




目录
LangChain 曾是最佳选择
或许从诞生那天起,LangChain 就注定是一个口碑两极分化的产品。
看好 LangChain 的人欣赏它丰富的工具和组建和易于集成等特点,不看好 LangChain 的人,认为它注定失败 —— 在这个技术变化如此之快的年代,用 LangChain 来构建一切根本行不通。
最近,一篇 LangChain 吐槽文再次成为热议焦点,作者 Fabian Both 是 AI 测试工具 Octomind 的深度学习工程师。Octomind 团队会使用具有多个 LLM 的 AI Agent 来自动创建和修复 Playwright 中的端到端测试。
这是一个持续一年多的故事,从选择 LangChain 开始,随后进入到了与 LangChain 顽强斗争的阶段。在 2024 年,他们终于决定告别 LangChain。
在 2023 年,LangChain 似乎是我们的最佳选择。它拥有一系列令人印象深刻的组件和工具,而且人气飙升。LangChain
承诺「让开发人员一个下午就能从一个想法变成可运行的代码」,但随着我们的需求变得越来越复杂,问题也开始浮出水面。
随着 LangChain 的不灵活性开始显现,我们开始深入研究 LangChain 的内部结构,以改进系统的底层行为。但是,由于
LangChain 故意将许多细节做得很抽象,我们无法轻松编写所需的底层代码。
起初,当我们的简单需求与 LangChain 的使用假设相吻合时,LangChain还能帮上忙。但它的高级抽象很快就让我们的代码变得更加难以理解,维护过程也令人沮丧。当团队用在理解和调试 LangChain的时间和用在构建功能上的时间一样时,这可不是一个好兆头。
LangChain 为什么如此抽象?
LangChain 的抽象方法所存在的问题,可以通过「将一个英语单词翻译成意大利语」这一微不足道的示例来说明。
下面是一个仅使用 OpenAI 软件包的 Python 示例:

这是一段简单易懂的代码,只包含一个类和一个函数调用。其余部分都是标准的 Python 代码。
将其与 LangChain 的版本进行对比:
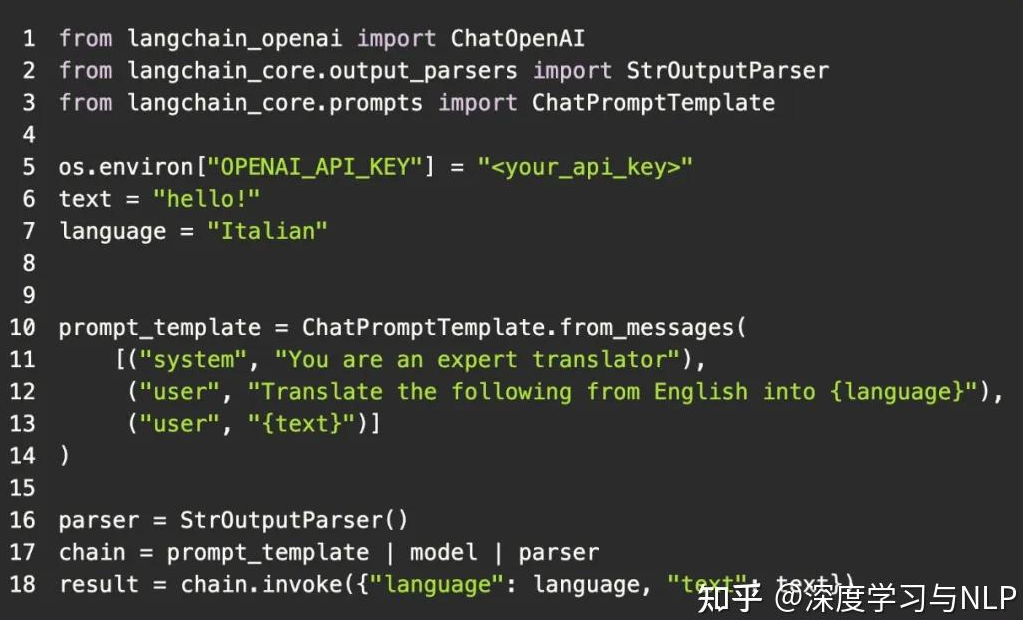
代码大致相同,但相似之处仅此而已。
我们现在有三个类和四个函数调用。但令人担忧的是,LangChain 引入了三个新的抽象概念:
- Prompt 模板: 为 LLM 提供 Prompt;
- 输出解析器: 处理来自 LLM 的输出;
- 链:LangChain 的「LCEL 语法」覆盖 Python 的 | 操作符。
LangChain 所做的只是增加了代码的复杂性,却没有带来任何明显的好处。
这种代码对于早期原型来说可能没什么问题。但对于生产使用,每个组件都必须得到合理的理解,这样在实际使用条件下才不至于意外崩溃。你必须遵守给定的数据结构,并围绕这些抽象设计应用程序。
让我们看看 Python 中的另一个抽象比较,这次是从 API 中获取 JSON。
使用内置的 http 包:

使用 requests 包:

高下显而易见。这就是好的抽象的感觉。
当然,这些都是微不足道的例子。但我想说的是,好的抽象可以简化代码,减少理解代码所需的认知负荷。
LangChain 试图通过隐藏细节,用更少的代码完成更多的工作,让你的生活变得更轻松。但是,如果这是以牺牲简单性和灵活性为代价的,那么抽象就失去了价值。
LangChain 还习惯于在其他抽象之上使用抽象,因此你往往不得不从嵌套抽象的角度来思考如何正确使用 API。这不可避免地会导致理解庞大的堆栈跟踪和调试你没有编写的内部框架代码,而不是实现新功能。
langChain+langGraph v1.0发布
正当人们以为 LangChain 的故事会随着开发者的离开而告一段落时,剧情却出现了反转。2025 年,LangChain 团队带着全新的姿态重新登场,正式发布了 v1.0。这一次,它不再试图成为“万物之链”的超级框架,而是回归初心——一个帮助开发者快速构建智能体(Agent)与 LLM 应用的轻量级工具集。
如今在官网上,LangChain 的口号也彻底变了:
“LangChain is the easiest way to start building agents and applications powered by LLMs.”
新的 LangChain 重点在于“易用”和“上手快”,同时将复杂的底层控制逻辑下放给 LangGraph——一个专为高定制、低延迟、可控工作流设计的底层编排框架。LangChain 负责加速原型和应用开发,LangGraph 则成为高级用户的“发动机房”。
换句话说,LangChain 终于不再试图包办一切,而是学会了“放手”。
官网原文说道:
LangChain 的智能体是基于 LangGraph构建的,以提供可持续执行、流式处理、人类参与(human-in-the-loop)、持久化等能力。
对于一般的 LangChain 智能体开发,你无需了解 LangGraph 的底层细节。
这里可以看的出来v1.0中,langChain和langGraph合并了,而官网也作出了对应变动:
LangChain v1 是一个更聚焦、面向生产环境的智能体构建基础框架。这一版本围绕三个核心改进进行了精简与重构:
-
create_agent
LangChain 构建智能体的新标准接口,用于取代旧版的langgraph.prebuilt.create_react_agent。 -
标准化内容块(Standard content blocks)
新增content_blocks属性,提供了跨不同模型提供商的统一接口,以便使用现代 LLM 的各类功能。 -
精简命名空间(Simplified namespace)
langchain命名空间现已聚焦于智能体的核心构建模块;旧版本中的功能被迁移至langchain-classic。
无论使用pip还是uv,你仅需要一行命令即可安装langChain:
uv add langchain
或
pip install -U langchain
然后我们就可以看到,旧的一切都被卸载掉了:
接下来,我们创建一个带有工具的chat agent:
# pip install -qU "langchain[anthropic]" to call the model
from langchain.agents import create_agent
def get_weather(city: str) -> str:
"""Get weather for a given city."""
return f"It's always sunny in {city}!"
agent = create_agent(
model="anthropic:claude-sonnet-4-5",
tools=[get_weather],
system_prompt="You are a helpful assistant",
)
# Run the agent
agent.invoke(
{"messages": [{"role": "user", "content": "what is the weather in sf"}]}
)
相比v0是不是简单了很多?进入create_agent的函数签名,我们可以看到v1的确更新了很多新特性,尤其是中间件。
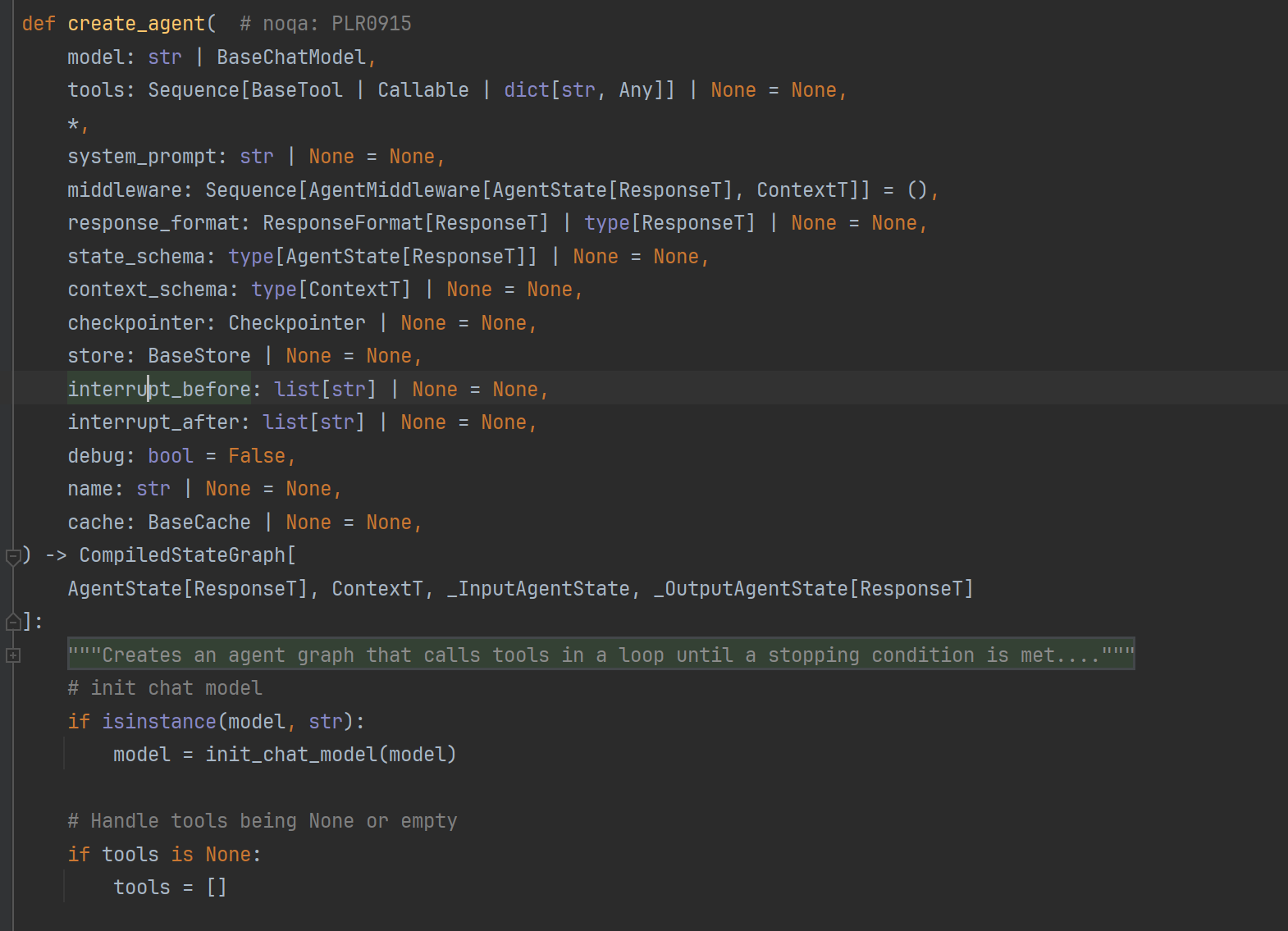
langchain v1.0新特征概览
create_agent
在 LangChain 1.0 中,create_agent 是构建智能体的标准方式。相比旧版的 langgraph.prebuilt.create_react_agent,它提供了更简洁的接口,并通过 middleware(中间件)机制 实现了更强的可定制能力。
from langchain.agents import create_agent
agent = create_agent(
model="anthropic:claude-sonnet-4-5",
tools=[search_web, analyze_data, send_email],
system_prompt="You are a helpful research assistant."
)
result = agent.invoke({
"messages": [
{"role": "user", "content": "Research AI safety trends"}
]
})
在底层实现中,create_agent 构建于核心智能体循环(core agent loop)之上——
即依次执行以下步骤:
- 调用模型;
- 让模型选择需要执行的工具;
- 当模型不再调用工具时结束循环。
Middleware
中间件 是 create_agent 的核心特性。
它为智能体提供了一个高度可定制的扩展入口,极大地提升了开发者可实现功能的上限。
优秀的智能体往往依赖于上下文工程(context engineering)——即在合适的时间,将恰当的信息传递给模型。
中间件通过一种可组合(composable)的抽象方式,帮助你控制以下关键行为:
- 动态 Prompt 构建
- 对话摘要(conversation summarization)
- 选择性工具访问(selective tool access)
- 状态管理(state management)
- 安全防护与限制(guardrails)
Prebuilt middleware
LangChain 提供了若干常用的预构建中间件,包括:
PIIMiddleware:在向模型发送数据前,自动屏蔽敏感信息;SummarizationMiddleware:当对话历史过长时进行摘要;HumanInTheLoopMiddleware:在执行敏感操作前要求人工审批。
示例代码:
from langchain.agents import create_agent
from langchain.agents.middleware import (
PIIMiddleware,
SummarizationMiddleware,
HumanInTheLoopMiddleware
)
agent = create_agent(
model="anthropic:claude-sonnet-4-5",
tools=[read_email, send_email],
middleware=[
PIIMiddleware(patterns=["email", "phone", "ssn"]),
SummarizationMiddleware(
model="anthropic:claude-sonnet-4-5",
max_tokens_before_summary=500
),
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"]
}
}
),
]
)
Custom Middleware
你也可以根据自己的需求构建自定义中间件。
中间件在智能体执行的各个阶段都提供了可扩展的 hook(钩子),允许你在不同步骤中插入自定义逻辑。
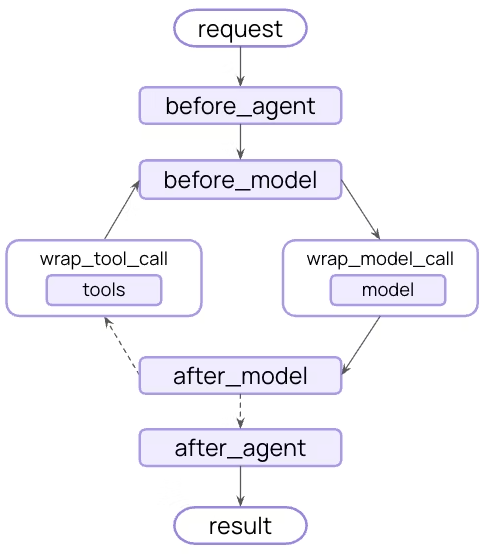
要创建自定义中间件,只需继承 AgentMiddleware 类,并实现以下任意钩子函数:
| Hook | 触发时机 | 常见用途 |
|---|---|---|
| before_agent | 调用智能体前 | 加载记忆、验证输入 |
| before_model | 每次调用 LLM 前 | 更新 prompt、裁剪消息 |
| wrap_model_call | LLM 调用过程(可包裹前后逻辑) | 拦截并修改请求或响应 |
| wrap_tool_call | 工具调用过程 | 拦截并修改工具执行逻辑 |
| after_model | 每次 LLM 响应后 | 校验输出、应用安全限制(guardrails) |
| after_agent | 智能体执行完成后 | 保存结果、清理资源 |
示例:根据用户的专业水平动态选择不同的模型与工具。
from dataclasses import dataclass
from langchain.agents.middleware import (
AgentMiddleware,
ModelRequest,
ModelRequestHandler
)
from langchain.messages import AIMessage
@dataclass
class Context:
user_expertise: str = "beginner"
class ExpertiseBasedToolMiddleware(AgentMiddleware):
def wrap_model_call(
self,
request: ModelRequest,
handler: ModelRequestHandler
) -> AIMessage:
user_level = request.runtime.context.user_expertise
if user_level == "expert":
# 专业用户使用更强大的模型和工具
model = "openai:gpt-5"
tools = [advanced_search, data_analysis]
else:
# 初学者使用更简单的模型和工具
model = "openai:gpt-5-nano"
tools = [simple_search, basic_calculator]
return handler(
request.replace(model=model, tools=tools)
)
agent = create_agent(
model="anthropic:claude-sonnet-4-5",
tools=[
simple_search,
advanced_search,
basic_calculator,
data_analysis
],
middleware=[ExpertiseBasedToolMiddleware()],
context_schema=Context
)
基于 LangGraph 构建
由于 create_agent 构建于 LangGraph 之上,因此你可以自动获得对长时间运行与高可靠性智能体的原生支持,包括以下功能:
-
持久化(Persistence)
对话会自动在会话之间持久保存,并具备内置的检查点(checkpointing)机制。 -
流式传输(Streaming)
实时流式输出生成的 token、工具调用及推理轨迹(reasoning traces)。 -
人类参与(Human-in-the-loop)
在执行敏感操作前,可暂停智能体流程,等待人工审批。 -
时间回溯(Time travel)
支持将对话“回滚”至任意时间点,从而探索不同的推理路径与提示方案。
你无需学习 LangGraph 的细节即可使用这些特性——它们开箱即用。
结构化输出(Structured Output)
create_agent 对结构化输出的生成进行了全面改进:
-
主循环集成(Main loop integration)
结构化输出现在直接在智能体主循环中生成,无需额外的 LLM 调用。 -
结构化输出策略(Structured output strategy)
模型可以在调用工具或使用模型提供商侧的结构化输出机制之间进行选择。 -
成本降低(Cost reduction)
由于去除了额外的 LLM 调用,显著减少了推理成本。
示例代码:
from langchain.agents import create_agent
from langchain.agents.structured_output import ToolStrategy
from pydantic import BaseModel
class Weather(BaseModel):
temperature: float
condition: str
def weather_tool(city: str) -> str:
"""获取指定城市的天气信息"""
return f"it's sunny and 70 degrees in {city}"
agent = create_agent(
"openai:gpt-4o-mini",
tools=[weather_tool],
response_format=ToolStrategy(Weather)
)
result = agent.invoke({
"messages": [{"role": "user", "content": "What's the weather in SF?"}]
})
print(repr(result["structured_response"]))
# 输出:Weather(temperature=70.0, condition='sunny')
错误处理(Error handling) 可以通过 ToolStrategy 的 handle_errors 参数控制结构化输出的错误处理逻辑,包括:
- 解析错误(Parsing errors):模型生成的数据与期望的结构不匹配;
- 多次工具调用(Multiple tool calls):模型为同一个结构化输出模式生成了两个或以上的工具调用。
标准化内容块(Standard Content Blocks)
目前,内容块(content block) 功能仅支持以下集成:
langchain-anthropiclangchain-awslangchain-openailangchain-google-genailangchain-ollama
未来将逐步扩展对更多模型提供商的支持。
新的 content_blocks 属性引入了一种跨模型提供商通用的消息内容标准表示形式。
示例代码:
from langchain_anthropic import ChatAnthropic
model = ChatAnthropic(model="claude-sonnet-4-5")
response = model.invoke("What's the capital of France?")
# 统一访问内容块
for block in response.content_blocks:
if block["type"] == "reasoning":
print(f"Model reasoning: {block['reasoning']}")
elif block["type"] == "text":
print(f"Response: {block['text']}")
elif block["type"] == "tool_call":
print(f"Tool call: {block['name']}({block['args']})")
-
提供商无关(Provider agnostic)
无论使用哪种模型提供商,都可通过统一的 API 访问推理轨迹(reasoning traces)、引用信息(citations)、内置工具(如网页搜索、代码解释器等)及其他功能。 -
类型安全(Type safe)
为所有内容块类型提供完整的类型提示。 -
向后兼容(Backward compatible)
标准化内容可按需惰性加载(lazy loading),不会引入破坏性变更。
精简的包结构(Simplified Package)
在 LangChain v1 中,langchain 包的命名空间经过了全面精简,重点聚焦于构建智能体(Agent)所需的核心模块。
这一改进后的命名空间仅暴露最常用、最相关的功能,使 API 更加清晰、专注:
| 命名空间(Namespace / Module) | 提供内容(What’s available) | 说明(Notes) |
|---|---|---|
langchain.agents | create_agent, AgentState | 核心智能体创建功能 |
langchain.messages | 消息类型、内容块、trim_messages | 从 @langchain-core 重新导出 |
langchain.tools | @tool, BaseTool, 注入辅助函数(injection helpers) | 从 @langchain-core 重新导出 |
langchain.chat_models | init_chat_model, BaseChatModel | 统一的聊天模型初始化接口 |
langchain.embeddings | Embeddings, init_embeddings | 向量嵌入模型接口 |
其中大多数模块为了方便开发,都从 langchain-core 重新导出,为构建智能体提供了一个更精炼、更直观的 API 接口层。 (终于不用一会儿from langchain-core,一会儿from langchain了)
示例代码:
# 构建智能体
from langchain.agents import create_agent
# 消息与内容
from langchain.messages import AIMessage, HumanMessage
# 工具
from langchain.tools import tool
# 模型初始化
from langchain.chat_models import init_chat_model
from langchain.embeddings import init_embeddings
为了保持核心包的精简与专注,旧版功能已迁移至 langchain-classic。
langchain-classic 中包含的内容:
- 旧版链(legacy chains)及链实现
- 索引 API(indexing API)
langchain-community导出内容- 其他已弃用的功能
如果你需要使用这些功能,可以通过以下命令安装:
pip install langchain-classic
然后更新你的导入语句:
from langchain import ...
from langchain_classic import ...
from langchain.chains import ...
from langchain_classic.chains import ...
