数据源抓取日志数据,处理后(转换成结构化的数据格式)将它们转发给其他服务,比如 Elasticsearch、对象存储等等
- 首先 Fluentd 从多个日志源获取数据
- 结构化并且标记这些数据
- 然后根据匹配的标签将数据发送到多个目标服务去
配置
fluentd的配置文件看着比较难受
日志源配置
<source>
@id fluentd-containers.log
@type tail # Fluentd 内置的输入方式,其原理是不停地从源文件中获取新的日志。
path /var/log/containers/*.log # 挂载的服务器Docker容器日志地址
pos_file /var/log/es-containers.log.pos
tag raw.kubernetes.* # 设置日志标签
read_from_head true
<parse> # 多行格式化成JSON
@type multi_format # 使用 multi-format-parser 解析器插件
<pattern>
format json # JSON 解析器
time_key time # 指定事件时间的时间字段
time_format %Y-%m-%dT%H:%M:%S.%NZ # 时间格式
</pattern>
<pattern>
format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/
time_format %Y-%m-%dT%H:%M:%S.%N%:z
</pattern>
</parse>
</source>
1、id:表示引用该日志源的唯一标识符,该标识可用于进一步过滤和路由结构化日志数据
2、type:Fluentd 内置的指令,tail 表示 Fluentd 从上次读取的位置通过 tail 不断获取数据,另外一个是 http 表示通过一个 GET 请求来收集数据。
3、path:tail 类型下的特定参数,告诉 Fluentd 采集 /var/log/containers 目录下的所有日志,这是 docker 在 Kubernetes 节点上用来存储运行容器 stdout 输出日志数据的目录。
4、pos_file:检查点,如果 Fluentd 程序重新启动了,它将使用此文件中的位置来恢复日志数据收集。
5、tag:用来将日志源与目标或者过滤器匹配的自定义字符串,Fluentd 匹配源/目标标签来路由日志数据。
路由配置
<match **>
@id elasticsearch
@type elasticsearch
@log_level info
include_tag_key true
type_name fluentd
host "#{ENV['OUTPUT_HOST']}"
port "#{ENV['OUTPUT_PORT']}"
logstash_format true
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size "#{ENV['OUTPUT_BUFFER_CHUNK_LIMIT']}"
queue_limit_length "#{ENV['OUTPUT_BUFFER_QUEUE_LIMIT']}"
overflow_action block
</buffer>
1、match:标识一个目标标签,后面是一个匹配日志源的正则表达式,我们这里想要捕获所有的日志并将它们发送给 Elasticsearch,所以需要配置成**。
2、id:目标的一个唯一标识符。
3、type:支持的输出插件标识符,我们这里要输出到 Elasticsearch,所以配置成 elasticsearch,这是 Fluentd 的一个内置插件。
4、log_level:指定要捕获的日志级别,我们这里配置成 info,表示任何该级别或者该级别以上(INFO、WARNING、ERROR)的日志都将被路由到 Elsasticsearch。
5、host/port:定义 Elasticsearch 的地址,也可以配置认证信息,我们的 Elasticsearch 不需要认证,所以这里直接指定 host 和 port 即可。
6、logstash_format:Elasticsearch 服务对日志数据构建反向索引进行搜索,将 logstash_format 设置为 true,Fluentd 将会以 logstash 格式来转发结构化的日志数据。
7、Buffer: Fluentd 允许在目标不可用时进行缓存,比如,如果网络出现故障或者 Elasticsearch 不可用的时候。缓冲区配置也有助于降低磁盘的 IO。
过滤配置
由于 Kubernetes 集群中应用太多,也还有很多历史数据,所以我们可以只将某些应用的日志进行收集,比如我们只采集具有 logging=true 这个 Label 标签的 Pod 日志,这个时候就需要使用 filter,如下所示
# 删除无用的属性
<filter kubernetes.**>