快速开始
上面介绍了如何使用langchain构建一个简单的智能体,接下来,我们将构建一个实用的天气预报智能体,演示关键的生产环境概念:
- 详细的系统提示(Detailed system prompts):提升智能体行为的准确性与稳定性
- 工具集成(Create tools):与外部数据源对接
- 模型配置(Model configuration):确保响应的一致性
- 结构化输出(Structured output):生成可预测的结果
- 对话记忆(Conversational memory):实现类似聊天的交互体验
创建并运行智能体,即可得到一个功能完整的智能体。
1. 定义系统提示(Define the System Prompt)
系统提示定义了智能体的角色和行为,应保持具体且可执行:
system_prompt = """You are an expert weather forecaster, who speaks in puns.
You have access to two tools:
- get_weather_for_location: use this to get the weather for a specific location
- get_user_location: use this to get the user's location
If a user asks you for the weather, make sure you know the location. If you can tell from the question that they mean wherever they are, use the get_user_location tool to find their location."""
2. 创建工具(Create Tools)
工具允许模型通过你定义的函数与外部系统交互。
工具可以依赖运行时上下文(runtime context),也可以与智能体记忆交互。
下面示例中,get_user_location 工具使用了运行时上下文:
from dataclasses import dataclass
from langchain.tools import tool, ToolRuntime
@tool
def get_weather_for_location(city: str) -> str:
"""获取指定城市的天气"""
return f"It's always sunny in {city}!"
@dataclass
class Context:
"""自定义运行时上下文模式"""
user_id: str
@tool
def get_user_location(runtime: ToolRuntime[Context]) -> str:
"""根据用户 ID 获取用户位置信息"""
user_id = runtime.context.user_id
return "Florida" if user_id == "1" else "SF"
注意事项:
- 工具应有完整文档:名称、描述、参数名都会成为模型 Prompt 的一部分。
- LangChain 的
@tool装饰器可添加元数据,并通过ToolRuntime参数支持运行时注入。
3. 配置模型(Configure Your Model)
为你的用例设置合适的语言模型参数:
from langchain.chat_models import init_chat_model
model = init_chat_model(
"anthropic:claude-sonnet-4-5",
temperature=0.5,
timeout=10,
max_tokens=1000
)
4. 定义响应格式(Define Response Format)
如果希望智能体的响应符合特定结构,可以定义结构化响应格式:
from dataclasses import dataclass
# 这里使用 dataclass,也支持 Pydantic 模型
@dataclass
class ResponseFormat:
"""智能体响应的结构化模式"""
# 风趣的回答(必填)
punny_response: str
# 若有,可提供天气的相关信息
weather_conditions: str | None = None
5. 添加记忆(Add Memory)
为智能体添加记忆,以便在多轮交互中保持状态,允许智能体记住之前的对话和上下文信息:
from langgraph.checkpoint.memory import InMemorySaver
checkpointer = InMemorySaver()
在生产环境中,应使用持久化的 checkpointer,将数据保存到数据库中。
6. 创建并运行智能体(Create and Run the Agent)
现在,将之前准备的所有组件组装起来,并运行智能体:
agent = create_agent(
model=model,
system_prompt=system_prompt,
tools=[get_user_location, get_weather_for_location],
context_schema=Context,
response_format=ResponseFormat,
checkpointer=checkpointer
)
# `thread_id` 是每个对话的唯一标识符
config = {"configurable": {"thread_id": "1"}}
# 第一次对话示例
response = agent.invoke(
{"messages": [{"role": "user", "content": "what is the weather outside?"}]},
config=config,
context=Context(user_id="1")
)
print(response['structured_response'])
# 输出示例:
# ResponseFormat(
# punny_response="Florida is still having a 'sun-derful' day! The sunshine is playing 'ray-dio' hits all day long! I'd say it's the perfect weather for some 'solar-bration'! If you were hoping for rain, I'm afraid that idea is all 'washed up' - the forecast remains 'clear-ly' brilliant!",
# weather_conditions="It's always sunny in Florida!"
# )
# 使用相同的 `thread_id` 继续对话
response = agent.invoke(
{"messages": [{"role": "user", "content": "thank you!"}]},
config=config,
context=Context(user_id="1")
)
print(response['structured_response'])
# 输出示例:
# ResponseFormat(
# punny_response="You're 'thund-erfully' welcome! It's always a 'breeze' to help you stay 'current' with the weather. I'm just 'cloud'-ing around waiting to 'shower' you with more forecasts whenever you need them. Have a 'sun-sational' day in the Florida sunshine!",
# weather_conditions=None
# )
注意:使用相同的
thread_id可以让智能体记住之前的对话上下文,实现连续交互。
完整代码:
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
from langchain.tools import tool, ToolRuntime
from langgraph.checkpoint.memory import InMemorySaver
# Define system prompt
system_prompt = """You are an expert weather forecaster, who speaks in puns.
You have access to two tools:
- get_weather_for_location: use this to get the weather for a specific location
- get_user_location: use this to get the user's location
If a user asks you for the weather, make sure you know the location. If you can tell from the question that they mean wherever they are, use the get_user_location tool to find their location."""
# Define context schema
@dataclass
class Context:
"""Custom runtime context schema."""
user_id: str
# Define tools
@tool
def get_weather_for_location(city: str) -> str:
"""Get weather for a given city."""
return f"It's always sunny in {city}!"
@tool
def get_user_location(runtime: ToolRuntime[Context]) -> str:
"""Retrieve user information based on user ID."""
user_id = runtime.context.user_id
return "Florida" if user_id == "1" else "SF"
# Configure model
model = init_chat_model(
"anthropic:claude-sonnet-4-5",
temperature=0
)
# Define response format
@dataclass
class ResponseFormat:
"""Response schema for the agent."""
# A punny response (always required)
punny_response: str
# Any interesting information about the weather if available
weather_conditions: str | None = None
# Set up memory
checkpointer = InMemorySaver()
# Create agent
agent = create_agent(
model=model,
system_prompt=system_prompt,
tools=[get_user_location, get_weather_for_location],
context_schema=Context,
response_format=ResponseFormat,
checkpointer=checkpointer
)
# Run agent
# `thread_id` is a unique identifier for a given conversation.
config = {"configurable": {"thread_id": "1"}}
response = agent.invoke(
{"messages": [{"role": "user", "content": "what is the weather outside?"}]},
config=config,
context=Context(user_id="1")
)
print(response['structured_response'])
# ResponseFormat(
# punny_response="Florida is still having a 'sun-derful' day! The sunshine is playing 'ray-dio' hits all day long! I'd say it's the perfect weather for some 'solar-bration'! If you were hoping for rain, I'm afraid that idea is all 'washed up' - the forecast remains 'clear-ly' brilliant!",
# weather_conditions="It's always sunny in Florida!"
# )
# Note that we can continue the conversation using the same `thread_id`.
response = agent.invoke(
{"messages": [{"role": "user", "content": "thank you!"}]},
config=config,
context=Context(user_id="1")
)
print(response['structured_response'])
# ResponseFormat(
# punny_response="You're 'thund-erfully' welcome! It's always a 'breeze' to help you stay 'current' with the weather. I'm just 'cloud'-ing around waiting to 'shower' you with more forecasts whenever you need them. Have a 'sun-sational' day in the Florida sunshine!",
# weather_conditions=None
# )
恭喜!你现在拥有了一个 AI 智能体,它可以:
- 理解上下文并记住对话内容
- 智能地使用多个工具
- 以一致的格式提供结构化响应
- 通过上下文处理用户特定信息
- 在多轮交互中保持对话状态
这里需要注意一点,在 LangChain 1.0 中,context 和 config 虽然都与执行智能体相关,但它们的用途是不同的,并不重复。
context
- 用于传入运行时上下文(runtime context),例如用户信息、环境参数等。
- 在你的示例里:
context=Context(user_id="1")
这里就是把用户 ID 传给智能体,让它能根据用户做个性化处理(如 get_user_location 工具中用到 runtime.context.user_id)。
换句话说,context 是智能体内部逻辑和工具调用可访问的数据。
config
- 用于传入执行时配置(runtime configuration),通常控制智能体执行的行为或策略,而不是具体数据。
- 在你的示例里:
config = {"configurable": {"thread_id": "1"}}
thread_id 用于标识对话线程,以便智能体在同一个会话中保持状态。
如果没有 config,智能体可能无法区分不同会话或线程,即使 context 是同一个用户。
核心组件
智能体
智能体构建
智能体将语言模型(LLM)与工具结合起来,创建可以推理、决策并迭代完成任务的系统。
-
create_agent提供了生产可用的智能体实现。 -
LLM 智能体会在循环中调用工具以达成目标。
-
智能体会一直运行,直到满足停止条件(stop condition):
- 模型输出最终结果
- 或达到迭代次数上限
核心执行流程:
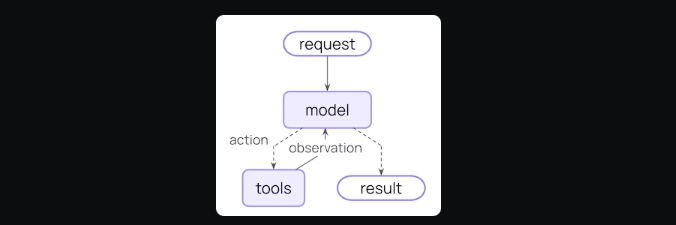
- input(输入) → 2. model(模型调用) → 3. action(选择工具或操作) → 4. tools(执行工具) → 5. observation(观察结果) → 6. finish(完成输出)
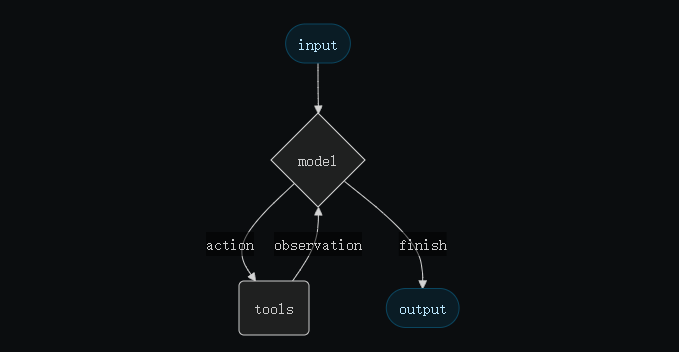
create_agent 使用 LangGraph 构建图结构的智能体运行时:
-
**图(Graph)由节点(nodes)和边(edges)**组成,用于定义智能体处理信息的方式
-
智能体沿着图移动,执行不同节点,例如:
- 模型节点(model node):调用模型
- 工具节点(tools node):执行工具
- 中间件节点(middleware):执行自定义逻辑
模型是智能体的推理引擎,支持多种指定方式,包括静态和动态模型选择。
静态模型(Static Model):
- 静态模型在创建智能体时配置,一旦运行就保持不变。
- 这是最常用、最直接的方式。
通过模型标识符字符串初始化静态模型:
from langchain.agents import create_agent
agent = create_agent(
"openai:gpt-5",
tools=tools
)
模型标识符字符串支持自动推断,例如
"gpt-5"会被推断为"openai:gpt-5"。
更精细的模型配置可直接使用提供商的模型实例:
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model="gpt-5",
temperature=0.1,
max_tokens=1000,
timeout=30
# ...其他参数
)
agent = create_agent(model, tools=tools)
使用模型实例可以完全控制配置参数,如
temperature、max_tokens、timeout、base_url等提供商特定设置。
动态模型(Dynamic Model):
- 动态模型在运行时根据当前状态和上下文选择模型。
- 支持复杂路由逻辑和成本优化。
要使用动态模型,需要创建一个带有 @wrap_model_call 装饰器的中间件,在请求中修改所使用的模型:
示例:基于对话长度选择模型
from langchain_openai import ChatOpenAI
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
basic_model = ChatOpenAI(model="gpt-4o-mini")
advanced_model = ChatOpenAI(model="gpt-4o")
@wrap_model_call
def dynamic_model_selection(request: ModelRequest, handler) -> ModelResponse:
"""根据对话复杂度选择模型"""
message_count = len(request.state["messages"])
if message_count > 10:
# 对较长对话使用高级模型
model = advanced_model
else:
model = basic_model
request.model = model
return handler(request)
agent = create_agent(
model=basic_model, # 默认模型
tools=tools,
middleware=[dynamic_model_selection]
)
⚠️ 注意:
- 在使用结构化输出(structured output)时,不支持预绑定模型(已调用
bind_tools的模型)。- 若需要动态模型选择并使用结构化输出,确保传入中间件的模型未预绑定。
工具(Tools):工具赋予智能体执行操作的能力。
智能体不仅仅是简单地绑定模型与工具,还支持:
- 按顺序调用多个工具(由单个提示触发)
- 在合适情况下并行调用工具
- 根据前一次结果动态选择工具
- 工具重试逻辑与错误处理
- 跨工具调用的状态持久化
定义工具(Defining Tools)将工具列表传递给智能体即可:
from langchain.tools import tool
from langchain.agents import create_agent
@tool
def search(query: str) -> str:
"""搜索信息"""
return f"Results for: {query}"
@tool
def get_weather(location: str) -> str:
"""获取指定地点的天气信息"""
return f"Weather in {location}: Sunny, 72°F"
agent = create_agent(model, tools=[search, get_weather])
如果提供空的工具列表,智能体将只包含一个 LLM 节点,不具备调用工具的能力。
要自定义工具错误的处理方式,可以使用 @wrap_tool_call 装饰器创建中间件:
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_tool_call
from langchain_core.messages import ToolMessage
@wrap_tool_call
def handle_tool_errors(request, handler):
"""Handle tool execution errors with custom messages."""
try:
return handler(request)
except Exception as e:
# Return a custom error message to the model
return ToolMessage(
content=f"Tool error: Please check your input and try again. ({str(e)})",
tool_call_id=request.tool_call["id"]
)
agent = create_agent(
model="gpt-4o",
tools=[search, get_weather],
middleware=[handle_tool_errors]
)
当工具执行失败时,智能体会返回带有自定义错误信息的 ToolMessage:
[
...
ToolMessage(
content="Tool error: Please check your input and try again. (division by zero)",
tool_call_id="..."
),
...
]
智能体遵循 ReAct(“推理 + 行动”)模式:在简短的推理步骤和精准的工具调用之间来回切换,并将工具调用的结果作为输入持续推理,直到能够给出最终答案。
一个ReAct 循环示例如下:
Prompt:
Identify the current most popular wireless headphones and verify availability.
(找出当前最流行的无线耳机,并确认是否有库存。)
================================ Human Message =================================
Find the most popular wireless headphones right now and check if they're in stock
**Reasoning(推理):** “流行度是时间敏感的,我需要用提供的搜索工具。”
**Acting(行动):** 调用 `search_products("wireless headphones")`
================================== Ai Message ==================================
Tool Calls:
search_products (call_abc123)
Call ID: call_abc123
Args:
query: wireless headphones
================================= Tool Message =================================
Found 5 products matching "wireless headphones". Top 5 results: WH-1000XM5, ...
**Reasoning:** “我需要确认排名最高的商品是否有库存。”
**Acting:** 调用 `check_inventory("WH-1000XM5")`
================================== Ai Message ==================================
Tool Calls:
check_inventory (call_def456)
Call ID: call_def456
Args:
product_id: WH-1000XM5
================================= Tool Message =================================
Product WH-1000XM5: 10 units in stock
**Reasoning:** “我已经有最热门型号和它的库存情况,现在可以回答用户问题。”
**Acting:** 生成最终答案
================================== Ai Message ==================================
I found wireless headphones (model WH-1000XM5) with 10 units in stock...
上文我们可以看到,你可以通过提供 prompt 来影响智能体处理任务的方式。
system_prompt 参数可以直接是一个字符串:
agent = create_agent(
model,
tools,
system_prompt="You are a helpful assistant. Be concise and accurate."
)
如果你没有提供 system_prompt,智能体会直接从消息内容中推断任务。
在更复杂的场景中,如果你需要根据运行时上下文或智能体状态来动态修改系统提示词,你可以使用 middleware(中间件)。
@dynamic_prompt 装饰器可以创建中间件,使系统提示词根据模型请求动态生成:
from typing import TypedDict
from langchain.agents import create_agent
from langchain.agents.middleware import dynamic_prompt, ModelRequest
class Context(TypedDict):
user_role: str
@dynamic_prompt
def user_role_prompt(request: ModelRequest) -> str:
"""Generate system prompt based on user role."""
user_role = request.runtime.context.get("user_role", "user")
base_prompt = "You are a helpful assistant."
if user_role == "expert":
return f"{base_prompt} Provide detailed technical responses."
elif user_role == "beginner":
return f"{base_prompt} Explain concepts simply and avoid jargon."
return base_prompt
agent = create_agent(
model="gpt-4o",
tools=[web_search],
middleware=[user_role_prompt],
context_schema=Context
)
# 系统提示词会根据 context 动态设置
result = agent.invoke(
{"messages": [{"role": "user", "content": "Explain machine learning"}]},
context={"user_role": "expert"}
)
调用智能体
你可以通过向智能体的 State 传入更新来调用它。
所有智能体的状态中都包含一组消息;要调用智能体,只需传入一条新的消息:
result = agent.invoke(
{"messages": [{"role": "user", "content": "What's the weather in San Francisco?"}]}
)
除此之外,智能体遵循 LangGraph 的 Graph API,并支持所有相关方法,例如 stream 和 invoke。
有人好奇,为什么这里的调用方式改为了传入一个莫名其妙的messages列表呢?
在langchain v1.0中,langchain本身是基于langGraph重构的一个内置的图,而写过langGraph的bro都清楚,这个图的运作是针对一个状态机进行的,上下文依赖于状态机,而create_agent内置了一个AgentState:
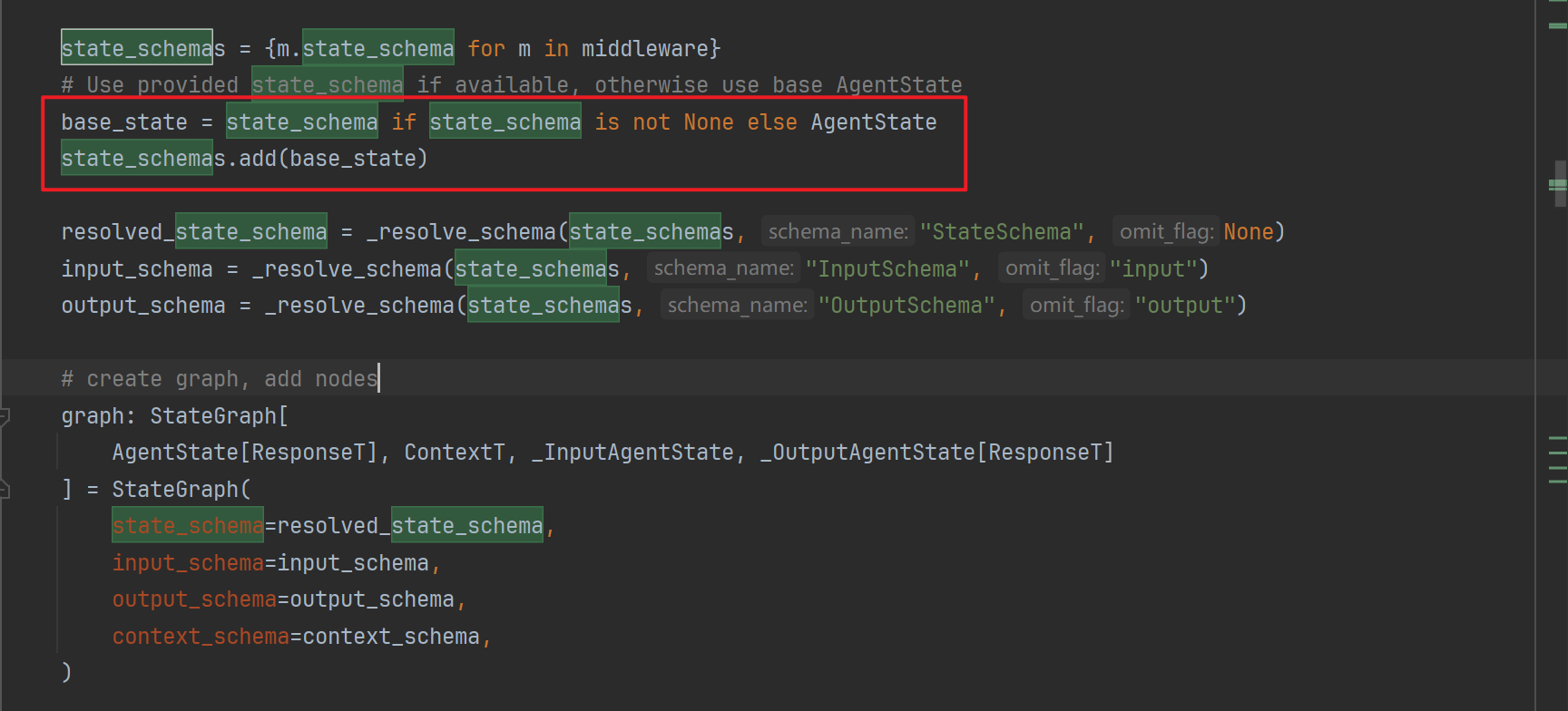
当我们不传入自定义的State时,langChain启用了内部的State,来看一下这个State的结构:
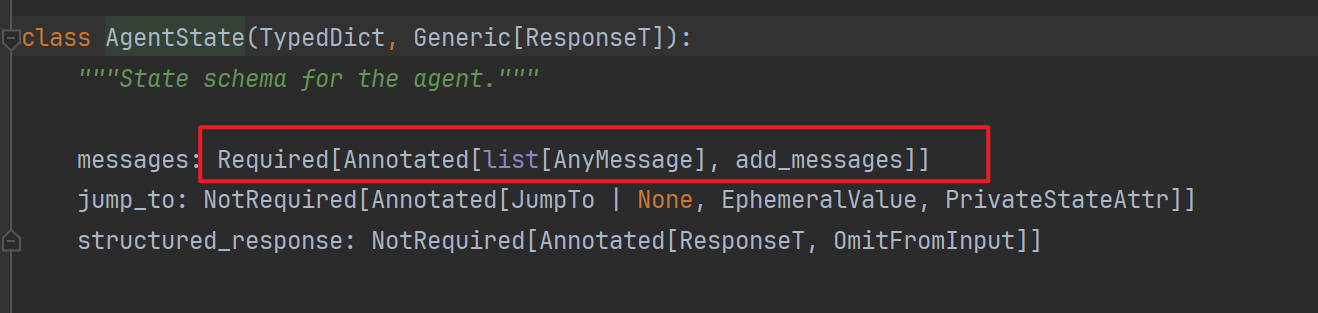
可以看到他是一个带有messages属性的TypeDict!而add_messages代表这个字段的行为,即传入的message不会替换反而是追加到上下文中!