@type record_transformer
remove_keys $.docker.container_id,$.kubernetes.container_image_id,$.kubernetes.pod_id,$.kubernetes.namespace_id,$.kubernetes.master_url,$.kubernetes.labels.pod-template-hash
</filter>
# 只保留具有logging=true标签的Pod日志
<filter kubernetes.**>
@id filter_log
@type grep
<regexp>
key $.kubernetes.labels.logging
pattern ^true$
</regexp>
</filter>
小结
考虑使用 Logstash 的情况:
-
复杂的数据转换和过滤需求: Logstash 提供强大的过滤和转换功能,适用于复杂的数据处理流程。如果你的数据需要进行复杂的转换、过滤和标准化,Logstash可能是一个不错的选择。
-
已有 Logstash 部署: 如果你的系统已经在使用 Logstash,并且没有遇到性能或其他问题,没有强烈的理由放弃。
-
插件生态系统: Logstash 有一个庞大的插件生态系统,可以很容易地与各种数据源和目的地集成。
考虑不使用 Logstash 的情况:
-
性能和资源消耗: Logstash 相对较重,可能需要更多的资源。如果你有严格的性能要求或者资源受限,可以考虑轻量级的代理,如 Filebeat 和 Fluentd。
-
简化架构: 如果你的数据流程相对简单,不需要复杂的数据转换和过滤,可以考虑使用更简化的架构,例如 Filebeat 直接将数据发送到 Elasticsearch 或者 Fluentd 将数据发送到 Elasticsearch。
-
特定的数据格式或协议: Fluentd 支持更广泛的数据格式和协议,可能更适合一些特定的使用情境。
-
个人偏好: 有时候,个人或团队的偏好也会在选择堆栈时起到重要作用。如果你对某个工具更熟悉或者更喜欢使用某个工具,这也是一个考虑因素。
在做出决策之前,最好在实际环境中进行一些测试和评估,以确保选择的工具满足特定需求,并且在性能和资源消耗方面表现良好。
docker搭建ELK
日志来源
- 使用docker部署nginx,并且提供简单的静态页面服务。
- 将nginx的配置,日志(error.log,access.log),页面统统挂载出来。
启动步骤如下:
-
先启动一个野nginx,然后把上述文件或目录docker cp出来,否则直接启动nginx会造成空目录覆盖镜像里面的文件导致无法启动nginx:
docker run -d --name nginx_test docker exec -it nginx_test bash -
确定文件,进入容器后,根据配置文件定位自己需要的目录:

# 配置目录(我嫌麻烦,一锅端) docker cp nginx_test:/etc/nginx /generalzy/elk/config # 页面目录 docker cp nginx_test:/usr/share/nginx/html /generalzy/elk/html # 日志目录 docker cp nginx_test:/var/log/nginx /genralzy/elk/logs -
修拍配置文件后启动:
docker run -p 30080:80 --name nginx --privileged=true \ -v /generalzy/elk/html:/usr/share/nginx/html \ -v /generalzy/elk/logs/access.log:/var/log/nginx/access.log \ -v /generalzy/elk/logs/error.log:/var/log/nginx/error.log \ -v /generalzy/elk/config:/etc/nginx \ -d nginx -
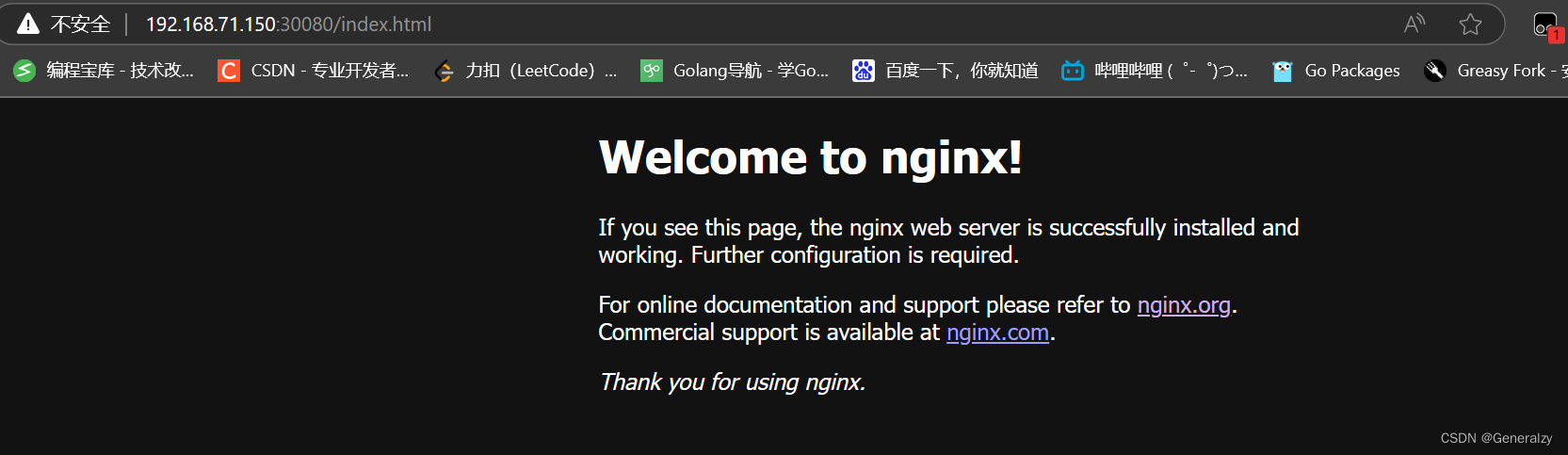
访问nginx
elk介绍
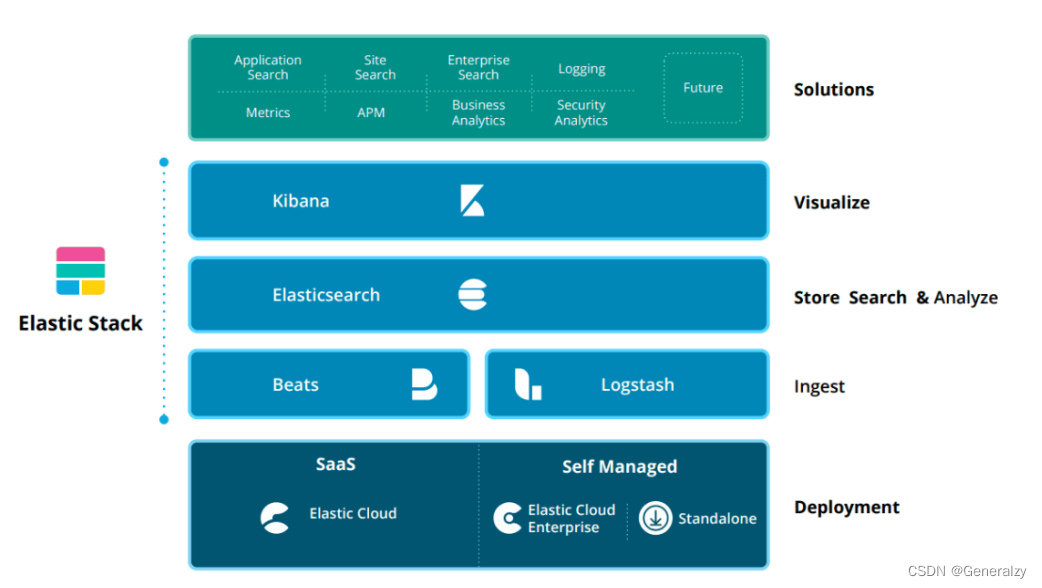
⼀个⽇志系统应该包含以下⼏点:
(1) 收集[collect]:能够采集多种来源的⽇志数据
(2) 传输[transform]:能够稳定的把⽇志数据解析过滤并传输到存储系统
(3) 存储[store]:存储⽇志数据
(4) 分析[analyze]:⽀持 UI 分析
(5) 警告[warning]:能够提供错误报告,监控机制
elasticsearch介绍
elasticsearch是⼀个分布式、⾼扩展、⾼实时的搜索与数据分析引擎,作为存储系统是整个ELK架构的 核⼼。⽤于全⽂检索、结构化搜索、分析。
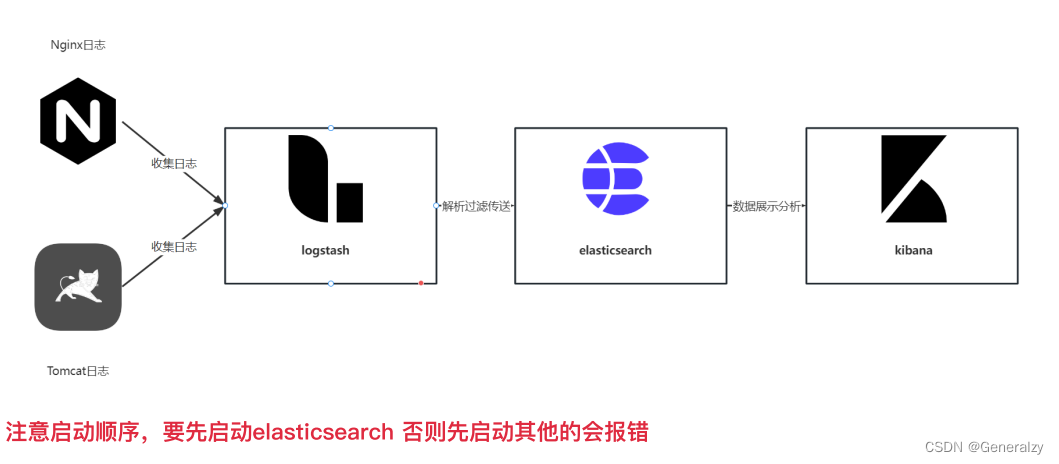