高级概念
结构化输出
在某些情况下,你可能希望智能体按特定格式返回结果。
LangChain 通过 response_format 参数提供多种结构化输出策略。
ToolStrategy 使用“人工工具调用”(artificial tool calling)来生成结构化输出。
适用于任何支持工具调用的模型:
from pydantic import BaseModel
from langchain.agents import create_agent
from langchain.agents.structured_output import ToolStrategy
class ContactInfo(BaseModel):
name: str
email: str
phone: str
agent = create_agent(
model="gpt-4o-mini",
tools=[search_tool],
response_format=ToolStrategy(ContactInfo)
)
result = agent.invoke({
"messages": [{"role": "user", "content": "Extract contact info from: John Doe, john@example.com, (555) 123-4567"}]
})
result["structured_response"]
# ContactInfo(name='John Doe', email='john@example.com', phone='(555) 123-4567')
ProviderStrategy 使用模型提供商的原生结构化输出功能。
它更可靠,但仅适用于支持原生结构化输出的模型(如 OpenAI):
from langchain.agents.structured_output import ProviderStrategy
agent = create_agent(
model="gpt-4o",
response_format=ProviderStrategy(ContactInfo)
)
注意
从 langchain 1.0 开始,仅传入 schema(例如 response_format=ContactInfo)已经不再支持。
你必须显式使用:
ToolStrategy- 或
ProviderStrategy
记忆
智能体通过消息状态(message state)自动维护对话历史。
你也可以通过自定义状态(state schema)让智能体在对话中记住额外的信息。
存储在状态中的信息可以理解为智能体的短期记忆:
-
自定义状态必须作为
TypedDict继承自AgentState。 -
定义自定义状态有两种方式:
- 通过 middleware(推荐方式)
- 通过 create_agent 的 state_schema 参数
推荐使用 middleware,因为它可以让状态扩展在概念上与具体 middleware 和工具绑定,更好地隔离逻辑。
state_schema 仍然保留以兼容旧版本。
通过 middleware 定义状态(推荐方式):
当你的自定义状态需要被特定的 middleware hook 或与之绑定的工具访问时,应该使用此方式。
from langchain.agents import AgentState
from langchain.agents.middleware import AgentMiddleware
from typing import Any
class CustomState(AgentState):
user_preferences: dict
class CustomMiddleware(AgentMiddleware):
state_schema = CustomState
tools = [tool1, tool2]
def before_model(self, state: CustomState, runtime) -> dict[str, Any] | None:
...
agent = create_agent(
model,
tools=tools,
middleware=[CustomMiddleware()]
)
# 智能体现在可以追踪 messages 之外的额外状态
result = agent.invoke({
"messages": [{"role": "user", "content": "I prefer technical explanations"}],
"user_preferences": {"style": "technical", "verbosity": "detailed"},
})
通过 state_schema 定义状态:
如果你的自定义状态只用于工具中,可以使用简单的 state_schema 方式:
from langchain.agents import AgentState
class CustomState(AgentState):
user_preferences: dict
agent = create_agent(
model,
tools=[tool1, tool2],
state_schema=CustomState
)
# 智能体现在可以追踪 messages 之外的额外状态
result = agent.invoke({
"messages": [{"role": "user", "content": "I prefer technical explanations"}],
"user_preferences": {"style": "technical", "verbosity": "detailed"},
})
注意
从 langchain 1.0 开始:
- 自定义状态必须是
TypedDict类型 - Pydantic 模型和 dataclass 已不再支持
流式输出
之前我们看到,智能体可以通过 invoke 返回最终结果。但如果智能体需要执行多个步骤,这可能会花费较长时间。
为了显示中间进度,你可以在执行过程中实时流式返回消息。
for chunk in agent.stream({
"messages": [{"role": "user", "content": "Search for AI news and summarize the findings"}]
}, stream_mode="values"):
# 每个 chunk 都包含当时的完整状态
latest_message = chunk["messages"][-1]
if latest_message.content:
print(f"Agent: {latest_message.content}")
elif latest_message.tool_calls:
print(f"Calling tools: {[tc['name'] for tc in latest_message.tool_calls]}")
StreamMode = Literal[
"values", "updates", "checkpoints", "tasks", "debug", "messages", "custom"
]
"""
stream 方法应以何种方式输出数据。
- "values":在每一步执行后(包括中断时),输出状态中的所有值。
在使用函数式 API 时,values 仅在工作流结束时输出一次。
- "updates":仅输出每一步中由节点或任务返回的节点名称或任务名称以及它们的更新内容。
如果同一步中有多个更新(例如执行了多个节点),这些更新会单独输出。
- "custom":在节点或任务内部使用 `StreamWriter` 输出自定义数据。
- "messages":逐 token 输出 LLM 消息,并包含节点或任务中任何 LLM 调用的元数据。
- "checkpoints":当创建检查点时输出事件,格式与 `get_state()` 的返回结果一致。
- "tasks":当任务开始和结束时输出事件,包括任务的结果和错误信息。
- "debug":同时输出 "checkpoints" 和 "tasks" 两类事件,用于调试目的。
"""
模型
LLM(大型语言模型)是一类强大的 AI 工具,能够像人类一样理解并生成文本。
它们非常通用,无需针对每个任务进行专门训练,就能用于写作、翻译、总结、回答问题等多种场景。
除了文本生成,许多模型还支持:
- 工具调用(Tool calling) —— 调用外部工具(例如数据库查询或 API 调用),并将结果用于生成回答
- 结构化输出(Structured output) —— 模型输出会被约束为遵循特定格式
- 多模态(Multimodality) —— 处理并返回除文本外的数据,例如图像、音频、视频
- 推理(Reasoning) —— 模型能够进行多步骤推理以得出结论
模型是智能体的推理引擎。
它们驱动智能体的决策过程,包括:
- 何时调用工具
- 如何解释返回结果
- 何时给出最终答案
你选择的模型的质量和功能会直接影响智能体的可靠性与表现。
不同模型各有所长——有些擅长遵循复杂指令,有些擅长结构化思考,有些支持更大的上下文窗口来处理更多信息。
LangChain 提供统一的模型接口,支持多家提供商的模型,使你可以轻松尝试和切换模型,找到最适合你的任务。
模型可以通过两种方式使用:
-
与智能体(Agents)配合使用
在创建智能体时动态指定模型。 -
独立使用(Standalone)
模型可以直接调用,用于文本生成、分类、抽取等任务,而不需要 agent 框架。
同一套模型接口适用于这两种场景,这让你能够从简单开始,并在需要时扩展到更复杂的基于智能体的工作流。
在 LangChain 中初始化独立模型最简单的方式是使用 init_chat_model,它可以从你选择的聊天模型提供商加载模型,例如:
- OpenAI
- Anthropic
- Azure
- Google Gemini
- AWS Bedrock
示例:安装 OpenAI 支持
pip install -U "langchain[openai]"
使用 init_chat_model 初始化模型
import os
from langchain.chat_models import init_chat_model
os.environ["OPENAI_API_KEY"] = "sk-..."
model = init_chat_model("gpt-4.1")
调用模型
response = model.invoke("Why do parrots talk?")
关键方法(Key methods)
-
Invoke
模型接收消息作为输入,并在完成生成后返回完整的响应。
-
Stream
与 invoke 类似,但模型会实时逐步流式返回生成内容。
-
Batch
批量发送多条请求以提高处理效率。
聊天模型接受一系列参数,用于配置其行为。不同的模型和提供商可能支持不同的参数,但常见的标准参数如下:
常见参数
| 参数名称 | 类型 | 描述 |
|---|---|---|
| model | 字符串 | 要使用的具体模型名称或标识符(必填)。 |
| api_key | 字符串 | 用于验证模型提供商的 API 密钥。通常在注册时获得,可以通过设置环境变量来访问。 |
| temperature | 数字 | 控制模型输出的随机性。值越高,输出越富有创造性;值越低,输出越确定。 |
| timeout | 数字 | 等待模型响应的最长时间(单位:秒),超时后取消请求。 |
| max_tokens | 数字 | 限制模型响应的最大 token 数量,从而控制输出的长度。 |
| max_retries | 数字 | 请求失败时(如网络超时或速率限制)重试的最大次数。 |
使用 init_chat_model 时,可以将这些参数作为 kwargs 传入:
model = init_chat_model(
"claude-sonnet-4-5-20250929",
# 传递给模型的参数:
temperature=0.7,
timeout=30,
max_tokens=1000,
)
附加参数
每个聊天模型集成可能会有额外的参数,用于控制特定提供商的功能。例如,ChatOpenAI 模型有 use_responses_api 参数,用于指定是否使用 OpenAI Responses API 或 Completions API。
模型直接调用
聊天模型必须通过调用才能生成输出。有三种主要的调用方式,每种方式适用于不同的使用场景。
调用模型最直接的方法是使用 invoke(),它可以接收单条消息或消息列表。
response = model.invoke("Why do parrots have colorful feathers?")
print(response)
你可以将消息列表传递给模型,以表示对话历史。每条消息都有一个角色,模型通过角色来标识消息的发送者。更多关于角色、类型和内容的信息,请参阅消息指南。
conversation = [
{"role": "system", "content": "You are a helpful assistant that translates English to French."},
{"role": "user", "content": "Translate: I love programming."},
{"role": "assistant", "content": "J'adore la programmation."},
{"role": "user", "content": "Translate: I love building applications."}
]
response = model.invoke(conversation)
print(response) # AIMessage("J'adore créer des applications.")
你也可以使用消息对象来表示对话内容:
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
conversation = [
SystemMessage("You are a helpful assistant that translates English to French."),
HumanMessage("Translate: I love programming."),
AIMessage("J'adore la programmation."),
HumanMessage("Translate: I love building applications.")
]
response = model.invoke(conversation)
print(response) # AIMessage("J'adore créer des applications.")
大多数模型支持流式输出,即在生成过程中逐步返回内容。通过流式输出,可以显著改善用户体验,特别是在处理较长响应时。
调用 stream() 会返回一个迭代器,逐步输出生成的内容。你可以使用循环实时处理每个输出块:
基本文本流式输出
for chunk in model.stream("Why do parrots have colorful feathers?"):
print(chunk.text, end="|", flush=True)
流式输出工具调用、推理和其他内容
for chunk in model.stream("What color is the sky?"):
for block in chunk.content_blocks:
if block["type"] == "reasoning" and (reasoning := block.get("reasoning")):
print(f"推理: {reasoning}")
elif block["type"] == "tool_call_chunk":
print(f"工具调用块: {block}")
elif block["type"] == "text":
print(block["text"])
else:
...
这种方式允许你在流式输出中处理工具调用、推理步骤以及文本内容,并根据类型对其进行相应的处理。
与 invoke() 不同,stream() 在模型完成生成之前,会逐步返回多个 AIMessageChunk 对象,每个对象包含输出的一部分文本。每个流中的块会被逐步汇总成完整的消息:
full = None # None | AIMessageChunk
for chunk in model.stream("What color is the sky?"):
full = chunk if full is None else full + chunk
print(full.text)
# 输出逐步返回的结果:
# The
# The sky
# The sky is
# The sky is typically
# The sky is typically blue
# ...
print(full.content_blocks)
# [{"type": "text", "text": "The sky is typically blue..."}]
生成的消息可以像 invoke() 生成的消息一样处理。例如,可以将其聚合为消息历史,并作为对话上下文传回模型。
流式输出只在程序的所有步骤都支持处理数据流时才有效。例如,一个不支持流式处理的应用程序需要先将整个输出存储在内存中,然后才能进行处理。
高级流式输出(Advanced streaming topics)
LangChain 通过在某些情况下自动启用流式模式,简化了从聊天模型的流式输出,即使你没有明确调用流式方法。当你使用非流式的 invoke 方法时,仍然希望流式处理整个应用程序,包括聊天模型的中间结果,这时自动流式功能特别有用。
例如,在 LangGraph 智能体中,你可以在节点内调用 model.invoke(),但如果在流式模式下运行,LangChain 会自动切换到流式处理。
工作原理:当你调用 invoke() 进行聊天模型请求时,LangChain 会自动检测并切换到内部流式模式,如果它发现你尝试对整体应用程序进行流式处理。从使用 invoke 的代码角度来看,调用的结果是一样的;但是,在聊天模型流式处理时,LangChain 会自动处理 on_llm_new_token 事件,这些事件会通过 LangChain 的回调系统触发。
回调事件使得 LangGraph 的 stream() 和 astream_events() 可以实时展示聊天模型的输出。
流式事件(Streaming events)
LangChain 聊天模型还可以使用 astream_events() 流式处理语义事件。
这简化了基于事件类型和其他元数据的过滤,同时会在后台聚合完整的消息。以下是一个示例:
async for event in model.astream_events("Hello"):
if event["event"] == "on_chat_model_start":
print(f"输入: {event['data']['input']}")
elif event["event"] == "on_chat_model_stream":
print(f"Token: {event['data']['chunk'].text}")
elif event["event"] == "on_chat_model_end":
print(f"完整消息: {event['data']['output'].text}")
else:
pass
输出示例:
输入: Hello
Token: Hi
Token: there
Token: !
Token: How
Token: can
Token: I
...
完整消息: Hi there! How can I help today?
这种方式使得你可以精细化地控制流式输出的每个阶段,便于实时处理和展示聊天模型的输出。
Batch批量处理将一组独立的请求批量发送给模型,可以显著提高性能并减少成本,因为这些请求可以并行处理:
responses = model.batch([
"Why do parrots have colorful feathers?",
"How do airplanes fly?",
"What is quantum computing?"
])
for response in responses:
print(response)
此方法通过客户端并行化模型调用,区别于提供商支持的批量 API,如 OpenAI 或 Anthropic 提供的批量 API。
默认情况下,batch() 会返回整个批次的最终输出。如果希望在每个输入生成完成时接收其对应的输出,可以使用 batch_as_completed() 流式返回结果:
for response in model.batch_as_completed([
"Why do parrots have colorful feathers?",
"How do airplanes fly?",
"What is quantum computing?"
]):
print(response)
使用 batch_as_completed() 时,结果可能会乱序返回。每个结果包含输入的索引,可以根据需要将它们重新排序。
在处理大量输入时,使用 batch() 或 batch_as_completed() 时,可能需要控制最大并行调用数。你可以通过在 RunnableConfig 字典中设置 max_concurrency 来实现:
model.batch(
list_of_inputs,
config={
'max_concurrency': 5, # 限制最多 5 个并行调用
}
)
工具调用
模型可以请求调用工具来执行任务,例如从数据库中获取数据、在网络上搜索或运行代码。工具由以下部分组成:
- 架构,包括工具的名称、描述和/或参数定义(通常为 JSON 架构)
- 执行函数或协程
你可能会听到“函数调用”这一术语,我们将其与“工具调用”互换使用。
以下是用户与模型之间工具调用的基本流程:
- 用户询问问题:“What’s the weather in SF and NYC?”
- 模型分析请求并决定需要调用的工具
- 工具:调用
get_weather("San Francisco")和get_weather("New York") - 工具执行:获取旧金山和纽约的天气数据
- 模型:处理结果并生成响应
- 用户:得到最终的回答:“SF: 72°F sunny, NYC: 68°F cloudy”
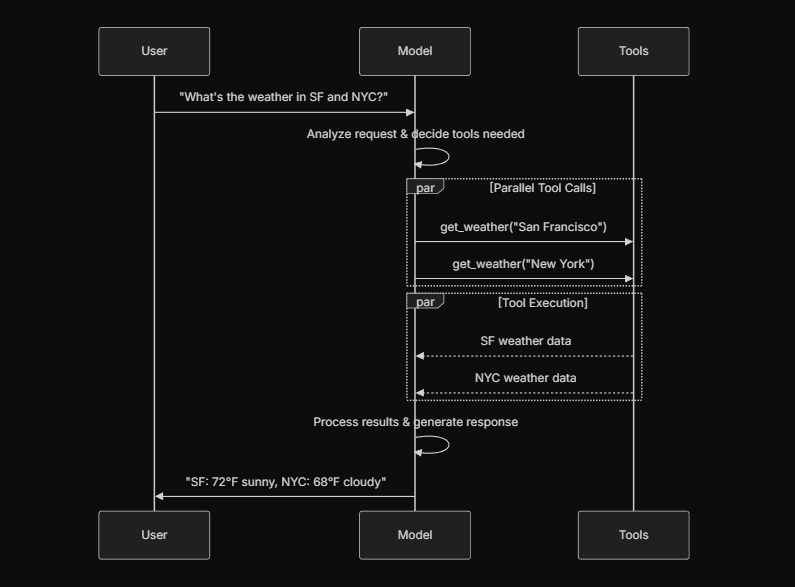
为了使你定义的工具可以被模型使用,必须使用 bind_tools 将它们绑定。在随后的调用中,模型可以根据需要选择调用任何绑定的工具。
一些模型提供商提供了内置工具,可以通过模型或调用参数启用(例如 ChatOpenAI,ChatAnthropic)。请查阅相关提供商的文档了解详细信息。
绑定用户自定义工具
from langchain.tools import tool
@tool
def get_weather(location: str) -> str:
"""获取指定位置的天气信息。"""
return f"It's sunny in {location}."
# 绑定自定义工具
model_with_tools = model.bind_tools([get_weather])
response = model_with_tools.invoke("What's the weather like in Boston?")
for tool_call in response.tool_calls:
# 查看模型调用的工具
print(f"工具: {tool_call['name']}")
print(f"参数: {tool_call['args']}")
当绑定用户定义的工具时,模型的响应中会包含请求执行工具的内容。如果模型与智能体分开使用,则需要你自己执行请求的工具,并将结果返回给模型,以便在后续推理中使用。而在使用智能体时,智能体的循环会为你处理工具执行的过程。
下面展示了一些常见的工具调用方式。
工具执行循环(Tool execution loop)
当模型返回工具调用时,你需要执行这些工具并将结果返回给模型。这就形成了一个对话循环,模型可以使用工具的结果生成最终响应。LangChain 提供了智能体抽象,可以帮你处理这一协调过程。
# 将(可能多个)工具绑定到模型
model_with_tools = model.bind_tools([get_weather])
# 步骤 1:模型生成工具调用
messages = [{"role": "user", "content": "What's the weather in Boston?"}]
ai_msg = model_with_tools.invoke(messages)
messages.append(ai_msg)
# 步骤 2:执行工具并收集结果
for tool_call in ai_msg.tool_calls:
# 使用生成的参数执行工具
tool_result = get_weather.invoke(tool_call)
messages.append(tool_result)
# 步骤 3:将结果返回给模型生成最终响应
final_response = model_with_tools.invoke(messages)
print(final_response.text)
# 输出: "The current weather in Boston is 72°F and sunny."
每个工具返回的 ToolMessage 都包含一个 tool_call_id,与原始工具调用匹配,帮助模型将结果与请求关联。
强制调用工具
默认情况下,模型可以根据用户输入自由选择使用哪个绑定工具。不过,你也可以强制模型使用某个特定工具或列表中的任意工具。
# 强制使用任意工具
model_with_tools = model.bind_tools([tool_1], tool_choice="any")
# 强制使用特定工具
model_with_tools = model.bind_tools([tool_1], tool_choice="specific")
并行工具调用
许多模型在适当情况下支持并行调用多个工具,使模型能够同时从不同来源获取信息。
model_with_tools = model.bind_tools([get_weather])
response = model_with_tools.invoke("What's the weather in Boston and Tokyo?")