logstash介绍
logstash是开源的数据收集引擎。可以收集不同来源的数据,并将数据解析过滤发送到输出⽬标。
logstash提供了⼤量插件,可解析,丰富,转换和缓冲任何类型的数据。
管道(pipeline) 是logstash中独⽴运⾏的单元。每个管道都必须要包含输⼊(input)、输出(output)以及可选的过滤器(fileter)
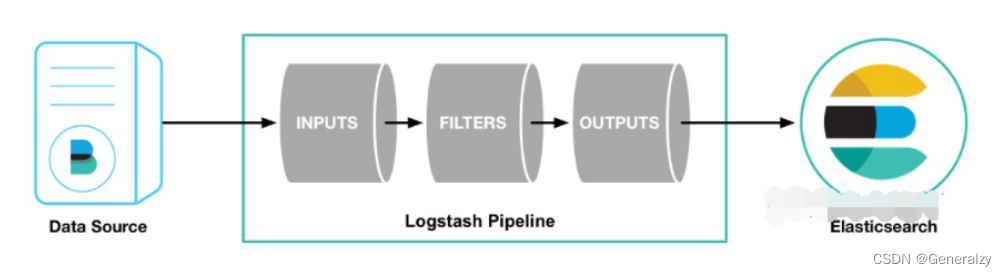
1:inputs 输⼊ 【输⼊来源可以是file、kafka、beats等】
2:filters 过滤
3:outputs 输出 【输出⽬标可以是Stdout(控制台)、File、ES等】
logstash可以从多个输⼊源获取内容通过type进⾏区分 并可根据type向多数据源输出
kibana介绍
Kibana是⼀个开源的分析与可视化平台。
⽤kibana搜索、查看存放在Elasticsearch中的数据。
Kibana与Elasticsearch的交互⽅式是各种不同的图表、表格、地图等,直观的展示数据,从⽽达到⾼级 的数据分析与可视化的⽬的。
部署
部署前先创建新的局域⽹,防⽌容器IP频繁改动后需要修改配置⽂件
docker network create --subnet=172.18.0.0/16 elk_net
或
docker network create elk_net
elasticsearch
拉取镜像:docker pull elasticsearch:7.17.9
修改配置⽂件:/usr/share/elasticsearch/config/elasticsearch.yml
# es集群名称
cluster.name: "elastic"
# 监听
network.host: 0.0.0.0
# 跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
# 开启密码校验
xpack.security.enabled: true
启动容器
docker run -it --privileged=true -d -p 39200:9200 -p 39300:9300 --name es \
--net elk_net --privileged=true \
-v /generalzy/elk/es/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /generalzy/elk/es/data:/usr/share/elasticsearch/data \
-v /generalzy/elk/es/logs:/usr/share/elasticsearch/logs \
-e ES_JAVA_OPTS="-Xms128m -Xmx128m" -e "discovery.type=single-node" elasticsearch:7.17.9
Xms Xmx为最⼩最⼤堆内存,将其改为我们主机的物理内存的⼀半(50%-70%)即可,要设置成相同的值,以防⽌在运⾏时调整堆的⼤⼩。
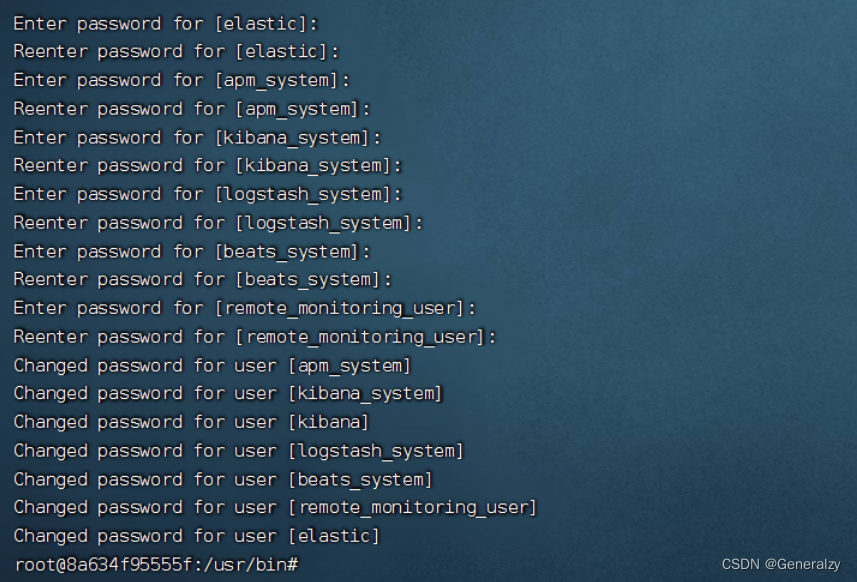
设置密码(123456)
进⼊elasticsearch容器中初始化各个组件的密码
./bin/elasticsearch-setup-passwords interactive
忘记密码重置密码
修改elasticsearch.yml配置⽂件注释使⽤xpack安全校验配置,取消使⽤密码校验

重启容器查看所有索引curl -XGET "127.0.0.1:9200/_cat/indices" -H 'Content-Type: application/json'
删除security-7索引:curl -XDELETE 127.0.0.1:9200/.security-7
修改配置⽂件开启密码配置 后 重启,重复添加密码操作。
logstash
拉取镜像:docker pull logstash:7.17.9
修改配置
logstash.yml:
# 节点名称
node.name: "logstash001"
http.host: "0.0.0.0"
# 设置禁⽤X-Pack监视功能
xpack.monitoring.enabled: false
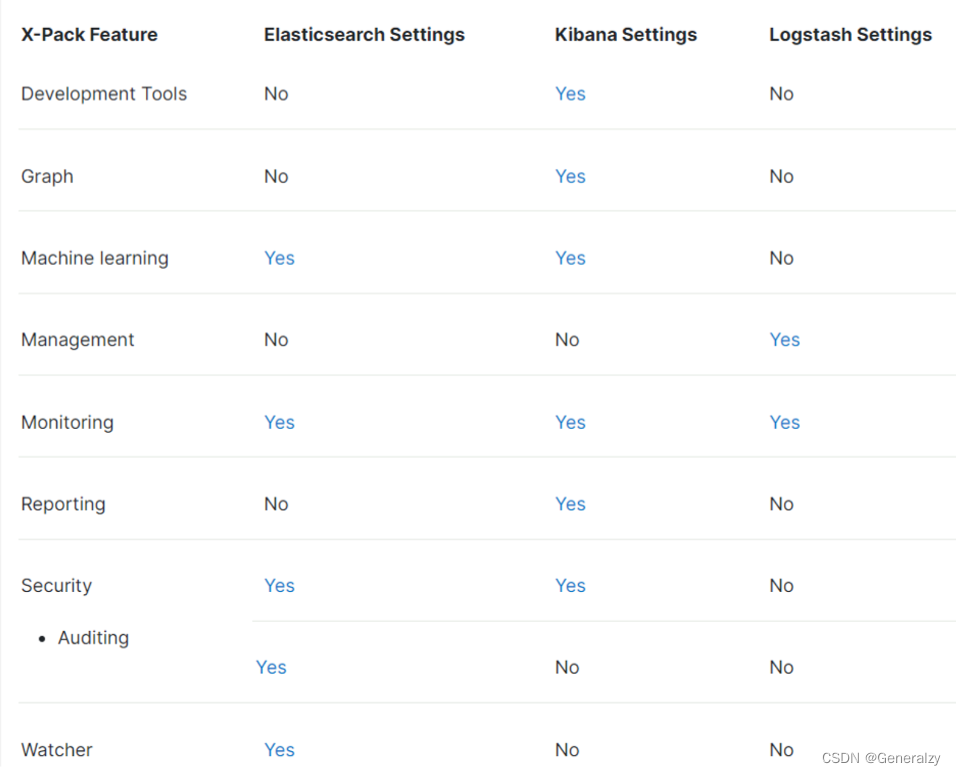
X-Pack是Elastic Stack的⼀个扩展插件,包含了安全控制、报警、监控、报表和画图功能。X- Pack能够⽅便地启⽤或禁⽤。
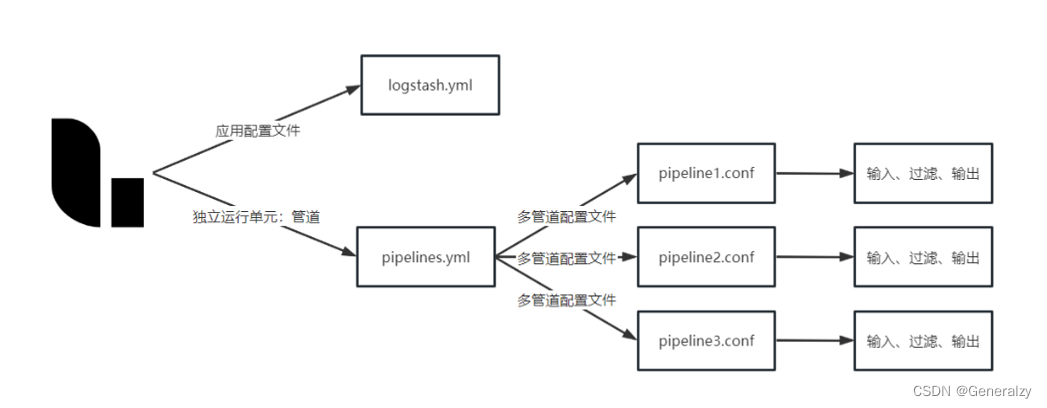
pipelines.yml:⽤于指定在⼀个logstash中运⾏多个管道的配置⽂件,在启动logstash时他会⾃动加载pipelines.yml中指定的path.config下的所有的管道配置⽂件conf合并成⼀个整体的配置⽂件。