# 模型可能生成多个工具调用
print(response.tool_calls)
# [
# {'name': 'get_weather', 'args': {'location': 'Boston'}, 'id': 'call_1'},
# {'name': 'get_weather', 'args': {'location': 'Tokyo'}, 'id': 'call_2'},
# ]
# 执行所有工具(可以使用 async 并行处理)
results = []
for tool_call in response.tool_calls:
if tool_call['name'] == 'get_weather':
result = get_weather.invoke(tool_call)
...
results.append(result)
模型会根据请求操作的独立性智能判断是否适合并行执行。
大多数支持工具调用的模型默认开启并行调用。部分模型(如 OpenAI 和 Anthropic)允许关闭此功能:
model.bind_tools([get_weather], parallel_tool_calls=False)
流式工具调用
在流式响应时,工具调用会通过 ToolCallChunk 逐步生成。这允许你在生成过程中实时查看工具调用,而无需等待完整响应。
for chunk in model_with_tools.stream("What's the weather in Boston and Tokyo?"):
# 工具调用块逐步到达
for tool_chunk in chunk.tool_call_chunks:
if name := tool_chunk.get("name"):
print(f"工具: {name}")
if id_ := tool_chunk.get("id"):
print(f"ID: {id_}")
if args := tool_chunk.get("args"):
print(f"参数: {args}")
输出示例:
# Output:
# Tool: get_weather
# ID: call_SvMlU1TVIZugrFLckFE2ceRE
# Args: {"lo
# Args: catio
# Args: n": "B
# Args: osto
# Args: n"}
# Tool: get_weather
# ID: call_QMZdy6qInx13oWKE7KhuhOLR
# Args: {"lo
# Args: catio
# Args: n": "T
# Args: okyo
# Args: "}
你也可以将多个块累积起来,构建完整的工具调用:
gathered = None
for chunk in model_with_tools.stream("What's the weather in Boston?"):
gathered = chunk if gathered is None else gathered + chunk
print(gathered.tool_calls)
结构化输出
可以要求模型以符合给定架构的格式提供响应。这对于确保输出可以轻松解析并在后续处理中使用非常有用。LangChain 支持多种架构类型和方法来强制执行结构化输出。
支持的架构类型:
- Pydantic
- TypedDict
- JSON Schema
Pydantic 模型提供了最丰富的特性集,包括字段验证、描述和嵌套结构。
from pydantic import BaseModel, Field
class Movie(BaseModel):
"""包含电影详情的模型"""
title: str = Field(..., description="电影的标题")
year: int = Field(..., description="电影的上映年份")
director: str = Field(..., description="电影的导演")
rating: float = Field(..., description="电影的评分(满分 10)")
model_with_structure = model.with_structured_output(Movie)
response = model_with_structure.invoke("Provide details about the movie Inception")
print(response) # Movie(title="Inception", year=2010, director="Christopher Nolan", rating=8.8)
TypedDict 提供了一个更简洁的替代方案,使用 Python 内置的类型系统即可实现,适合不需要运行时验证的场景。
from typing_extensions import TypedDict, Annotated
class MovieDict(TypedDict):
"""包含电影详情的字典"""
title: Annotated[str, ..., "电影的标题"]
year: Annotated[int, ..., "电影的上映年份"]
director: Annotated[str, ..., "电影的导演"]
rating: Annotated[float, ..., "电影的评分(满分 10)"]
model_with_structure = model.with_structured_output(MovieDict)
response = model_with_structure.invoke("Provide details about the movie Inception")
print(response)
# 输出: {'title': 'Inception', 'year': 2010, 'director': 'Christopher Nolan', 'rating': 8.8}
TypedDict不提供运行时验证,如果需要验证则应使用 Pydantic。- 可以通过
with_structured_output方法将 TypedDict 与模型绑定,使模型输出自动遵循定义的结构。 - 可与
include_raw=True一起使用,同时获取原始 AI 消息和解析后的数据结构。
结构化输出的关键考虑事项:
-
方法参数:
一些提供商支持不同的方法(例如json_schema,function_calling,json_mode)来实现结构化输出:json_schema:通常指提供商提供的专用结构化输出功能。function_calling:通过强制工具调用并遵循给定的架构来生成结构化输出。json_mode:是一些提供商提供的json_schema先行模式,它生成有效的 JSON,但架构必须在提示中描述。
-
包含原始内容(Include raw):
使用include_raw=True可以同时获得解析后的输出和原始 AI 消息。 -
验证:
- Pydantic 模型 提供自动验证。
- TypedDict 和 JSON Schema 需要手动验证。
示例:消息输出与解析结构
可以同时返回原始的 AIMessage 对象和解析后的表示,以便访问响应的元数据,如令牌计数。为此,在调用 with_structured_output 时,设置 include_raw=True:
from pydantic import BaseModel, Field
class Movie(BaseModel):
"""包含电影详情的模型"""
title: str = Field(..., description="电影的标题")
year: int = Field(..., description="电影的上映年份")
director: str = Field(..., description="电影的导演")
rating: float = Field(..., description="电影的评分(满分 10)")
model_with_structure = model.with_structured_output(Movie, include_raw=True)
response = model_with_structure.invoke("Provide details about the movie Inception")
print(response)
# 输出:
# {
# "raw": AIMessage(...),
# "parsed": Movie(title=..., year=..., ...),
# "parsing_error": None,
# }
示例:嵌套结构
from pydantic import BaseModel, Field
class Actor(BaseModel):
name: str
role: str
class MovieDetails(BaseModel):
title: str
year: int
cast: list[Actor]
genres: list[str]
budget: float | None = Field(None, description="预算(单位:百万美元)")
model_with_structure = model.with_structured_output(MovieDetails)
高级功能
多模态
某些模型能够处理和返回非文本数据,如图像、音频和视频。可以通过提供 内容块(content blocks) 的方式,将非文本数据传递给模型。
所有具有底层多模态能力的 LangChain 聊天模型都支持:
- 跨提供商的标准格式数据(详见消息指南)
- OpenAI 聊天完成格式
- 任何特定提供商原生格式(例如 Anthropic 模型接受 Anthropic 原生格式)
部分模型还可以在响应中返回多模态数据。如果模型被调用以生成多模态输出,返回的 AIMessage 将包含多模态类型的内容块。
response = model.invoke("Create a picture of a cat")
print(response.content_blocks)
# [
# {"type": "text", "text": "Here's a picture of a cat"},
# {"type": "image", "base64": "...", "mime_type": "image/jpeg"},
# ]
推理
新一代模型能够执行多步推理来得出结论,即将复杂问题拆解为更小、更易处理的步骤。
如果底层模型支持,可以显示该推理过程,以更好地理解模型如何得出最终答案。
示例:流式推理输出
for chunk in model.stream("Why do parrots have colorful feathers?"):
reasoning_steps = [r for r in chunk.content_blocks if r["type"] == "reasoning"]
print(reasoning_steps if reasoning_steps else chunk.text)
- 根据模型,有时可以指定推理的“努力程度”。
- 也可以要求模型完全关闭推理。
- 这种设置可能表现为分类“等级”(例如
'low'或'high')或整数令牌预算。
本地模型
LangChain 支持在本地硬件上运行模型,适用于以下场景:
- 数据隐私要求高
- 需要调用自定义模型
- 避免使用云模型产生的费用
Ollama 是在本地运行模型的最简单方式之一。
Prompt缓存
许多提供商提供Prompt缓存功能,以减少重复处理相同令牌时的延迟和成本。缓存可以是隐式或显式的:
-
隐式缓存:
当请求命中缓存时,提供商会自动传递成本节省。例如:OpenAI 和 Gemini(Gemini 2.5 及以上版本)。 -
显式缓存:
允许手动指定缓存点,以获得更大控制或保证成本节省。例如:ChatOpenAI(通过prompt_cache_key)、Anthropic 的AnthropicPromptCachingMiddleware和cache_control选项、AWS Bedrock、Gemini。
提示缓存通常仅在输入令牌超过最低阈值时启用。具体详情请参考提供商页面。
缓存使用情况会在模型响应的 使用元数据(usage metadata) 中体现。
服务端工具使用
部分提供商支持 服务端工具调用循环:模型可以在单轮对话中与网络搜索、代码解释器等工具交互,并分析结果。
如果模型在服务端调用工具,响应消息的内容将包含表示工具调用及其结果的内容块。访问响应content_blocks 会返回服务端工具调用和结果,且格式与提供商无关。
示例:服务端工具调用
from langchain.chat_models import init_chat_model
model = init_chat_model("gpt-4.1-mini")
tool = {"type": "web_search"}
model_with_tools = model.bind_tools([tool])
response = model_with_tools.invoke("What was a positive news story from today?")
response.content_blocks
返回结果示例
[
{
"type": "server_tool_call",
"name": "web_search",
"args": {
"query": "positive news stories today",
"type": "search"
},
"id": "ws_abc123"
},
{
"type": "server_tool_result",
"tool_call_id": "ws_abc123",
"status": "success"
},
{
"type": "text",
"text": "Here are some positive news stories from today...",
"annotations": [
{
"end_index": 410,
"start_index": 337,
"title": "article title",
"type": "citation",
"url": "..."
}
]
}
]
- 这表示一次完整的对话轮次;无需像客户端工具调用那样传入 ToolMessage 对象。
- 具体可用工具及使用详情,请参考对应提供商的集成页面。
速率限制
许多聊天模型提供商会限制在特定时间段内的调用次数。
- 如果达到速率限制,通常会收到提供商的 rate limit 错误响应,需要等待后才能继续请求。
- 为管理速率限制,聊天模型集成支持在初始化时提供
rate_limiter参数,用于控制请求速率。
示例:初始化并使用速率限制器
LangChain 提供可选的内置 InMemoryRateLimiter,线程安全,可在同一进程的多个线程间共享。
from langchain_core.rate_limiters import InMemoryRateLimiter
rate_limiter = InMemoryRateLimiter(
requests_per_second=0.1, # 每 10 秒 1 次请求
check_every_n_seconds=0.1, # 每 100ms 检查一次是否允许发起请求
max_bucket_size=10, # 控制最大突发请求数
)
model = init_chat_model(
model="gpt-5",
model_provider="openai",
rate_limiter=rate_limiter
)
- 该速率限制器仅限制单位时间内请求次数。
- 若还需要限制请求大小,则需使用其他方式处理。
基础 URL 或代理配置
在许多聊天模型集成中,可以配置 API 请求的 基础 URL,这可以用于:
- 使用兼容 OpenAI API 的模型提供商
- 或者通过代理服务器访问模型
基础 URL 配置
许多模型提供商提供 OpenAI 兼容的 API(例如 Together AI、vLLM)。使用 init_chat_model 时可以通过 base_url 参数指定:
model = init_chat_model(
model="MODEL_NAME",
model_provider="openai",
base_url="BASE_URL",
api_key="YOUR_API_KEY",
)
- 如果直接使用聊天模型类实例化,参数名称可能因提供商而异,具体请参考对应文档。
对于需要 HTTP 代理的部署,一些模型集成支持代理配置:
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model="gpt-4o",
openai_proxy="http://proxy.example.com:8080"
)
- 不同集成对代理的支持情况不同,请参考具体模型提供商的文档。
对数概率
某些模型可以返回 每个 token 的对数概率,用于表示生成该 token 的可能性。可在初始化模型时通过logprobs 参数开启:
model = init_chat_model(
model="gpt-4o",
model_provider="openai"
).bind(logprobs=True)
response = model.invoke("Why do parrots talk?")
print(response.response_metadata["logprobs"])
Token 使用情况
- 部分模型提供商会在调用响应中返回 token 使用信息。
- 当可用时,这些信息会包含在 AIMessage 对象中。
- 某些提供商(如 OpenAI、Azure OpenAI)在流式调用场景下,需要用户 显式选择 接收 token 使用数据。
可以通过回调或上下文管理器跟踪应用中多个模型的 token 总量:
回调处理器示例
from langchain.chat_models import init_chat_model
from langchain_core.callbacks import UsageMetadataCallbackHandler
model_1 = init_chat_model(model="gpt-4o-mini")
model_2 = init_chat_model(model="claude-haiku-4-5-20251001")
callback = UsageMetadataCallbackHandler()
result_1 = model_1.invoke("Hello", config={"callbacks": [callback]})
result_2 = model_2.invoke("Hello", config={"callbacks": [callback]})
callback.usage_metadata
上下文管理器示例
from langchain.chat_models import init_chat_model
from langchain_core.callbacks import get_usage_metadata_callback
model_1 = init_chat_model(model="gpt-4o-mini")
model_2 = init_chat_model(model="claude-haiku-4-5-20251001")
with get_usage_metadata_callback() as cb:
model_1.invoke("Hello")
model_2.invoke("Hello")
print(cb.usage_metadata)
返回示例
{
"gpt-4o-mini-2024-07-18": {
"input_tokens": 8,
"output_tokens": 10,
"total_tokens": 18,
"input_token_details": {"audio": 0, "cache_read": 0},
"output_token_details": {"audio": 0, "reasoning": 0}
},
"claude-haiku-4-5-20251001": {
"input_tokens": 8,
"output_tokens": 21,
"total_tokens": 29,
"input_token_details": {"cache_read": 0, "cache_creation": 0}
}
}
input_tokens:输入 token 数量output_tokens:输出 token 数量total_tokens:总 token 数量input_token_details/output_token_details:按类型统计 token 使用情况
调用配置
在调用模型时,可以通过 config 参数传递额外的配置,使用 RunnableConfig 字典。这提供了对执行行为、回调和元数据跟踪的运行时控制。
调用示例
response = model.invoke(
"Tell me a joke",
config={
"run_name": "joke_generation", # 该运行的自定义名称
"tags": ["humor", "demo"], # 用于分类的标签
"metadata": {"user_id": "123"}, # 自定义元数据
"callbacks": [my_callback_handler], # 回调处理器
}
)
这些配置值在以下场景中尤其有用:
- 使用 LangSmith 进行调试和追踪
- 实现自定义日志记录或监控
- 控制生产环境中的资源使用
- 在复杂管道中跟踪调用
关键配置属性(Key configuration attributes)
-
run_name
- 类型:
string - 作用:标识此特定调用的名称,用于日志和追踪,不会被子调用继承。
- 类型:
-
tags
- 类型:
string[] - 作用:标签,供所有子调用继承,便于在调试工具中进行过滤和组织。
- 类型:
-
metadata
- 类型:
object - 作用:自定义键值对,用于跟踪额外的上下文,所有子调用都会继承。
- 类型:
-
max_concurrency
- 类型:
number - 作用:控制使用
batch()或batch_as_completed()时最大并发调用数。
- 类型:
-
callbacks
- 类型:
array - 作用:用于在执行过程中监控和响应事件的处理器。
- 类型:
-
recursion_limit
- 类型:
number - 作用:设置链式调用的最大递归深度,防止在复杂管道中出现无限循环。
- 类型:
可配置模型
您还可以通过指定 configurable_fields 来创建一个运行时可配置的模型。如果没有指定模型值,则默认 model 和 model_provider 会是可配置的。
from langchain.chat_models import init_chat_model
configurable_model = init_chat_model(temperature=0)
configurable_model.invoke(
"what's your name",
config={"configurable": {"model": "gpt-5-nano"}}, # 使用 GPT-5-Nano 模型运行
)
configurable_model.invoke(
"what's your name",
config={"configurable": {"model": "claude-sonnet-4-5-20250929"}}, # 使用 Claude 模型运行
)
具有默认值的可配置模型
我们可以创建一个具有默认模型值的可配置模型,指定哪些参数是可配置的,并为可配置的参数添加前缀:
first_model = init_chat_model(
model="gpt-4.1-mini",
temperature=0,
configurable_fields=("model", "model_provider", "temperature", "max_tokens"),
config_prefix="first", # 当有多个模型的链式调用时非常有用
)
first_model.invoke("what's your name")
first_model.invoke(
"what's your name",
config={
"configurable": {
"first_model": "claude-sonnet-4-5-20250929",
"first_temperature": 0.5,
"first_max_tokens": 100,
}
},
)
声明式使用可配置模型
我们可以像对常规实例化的聊天模型对象一样,在可配置模型上调用声明式操作(如 bind_tools、with_structured_output、with_configurable 等)并将可配置模型链接起来。
from pydantic import BaseModel, Field
class GetWeather(BaseModel):
"""获取指定位置的当前天气"""
location: str = Field(..., description="城市和州,例如:San Francisco, CA")
class GetPopulation(BaseModel):
"""获取指定位置的当前人口"""
location: str = Field(..., description="城市和州,例如:San Francisco, CA")
model = init_chat_model(temperature=0)
model_with_tools = model.bind_tools([GetWeather, GetPopulation])
model_with_tools.invoke(
"what's bigger in 2024 LA or NYC", config={"configurable": {"model": "gpt-4.1-mini"}}
).tool_calls
[
{
'name': 'GetPopulation',
'args': {'location': 'Los Angeles, CA'},
'id': 'call_Ga9m8FAArIyEjItHmztPYA22',
'type': 'tool_call'
},
{
'name': 'GetPopulation',
'args': {'location': 'New York, NY'},
'id': 'call_jh2dEvBaAHRaw5JUDthOs7rt',
'type': 'tool_call'
}
]
model_with_tools.invoke(
"what's bigger in 2024 LA or NYC",
config={"configurable": {"model": "claude-sonnet-4-5-20250929"}},
).tool_calls
[
{
'name': 'GetPopulation',
'args': {'location': 'Los Angeles, CA'},
'id': 'toolu_01JMufPf4F4t2zLj7miFeqXp',
'type': 'tool_call'
},
{
'name': 'GetPopulation',
'args': {'location': 'New York City, NY'},
'id': 'toolu_01RQBHcE8kEEbYTuuS8WqY1u',
'type': 'tool_call'
}
]
消息
消息是 LangChain 中模型的基本上下文单元。它们表示模型的输入和输出,包含在与大语言模型(LLM)交互时所需的内容和元数据,用于表示对话的状态。
消息是包含以下内容的对象:
- 角色(Role) - 标识消息的类型(例如:系统、用户)
- 内容(Content) - 表示消息的实际内容(如文本、图片、音频、文档等)
- 元数据(Metadata) - 可选字段,例如响应信息、消息 ID 和令牌使用情况
LangChain 提供了一种标准的消息类型,可在所有模型提供商中使用,确保无论调用哪个模型,都能保持一致的行为。
使用消息的最简单方式是创建消息对象,并在调用模型时将其传递给模型。
from langchain.chat_models import init_chat_model
from langchain.messages import HumanMessage, AIMessage, SystemMessage
model = init_chat_model("gpt-5-nano")
system_msg = SystemMessage("You are a helpful assistant.")
human_msg = HumanMessage("Hello, how are you?")
# 与聊天模型一起使用
messages = [system_msg, human_msg]
response = model.invoke(messages) # 返回 AIMessage
**文本提示(Text prompts)**文本提示是字符串,非常适合简单的生成任务,尤其是当您不需要保留对话历史时。
response = model.invoke("Write a haiku about spring")
使用文本提示时的场景:
- 您有一个独立的请求
- 您不需要对话历史
- 您希望保持代码简洁
消息提示(Message prompts) 或者,可以通过提供消息对象的列表,将多个消息传递给模型。
from langchain.messages import SystemMessage, HumanMessage, AIMessage
messages = [
SystemMessage("You are a poetry expert"),
HumanMessage("Write a haiku about spring"),
AIMessage("Cherry blossoms bloom...")
]
response = model.invoke(messages)
使用消息提示时的场景:
- 管理多轮对话
- 处理多模态内容(图片、音频、文件等)
- 包括系统指令
字典格式(Dictionary format) 也可以直接使用 OpenAI 聊天完成格式指定消息。
messages = [
{"role": "system", "content": "You are a poetry expert"},
{"role": "user", "content": "Write a haiku about spring"},
{"role": "assistant", "content": "Cherry blossoms bloom..."}
]
response = model.invoke(messages)
消息类型(Message types)
- 系统消息(System message) - 告诉模型如何行为并为交互提供上下文
- 用户消息(Human message) - 表示用户输入和与模型的交互
- AI 消息(AI message) - 模型生成的响应,包括文本内容、工具调用和元数据
- 工具消息(Tool message) - 表示工具调用的输出
SystemMessage 代表一组初始指令,旨在引导模型的行为。您可以使用系统消息来设置语气、定义模型的角色,并为响应设定指导原则。
基本指令:
system_msg = SystemMessage("You are a helpful coding assistant.")
messages = [
system_msg,
HumanMessage("How do I create a REST API?")
]
response = model.invoke(messages)
详细角色描述
from langchain.messages import SystemMessage, HumanMessage
system_msg = SystemMessage("""
You are a senior Python developer with expertise in web frameworks.
Always provide code examples and explain your reasoning.
Be concise but thorough in your explanations.
""")
messages = [
system_msg,
HumanMessage("How do I create a REST API?")
]
response = model.invoke(messages)
HumanMessage 代表用户的输入和交互。它们可以包含文本、图片、音频、文件以及任何其他形式的多模态内容。
文本内容:
response = model.invoke([
HumanMessage("What is machine learning?")
])
可以为消息添加元数据:
human_msg = HumanMessage(
content="Hello!",
name="alice", # 可选:标识不同的用户
id="msg_123", # 可选:唯一标识符,用于追踪
)
name 字段的行为取决于提供商 - 有些用它来标识用户,而有些则忽略它。具体行为请参见模型提供商的参考文档。
AIMessage 代表模型调用的输出。它们可以包含多模态数据、工具调用和提供商特定的元数据,您可以稍后访问这些数据。
response = model.invoke("Explain AI")
print(type(response)) # <class 'langchain_core.messages.ai.AIMessage'>
AIMessage 对象由模型返回,当调用模型时,它包含响应中的所有相关元数据。
不同的提供商对消息类型的权重和上下文化处理有所不同,这意味着有时手动创建一个新的 AIMessage 对象并将其插入到消息历史中,就好像它是从模型生成的一样,这会很有帮助。
from langchain.messages import AIMessage, SystemMessage, HumanMessage
# 手动创建一个 AI 消息(例如,作为对话历史的一部分)
ai_msg = AIMessage("I'd be happy to help you with that question!")
# 添加到对话历史
messages = [
SystemMessage("You are a helpful assistant"),
HumanMessage("Can you help me?"),
ai_msg, # 插入到历史记录中,假设它来自模型
HumanMessage("Great! What's 2+2?")
]
response = model.invoke(messages)
属性(Attributes)
- text:字符串类型,表示消息的文本内容。
- content:字符串或字典数组,表示消息的原始内容。
- content_blocks:
ContentBlock[],消息的标准化内容块。 - tool_calls:字典数组或 None,表示模型做出的工具调用。如果没有工具调用,则为空。
- id:字符串类型,消息的唯一标识符(由 LangChain 自动生成或在提供商响应中返回)。
- usage_metadata:字典或 None,消息的使用元数据,可能包含令牌计数(如果可用)。
- response_metadata:
ResponseMetadata或 None,消息的响应元数据。
当模型进行工具调用时,它们会包含在 AIMessage 中:
from langchain.chat_models import init_chat_model
model = init_chat_model("gpt-5-nano")
def get_weather(location: str) -> str:
"""获取某个地点的天气。"""
...
model_with_tools = model.bind_tools([get_weather])
response = model_with_tools.invoke("What's the weather in Paris?")
for tool_call in response.tool_calls:
print(f"Tool: {tool_call['name']}")
print(f"Args: {tool_call['args']}")
print(f"ID: {tool_call['id']}")
其他结构化数据,如推理过程或引用,也可以出现在消息内容中。
AIMessage 可以在其 usage_metadata 字段中保存令牌计数和其他使用元数据:
from langchain.chat_models import init_chat_model
model = init_chat_model("gpt-5-nano")
response = model.invoke("Hello!")
response.usage_metadata
返回结果:
{'input_tokens': 8,
'output_tokens': 304,
'total_tokens': 312,
'input_token_details': {'audio': 0, 'cache_read': 0},
'output_token_details': {'audio': 0, 'reasoning': 256}}
在流式传输过程中,您将接收到 AIMessageChunk 对象,这些对象可以组合成完整的消息对象:
chunks = []
full_message = None
for chunk in model.stream("Hi"):
chunks.append(chunk)
print(chunk.text)
full_message = chunk if full_message is None else full_message + chunk
对于支持工具调用的模型,AI 消息可以包含工具调用。工具消息用于将单个工具执行的结果传递回模型。
工具可以直接生成 ToolMessage 对象。下面是一个简单的示例。更多内容请参见工具指南。
# 在模型进行工具调用后
ai_message = AIMessage(
content=[],
tool_calls=[{
"name": "get_weather",
"args": {"location": "San Francisco"},
"id": "call_123"
}]
)
# 执行工具并创建结果消息
weather_result = "Sunny, 72°F"
tool_message = ToolMessage(
content=weather_result,
tool_call_id="call_123" # 必须与工具调用的 ID 匹配
)
# 继续对话
messages = [
HumanMessage("What's the weather in San Francisco?"),
ai_message, # 模型的工具调用
tool_message, # 工具执行结果
]
response = model.invoke(messages) # 模型处理结果
属性(Attributes)
-
content
类型:字符串(必需)
工具调用的字符串化输出。 -
tool_call_id
类型:字符串(必需)
该消息响应的工具调用 ID。(必须与AIMessage中的工具调用 ID 匹配) -
name
类型:字符串(必需)
被调用的工具名称。 -
artifact
类型:字典(可选)
额外的数据,虽然不会发送到模型,但可以通过编程访问。
artifact字段用于存储附加数据,这些数据不会被发送到模型,但可以通过编程访问。这对于存储原始结果、调试信息或下游处理的数据很有用,而不会干扰模型的上下文。
示例:使用 artifact 存储检索元数据
例如,检索工具可以从文档中检索一段内容,以供模型参考。消息内容中包含模型将引用的文本,而 artifact 可以包含文档标识符或其他元数据,供应用程序使用(例如,用于渲染页面)。下面是一个示例:
from langchain.messages import ToolMessage
# 发送给模型的内容
message_content = "It was the best of times, it was the worst of times."
# 可供下游使用的 artifact
artifact = {"document_id": "doc_123", "page": 0}
tool_message = ToolMessage(
content=message_content,
tool_call_id="call_123",
name="search_books",
artifact=artifact,
)
消息内容
你可以把消息的内容看作是发送给模型的数据负载。消息有一个 content 属性,它是松散类型的,支持字符串和无类型对象的列表(例如字典)。这使得 LangChain 聊天模型能够直接支持提供商本地结构,例如多模态内容和其他数据。
另外,LangChain 为文本、推理、引用、多模态数据、服务器端工具调用和其他消息内容提供了专门的内容类型。
LangChain 聊天模型接受 content 属性中的消息内容,可以包含:
- 一个字符串
- 一个提供商本地格式的内容块列表
- 一个 LangChain 标准内容块列表
下面是使用多模态输入的示例:
from langchain.messages import HumanMessage
# 字符串内容
human_message = HumanMessage("Hello, how are you?")
# 提供商本地格式(例如 OpenAI)
human_message = HumanMessage(content=[
{"type": "text", "text": "Hello, how are you?"},
{"type": "image_url", "image_url": {"url": "https://example.com/image.jpg"}}
])
# 标准内容块列表
human_message = HumanMessage(content_blocks=[
{"type": "text", "text": "Hello, how are you?"},
{"type": "image", "url": "https://example.com/image.jpg"},
])
在初始化消息时指定 content_blocks 仍然会填充消息内容,但提供了一个类型安全的接口来实现这一点。
标准内容块
LangChain 提供了一个标准的消息内容表示,适用于所有提供商。
消息对象实现了一个 content_blocks 属性,它会懒加载地将 content 属性解析成标准的、类型安全的表示。例如,来自 ChatAnthropic 或 ChatOpenAI 生成的消息将包含各自提供商格式的思考或推理块,但可以懒加载成一致的 ReasoningContentBlock 表示:
from langchain.messages import AIMessage
message = AIMessage(
content=[
{
"type": "reasoning",
"id": "rs_abc123",
"summary": [
{"type": "summary_text", "text": "summary 1"},
{"type": "summary_text", "text": "summary 2"},
],
},
{"type": "text", "text": "...", "id": "msg_abc123"},
],
response_metadata={"model_provider": "openai"}
)
message.content_blocks
输出:
[
{'type': 'reasoning', 'id': 'rs_abc123', 'reasoning': 'summary 1'},
{'type': 'reasoning', 'id': 'rs_abc123', 'reasoning': 'summary 2'},
{'type': 'text', 'text': '...', 'id': 'msg_abc123'}
]
如果 LangChain 之外的应用程序需要访问标准的内容块表示,你可以选择将内容块存储在消息内容中。
为此,你可以将 LC_OUTPUT_VERSION 环境变量设置为 v1,或者初始化任何聊天模型时使用 output_version="v1":
from langchain.chat_models import init_chat_model
model = init_chat_model("gpt-5-nano", output_version="v1")
多模态
多模态性指的是处理不同形式的数据的能力,如文本、音频、图像和视频。LangChain 包括了这些数据的标准类型,可以跨提供商使用。
聊天模型可以接受多模态数据作为输入,并生成多模态数据作为输出。下面我们展示了一些包含多模态数据的输入消息的简短示例。
额外的键值可以包含在内容块的顶层,或者嵌套在 extras 中:{"key": value}。例如,OpenAI 和 AWS Bedrock Converse 要求 PDF 文件提供文件名。请查看所选模型的提供商页面以获取具体信息。
# 从 URL
message = {
"role": "user",
"content": [
{"type": "text", "text": "Describe the content of this image."},
{"type": "image", "url": "https://example.com/path/to/image.jpg"},
]
}
# 从 base64 数据
message = {
"role": "user",
"content": [
{"type": "text", "text": "Describe the content of this image."},
{
"type": "image",
"base64": "AAAAIGZ0eXBtcDQyAAAAAGlzb21tcDQyAAACAGlzb2...",
"mime_type": "image/jpeg",
},
]
}
# 从提供商管理的文件 ID
message = {
"role": "user",
"content": [
{"type": "text", "text": "Describe the content of this image."},
{"type": "image", "file_id": "file-abc123"},
]
}
并非所有模型都支持所有文件类型。请查看模型提供商的参考文档,了解支持的格式和大小限制。
内容块参考
内容块(Content blocks)可以在创建消息或访问 content_blocks 属性时表示为类型化字典的列表。列表中的每一项必须符合以下块类型之一:
TextContentBlock
用途:标准文本输出
| 属性 | 类型 | 说明 |
|---|---|---|
| type | string | 必填,始终为 "text" |
| text | string | 必填,文本内容 |
| annotations | object[] | 文本注释列表 |
| extras | object | 额外的提供商特定数据 |
示例:
{
"type": "text",
"text": "Hello world",
"annotations": []
}
ReasoningContentBlock
用途:模型推理步骤
| 属性 | 类型 | 说明 |
|---|---|---|
| type | string | 必填,始终为 "reasoning" |
| reasoning | string | 推理内容 |
| extras | object | 提供商特定的额外数据 |
示例:
{
"type": "reasoning",
"reasoning": "The user is asking about...",
"extras": {"signature": "abc123"}
}
ImageContentBlock
用途:图像数据
| 属性 | 类型 | 说明 |
|---|---|---|
| type | string | 必填,始终为 "image" |
| url | string | 图像 URL |
| base64 | string | Base64 编码图像数据 |
| id | string | 外部存储图像的引用 ID |
| mime_type | string | 图像 MIME 类型(如 image/jpeg) |
AudioContentBlock
用途:音频数据
| 属性 | 类型 | 说明 |
|---|---|---|
| type | string | 必填,始终为 "audio" |
| url | string | 音频 URL |
| base64 | string | Base64 编码音频数据 |
| id | string | 外部存储音频文件的引用 ID |
| mime_type | string | 音频 MIME 类型(如 audio/mpeg) |
VideoContentBlock
用途:视频数据
| 属性 | 类型 | 说明 |
|---|---|---|
| type | string | 必填,始终为 "video" |
| url | string | 视频 URL |
| base64 | string | Base64 编码视频数据 |
| id | string | 外部存储视频文件的引用 ID |
| mime_type | string | 视频 MIME 类型(如 video/mp4) |
FileContentBlock
用途:通用文件(PDF 等)
| 属性 | 类型 | 说明 |
|---|---|---|
| type | string | 必填,始终为 "file" |
| url | string | 文件 URL |
| base64 | string | Base64 编码文件数据 |
| id | string | 外部存储文件的引用 ID |
| mime_type | string | 文件 MIME 类型(如 application/pdf) |
PlainTextContentBlock
用途:文本文档(.txt、.md)
| 属性 | 类型 | 说明 |
|---|---|---|
| type | string | 必填,始终为 "text-plain" |
| text | string | 文本内容 |
| mime_type | string | 文本 MIME 类型(如 text/plain) |
ToolCall
用途:函数调用
| 属性 | 类型 | 说明 |
|---|---|---|
| type | string | 必填,始终为 "tool_call" |
| name | string | 必填,工具名称 |
| args | object | 必填,传递给工具的参数 |
| id | string | 必填,工具调用的唯一标识 |
示例:
{
"type": "tool_call",
"name": "search",
"args": {"query": "weather"},
"id": "call_123"
}
ToolCallChunk
用途:流式工具调用片段
| 属性 | 类型 | 说明 | |
|---|---|---|---|
| type | string | 必填,始终为 "tool_call_chunk" | |
| name | string | 工具名称 | |
| args | string | 部分工具参数(可能是未完成的 JSON) | |
| id | string | 工具调用标识 | |
| index | number | string | 流中的片段位置 |
InvalidToolCall
用途:格式错误的调用(用于捕获 JSON 解析错误)
| 属性 | 类型 | 说明 |
|---|---|---|
| type | string | 必填,始终为 "invalid_tool_call" |
| name | string | 调用失败的工具名称 |
| args | object | 传递给工具的参数 |
| error | string | 错误描述 |
ServerToolCall
用途:服务器端执行的工具调用
| 属性 | 类型 | 说明 |
|---|---|---|
| type | string | 必填,始终为 "server_tool_call" |
| id | string | 工具调用标识 |
| name | string | 工具名称 |
| args | string | 部分工具参数(可能是未完成的 JSON) |
ServerToolCallChunk
用途:流式服务器端工具调用片段
| 属性 | 类型 | 说明 | |
|---|---|---|---|
| type | string | 必填,始终为 "server_tool_call_chunk" | |
| id | string | 工具调用标识 | |
| name | string | 工具名称 | |
| args | string | 部分工具参数(可能是未完成的 JSON) | |
| index | number | string | 流中的片段位置 |
ServerToolResult
用途:工具执行结果
| 属性 | 类型 | 说明 |
|---|---|---|
| type | string | 必填,始终为 "server_tool_result" |
| tool_call_id | string | 对应的服务器端工具调用标识 |
| id | string | 服务器工具结果标识 |
| status | string | 执行状态 "success" 或 "error" |
| output | any | 执行输出 |
NonStandardContentBlock
用途:提供商特定的逃生通道
| 属性 | 类型 | 说明 |
|---|---|---|
| type | string | 必填,始终为 "non_standard" |
| value | object | 必填,提供商特定的数据结构 |
用途:用于实验性或提供商独有的功能。
内容块在 LangChain v1 中作为消息的新属性引入,用于在不同提供商间标准化内容格式,同时保持与现有代码的向后兼容性。内容块并不是替代 content 属性,而是提供了一个可以标准化访问消息内容的新接口。
工具
许多 AI 应用通过自然语言与用户交互。然而,一些用例需要模型直接与外部系统(如 API、数据库或文件系统)交互,并使用结构化输入。
工具是代理调用以执行操作的组件。它们通过定义良好的输入和输出扩展模型的能力,让模型能够与外部世界互动。工具封装了可调用函数及其输入模式,这些工具可以传递给兼容的聊天模型,让模型决定是否调用该工具以及使用哪些参数。在这些场景中,工具调用使模型能够生成符合指定输入模式的请求。
一些聊天模型(如 OpenAI、Anthropic 和 Gemini)具有内置工具,这些工具在服务器端执行,例如网页搜索和代码解释器。
创建工具最简单的方法是使用 @tool 装饰器。默认情况下,函数的 docstring 会成为工具的描述,帮助模型理解何时使用它:
from langchain.tools import tool
@tool
def search_database(query: str, limit: int = 10) -> str:
"""Search the customer database for records matching the query.
Args:
query: Search terms to look for
limit: Maximum number of results to return
"""
return f"Found {limit} results for '{query}'"
类型提示是必需的,因为它们定义了工具的输入模式。docstring 应该简明而信息丰富,以帮助模型理解工具的用途。
自定义工具名称
默认情况下,工具名称来自函数名称。如果需要更具描述性的名称,可以覆盖它:
@tool("web_search") # 自定义名称
def search(query: str) -> str:
"""Search the web for information."""
return f"Results for: {query}"
print(search.name) # web_search
自定义工具描述
可以覆盖自动生成的工具描述,为模型提供更清晰的指导:
@tool("calculator", description="Performs arithmetic calculations. Use this for any math problems.")
def calc(expression: str) -> str:
"""Evaluate mathematical expressions."""
return str(eval(expression))
高级输入模式定义
可以使用 Pydantic 模型或 JSON Schema 定义复杂的输入:
Pydantic 模型示例
from pydantic import BaseModel, Field
from typing import Literal
class WeatherInput(BaseModel):
"""Input for weather queries."""
location: str = Field(description="City name or coordinates")
units: Literal["celsius", "fahrenheit"] = Field(
default="celsius",
description="Temperature unit preference"
)
include_forecast: bool = Field(
default=False,
description="Include 5-day forecast"
)
@tool(args_schema=WeatherInput)
def get_weather(location: str, units: str = "celsius", include_forecast: bool = False) -> str:
"""Get current weather and optional forecast."""
temp = 22 if units == "celsius" else 72
result = f"Current weather in {location}: {temp} degrees {units[0].upper()}"
if include_forecast:
result += "\nNext 5 days: Sunny"
return result
这样定义工具可以让模型通过结构化参数调用,并生成符合输入模式的请求。
访问上下文
当工具能够访问代理状态、运行时上下文和长期记忆时,它们的能力最强。这使工具能够做出上下文感知的决策、个性化响应,并在对话中保持信息。
运行时上下文提供了一种方法,可以在运行时将依赖项(如数据库连接、用户 ID 或配置)注入工具,使工具更易于测试和复用。
工具可以通过 ToolRuntime 参数访问运行时信息,它提供以下功能:
- State(状态):可变数据,在执行过程中流动(例如消息、计数器、自定义字段)
- Context(上下文):不可变配置,如用户 ID、会话信息或应用特定配置
- Store(存储):跨对话的持久化长期记忆
- Stream Writer(流写入器):在工具执行时流式发送自定义更新
- Config(配置):用于执行的
RunnableConfig - Tool Call ID(工具调用 ID):当前工具调用的 ID
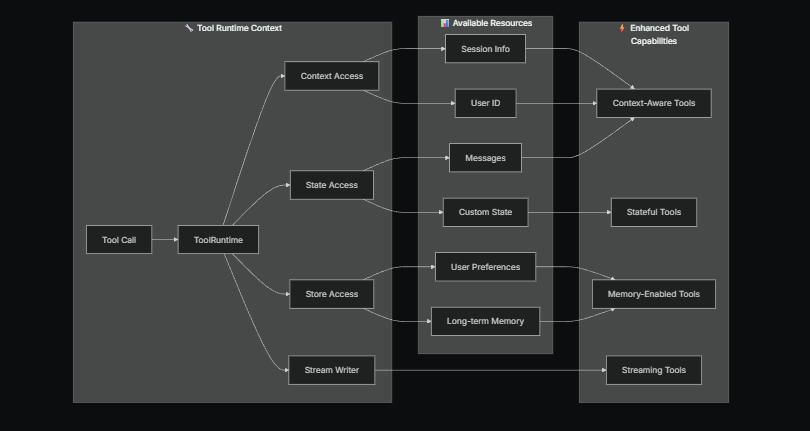
ToolRuntime 用于在单个参数中访问所有运行时信息。只需在工具签名中添加 runtime: ToolRuntime,它将自动注入,不会暴露给 LLM。
ToolRuntime:统一参数,为工具提供对状态、上下文、存储、流、配置和工具调用 ID 的访问。这取代了以前需要分别使用 InjectedState、InjectedStore、get_runtime 和 InjectedToolCallId 的模式。
运行时会自动将这些能力提供给工具函数,无需显式传递或使用全局状态。
访问状态示例
工具可以通过 ToolRuntime 访问当前图状态:
from langchain.tools import tool, ToolRuntime
# 访问当前对话状态
@tool
def summarize_conversation(
runtime: ToolRuntime
) -> str:
"""Summarize the conversation so far."""
messages = runtime.state["messages"]
human_msgs = sum(1 for m in messages if m.__class__.__name__ == "HumanMessage")
ai_msgs = sum(1 for m in messages if m.__class__.__name__ == "AIMessage")
tool_msgs = sum(1 for m in messages if m.__class__.__name__ == "ToolMessage")
return f"Conversation has {human_msgs} user messages, {ai_msgs} AI responses, and {tool_msgs} tool results"
访问自定义状态字段:
@tool
def get_user_preference(
pref_name: str,
runtime: ToolRuntime # ToolRuntime 参数不会暴露给模型
) -> str:
"""Get a user preference value."""
preferences = runtime.state.get("user_preferences", {})
return preferences.get(pref_name, "Not set")
tool_runtime 参数对模型是隐藏的。在上例中,模型在工具模式中只看到 pref_name,tool_runtime 不会包含在请求中。
更新状态:
使用 Command 来更新代理的状态或控制图的执行流程:
from langgraph.types import Command
from langchain.messages import RemoveMessage
from langgraph.graph.message import REMOVE_ALL_MESSAGES
from langchain.tools import tool, ToolRuntime
# 通过删除所有消息来更新对话历史
@tool
def clear_conversation() -> Command:
"""清除对话历史。"""
return Command(
update={
"messages": [RemoveMessage(id=REMOVE_ALL_MESSAGES)],
}
)
# 更新代理状态中的 user_name
@tool
def update_user_name(
new_name: str,
runtime: ToolRuntime
) -> Command:
"""更新用户的名字。"""
return Command(update={"user_name": new_name})
通过使用 Command,你可以精确控制状态更新,能够方便地更新消息或状态中的某些字段。
上下文
通过 runtime.context 访问不可变配置和上下文数据,如用户ID、会话详情或特定应用的配置。
工具可以通过 ToolRuntime 访问运行时上下文:
from dataclasses import dataclass
from langchain_openai import ChatOpenAI
from langchain.agents import create_agent
from langchain.tools import tool, ToolRuntime
USER_DATABASE = {
"user123": {
"name": "Alice Johnson",
"account_type": "Premium",
"balance": 5000,
"email": "alice@example.com"
},
"user456": {
"name": "Bob Smith",
"account_type": "Standard",
"balance": 1200,
"email": "bob@example.com"
}
}
@dataclass
class UserContext:
user_id: str
@tool
def get_account_info(runtime: ToolRuntime[UserContext]) -> str:
"""获取当前用户的账户信息。"""
user_id = runtime.context.user_id
if user_id in USER_DATABASE:
user = USER_DATABASE[user_id]
return f"账户持有人: {user['name']}\n账户类型: {user['account_type']}\n余额: ${user['balance']}"
return "未找到用户"
model = ChatOpenAI(model="gpt-4o")
agent = create_agent(
model,
tools=[get_account_info],
context_schema=UserContext,
system_prompt="你是一个财务助手。"
)
result = agent.invoke(
{"messages": [{"role": "user", "content": "我的当前余额是多少?"}]},
context=UserContext(user_id="user123")
)
记忆(存储)
通过 store 访问会话间的持久数据。store 通过 runtime.store 访问,允许你保存和检索用户特定或应用特定的数据。
工具可以通过 ToolRuntime 访问和更新存储:
from typing import Any
from langgraph.store.memory import InMemoryStore
from langchain.agents import create_agent
from langchain.tools import tool, ToolRuntime
# 访问记忆
@tool
def get_user_info(user_id: str, runtime: ToolRuntime) -> str:
"""查找用户信息。"""
store = runtime.store
user_info = store.get(("users",), user_id)
return str(user_info.value) if user_info else "未知用户"
# 更新记忆
@tool
def save_user_info(user_id: str, user_info: dict[str, Any], runtime: ToolRuntime) -> str:
"""保存用户信息。"""
store = runtime.store
store.put(("users",), user_id, user_info)
return "成功保存用户信息。"
store = InMemoryStore()
agent = create_agent(
model,
tools=[get_user_info, save_user_info],
store=store
)
# 第一次会话:保存用户信息
agent.invoke({
"messages": [{"role": "user", "content": "保存以下用户信息:userid: abc123, name: Foo, age: 25, email: foo@langchain.dev"}]
})
# 第二次会话:获取用户信息
agent.invoke({
"messages": [{"role": "user", "content": "获取ID为'abc123'的用户信息"}]
})
# 获取ID为 "abc123" 的用户信息:
# - 姓名: Foo
# - 年龄: 25
# - 邮箱: foo@langchain.dev
这样,你可以在会话之间保存并恢复特定的用户信息,提供更有个性化的互动体验。
流写入器 (Stream Writer)
使用 runtime.stream_writer 从工具执行过程中流式传输自定义更新。这对于向用户提供实时反馈非常有用,能够显示工具当前正在执行的操作。
from langchain.tools import tool, ToolRuntime
@tool
def get_weather(city: str, runtime: ToolRuntime) -> str:
"""获取指定城市的天气。"""
writer = runtime.stream_writer
# 在工具执行时流式传输自定义更新
writer(f"正在查询城市 {city} 的数据")
writer(f"已获取 {city} 的数据")
return f"{city} 总是阳光明媚!"