将管道的具体的配置⽂件放置在config下,⽅便容器统⼀的挂载
# This file is where you define your pipelines. You can define multiple.
# For more information on multiple pipelines, see the documentation:
# https://www.elastic.co/guide/en/logstash/current/multiple-pipelines.html
# 可以在这个配置⽂件中定义多个管道,⽤于从多个数据源中获取信息
- pipeline.id: pipeline001 # 管道id
path.config: "/usr/share/logstash/config/*.conf"
pipeline管道配置: /usr/share/logstash/config/pipeline001.conf
#获取/usr/share/logs/*下的⽂件输出到es中
input {
file{
path => ['/usr/share/logs/*']
type => "nginx-log"
}
}
filter {
#json{
# 将message作为解析json的字段
#source => "message"
#}
}
output {
if[type] == "nginx-log"{
elasticsearch {
hosts => [ "es:9200" ]
index => "nginx-log-%{+YYYY-MM-dd}"
user => "elastic"
password => "123456"
}
}
}
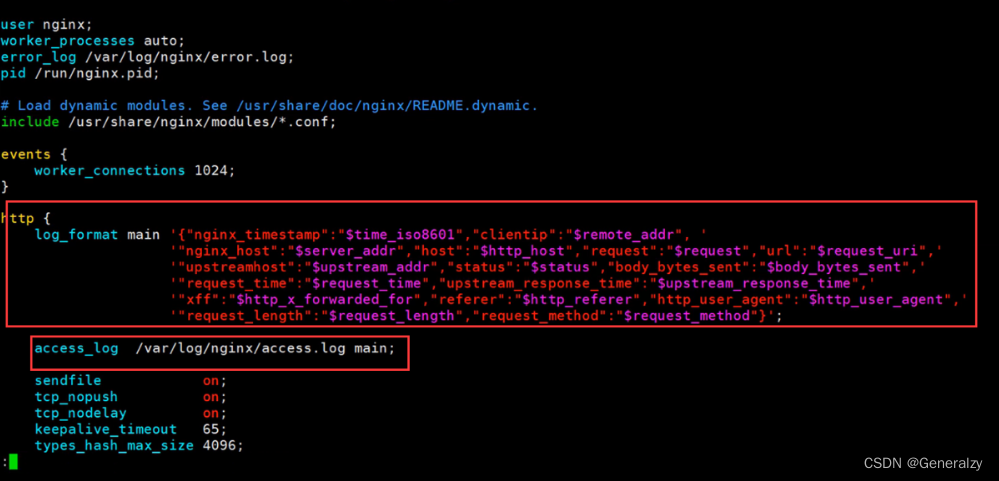
nginx不做格式化 在logstash中是⽆法格式化成功的。它可以把json字符串处理成json数据(别忘了结尾分号)
'{"nginx_timestamp":"$time_iso8601","clientip":"$remote_addr", '
' "nginx_host":"$server_addr","host":"$http_host","request":"$request","url":"$request_uri",'
' "upstreamhost":"$upstream_addr","status":"$status","body_bytes_sent":"$body_bytes_sent",'
' "upstream_response_time":"$upstream_response_time",'
' "xff":"$http_x_forwarded_for","referer":"$http_referer","http_user_agent":"$http_user_agent",'
' "request_length":"$request_length","request_method":"$request_method"}'
启动容器
docker run -d -it --privileged=true --name=lh --net elk_net \
-p 35047:5047 -p 39600:9600 \
-v /generalzy/elk/logstash:/usr/share/logstash/config \
# nginx日志
-v /generalzy/elk/logs/:/usr/share/logs/ \
logstash:7.17.9

kibana
拉取镜像
docker pull kibana:7.17.9
修改配置⽂件kibana.yml
server.name: kibana
server.host: "0.0.0.0"
xpack.monitoring.ui.container.elasticsearch.enabled: true
elasticsearch.hosts: [ "http://es:9200" ]
elasticsearch.username: "elastic"
elasticsearch.password: "123456"
elasticsearch.requestTimeout: 50000
i18n.locale: "zh-CN" #中⽂ui界⾯
server.publicBaseUrl: "http://0.0.0.0:5601"
启动容器
docker run -d --privileged=true --name kb \
-p 35601:5601 --net elk_net \
-v /generalzy/elk/kibana/kibana.yml:/usr/share/kibana/config/kibana.yml \
kibana:7.17.9
运行
打开界⾯后 先在索引管理中找到logstash输出到es中的数据产⽣的索引,随后去“索引模式”模块中去定义⼀个索引模式,kibana索引模式要与es中的索引相匹配才可以在kibana中实现可视化管理。
-
先根据索引写一个正则,由于收集的日志前缀都是nginx,可以定义
nginx索引模式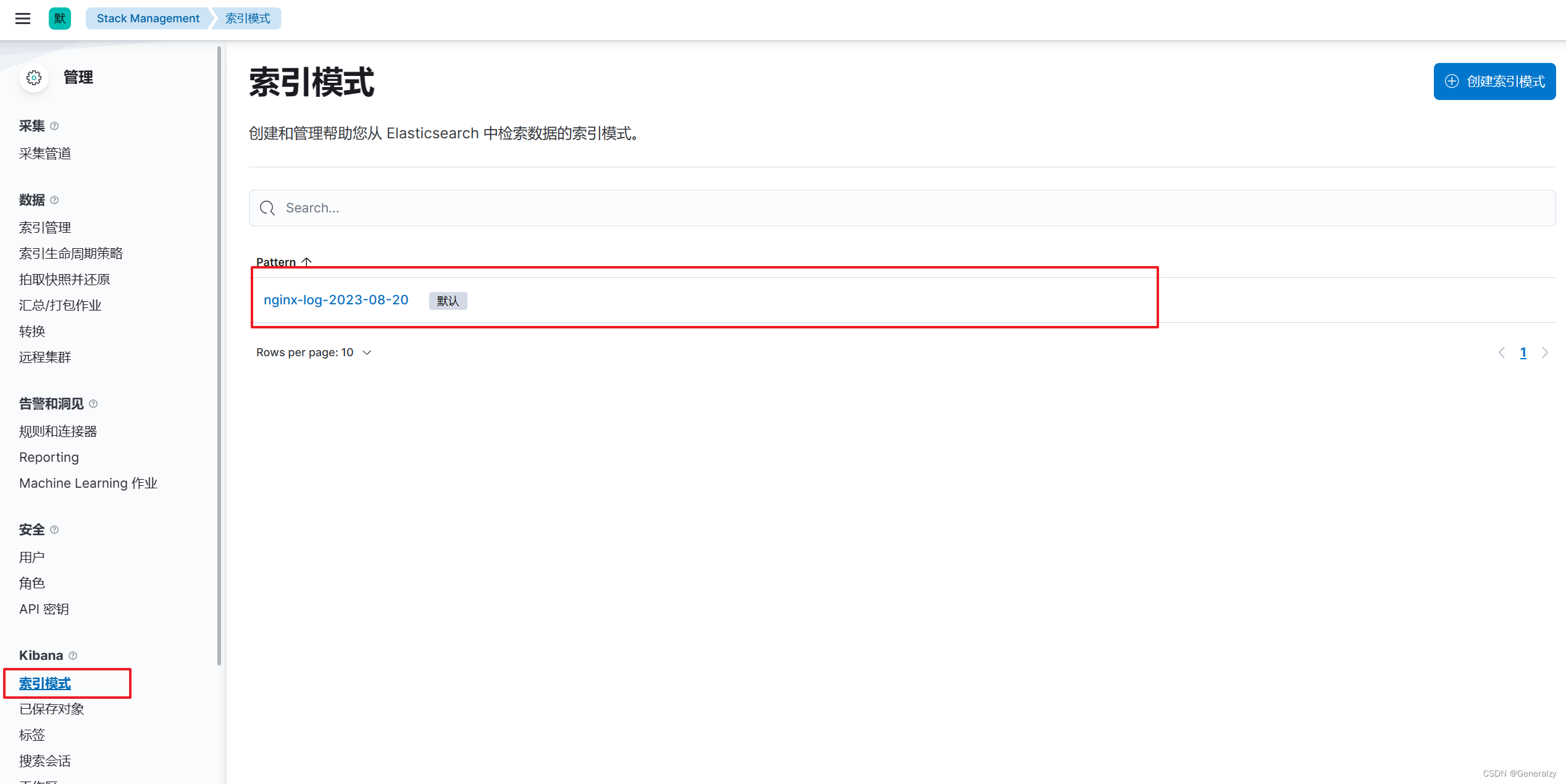
-
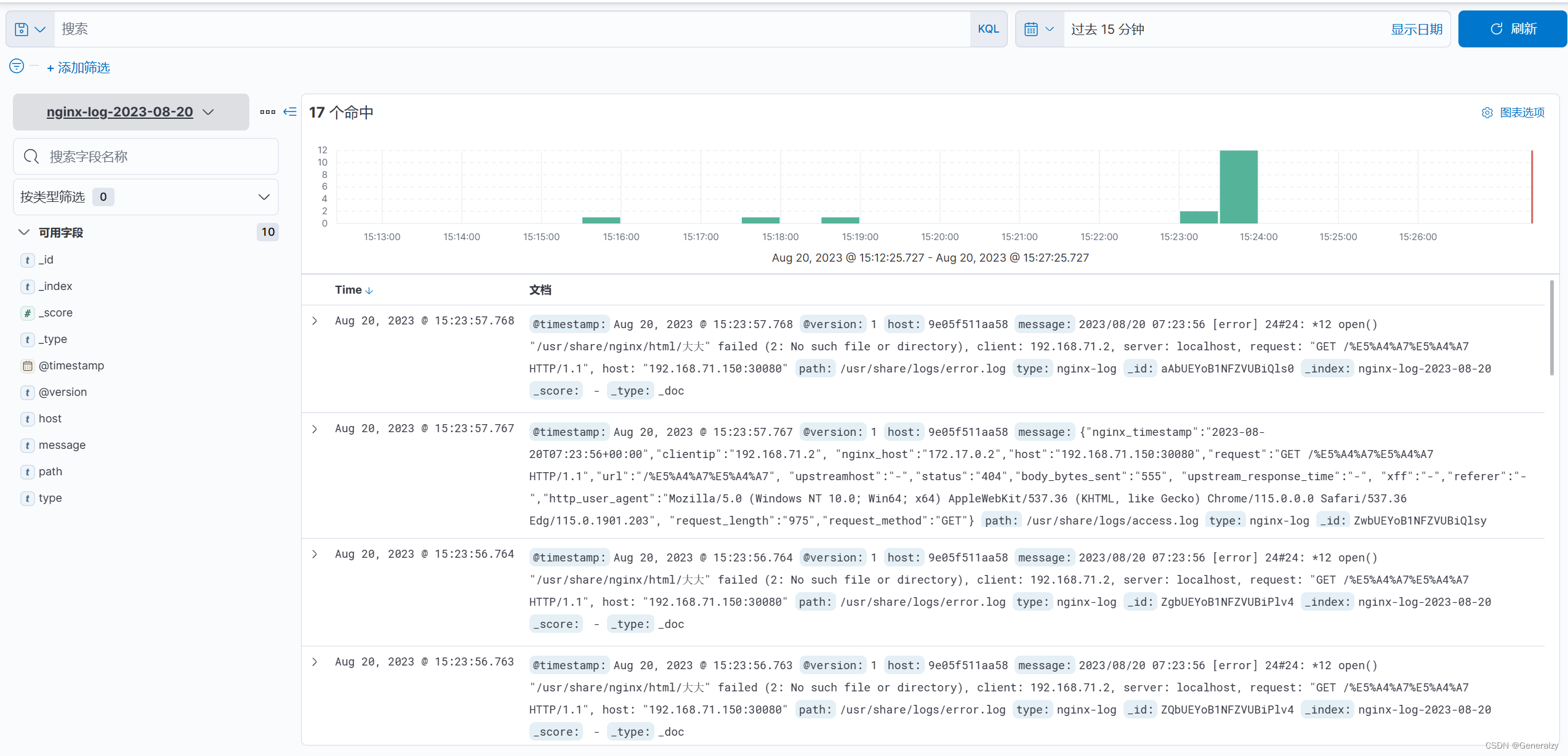
查看日志:
k8s搭建EFK和ELFK
elastic官方提供了官方的docker镜像和helm模板:
这里简单举例部署一个3节点的es集群,node角色为混合,并且配置CA证书校验,以及做kibana的可视化。
部署步骤
创建一个elastic名称空间

下载官方helm包:https://github.com/elastic/helm-charts
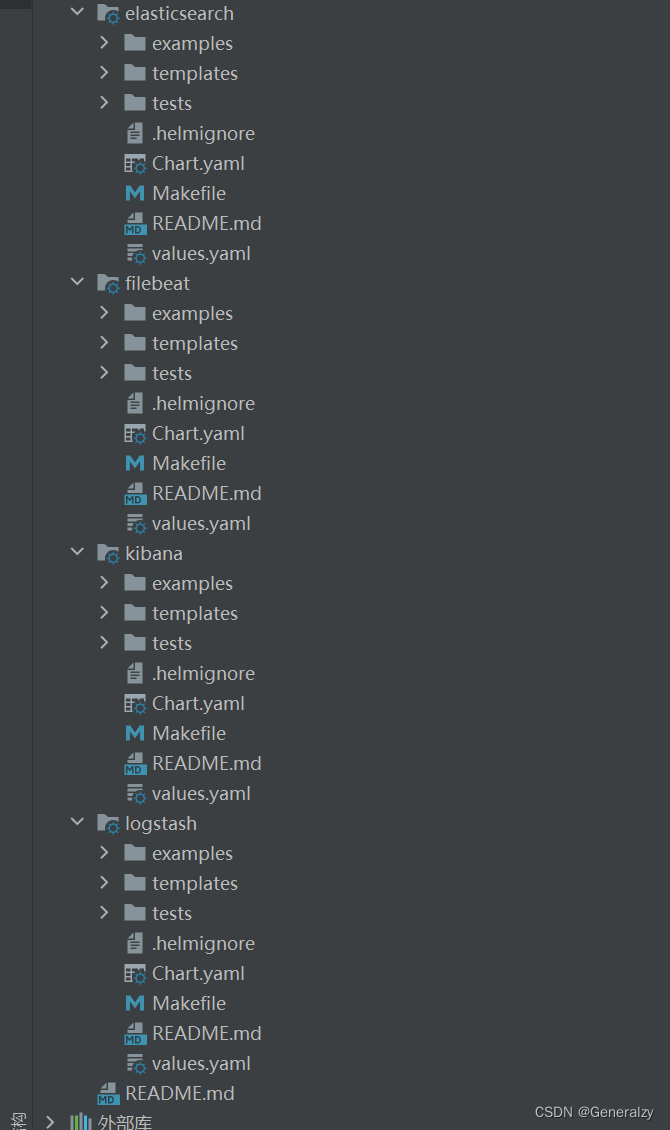
删掉没用的东西,就剩下:
阅读配置 Elastic Stack 的安全性:参考文档 选择合适的安全策略
官方原文:
Elastic Stack 由许多活动部件组成。集群由 Elasticsearch 节点、Logstash 实例、Kibana 实例、Beats 代理以及所有与集群通信的客户端组成。为了确保集群安全,请遵守Elasticsearch 安全原则。
实施安全性是配置 Elastic Stack 的关键步骤。默认情况下不启用安全性,因此为 Elastic Stack 配置安全性 以保护 Elasticsearch 集群以及与集群通信的任何客户端的安全非常重要。在不启用安全性的情况下显式运行 Elasticsearch 会使您的集群暴露给任何可以向 Elasticsearch 发送网络流量的人。
您可以使用密码保护对数据的访问,并通过配置传输层安全性 (TLS) 启用更高级的安全性。此附加层为您与 Elastic Stack 的通信提供机密性和完整性保护。您还可以实施其他安全措施,例如基于角色的访问控制、IP 过滤和审核。
启用安全性可通过以下方式保护 Elasticsearch 集群:
通过密码保护、基于角色的访问控制和 IP 过滤 来防止未经授权的访问。
通过 SSL/TLS 加密保护数据的完整性 。
维护审计跟踪, 以便您知道谁对您的集群及其存储的数据做了什么。

为 Elastic Stack 以及安全的 HTTPS 流量设置基本安全性
生成证书文件
# 运行容器生成证书
docker run --name elastic-charts-certs -i -w /app elasticsearch:7.17.3 /bin/sh -c \
"elasticsearch-certutil ca --out /app/elastic-stack-ca.p12 --pass '' && \
elasticsearch-certutil cert --name security-master --dns \
security-master --ca /app/elastic-stack-ca.p12 --pass '' --ca-pass '' --out /app/elastic-certificates.p12"