如果在你的工具中使用了 runtime.stream_writer,则该工具必须在 LangGraph 执行上下文中调用。
短期记忆
记忆是一个系统,它能记住先前交互的信息。对于 AI 代理来说,记忆至关重要,因为它让代理能够记住之前的交互,学习反馈,并适应用户偏好。随着代理处理更复杂的任务和更多的用户交互,这种能力对于效率和用户满意度变得越来越重要。
短期记忆使得你的应用能够记住单个线程或会话中的先前交互。
一个线程组织了一个会话中的多个交互,类似于电子邮件将消息分组为一个单一的对话。
会话历史是短期记忆最常见的形式。长时间的对话对今天的语言模型(LLMs)提出了挑战;完整的历史可能无法放入 LLM 的上下文窗口中,从而导致上下文丢失或错误。
即使模型支持完整的上下文长度,许多 LLM 在长上下文中表现仍然很差。它们容易被过时或不相关的内容分心,同时响应时间变慢,成本增加。
聊天模型通过消息接收上下文,消息包括指令(系统消息)和输入(人类消息)。在聊天应用中,消息在人的输入和模型响应之间交替,从而形成一个随着时间推移而不断增长的消息列表。由于上下文窗口是有限的,许多应用可以通过使用技术来移除或“忘记”过时的信息来受益。
使用方式
要为代理添加短期记忆(线程级持久性),你需要在创建代理时指定一个检查点(checkpointer)。
LangChain 的代理将短期记忆作为代理状态的一部分进行管理。通过将这些信息存储在图的状态中,代理可以访问给定会话的完整上下文,同时保持不同线程之间的隔离。
状态通过检查点持久化到数据库(或内存)中,因此线程可以随时恢复。
短期记忆在每次代理调用或完成一个步骤(如工具调用)时更新,并且在每次步骤开始时读取状态。
from langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaver
agent = create_agent(
"gpt-5",
[get_user_info],
checkpointer=InMemorySaver(), # 使用内存保存器进行短期记忆持久化
)
agent.invoke(
{"messages": [{"role": "user", "content": "Hi! My name is Bob."}]},
{"configurable": {"thread_id": "1"}}, # 为线程指定唯一 ID
)
在生产环境中,使用由数据库支持的检查点:
pip install langgraph-checkpoint-postgres
from langchain.agents import create_agent
from langgraph.checkpoint.postgres import PostgresSaver
DB_URI = "postgresql://postgres:postgres@localhost:5442/postgres?sslmode=disable"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
checkpointer.setup() # 自动在 PostgreSQL 中创建表
agent = create_agent(
"gpt-5",
[get_user_info],
checkpointer=checkpointer, # 使用数据库检查点进行短期记忆持久化
)
默认情况下,代理使用 AgentState 来管理短期记忆,特别是通过 messages 键管理会话历史。你可以扩展 AgentState 来添加额外的字段。自定义的状态模式通过 state_schema 参数传递给 create_agent 方法。
from langchain.agents import create_agent, AgentState
from langgraph.checkpoint.memory import InMemorySaver
class CustomAgentState(AgentState):
user_id: str
preferences: dict
agent = create_agent(
"gpt-5",
[get_user_info],
state_schema=CustomAgentState, # 使用自定义状态模式
checkpointer=InMemorySaver(),
)
# 可以在调用时传递自定义状态
result = agent.invoke(
{
"messages": [{"role": "user", "content": "Hello"}],
"user_id": "user_123",
"preferences": {"theme": "dark"}
},
{"configurable": {"thread_id": "1"}}
)
超上下文窗口解决方案
启用短期记忆后,长时间的对话可能会超过 LLM 的上下文窗口。常见的解决方案包括:
- 修剪消息:删除前 N 条或后 N 条消息(在调用 LLM 之前)
- 删除消息:从 LangGraph 状态中永久删除消息
- 总结消息:将历史中的较早消息总结并用总结替换
- 自定义策略:例如消息过滤等
这些策略允许代理在不超过 LLM 上下文窗口的情况下跟踪对话。
修剪消息
大多数 LLM 都有一个最大支持的上下文窗口(以 tokens 为单位)。
决定何时修剪消息的一种方法是计算消息历史中的 tokens 数量,当接近该限制时进行修剪。如果你使用 LangChain,可以使用修剪消息的实用程序,指定要保留的 tokens 数量以及处理边界的策略(例如,保留最后的 max_tokens)。
要在代理中修剪消息历史,请使用 @before_model 中间件装饰器:
from langchain.messages import RemoveMessage
from langgraph.graph.message import REMOVE_ALL_MESSAGES
from langgraph.checkpoint.memory import InMemorySaver
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import before_model
from langgraph.runtime import Runtime
from langchain_core.runnables import RunnableConfig
from typing import Any
@before_model
def trim_messages(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
"""只保留最后几条消息,以适应上下文窗口。"""
messages = state["messages"]
if len(messages) <= 3:
return None # 不需要更改
first_msg = messages[0]
recent_messages = messages[-3:] if len(messages) % 2 == 0 else messages[-4:]
new_messages = [first_msg] + recent_messages
return {
"messages": [
RemoveMessage(id=REMOVE_ALL_MESSAGES),
*new_messages
]
}
agent = create_agent(
model,
tools=tools,
middleware=[trim_messages],
checkpointer=InMemorySaver(),
)
config: RunnableConfig = {"configurable": {"thread_id": "1"}}
agent.invoke({"messages": "hi, my name is bob"}, config)
agent.invoke({"messages": "write a short poem about cats"}, config)
agent.invoke({"messages": "now do the same but for dogs"}, config)
final_response = agent.invoke({"messages": "what's my name?"}, config)
final_response["messages"][-1].pretty_print()
删除消息
你可以从图形状态中删除消息以管理消息历史。这对于删除特定消息或清空整个消息历史非常有用。
要从图形状态中删除消息,你可以使用 RemoveMessage。为了使 RemoveMessage 生效,你需要使用 add_messages reducer 和一个状态键。默认的 AgentState 提供了这一功能。
删除特定消息:
from langchain.messages import RemoveMessage
def delete_messages(state):
messages = state["messages"]
if len(messages) > 2:
# 删除最早的两条消息
return {"messages": [RemoveMessage(id=m.id) for m in messages[:2]]}
删除所有消息:
from langgraph.graph.message import REMOVE_ALL_MESSAGES
def delete_messages(state):
return {"messages": [RemoveMessage(id=REMOVE_ALL_MESSAGES)]}
删除消息时,请确保结果消息历史是有效的。检查你使用的 LLM 提供商的限制。例如:
- 一些提供商期望消息历史从用户消息开始
- 大多数提供商要求带有工具调用的助手消息后跟相应的工具结果消息
使用 after_model 中间件装饰器删除旧消息:
from langchain.messages import RemoveMessage
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import after_model
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.runtime import Runtime
from langchain_core.runnables import RunnableConfig
@after_model
def delete_old_messages(state: AgentState, runtime: Runtime) -> dict | None:
"""移除旧消息以保持对话简洁。"""
messages = state["messages"]
if len(messages) > 2:
# 删除最早的两条消息
return {"messages": [RemoveMessage(id=m.id) for m in messages[:2]]}
return None
agent = create_agent(
"gpt-5-nano",
tools=[],
system_prompt="Please be concise and to the point.",
middleware=[delete_old_messages],
checkpointer=InMemorySaver(),
)
config: RunnableConfig = {"configurable": {"thread_id": "1"}}
for event in agent.stream(
{"messages": [{"role": "user", "content": "hi! I'm bob"}]},
config,
stream_mode="values",
):
print([(message.type, message.content) for message in event["messages"]])
for event in agent.stream(
{"messages": [{"role": "user", "content": "what's my name?"}]},
config,
stream_mode="values",
):
print([(message.type, message.content) for message in event["messages"]])
总结消息
如上所示,修剪或删除消息的问题在于,可能会丢失从消息队列中裁剪的信息。因此,一些应用程序从使用聊天模型对消息历史进行总结的更复杂方法中受益。
要在代理中总结消息历史,可以使用内置的 SummarizationMiddleware:
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
from langgraph.checkpoint.memory import InMemorySaver
from langchain_core.runnables import RunnableConfig
checkpointer = InMemorySaver()
agent = create_agent(
model="gpt-4o",
tools=[],
middleware=[
SummarizationMiddleware(
model="gpt-4o-mini",
max_tokens_before_summary=4000, # 当消息达到4000个tokens时触发总结
messages_to_keep=20, # 总结后保留最后20条消息
)
],
checkpointer=checkpointer,
)
config: RunnableConfig = {"configurable": {"thread_id": "1"}}
agent.invoke({"messages": "hi, my name is bob"}, config)
agent.invoke({"messages": "write a short poem about cats"}, config)
agent.invoke({"messages": "now do the same but for dogs"}, config)
final_response = agent.invoke({"messages": "what's my name?"}, config)
final_response["messages"][-1].pretty_print()
"""
================================== Ai Message ==================================
Your name is Bob!
"""
访问Memory
您可以通过多种方式访问和修改代理的短期记忆(状态):
通过工具访问Memory
通过 ToolRuntime 参数在工具中访问短期记忆(状态)。tool_runtime 参数对工具签名是隐藏的(所以模型看不到它),但是工具可以通过它访问状态。
from langchain.agents import create_agent, AgentState
from langchain.tools import tool, ToolRuntime
class CustomState(AgentState):
user_id: str
@tool
def get_user_info(
runtime: ToolRuntime
) -> str:
"""查找用户信息。"""
user_id = runtime.state["user_id"]
return "用户是 John Smith" if user_id == "user_123" else "未知用户"
agent = create_agent(
model="gpt-5-nano",
tools=[get_user_info],
state_schema=CustomState,
)
result = agent.invoke({
"messages": "查找用户信息",
"user_id": "user_123"
})
print(result["messages"][-1].content)
# 输出:用户是 John Smith。
要在执行期间修改代理的短期记忆(状态),可以直接从工具返回状态更新。这对于保存中间结果或使信息对后续工具或提示可访问非常有用。
from langchain.tools import tool, ToolRuntime
from langchain_core.runnables import RunnableConfig
from langchain.messages import ToolMessage
from langchain.agents import create_agent, AgentState
from langgraph.types import Command
from pydantic import BaseModel
class CustomState(AgentState):
user_name: str
class CustomContext(BaseModel):
user_id: str
@tool
def update_user_info(
runtime: ToolRuntime[CustomContext, CustomState],
) -> Command:
"""查找并更新用户信息。"""
user_id = runtime.context.user_id
name = "John Smith" if user_id == "user_123" else "未知用户"
return Command(update={
"user_name": name,
# 更新消息历史
"messages": [
ToolMessage(
"成功查找用户信息",
tool_call_id=runtime.tool_call_id
)
]
})
@tool
def greet(
runtime: ToolRuntime[CustomContext, CustomState]
) -> str:
"""一旦找到用户信息,就用它来问候用户。"""
user_name = runtime.state["user_name"]
return f"你好 {user_name}!"
agent = create_agent(
model="gpt-5-nano",
tools=[update_user_info, greet],
state_schema=CustomState,
context_schema=CustomContext,
)
agent.invoke(
{"messages": [{"role": "user", "content": "问候用户"}]},
context=CustomContext(user_id="user_123"),
)
通过Prompt
可以在中间件中访问短期记忆(状态),以基于对话历史或自定义状态字段创建动态提示。
from langchain.agents import create_agent
from typing import TypedDict
from langchain.agents.middleware import dynamic_prompt, ModelRequest
class CustomContext(TypedDict):
user_name: str
def get_weather(city: str) -> str:
"""获取城市天气。"""
return f"{city} 的天气总是晴朗!"
@dynamic_prompt
def dynamic_system_prompt(request: ModelRequest) -> str:
user_name = request.runtime.context["user_name"]
system_prompt = f"你是一个乐于助人的助手。称呼用户为 {user_name}。"
return system_prompt
agent = create_agent(
model="gpt-5-nano",
tools=[get_weather],
middleware=[dynamic_system_prompt],
context_schema=CustomContext,
)
result = agent.invoke(
{"messages": [{"role": "user", "content": "旧金山的天气怎么样?"}]},
context=CustomContext(user_name="John Smith"),
)
for msg in result["messages"]:
msg.pretty_print()
输出示例
================================ Human Message =================================
旧金山的天气怎么样?
================================== Ai Message ==================================
Tool Calls:
get_weather (call_WFQlOGn4b2yoJrv7cih342FG)
Call ID: call_WFQlOGn4b2yoJrv7cih342FG
Args:
city: San Francisco
================================= Tool Message =================================
Name: get_weather
San Francisco 的天气总是晴朗!
================================== Ai Message ==================================
你好 John Smith,旧金山的天气总是晴朗!
模型调用前(Before model)
可以在 @before_model 中间件中访问短期记忆(状态),用于在模型调用之前处理消息。
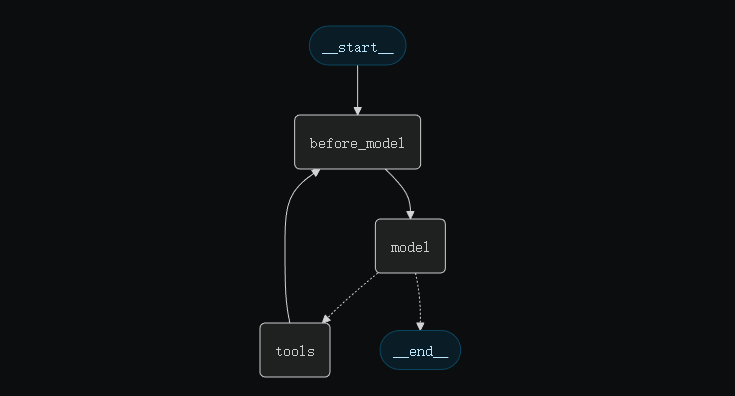
示例:
from langchain.messages import RemoveMessage
from langgraph.graph.message import REMOVE_ALL_MESSAGES
from langgraph.checkpoint.memory import InMemorySaver
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import before_model
from langgraph.runtime import Runtime
from typing import Any
@before_model
def trim_messages(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
"""仅保留最近几条消息以适应上下文窗口。"""
messages = state["messages"]
if len(messages) <= 3:
return None # 无需修改
first_msg = messages[0]
recent_messages = messages[-3:] if len(messages) % 2 == 0 else messages[-4:]
new_messages = [first_msg] + recent_messages
return {
"messages": [
RemoveMessage(id=REMOVE_ALL_MESSAGES),
*new_messages
]
}
agent = create_agent(
model,
tools=tools,
middleware=[trim_messages]
)
config: RunnableConfig = {"configurable": {"thread_id": "1"}}
agent.invoke({"messages": "hi, my name is bob"}, config)
agent.invoke({"messages": "write a short poem about cats"}, config)
agent.invoke({"messages": "now do the same but for dogs"}, config)
final_response = agent.invoke({"messages": "what's my name?"}, config)
final_response["messages"][-1].pretty_print()
输出示例:
================================== Ai Message ==================================
Your name is Bob. You told me that earlier.
If you'd like me to call you a nickname or use a different name, just say the word.
模型调用后(After model)
可以在 @after_model 中间件中访问短期记忆(状态),用于在模型调用之后处理消息。
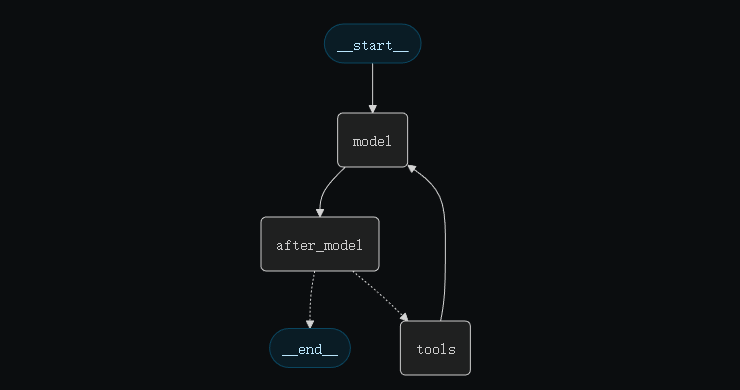
示例:
from langchain.messages import RemoveMessage
from langgraph.checkpoint.memory import InMemorySaver
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import after_model
from langgraph.runtime import Runtime
@after_model
def validate_response(state: AgentState, runtime: Runtime) -> dict | None:
"""删除包含敏感词的消息。"""
STOP_WORDS = ["password", "secret"]
last_message = state["messages"][-1]
if any(word in last_message.content for word in STOP_WORDS):
return {"messages": [RemoveMessage(id=last_message.id)]}
return None
agent = create_agent(
model="gpt-5-nano",
tools=[],
middleware=[validate_response],
checkpointer=InMemorySaver(),
)
这个示例展示了如何在模型调用前后处理消息,实现消息裁剪、敏感词过滤等功能。
流式处理
LangChain 实现了一个流式处理系统,用于实时更新。
流式处理对于增强基于 LLM(大语言模型)的应用程序的响应能力至关重要。通过逐步显示输出,即使在完整的响应还没有准备好之前,流式处理显著改善了用户体验(UX),特别是在处理 LLM 的延迟时。
使用 LangChain 流式处理,可以实现以下功能:
- 流式代理进度 — 在每个代理步骤后获取状态更新。
- 流式 LLM 标记 — 在语言模型生成时实时流式输出标记。
- 流式自定义更新 — 发出用户定义的信号(例如,“已获取 10/100 条记录”)。
- 流式多模式 — 从更新(代理进度)、消息(LLM 标记 + 元数据)或自定义(任意用户数据)中选择。
流式处理在大语言模型应用中极大地提升了交互性和响应速度,尤其适用于需要实时反馈的场景。
代理进度
要流式传输代理进度,使用 stream 或 astream 方法并设置 stream_mode="updates"。这会在每个代理步骤后发出一个事件。
例如,如果你有一个代理只调用一次工具,你应该会看到以下更新:
- LLM 节点:AIMessage 包含工具调用请求
- 工具节点:ToolMessage 包含执行结果
- LLM 节点:最终的 AI 响应
流式代理进度示例:
from langchain.agents import create_agent
def get_weather(city: str) -> str:
"""获取指定城市的天气信息"""
return f"It's always sunny in {city}!"
agent = create_agent(
model="gpt-5-nano",
tools=[get_weather],
)
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "What is the weather in SF?"}]},
stream_mode="updates",
):
for step, data in chunk.items():
print(f"step: {step}")
print(f"content: {data['messages'][-1].content_blocks}")
输出示例:
step: model
content: [{'type': 'tool_call', 'name': 'get_weather', 'args': {'city': 'San Francisco'}, 'id': 'call_OW2NYNsNSKhRZpjW0wm2Aszd'}]
step: tools
content: [{'type': 'text', 'text': "It's always sunny in San Francisco!"}]
step: model
content: [{'type': 'text', 'text': 'It's always sunny in San Francisco!'}]
LLM token
要流式传输 LLM 生成的token,使用 stream_mode="messages"。以下是流式工具调用和最终响应的输出示例。
from langchain.agents import create_agent
def get_weather(city: str) -> str:
"""获取指定城市的天气信息"""
return f"It's always sunny in {city}!"
agent = create_agent(
model="gpt-5-nano",
tools=[get_weather],
)
for token, metadata in agent.stream(
{"messages": [{"role": "user", "content": "What is the weather in SF?"}]},
stream_mode="messages",
):
print(f"node: {metadata['langgraph_node']}")
print(f"content: {token.content_blocks}")
print("\n")
输出示例:
node: model
content: [{'type': 'tool_call_chunk', 'id': 'call_vbCyBcP8VuneUzyYlSBZZsVa', 'name': 'get_weather', 'args': '', 'index': 0}]
node: model
content: [{'type': 'tool_call_chunk', 'id': None, 'name': None, 'args': '{"', 'index': 0}]
node: model
content: [{'type': 'tool_call_chunk', 'id': None, 'name': None, 'args': 'city', 'index': 0}]
node: model
content: [{'type': 'tool_call_chunk', 'id': None, 'name': None, 'args': '":"', 'index': 0}]
node: model
content: [{'type': 'tool_call_chunk', 'id': None, 'name': None, 'args': 'San', 'index': 0}]
node: model
content: [{'type': 'tool_call_chunk', 'id': None, 'name': None, 'args': ' Francisco', 'index': 0}]
node: model
content: [{'type': 'tool_call_chunk', 'id': None, 'name': None, 'args': '"}', 'index': 0}]
node: model
content: []
node: tools
content: [{'type': 'text', 'text': "It's always sunny in San Francisco!"}]
node: model
content: []
node: model
content: [{'type': 'text', 'text': 'Here'}]
node: model
content: [{'type': 'text', 'text': ''s'}]
node: model
content: [{'type': 'text', 'text': ' what'}]
node: model
content: [{'type': 'text', 'text': ' I'}]
node: model
content: [{'type': 'text', 'text': ' got'}]
node: model
content: [{'type': 'text', 'text': ':'}]
node: model
content: [{'type': 'text', 'text': ' "'}]
node: model
content: [{'type': 'text', 'text': "It's"}]
node: model
content: [{'type': 'text', 'text': ' always'}]
node: model
content: [{'type': 'text', 'text': ' sunny'}]
node: model
content: [{'type': 'text', 'text': ' in'}]
node: model
content: [{'type': 'text', 'text': ' San'}]
node: model
content: [{'type': 'text', 'text': ' Francisco'}]
node: model
content: [{'type': 'text', 'text': '!"\n\n'}]
自定义更新
要在工具执行时流式传输更新,可以使用 get_stream_writer。
流式传输自定义更新示例:
from langchain.agents import create_agent
from langgraph.config import get_stream_writer
def get_weather(city: str) -> str:
"""获取指定城市的天气信息"""
writer = get_stream_writer()
# 流式传输任意数据
writer(f"Looking up data for city: {city}")
writer(f"Acquired data for city: {city}")
return f"It's always sunny in {city}!"
agent = create_agent(
model="claude-sonnet-4-5-20250929",
tools=[get_weather],
)
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "What is the weather in SF?"}]},
stream_mode="custom"
):
print(chunk)
输出示例:
Looking up data for city: San Francisco
Acquired data for city: San Francisco
注意:如果你在工具内部添加 get_stream_writer,你将无法在 LangGraph 执行上下文外调用该工具。
get_stream_writer 是一个工具函数,用于在 LangChain 中获取一个流写入器,允许你在工具执行时实时传输自定义更新信息。这对于需要提供动态反馈的应用尤其有用,比如在处理复杂任务时,用户可以看到进度或其他实时信息,而不仅仅是最终的输出结果。
实时反馈:get_stream_writer 可以用来在执行过程中动态地流式传输信息,告诉用户工具在做什么。这对于提升用户体验,特别是在处理需要一定时间的任务时非常重要。
自定义更新:你可以通过它输出任意的进度信息或状态更新。例如,通知用户正在获取某些数据、执行某个步骤、或是处理某些任务。
比如我在定义的websearch工具中,使用get_stream_writer来向前端输出”正在搜索网页"…
流式传输多模式
你可以通过将 stream_mode 设置为列表来指定多个流模式,例如 stream_mode=["updates", "custom"]。
流式传输多种模式示例:
from langchain.agents import create_agent
from langgraph.config import get_stream_writer
def get_weather(city: str) -> str:
"""获取指定城市的天气信息"""
writer = get_stream_writer()
writer(f"Looking up data for city: {city}")
writer(f"Acquired data for city: {city}")
return f"It's always sunny in {city}!"
agent = create_agent(
model="gpt-5-nano",
tools=[get_weather],
)
for stream_mode, chunk in agent.stream(
{"messages": [{"role": "user", "content": "What is the weather in SF?"}]},
stream_mode=["updates", "custom"]
):
print(f"stream_mode: {stream_mode}")
print(f"content: {chunk}")
print("\n")
输出示例:
stream_mode: updates
content: {'model': {'messages': [AIMessage(content='', response_metadata={'token_usage': {'completion_tokens': 280, 'prompt_tokens': 132, 'total_tokens': 412, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 256, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-5-nano-2025-08-07', 'system_fingerprint': None, 'id': 'chatcmpl-C9tlgBzGEbedGYxZ0rTCz5F7OXpL7', 'service_tier': 'default', 'finish_reason': 'tool_calls', 'logprobs': None}, id='lc_run--480c07cb-e405-4411-aa7f-0520fddeed66-0', tool_calls=[{'name': 'get_weather', 'args': {'city': 'San Francisco'}, 'id': 'call_KTNQIftMrl9vgNwEfAJMVu7r', 'type': 'tool_call'}], usage_metadata={'input_tokens': 132, 'output_tokens': 280, 'total_tokens': 412, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 256}})]}}
stream_mode: custom
content: Looking up data for city: San Francisco
stream_mode: custom
content: Acquired data for city: San Francisco
stream_mode: updates
content: {'tools': {'messages': [ToolMessage(content="It's always sunny in San Francisco!", name='get_weather', tool_call_id='call_KTNQIftMrl9vgNwEfAJMVu7r')]}}
stream_mode: updates
content: {'model': {'messages': [AIMessage(content='San Francisco weather: It\'s always sunny in San Francisco!\n\n', response_metadata={'token_usage': {'completion_tokens': 764, 'prompt_tokens': 168, 'total_tokens': 932, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 704, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-5-nano-2025-08-07', 'system_fingerprint': None, 'id': 'chatcmpl-C9tljDFVki1e1haCyikBptAuXuHYG', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--acbc740a-18fe-4a14-8619-da92a0d0ee90-0', usage_metadata={'input_tokens': 168, 'output_tokens': 764, 'total_tokens': 932, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 704}})]}}
禁用流式传输
在某些应用中,可能需要禁用给定模型的单个标记流式传输。这在多代理系统中非常有用,可以控制哪些代理流式传输其输出。
结构化输出
结构化输出允许代理返回特定且可预测的格式的数据。与解析自然语言响应不同,你将获得结构化数据,这些数据以JSON对象、Pydantic模型或数据类的形式返回,应用程序可以直接使用这些数据。
LangChain的 create_agent 会自动处理结构化输出。用户设置所需的结构化输出模式,并且当模型生成结构化数据时,这些数据会被捕获、验证,并作为代理状态中的 structured_response 返回。
注意区分model的结构化输出和agent的结构化输出。
响应格式控制代理如何返回结构化数据:
- ToolStrategy[StructuredResponseT]: 使用工具调用来返回结构化输出。
- ProviderStrategy[StructuredResponseT]: 使用提供者原生的结构化输出。
- type[StructuredResponseT]: 模式类型 —— 根据模型能力自动选择最佳策略。
- None: 没有结构化输出。
当直接提供模式类型时,LangChain 会自动选择:
- 如果模型支持原生结构化输出(例如 OpenAI、Grok),会使用 ProviderStrategy。
- 对于所有其他模型,使用 ToolStrategy。
结构化响应会返回在代理最终状态的 structured_response 键中。
某些模型提供者通过他们的API原生支持结构化输出(例如 OpenAI、Grok、Gemini)。当此功能可用时,这是最可靠的方法。
要使用此策略,需要配置 ProviderStrategy:
class ProviderStrategy(Generic[SchemaT]):
schema: type[SchemaT]
schema:定义结构化输出格式的模式。支持:
- Pydantic 模型:具有字段验证的 BaseModel 子类。
- Dataclass:带有类型注解的 Python 数据类。
- TypedDict:带有类型注解的字典类。
- JSON Schema:带有 JSON 模式说明的字典。
LangChain 在以下情况下会自动使用 ProviderStrategy:
- 当你直接将模式类型传递给
create_agent.response_format,并且模型支持原生结构化输出时。
以下是一个使用 Pydantic 模型作为结构化输出格式的例子:
from pydantic import BaseModel, Field
from langchain.agents import create_agent
class ContactInfo(BaseModel):
"""人员的联系信息"""
name: str = Field(description="人员的名字")
email: str = Field(description="人员的电子邮件地址")
phone: str = Field(description="人员的电话号码")
agent = create_agent(
model="gpt-5",
tools=tools,
response_format=ContactInfo # 自动选择 ProviderStrategy
)
result = agent.invoke({
"messages": [{"role": "user", "content": "Extract contact info from: John Doe, john@example.com, (555) 123-4567"}]
})
print(result["structured_response"])
# 输出:ContactInfo(name='John Doe', email='john@example.com', phone='(555) 123-4567')
提供者原生结构化输出提供了高可靠性和严格验证,因为模型提供者强制执行模式。在可用时,建议使用此功能。
如果提供者原生支持结构化输出,那么在 create_agent 中直接写 response_format=ProductReview 等同于使用 response_format=ToolStrategy(ProductReview)。在这两种情况下,如果模型不支持结构化输出,代理将回退到工具调用策略。
对于不支持原生结构化输出的模型,LangChain使用工具调用来实现相同的功能。这适用于所有支持工具调用的模型,大多数现代模型都支持此功能。
要使用此策略,需要配置 ToolStrategy:
class ToolStrategy(Generic[SchemaT]):
schema: type[SchemaT] # 定义结构化输出格式的模式
tool_message_content: str | None # 自定义工具消息内容
handle_errors: Union[
bool,
str,
type[Exception],
tuple[type[Exception], ...],
Callable[[Exception], str],
] # 错误处理策略
参数说明:
-
schema (必需):
定义结构化输出格式的模式。支持:- Pydantic 模型:具有字段验证的
BaseModel子类。 - Dataclass:带有类型注解的 Python 数据类。
- TypedDict:带有类型注解的字典类。
- JSON Schema:带有 JSON 模式说明的字典。
- Union 类型:多种模式选项。模型会根据上下文选择最合适的模式。
- Pydantic 模型:具有字段验证的
-
tool_message_content:
自定义结构化输出生成时,返回的工具消息内容。如果未提供,则默认显示结构化响应数据。 -
handle_errors:
结构化输出验证失败时的错误处理策略。默认为True:- True:捕获所有错误并使用默认错误模板。
- str:捕获所有错误并使用此自定义消息。
- type[Exception]:仅捕获此异常类型并使用默认消息。
- tuple[type[Exception], …]:仅捕获这些异常类型并使用默认消息。
- Callable[[Exception], str]:自定义函数,返回错误消息。
- False:不重试,允许异常传播。
以下是一个使用 Pydantic 模型 作为结构化输出格式的例子:
from pydantic import BaseModel, Field
from typing import Literal
from langchain.agents import create_agent
from langchain.agents.structured_output import ToolStrategy
class ProductReview(BaseModel):
"""产品评论分析"""
rating: int | None = Field(description="产品的评分", ge=1, le=5)
sentiment: Literal["positive", "negative"] = Field(description="评论的情感")
key_points: list[str] = Field(description="评论的关键点,每个关键点小写,1-3个词")
agent = create_agent(
model="gpt-5",
tools=tools,
response_format=ToolStrategy(ProductReview) # 自动选择工具调用策略
)
result = agent.invoke({
"messages": [{"role": "user", "content": "分析这个评论:'很棒的产品:5星。运输很快,但很贵'"}]
})
print(result["structured_response"])
# 输出:ProductReview(rating=5, sentiment='positive', key_points=['fast shipping', 'expensive'])
tool_message_content 参数允许你自定义生成结构化输出时,在对话历史中显示的消息内容:
from pydantic import BaseModel, Field
from typing import Literal
from langchain.agents import create_agent
from langchain.agents.structured_output import ToolStrategy
class MeetingAction(BaseModel):
"""会议记录中的行动项"""
task: str = Field(description="需要完成的具体任务")
assignee: str = Field(description="负责任务的人员")
priority: Literal["low", "medium", "high"] = Field(description="任务优先级")
agent = create_agent(
model="gpt-5",
tools=[],
response_format=ToolStrategy(
schema=MeetingAction,
tool_message_content="行动项已记录并添加到会议记录!"
)
)
agent.invoke({
"messages": [{"role": "user", "content": "会议中:Sarah需要尽快更新项目时间表"}]
})
输出:
================================ 人类消息 =================================
会议中:Sarah需要尽快更新项目时间表
================================== AI消息 ==================================
工具调用:
MeetingAction (call_1)
调用ID:call_1
参数:
task: 更新项目时间表
assignee: Sarah
priority: 高
================================= 工具消息 =================================
名称: MeetingAction
行动项已记录并添加到会议记录!
如果没有 tool_message_content,我们的最终工具消息将是:
================================ 工具消息 =================================
名称: MeetingAction
返回结构化响应:{'task': '更新项目时间表', 'assignee': 'Sarah', 'priority': '高'}
为什么会使用ToolStrategy?
假设一个模型不会输出结构化内容,则你需要提供一个工具,利用模型的fucntion call能力,把曾经输出的自然语言再进行一次Function call然后返回。
而ToolStrategy其实就是内置的一个工具,LangChain在v0.x玩抽象,没想到在v1.0上玩抽象中的抽象。
错误处理
在生成结构化输出时,模型可能会出现错误,特别是在通过工具调用生成结构化数据时。LangChain 提供了智能重试机制来自动处理这些错误。
多个结构化输出错误
当模型错误地调用了多个结构化输出工具时,代理会在 ToolMessage 中提供错误反馈,并提示模型进行重试。
假设你使用了一个 Union 类型来期望返回一个结构化输出,但模型错误地返回了两个结构化输出。LangChain 会触发错误,并要求模型修复错误。
from pydantic import BaseModel, Field
from typing import Union
from langchain.agents import create_agent
from langchain.agents.structured_output import ToolStrategy
class ContactInfo(BaseModel):
name: str = Field(description="Person's name")
email: str = Field(description="Email address")
class EventDetails(BaseModel):
event_name: str = Field(description="Name of the event")
date: str = Field(description="Event date")
agent = create_agent(
model="gpt-5",
tools=[],
response_format=ToolStrategy(Union[ContactInfo, EventDetails]) # 默认: handle_errors=True
)
result = agent.invoke({
"messages": [{"role": "user", "content": "Extract info: John Doe (john@email.com) is organizing Tech Conference on March 15th"}]
})
# 模型返回多个结构化输出
错误反馈:
Tool Message:
Name: ContactInfo
Error: Model incorrectly returned multiple structured responses (ContactInfo, EventDetails) when only one is expected.
Please fix your mistakes.
模型会根据错误提示进行重试,返回正确的结构化响应。
模式验证错误
如果结构化输出与预期的模式不匹配,代理会提供具体的错误反馈。
假设你定义了一个 ProductRating 模型来解析产品评分,但模型返回的评分超过了有效范围(1 到 5),系统会提示错误,并要求修复:
from pydantic import BaseModel, Field
from langchain.agents import create_agent
from langchain.agents.structured_output import ToolStrategy
class ProductRating(BaseModel):
rating: int | None = Field(description="Rating from 1-5", ge=1, le=5)
comment: str = Field(description="Review comment")
agent = create_agent(
model="gpt-5",
tools=[],
response_format=ToolStrategy(ProductRating), # 默认: handle_errors=True
system_prompt="You are a helpful assistant that parses product reviews. Do not make any field or value up."
)
result = agent.invoke({
"messages": [{"role": "user", "content": "Parse this: Amazing product, 10/10!"}]
})
# 错误反馈:评分超过了最大值
错误反馈:
Tool Message:
Name: ProductRating
Error: Failed to parse structured output for tool 'ProductRating': 1 validation error for ProductRating.rating
Input should be less than or equal to 5 [type=less_than_equal, input_value=10, input_type=int].
Please fix your mistakes.
模型会根据错误提示进行修复,返回正确的数据。
错误处理策略
你可以通过 handle_errors 参数自定义错误处理方式。
- 自定义错误消息:通过设置
handle_errors为字符串,可以定义一个固定的错误消息来提示模型进行重试。
ToolStrategy(
schema=ProductRating,
handle_errors="Please provide a valid rating between 1-5 and include a comment."
)
- 仅处理特定异常:通过设置
handle_errors为异常类型,代理将只在特定异常(如ValueError)发生时进行重试,其他异常将被抛出。
ToolStrategy(
schema=ProductRating,
handle_errors=ValueError # 仅对 ValueError 进行重试
)
- 处理多个异常类型:你可以为多个异常类型定义错误处理机制,当这些异常发生时,代理会自动进行重试。
ToolStrategy(
schema=ProductRating,
handle_errors=(ValueError, TypeError) # 对 ValueError 和 TypeError 进行重试
)
- 自定义错误处理函数:你还可以定义一个自定义函数来处理不同的错误类型,并返回相应的错误消息。
def custom_error_handler(error: Exception) -> str:
if isinstance(error, StructuredOutputValidationError):
return "There was an issue with the format. Try again."
elif isinstance(error, MultipleStructuredOutputsError):
return "Multiple structured outputs were returned. Pick the most relevant one."
else:
return f"Error: {str(error)}"
ToolStrategy(
schema=ToolStrategy(Union[ContactInfo, EventDetails]),
handle_errors=custom_error_handler
)
- 没有错误处理:如果你不希望对错误进行处理,可以将
handle_errors设置为False,这样所有错误都会被抛出。
ToolStrategy(
schema=ProductRating,
handle_errors=False # 所有错误都会被抛出
)
总结:
- 多个结构化输出错误:如果模型错误地返回了多个结构化输出,LangChain 会提醒模型并要求重试。
- 模式验证错误:当模型返回的数据不符合预期的模式时,LangChain 会提供详细的错误反馈,帮助修复错误。
- 自定义错误处理:通过
handle_errors,你可以自定义如何处理这些错误,定义错误消息或指定特定的异常类型进行重试。
中间件
中间件提供了一种方式来更加精确地控制代理内部的执行过程。中间件对于以下操作特别有用:
- 跟踪代理行为:进行日志记录、分析和调试。
- 转换提示、工具选择和输出格式。
- 添加重试、回退和提前终止逻辑。
- 应用速率限制、保护措施和个人身份信息(PII)检测。
你可以通过将中间件传递给 create_agent 来添加中间件:
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware, HumanInTheLoopMiddleware
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[
SummarizationMiddleware(...),
HumanInTheLoopMiddleware(...)
],
)
核心代理循环包括调用模型、让模型选择工具执行,然后在模型不再调用工具时结束:
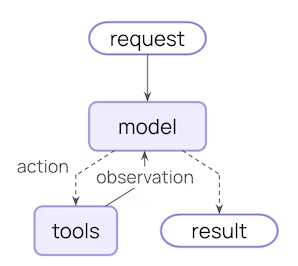
中间件暴露了在每个步骤前后进行钩子操作的机会:
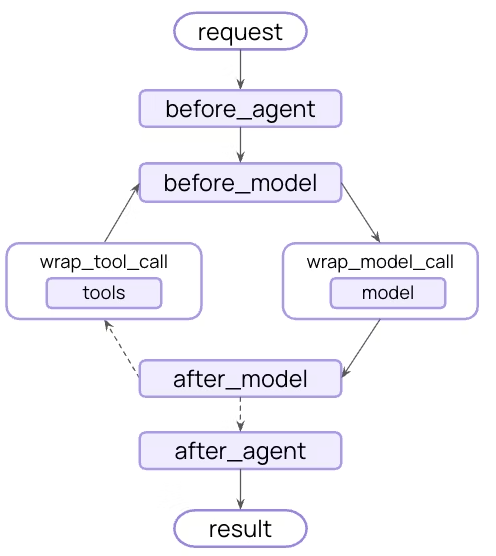
内置中间件
LangChain 提供了预构建的中间件,适用于常见的用例。每个中间件都是生产就绪的,并且可以根据你的特定需求进行配置。
以下中间件适用于任何 LLM 提供商:
| 中间件名称 | 描述 |
|---|---|
| Summarization | 当接近令牌限制时,自动总结对话历史。 |
| Human-in-the-loop | 在工具调用前暂停执行,等待人工审批。 |
| Model call limit | 限制模型调用次数,以防止产生过高的费用。 |
| Tool call limit | 通过限制调用次数来控制工具执行。 |
| Model fallback | 当主要模型失败时,自动回退到备选模型。 |
| PII detection | 检测和处理个人身份信息(PII)。 |
| To-do list | 为代理提供任务规划和跟踪能力。 |
| LLM tool selector | 在调用主模型之前,使用 LLM 选择相关工具。 |
| Tool retry | 自动重试失败的工具调用,采用指数退避策略。 |
| LLM tool emulator | 使用 LLM 模拟工具执行,用于测试目的。 |
| Context editing | 管理对话上下文,通过修剪或清除工具使用记录。 |
| Shell tool | 向代理暴露一个持久化的 Shell 会话,用于命令执行。 |
| File search | 提供文件系统文件的 Glob 和 Grep 搜索工具。 |
总结中间件(Summarization)
当接近令牌限制时,自动总结对话历史,保留最近的消息,同时压缩较早的上下文。
总结功能在以下情况中特别有用:
- 超过上下文窗口的长期对话。
- 具有广泛历史记录的多轮对话。
- 在需要保留完整对话上下文的应用程序中。
配置选项
-
model
string | BaseChatModel(必需)
用于生成总结的模型。可以是模型标识符字符串(如 ‘openai:gpt-4o-mini’)或一个BaseChatModel实例。 -
trigger
dict | list[dict]
总结触发条件。可以是:- 单个条件字典(必须满足所有属性 - AND 逻辑)
- 条件字典的列表(必须满足任何条件 - OR 逻辑)
每个条件可以包含: fraction(float):模型上下文大小的比例(0-1)tokens(int):绝对令牌数量messages(int):消息数量
每个条件至少需要指定一个属性。如果未提供,摘要将不会自动触发。
-
keep
dict(默认值:{messages: 20})
总结后要保留多少上下文。需要指定以下之一:fraction(float):要保留的模型上下文大小的比例(0-1)tokens(int):要保留的绝对令牌数messages(int):要保留的最近消息数量
-
token_counter
function
自定义令牌计数函数,默认为基于字符的计数。 -
summary_prompt
string
自定义总结提示模板。如果未指定,将使用内置模板。模板应包含{messages}占位符,表示将插入对话历史。 -
trim_tokens_to_summarize
number(默认值:4000)
生成总结时包含的最大令牌数量。在生成总结之前,消息将被修剪以适应此限制。 -
summary_prefix
string
添加到总结消息的前缀。如果未提供,将使用默认前缀。 -
max_tokens_before_summary
number(已废弃)
废弃:使用trigger: {"tokens": value}来代替。触发总结的令牌阈值。 -
messages_to_keep
number(已废弃)
废弃:使用keep: {"messages": value}来代替。要保留的最近消息。
总结中间件监控消息的令牌数量,并在达到阈值时自动总结较旧的消息。触发条件控制总结的执行时机:
- 单条件对象(必须满足所有属性 - AND 逻辑)
- 条件数组(必须满足任何条件 - OR 逻辑)
每个条件可以使用 fraction(模型上下文大小的比例)、tokens(绝对令牌数量)或 messages(消息数量)。
保留条件 控制保留多少上下文(指定其中之一):
fraction- 要保留的模型上下文大小的比例tokens- 要保留的绝对令牌数量messages- 要保留的消息数量
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
# 单条件:当令牌数 >= 4000 且消息数 >= 10 时触发总结
agent = create_agent(
model="gpt-4o",
tools=[weather_tool, calculator_tool],
middleware=[
SummarizationMiddleware(
model="gpt-4o-mini",
trigger={"tokens": 4000, "messages": 10},
keep={"messages": 20},
),
],
)
# 多条件
agent2 = create_agent(
model="gpt-4o",
tools=[weather_tool, calculator_tool],
middleware=[
SummarizationMiddleware(
model="gpt-4o-mini",
trigger=[
{"tokens": 5000, "messages": 3},
{"tokens": 3000, "messages": 6},
],
keep={"messages": 20},
),
],
)
# 使用比例限制
agent3 = create_agent(
model="gpt-4o",
tools=[weather_tool, calculator_tool],
middleware=[
SummarizationMiddleware(
model="gpt-4o-mini",
trigger={"fraction": 0.8},
keep={"fraction": 0.3},
),
],
)
人类监督(Human-in-the-loop)
暂停代理执行,等待人类批准、编辑或拒绝工具调用,然后才执行。
“人类监督”对于以下情况特别有用:
- 需要人类批准的高风险操作(例如数据库写入、金融交易)。
- 合规工作流程中,必须有人工监督。
- 长时间运行的对话,其中人类反馈引导代理行为。
人类监督中间件 需要一个检查点(checkpointer)来在中断后保持状态。
from langchain.agents import create_agent
from langchain.agents.middleware import HumanInTheLoopMiddleware
from langgraph.checkpoint.memory import InMemorySaver
agent = create_agent(
model="gpt-4o",
tools=[read_email_tool, send_email_tool],
checkpointer=InMemorySaver(),
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