# 从容器中将生成的证书拷贝出来
docker cp elastic-charts-certs:/app/elastic-certificates.p12 ./
# 删除容器
docker rm -f elastic-charts-certs
# 将 pcks12 中的信息分离出来,写入文件
openssl pkcs12 -nodes -passin pass:'' -in elastic-certificates.p12 -out elastic-certificate.pem
添加secret备用:
# 添加证书
kubectl create secret generic elastic-certificates --from-file=elastic-certificates.p12 -n elastic
kubectl create secret generic elastic-certificate-pem --from-file=elastic-certificate.pem -n elastic
# 设置集群用户名密码,用户名不建议修改
kubectl create secret generic elastic-credentials \
--from-literal=username=elastic --from-literal=password=admin@123 -n elastic

配置证书并启动es
参考官方给的example配置:

由于是个人微机,我不区分角色,并且提前准备好pv做数据持久化

value.yaml:
---
clusterName: "elasticsearch"
nodeGroup: "master"
namespace: "elastic"
# The service that non master groups will try to connect to when joining the cluster
# This should be set to clusterName + "-" + nodeGroup for your master group
masterService: ""
# Elasticsearch roles that will be applied to this nodeGroup
# These will be set as environment variables. E.g. node.master=true
roles:
master: "true"
ingest: "true"
data: "true"
replicas: 3
minimumMasterNodes: 2
esMajorVersion: ""
clusterDeprecationIndexing: "false"
# Allows you to add any config files in /usr/share/elasticsearch/config/
# such as elasticsearch.yml and log4j2.properties
esConfig:
elasticsearch.yml: |
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
xpack.security.http.ssl.enabled: true
xpack.security.http.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
xpack.security.http.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
esJvmOptions: {}
# processors.options: |
# -XX:ActiveProcessorCount=3
extraEnvs:
- name: ELASTIC_USERNAME
valueFrom:
secretKeyRef:
name: elastic-credentials
key: username
- name: ELASTIC_PASSWORD
valueFrom:
secretKeyRef:
name: elastic-credentials
key: password
envFrom: []
secretMounts: []
hostAliases: []
image: "docker.elastic.co/elasticsearch/elasticsearch"
imageTag: "7.17.3"
imagePullPolicy: "IfNotPresent"
podAnnotations:
{}
# iam.amazonaws.com/role: es-cluster
# additionals labels
labels: {}
esJavaOpts: "-Xmx256m -Xms256m" # example: "-Xmx1g -Xms1g"
resources:
requests:
cpu: "256m"
memory: "256Mi"
limits:
cpu: "256m"
memory: "256Mi"
initResources:
{}
# limits:
# cpu: "25m"
# # memory: "128Mi"
# requests:
# cpu: "25m"
# memory: "128Mi"
networkHost: "0.0.0.0"
volumeClaimTemplate:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 4Gi
rbac:
create: false
serviceAccountAnnotations: {}
serviceAccountName: ""
automountToken: true
podSecurityPolicy:
create: false
name: ""
spec:
privileged: true
fsGroup:
rule: RunAsAny
runAsUser:
rule: RunAsAny
seLinux:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
volumes:
- secret
- configMap
- persistentVolumeClaim
- emptyDir
persistence:
enabled: true
labels:
# Add default labels for the volumeClaimTemplate of the StatefulSet
enabled: false
annotations: {}
extraVolumes:
[]
# - name: extras
# emptyDir: {}
extraVolumeMounts:
[]
# - name: extras
# mountPath: /usr/share/extras
# readOnly: true
extraContainers:
[]
# - name: do-something
# image: busybox
# command: ['do', 'something']
extraInitContainers:
[]
priorityClassName: ""
antiAffinityTopologyKey: "kubernetes.io/hostname"
# 节点如果少就置空,允许部署到同一个node
# 否则禁止es部署到同一个node
antiAffinity: "hard"
nodeAffinity: {}
podManagementPolicy: "Parallel"
enableServiceLinks: true
protocol: https
httpPort: 9200
transportPort: 9300
service:
enabled: true
labels: {}
labelsHeadless: {}
type: ClusterIP
# Consider that all endpoints are considered "ready" even if the Pods themselves are not
# https://kubernetes.io/docs/reference/kubernetes-api/service-resources/service-v1/#ServiceSpec
publishNotReadyAddresses: false
nodePort: ""
annotations: {}
httpPortName: http
transportPortName: transport
loadBalancerIP: ""
loadBalancerSourceRanges: []
externalTrafficPolicy: ""
updateStrategy: RollingUpdate
# This is the max unavailable setting for the pod disruption budget
# The default value of 1 will make sure that kubernetes won't allow more than 1
# of your pods to be unavailable during maintenance
maxUnavailable: 1
podSecurityContext:
fsGroup: 1000
runAsUser: 1000
securityContext:
capabilities:
drop:
- ALL
# readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
# How long to wait for elasticsearch to stop gracefully
terminationGracePeriod: 120
sysctlVmMaxMapCount: 262144
readinessProbe:
failureThreshold: 3
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 3
timeoutSeconds: 5
clusterHealthCheckParams: "wait_for_status=green&timeout=1s"
schedulerName: ""
imagePullSecrets: []
nodeSelector: {}
tolerations: []
ingress:
enabled: false
annotations: {}
className: "nginx"
pathtype: ImplementationSpecific
hosts:
- host: chart-example.local
paths:
- path: /
tls: []
nameOverride: ""
fullnameOverride: ""
healthNameOverride: ""
lifecycle:
{}
sysctlInitContainer:
enabled: true
keystore: []
networkPolicy:
http:
enabled: false
transport:
enabled: false
tests:
enabled: true
fsGroup: ""
helm部署集群:

启动kibana
获取集群svc:

kibana.values.yaml
---
# 填写集群名称
elasticsearchHosts: "http://elasticsearch-master:9200"
replicas: 1
# Extra environment variables to append to this nodeGroup
# This will be appended to the current 'env:' key. You can use any of the kubernetes env
# syntax here
extraEnvs:
- name: "NODE_OPTIONS"
value: "--max-old-space-size=1800"
- name: ELASTIC_USERNAME
valueFrom:
secretKeyRef:
name: elastic-credentials
key: username
- name: ELASTIC_PASSWORD
valueFrom:
secretKeyRef:
name: elastic-credentials
key: password
# Allows you to load environment variables from kubernetes secret or config map
envFrom: []
# - secretRef:
# name: env-secret
# - configMapRef:
# name: config-map
# A list of secrets and their paths to mount inside the pod
# This is useful for mounting certificates for security and for mounting
# the X-Pack license
secretMounts: []
# - name: kibana-keystore
# secretName: kibana-keystore
# path: /usr/share/kibana/data/kibana.keystore
# subPath: kibana.keystore # optional
hostAliases: []
#- ip: "127.0.0.1"
# hostnames:
# - "foo.local"
# - "bar.local"
image: "docker.elastic.co/kibana/kibana"
imageTag: "7.17.3"
imagePullPolicy: "IfNotPresent"
# additionals labels
labels: {}
annotations: {}
podAnnotations: {}
# iam.amazonaws.com/role: es-cluster
resources:
requests:
cpu: "100m"
memory: "256Mi"
limits:
cpu: "100m"
memory: "256Mi"
protocol: https
serverHost: "0.0.0.0"
healthCheckPath: "/app/kibana"
# Allows you to add any config files in /usr/share/kibana/config/
# such as kibana.yml
kibanaConfig:
kibana.yml: |
i18n.locale: "zh-CN"
# If Pod Security Policy in use it may be required to specify security context as well as service account
podSecurityContext:
fsGroup: 1000
securityContext:
capabilities:
drop:
- ALL
# readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
serviceAccount: ""
# Whether or not to automount the service account token in the pod. Normally, Kibana does not need this
automountToken: true