"send_email_tool": {
"allowed_decisions": ["approve", "edit", "reject"],
},
"read_email_tool": False,
}
),
],
)
模型调用限制(Model Call Limit)
限制模型调用次数,以防止无限循环或过度成本。
模型调用限制对于以下情况非常有用:
- 防止代理过度调用API,导致无限循环。
- 强制在生产部署中控制成本。
- 在特定调用预算内测试代理行为。
配置选项
-
thread_limit
number
限制一个线程中所有运行的最大模型调用次数,默认为没有限制。 -
run_limit
number
限制单次调用的最大模型调用次数,默认为没有限制。 -
exit_behavior
string(默认值:“end”)
达到限制时的行为。选项:'end'(优雅终止)'error'(抛出异常)
from langchain.agents import create_agent
from langchain.agents.middleware import ModelCallLimitMiddleware
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[
ModelCallLimitMiddleware(
thread_limit=10, # 限制每个线程最多10次模型调用
run_limit=5, # 限制每次调用最多5次模型调用
exit_behavior="end", # 达到限制时优雅终止
),
],
)
工具调用限制(Tool call limit)
通过限制工具调用次数来控制代理执行,无论是全局限制所有工具调用,还是针对特定工具进行限制。
工具调用限制对于以下情况特别有用:
- 防止过度调用昂贵的外部API。
- 限制网络搜索或数据库查询。
- 强制对特定工具使用进行速率限制。
- 防止代理进入无限循环。
配置选项
-
tool_name
string
指定要限制的具体工具名称。如果未提供,限制将应用于所有工具。 -
thread_limit
number
限制一个线程(对话)中的最大工具调用次数。会在多次调用之间保持状态。需要一个检查点(checkpointer)来保持状态。为None表示没有线程限制。 -
run_limit
number
限制单次调用中的最大工具调用次数(一个用户消息 → 响应循环)。每次新用户消息时会重置。为None表示没有运行限制。
注意: 必须指定thread_limit或run_limit中的至少一个。 -
exit_behavior
string(默认值:“continue”)
达到限制时的行为:'continue'(默认):阻止超出限制的工具调用,显示错误消息,其他工具和模型继续执行。模型会根据错误消息决定何时结束。'error':立即抛出ToolCallLimitExceededError异常,立即停止执行。'end':立即停止执行,返回一个ToolMessage和 AI 消息,仅在限制单个工具时有效;如果其他工具有待处理的调用,则会抛出NotImplementedError。
from langchain.agents import create_agent
from langchain.agents.middleware import ToolCallLimitMiddleware
# 定义全局限制
global_limiter = ToolCallLimitMiddleware(thread_limit=20, run_limit=10)
# 定义针对具体工具的限制
search_limiter = ToolCallLimitMiddleware(tool_name="search", thread_limit=5, run_limit=3)
database_limiter = ToolCallLimitMiddleware(tool_name="query_database", thread_limit=10)
strict_limiter = ToolCallLimitMiddleware(tool_name="scrape_webpage", run_limit=2, exit_behavior="error")
agent = create_agent(
model="gpt-4o",
tools=[search_tool, database_tool, scraper_tool],
middleware=[global_limiter, search_limiter, database_limiter, strict_limiter],
)
模型回退(Model fallback)
当主模型失败时,自动回退到备用模型。
模型回退对于以下情况特别有用:
- 构建具有弹性的代理,可以处理模型故障。
- 通过回退到更便宜的模型来优化成本。
- 跨多个提供者(如 OpenAI、Anthropic 等)实现冗余。
配置选项
-
first_model
string | BaseChatModel(必填)
主模型失败时,首先尝试回退到的备用模型。可以是模型标识符字符串(例如'openai:gpt-4o-mini')或BaseChatModel实例。 -
additional_models
string | BaseChatModel
如果前一个备用模型失败,则依次尝试的其他备用模型。
from langchain.agents import create_agent
from langchain.agents.middleware import ModelFallbackMiddleware
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[
ModelFallbackMiddleware(
"gpt-4o-mini", # 第一个备用模型
"claude-3-5-sonnet-20241022", # 第二个备用模型
),
],
)
PII 检测(PII Detection)
使用可配置的策略检测和处理对话中的个人可识别信息(PII)。
PII 检测对于以下情况特别有用:
-
需要合规性的医疗保健和金融应用。
-
需要清理日志的客户服务代理。
-
任何处理敏感用户数据的应用。
-
pii_type
string(必填)
要检测的 PII 类型。可以是内置类型(例如:email, credit_card, ip, mac_address, url)或自定义类型名称。 -
strategy
string(默认值:“redact”)
检测到 PII 后如何处理。选项包括:'block':检测到时抛出异常。'redact':用[REDACTED_TYPE]替换。'mask':部分遮掩(例如:****-****-****-1234)。'hash':替换为确定性哈希值。
-
detector
function | regex
自定义检测函数或正则表达式模式。如果未提供,使用内置的 PII 类型检测器。 -
apply_to_input
boolean(默认值:True)
在模型调用之前检查用户消息。 -
apply_to_output
boolean(默认值:False)
在模型调用之后检查 AI 消息。 -
apply_to_tool_results
boolean(默认值:False)
在执行工具之后检查工具结果消息。
-
简单的正则表达式匹配:
from langchain.agents import create_agent from langchain.agents.middleware import PIIMiddleware # 使用正则表达式检测 API 密钥 agent1 = create_agent( model="gpt-4o", tools=[...], middleware=[ PIIMiddleware( "api_key", detector=r"sk-[a-zA-Z0-9]{32}", strategy="block", ), ], ) -
编译的正则表达式模式:
import re from langchain.agents import create_agent from langchain.agents.middleware import PIIMiddleware # 使用编译的正则表达式模式检测电话号码 agent2 = create_agent( model="gpt-4o", tools=[...], middleware=[ PIIMiddleware( "phone_number", detector=re.compile(r"\+?\d{1,3}[\s.-]?\d{3,4}[\s.-]?\d{4}"), strategy="mask", ), ], ) -
自定义检测函数:
from langchain.agents import create_agent from langchain.agents.middleware import PIIMiddleware import re def detect_ssn(content: str) -> list[dict[str, str | int]]: """检测社会保障号码(SSN)并进行验证。 返回一个包含 'text', 'start', 和 'end' 键的字典列表。 """ matches = [] pattern = r"\d{3}-\d{2}-\d{4}" for match in re.finditer(pattern, content): ssn = match.group(0) # 验证:前 3 位不能是 000, 666 或 900-999 first_three = int(ssn[:3]) if first_three not in [0, 666] and not (900 <= first_three <= 999): matches.append({ "text": ssn, "start": match.start(), "end": match.end(), }) return matches # 使用自定义的社会保障号码检测函数 agent3 = create_agent( model="gpt-4o", tools=[...], middleware=[ PIIMiddleware( "ssn", detector=detect_ssn, strategy="hash", ), ], )
自定义检测函数签名:
检测函数必须接受一个字符串(content),并返回匹配项,返回一个包含 text, start, 和 end 键的字典列表。
def detector(content: str) -> list[dict[str, str | int]]:
return [
{"text": "matched_text", "start": 0, "end": 12},
# ... more matches
]
自定义检测器的使用方法:
- 使用正则表达式字符串来匹配简单模式。
- 使用 RegExp 对象来处理需要标志的情况(例如:不区分大小写的匹配)。
- 使用自定义函数来实现更复杂的验证逻辑,提供对检测逻辑的完全控制。
配置选项:
-
pii_type
string(必填)
要检测的个人可识别信息(PII)类型。可以是内置类型(例如:email, credit_card, ip, mac_address, url)或自定义类型名称。 -
strategy
string(默认值:“redact”)
检测到 PII 后如何处理。选项包括:'block':检测到时抛出异常。'redact':用[REDACTED_TYPE]替换。'mask':部分遮掩(例如:****-****-****-1234)。'hash':替换为确定性哈希值。
-
detector
function | regex
自定义检测函数或正则表达式模式。如果未提供,使用内置的 PII 类型检测器。 -
apply_to_input
boolean(默认值:True)
在模型调用之前检查用户消息。 -
apply_to_output
boolean(默认值:False)
在模型调用之后检查 AI 消息。 -
apply_to_tool_results
boolean(默认值:False)
在执行工具之后检查工具结果消息。
待办事项清单(To-do list)
为代理配备任务规划和跟踪能力,以应对复杂的多步骤任务。待办事项清单适用于以下情况:
- 需要跨多个工具协调的复杂多步骤任务。
- 长时间运行的操作,其中进度可见性至关重要。
该中间件自动为代理提供 write_todos 工具和系统提示,以指导有效的任务规划。
from langchain.agents import create_agent
from langchain.agents.middleware import TodoListMiddleware
agent = create_agent(
model="gpt-4o",
tools=[read_file, write_file, run_tests],
middleware=[TodoListMiddleware()],
)
配置选项:
-
system_prompt
类型:字符串
用于指导待办事项使用的自定义系统提示。如果未指定,则使用内置提示。 -
tool_description
类型:字符串
write_todos工具的自定义描述。如果未指定,则使用内置描述。
LLM 工具选择器(LLM tool selector)
使用 LLM 在调用主模型之前智能地选择相关工具。LLM 工具选择器适用于以下情况:
- 代理拥有多个工具(10 个以上),其中大多数工具在每次查询时并不相关。
- 通过过滤不相关的工具来减少令牌使用量。
- 提高模型的专注度和准确性。
该中间件使用结构化输出询问 LLM,哪些工具最适用于当前查询。结构化输出模式定义了可用的工具名称和描述。模型提供商通常会在后台将此结构化输出信息添加到系统提示中。
from langchain.agents import create_agent
from langchain.agents.middleware import LLMToolSelectorMiddleware
agent = create_agent(
model="gpt-4o",
tools=[tool1, tool2, tool3, tool4, tool5, ...],
middleware=[
LLMToolSelectorMiddleware(
model="gpt-4o-mini",
max_tools=3,
always_include=["search"],
),
],
)
配置选项:
-
model
类型:字符串 |BaseChatModel
用于工具选择的模型。可以是模型标识符字符串(例如openai:gpt-4o-mini)或BaseChatModel实例。有关更多信息,请参见init_chat_model。默认为代理的主模型。 -
system_prompt
类型:字符串
用于选择模型的指令。如果未指定,则使用内置提示。 -
max_tools
类型:数字
要选择的工具的最大数量。如果模型选择更多工具,则仅使用前max_tools个。如果未指定,则没有限制。 -
always_include
类型:列表(字符串)
始终包含的工具名称,无论是否被选择。这些工具不计入max_tools限制。
工具重试
自动重试失败的工具调用,并支持可配置的指数退避。工具重试适用于以下情况:
- 处理外部 API 调用中的瞬时故障。
- 提高依赖网络的工具的可靠性。
- 构建能够优雅处理临时错误的弹性代理。
from langchain.agents import create_agent
from langchain.agents.middleware import ToolRetryMiddleware
agent = create_agent(
model="gpt-4o",
tools=[search_tool, database_tool],
middleware=[
ToolRetryMiddleware(
max_retries=3,
backoff_factor=2.0,
initial_delay=1.0,
),
],
)
配置选项:
-
max_retries
类型:数字,默认值:“2”
初始调用后的最大重试次数(默认总共重试 3 次)。 -
tools
类型:列表(BaseTool| 字符串)
可选的工具或工具名称列表,适用重试逻辑。如果为None,则应用于所有工具。 -
retry_on
类型:元组(Exception类型,…) | 可调用,默认值:“(Exception,)”
可重试的异常类型元组,或接受异常并返回True以指示应重试的可调用函数。 -
on_failure
类型:字符串 | 可调用,默认值:“return_message”
所有重试用尽后的处理方式。选项有:'return_message'- 返回包含错误详情的ToolMessage(允许 LLM 处理失败)。'raise'- 重新抛出异常(停止代理执行)。- 自定义可调用 - 返回用于
ToolMessage内容的错误消息的函数。
-
backoff_factor
类型:数字,默认值:“2.0”
指数退避的乘数。每次重试的等待时间为initial_delay * (backoff_factor ** retry_number)秒。若设置为 0.0,则表示常规延迟。 -
initial_delay
类型:数字,默认值:“1.0”
第一次重试前的初始延迟,单位为秒。 -
max_delay
类型:数字,默认值:“60.0”
重试间隔的最大延迟(限制指数退避增长)。 -
jitter
类型:布尔值,默认值:“true”
是否在延迟中添加随机抖动(±25%),以避免“雷鸣效应”。
该中间件自动重试失败的工具调用,并使用指数退避。
关键配置:
max_retries- 重试次数(默认:2)。backoff_factor- 指数退避的乘数(默认:2.0)。initial_delay- 第一次重试的延迟(默认:1.0)。max_delay- 延迟增长的上限(默认:60.0)。jitter- 是否添加随机变化(默认:True)。
失败处理:
on_failure='return_message'- 返回错误消息。on_failure='raise'- 重新抛出异常。- 自定义函数 - 返回错误消息的函数。
from langchain.agents import create_agent
from langchain.agents.middleware import ToolRetryMiddleware
agent = create_agent(
model="gpt-4o",
tools=[search_tool, database_tool, api_tool],
middleware=[
ToolRetryMiddleware(
max_retries=3,
backoff_factor=2.0,
initial_delay=1.0,
max_delay=60.0,
jitter=True,
tools=["api_tool"],
retry_on=(ConnectionError, TimeoutError),
on_failure="return_message",
),
],
)
LLM 工具模拟器
使用 LLM 模拟工具执行,供测试使用,将实际的工具调用替换为 AI 生成的响应。LLM 工具模拟器适用于以下情况:
- 测试代理行为而不执行实际工具。
- 在外部工具不可用或昂贵时开发代理。
- 在实现实际工具之前原型设计代理工作流。
from langchain.agents import create_agent
from langchain.agents.middleware import LLMToolEmulator
agent = create_agent(
model="gpt-4o",
tools=[get_weather, search_database, send_email],
middleware=[
LLMToolEmulator(), # 模拟所有工具
],
)
配置选项:
-
tools
类型:列表(字符串 |BaseTool)
要模拟的工具名称(字符串)或BaseTool实例的列表。如果为None(默认),则模拟所有工具。如果为空列表[],则不模拟任何工具。如果是包含工具名称/实例的数组,则仅模拟这些工具。 -
model
类型:字符串 |BaseChatModel
用于生成模拟工具响应的模型。可以是模型标识符字符串(例如'anthropic:claude-sonnet-4-5-20250929')或BaseChatModel实例。如果未指定,则默认使用代理的模型。有关更多信息,请参见init_chat_model。
该中间件使用 LLM 为工具调用生成合理的响应,而不是执行实际的工具。
from langchain.agents import create_agent
from langchain.agents.middleware import LLMToolEmulator
from langchain_core.tools import tool
@tool
def get_weather(location: str) -> str:
"""获取某个地点的当前天气。"""
return f"Weather in {location}"
@tool
def send_email(to: str, subject: str, body: str) -> str:
"""发送邮件。"""
return "Email sent"
# 模拟所有工具(默认行为)
agent = create_agent(
model="gpt-4o",
tools=[get_weather, send_email],
middleware=[LLMToolEmulator()],
)
# 仅模拟特定工具
agent2 = create_agent(
model="gpt-4o",
tools=[get_weather, send_email],
middleware=[LLMToolEmulator(tools=["get_weather"])],
)
# 使用自定义模型进行模拟
agent4 = create_agent(
model="gpt-4o",
tools=[get_weather, send_email],
middleware=[LLMToolEmulator(model="anthropic:claude-sonnet-4-5-20250929")],
)
上下文编辑
在达到令牌限制时,通过清除旧的工具调用输出,同时保留最近的结果,来管理对话上下文。这有助于在长时间对话中处理多个工具调用时保持上下文窗口的可管理性。上下文编辑适用于以下情况:
- 长时间的对话,涉及多个工具调用,超过了令牌限制。
- 通过删除不再相关的旧工具输出来减少令牌成本。
- 只保留最新的 N 个工具结果在上下文中。
from langchain.agents import create_agent
from langchain.agents.middleware import ContextEditingMiddleware, ClearToolUsesEdit
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[
ContextEditingMiddleware(
edits=[
ClearToolUsesEdit(
trigger=100000,
keep=3,
),
],
),
],
)
配置选项:
-
edits
类型:列表(ContextEdit),默认值:“[ClearToolUsesEdit()]”
要应用的ContextEdit策略列表。 -
token_count_method
类型:字符串,默认值:“approximate”
令牌计数方法。选项:‘approximate’ 或 ‘model’
ClearToolUsesEdit 选项:
-
trigger
类型:数字,默认值:“100000”
触发编辑的令牌计数。当对话超过此令牌数时,将清除旧的工具输出。 -
clear_at_least
类型:数字,默认值:“0”
编辑执行时要回收的最小令牌数。如果设置为 0,则根据需要清除。 -
keep
类型:数字,默认值:“3”
必须保留的最新工具结果的数量。这些结果将永远不会被清除。 -
clear_tool_inputs
类型:布尔值,默认值:“False”
是否清除工具调用参数。当设置为True时,工具调用的参数将被替换为空对象。 -
exclude_tools
类型:列表(字符串),默认值:“()”
要排除在清除范围外的工具名称列表。这些工具的输出将永远不会被清除。 -
placeholder
类型:字符串,默认值:“[cleared]”
对于已清除的工具输出,插入的占位符文本。这将替换原始工具消息内容。
当令牌限制达到时,中间件应用上下文编辑策略。最常见的策略是 ClearToolUsesEdit,它清除旧的工具结果,同时保留最近的结果。
工作原理:
- 监控对话中的令牌数量
- 达到阈值时,清除较旧的工具输出
- 保留最新的 N 个工具结果
- 可选地,保留工具调用参数以保持上下文
from langchain.agents import create_agent
from langchain.agents.middleware import ContextEditingMiddleware, ClearToolUsesEdit
agent = create_agent(
model="gpt-4o",
tools=[search_tool, calculator_tool, database_tool],
middleware=[
ContextEditingMiddleware(
edits=[
ClearToolUsesEdit(
trigger=2000,
keep=3,
clear_tool_inputs=False,
exclude_tools=[],
placeholder="[cleared]",
),
],
),
],
)
Shell 工具
为代理提供一个持久的 shell 会话,用于执行命令。Shell 工具中间件适用于以下情况:
- 需要执行系统命令的代理
- 开发和部署自动化任务
- 测试和验证工作流
- 文件系统操作和脚本执行
安全考虑:使用适当的执行策略(HostExecutionPolicy、DockerExecutionPolicy 或 CodexSandboxExecutionPolicy)以匹配您的部署的安全需求。
限制:当前持久的 shell 会话不支持中断(人工干预)。预计将来会添加对此的支持。
from langchain.agents import create_agent
from langchain.agents.middleware import (
ShellToolMiddleware,
HostExecutionPolicy,
)
agent = create_agent(
model="gpt-4o",
tools=[search_tool],
middleware=[
ShellToolMiddleware(
workspace_root="/workspace",
execution_policy=HostExecutionPolicy(),
),
],
)
配置选项:
-
workspace_root
类型:字符串 | 路径 | None
Shell 会话的基础目录。如果省略,则会在代理启动时创建一个临时目录,并在结束时删除。 -
startup_commands
类型:元组(字符串,…) | 列表(字符串) | 字符串 | None
会话启动后顺序执行的可选命令。 -
shutdown_commands
类型:元组(字符串,…) | 列表(字符串) | 字符串 | None
会话关闭前执行的可选命令。 -
execution_policy
类型:BaseExecutionPolicy| None
控制超时、输出限制和资源配置的执行策略。选项:HostExecutionPolicy- 完整的主机访问(默认);适用于代理已在容器或虚拟机中运行的可信环境。DockerExecutionPolicy- 为每个代理运行启动一个单独的 Docker 容器,提供更强的隔离性。CodexSandboxExecutionPolicy- 通过 Codex CLI 进行沙箱化执行,附加系统调用/文件系统限制。
-
redaction_rules
类型:元组(RedactionRule,…) | 列表(RedactionRule) | None
可选的红action规则,在返回给模型之前对命令输出进行清理。 -
tool_description
类型:字符串 | None
可选的 Shell 工具描述覆盖。 -
shell_command
类型:序列(字符串) | 字符串 | None
可选的 shell 可执行文件(字符串)或启动持久会话时使用的参数序列。默认为/bin/bash。 -
env
类型:映射(字符串,任意) | None
可选的环境变量,供 shell 会话使用。值在命令执行前会被强制转换为字符串。
该中间件为代理提供一个持久的 shell 会话,代理可以顺序执行命令。
执行策略:
HostExecutionPolicy(默认) - 本地主机执行,提供完整的主机访问权限。DockerExecutionPolicy- 隔离的 Docker 容器执行。CodexSandboxExecutionPolicy- 通过 Codex CLI 进行沙箱化执行。
from langchain.agents import create_agent
from langchain.agents.middleware import (
ShellToolMiddleware,
HostExecutionPolicy,
DockerExecutionPolicy,
RedactionRule,
)
# 基本 shell 工具与主机执行
agent = create_agent(
model="gpt-4o",
tools=[search_tool],
middleware=[
ShellToolMiddleware(
workspace_root="/workspace",
execution_policy=HostExecutionPolicy(),
),
],
)
# Docker 隔离与启动命令
agent_docker = create_agent(
model="gpt-4o",
tools=[],
middleware=[
ShellToolMiddleware(
workspace_root="/workspace",
startup_commands=["pip install requests", "export PYTHONPATH=/workspace"],
execution_policy=DockerExecutionPolicy(
image="python:3.11-slim",
command_timeout=60.0,
),
),
],
)
# 带输出清理
agent_redacted = create_agent(
model="gpt-4o",
tools=[],
middleware=[
ShellToolMiddleware(
workspace_root="/workspace",
redaction_rules=[
RedactionRule(pii_type="api_key", detector=r"sk-[a-zA-Z0-9]{32}"),
],
),
],
)
文件搜索
提供对文件系统文件的 Glob 和 Grep 搜索工具。文件搜索中间件适用于以下情况:
- 代码探索与分析
- 根据名称模式查找文件
- 使用正则表达式搜索代码内容
- 需要文件发现的大型代码库
from langchain.agents import create_agent
from langchain.agents.middleware import FilesystemFileSearchMiddleware
agent = create_agent(
model="gpt-4o",
tools=[],
middleware=[
FilesystemFileSearchMiddleware(
root_path="/workspace",
use_ripgrep=True,
),
],
)
配置选项:
-
root_path
类型:字符串,必填项
要搜索的根目录。所有文件操作都相对于此路径进行。 -
use_ripgrep
类型:布尔值,默认值:“True”
是否使用ripgrep进行搜索。如果