# This is the PriorityClass settings as defined in
# https://kubernetes.io/docs/concepts/configuration/pod-priority-preemption/#priorityclass
priorityClassName: ""
httpPort: 5601
extraVolumes:
[]
# - name: extras
# emptyDir: {}
extraVolumeMounts:
[]
# - name: extras
# mountPath: /usr/share/extras
# readOnly: true
#
extraContainers: []
# - name: dummy-init
# image: busybox
# command: ['echo', 'hey']
extraInitContainers: []
# - name: dummy-init
# image: busybox
# command: ['echo', 'hey']
updateStrategy:
type: "Recreate"
service:
type: nodePort
loadBalancerIP: ""
port: 5601
nodePort: "32121"
labels: {}
annotations:
{}
# cloud.google.com/load-balancer-type: "Internal"
# service.beta.kubernetes.io/aws-load-balancer-internal: 0.0.0.0/0
# service.beta.kubernetes.io/azure-load-balancer-internal: "true"
# service.beta.kubernetes.io/openstack-internal-load-balancer: "true"
# service.beta.kubernetes.io/cce-load-balancer-internal-vpc: "true"
loadBalancerSourceRanges:
[]
# 0.0.0.0/0
httpPortName: http
ingress:
enabled: false
className: "nginx"
pathtype: ImplementationSpecific
annotations: {}
# kubernetes.io/ingress.class: nginx
# kubernetes.io/tls-acme: "true"
hosts:
- host: kibana-example.local
paths:
- path: /
#tls: []
# - secretName: chart-example-tls
# hosts:
# - chart-example.local
readinessProbe:
failureThreshold: 3
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 3
timeoutSeconds: 5
imagePullSecrets: []
nodeSelector: {}
tolerations: []
affinity: {}
nameOverride: ""
fullnameOverride: ""
lifecycle:
{}
# preStop:
# exec:
# command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
# postStart:
# exec:
# command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
# Deprecated - use only with versions < 6.6
elasticsearchURL: "" # "http://elasticsearch-master:9200"
启动filebeat
filebeat支持ds和deploy部署,但基本values文件是一样的:
---
daemonset:
# Annotations to apply to the daemonset
annotations: {}
# additionals labels
labels: {}
affinity: {}
# Include the daemonset
enabled: true
# Extra environment variables for Filebeat container.
envFrom: []
# - configMapRef:
# name: config-secret
extraEnvs:
- name: ELASTIC_USERNAME
valueFrom:
secretKeyRef:
name: elastic-credentials
key: username
- name: ELASTIC_PASSWORD
valueFrom:
secretKeyRef:
name: elastic-credentials
key: password
extraVolumes:
[]
# - name: extras
# emptyDir: {}
extraVolumeMounts:
[]
# - name: extras
# mountPath: /usr/share/extras
# readOnly: true
hostNetworking: false
# Allows you to add any config files in /usr/share/filebeat
# such as filebeat.yml for daemonset
filebeatConfig:
filebeat.yml: |
filebeat.inputs:
- type: container
paths:
- /var/log/containers/*.log
processors:
- add_kubernetes_metadata:
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
output.elasticsearch:
username: '${ELASTICSEARCH_USERNAME}'
password: '${ELASTICSEARCH_PASSWORD}'
protocol: https
hosts: ["elastic-master:9200"]
ssl.certificate_authorities:
- /usr/share/filebeat/config/certs/elastic-certificate.pem
# Only used when updateStrategy is set to "RollingUpdate"
maxUnavailable: 1
nodeSelector: {}
# A list of secrets and their paths to mount inside the pod
# This is useful for mounting certificates for security other sensitive values
secretMounts: []
# - name: filebeat-certificates
# secretName: filebeat-certificates
# path: /usr/share/filebeat/certs
# Various pod security context settings. Bear in mind that many of these have an impact on Filebeat functioning properly.
#
# - User that the container will execute as. Typically necessary to run as root (0) in order to properly collect host container logs.
# - Whether to execute the Filebeat containers as privileged containers. Typically not necessarily unless running within environments such as OpenShift.
securityContext:
runAsUser: 0
privileged: false
resources:
requests:
cpu: "100m"
memory: "100Mi"
limits:
cpu: "1000m"
memory: "200Mi"
tolerations: []
关于filebeat的配置,可以参考官方文档,给的很清楚:https://www.elastic.co/guide/en/beats/filebeat/7.17/configuration-filebeat-options.html
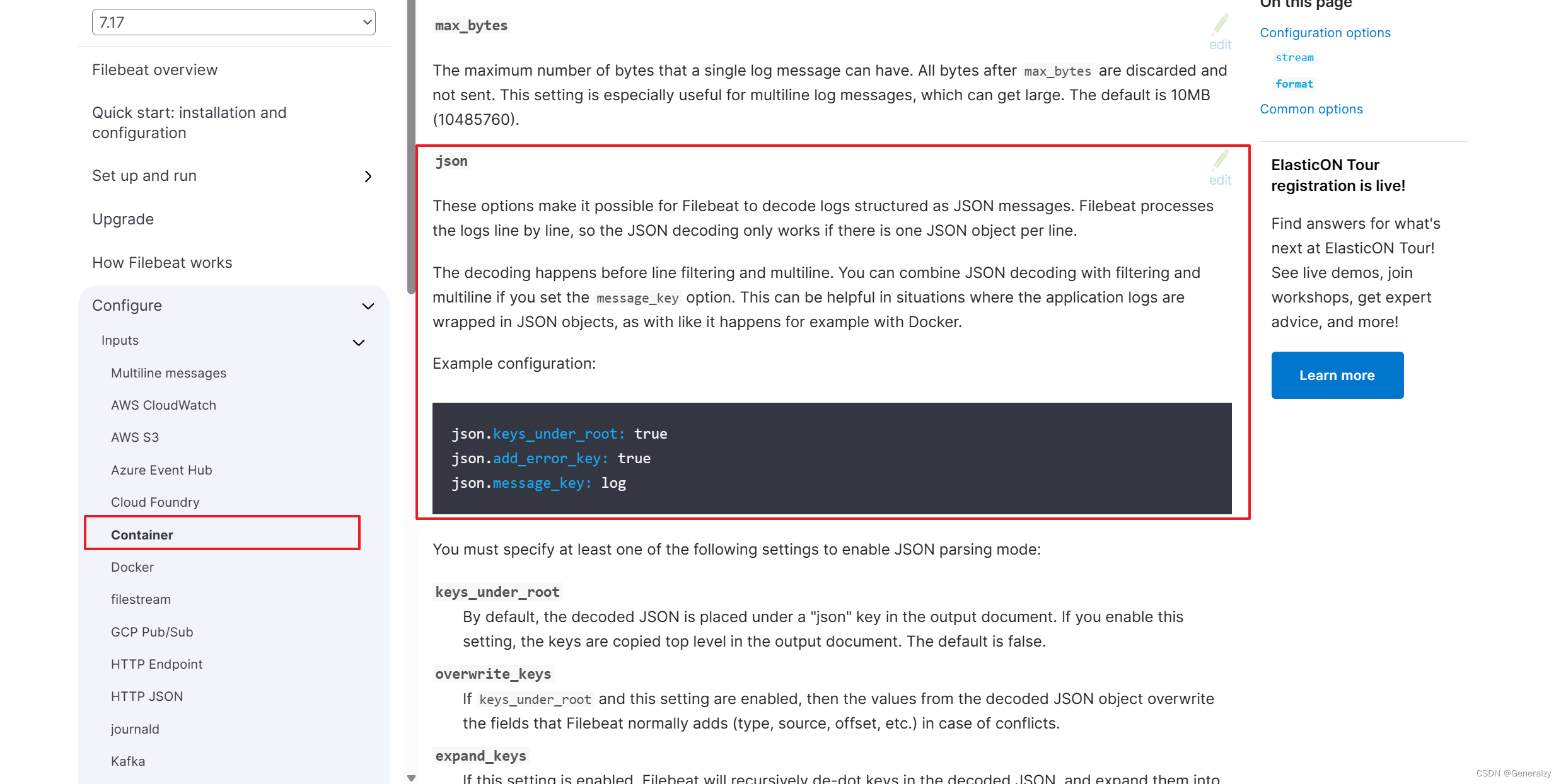
如果想要解析json格式的日志,还可以加上字段decode:
FAQ
yaml的"|+"…是什么意思
-
null 用~表示
parent: ~ -
类型转换,Yaml 允许使用两个感叹号,强制转换数据类型
e: !!str 123 f: !!str true -
如果字符串之中包含空格或特殊字符,需要放在引号中
str: '内容: 字符串' -
字符串可以写成多行,从第二行开始,必须有一个单空格缩进,换行符会被转为空格。
str: 我是一段 多行 字符串
-
多行字符串可以使用 | 保留换行符,也可以使用 > 折叠换行
this: | Foo Bar that: > Foo Bar
-
- 表示保留文字块末尾的换行,- 表示删除字符串末尾的换行
s1: | Foo s2: |+ Foo s3: |- Foo
-
& 锚点和 * 别名,可以用来引用:
defaults: &defaults adapter: postgres host: localhost development: database: myapp_development <<: *defaults test: database: myapp_test <<: *defaults等价于
defaults: adapter: postgres host: localhost development: database: myapp_development adapter: postgres host: localhost test: database: myapp_test adapter: postgres host: localhost
es-cluster和master-client-data模式的区别
- 默认情况下,ES集群节点都是混合节点,即在elasticsearch.yml中默认node.master: true和node.data: true。
- 当ES集群规模达到一定程度以后,就需要注意对集群节点进行角色划分。
- ES集群节点可以划分为三种:主节点、数据节点和客户端节点。
三类节点说明
master - 主节点:elasticsearch.yml:node.master: true node.data: false- 主要功能:维护元数据,管理集群节点状态;不负责数据写入和查询。
- 配置要点:内存可以相对小一些,但是机器一定要稳定,最好是独占的机器。
data - 数据节点:elasticsearch.yml:node.master:false node.data: true- 主要功能:负责数据的写入与查询,压力大。
- 配置要点:大内存,最好是独占的机器。
client - 客户端节点:elasticsearch.yml:node.master: false node.data: false- 主要功能:负责任务分发和结果汇聚,分担数据节点压力。
- 配置要点:大内存,最好是独占的机器
mixed- 混合节点(不建议):elasticsearch.yml:node.master: true node.data: true- 主要功能:综合上述三个节点的功能。
- 配置要点:大内存,最好是独占的机器。
特别说明:不建议这种配置,节点容易挂掉。
假定共计20台机器,则可以按照如下配置:

其他集群节点参考:官方文档
查看pod某个容器的日志
kubectl logs -p es-cluster-0 -c fix-permissions 是一个用于检索 Kubernetes Pod 中容器日志的命令。让我解释这个命令的各个部分:
kubectl: Kubernetes 命令行工具,用于与 Kubernetes 集群交互。logs: 用于检索 Pod 中容器的日志信息。-p es-cluster-0: 使用-p选项指定要查看的 Pod 的名称,es-cluster-0是 Pod 的名称。-c fix-permissions: 使用-c选项指定要查看的容器的名称,fix-permissions是初始化容器的名称。
综合起来,这个命令的目的是查看名为 fix-permissions 的初始化容器在 Pod es-cluster-0 中的日志信息。这样可以诊断初始化容器在启动时是否遇到了问题,以及问题的具体原因。
使用 -p 选项是为了查看 Pod 中先前版本的容器日志,因为 -p 表示 “previous”,即查看先前版本的日志。如果 Pod 正在运行,也可以使用 kubectl logs -f es-cluster-0 -c fix-permissions 命令实时跟踪正在运行的容器日志。
查看pod container的name
kubectl get pods <pod-name> -o jsonpath='{.spec.containers[*].name}'
es集群安全性

参考官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.17/configuring-tls.html#tls-transport
busyBox测试集群连通性
busybox是一个包含了nslookup,ping,wget等网络处理命令的Pod容器(不含curl命令),它的体积非常小,适合做一些容器内的网络调试。
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: default
spec:
containers:
- name: busybox
image: busybox:1.32
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
restartPolicy: Always


















 3957
3957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











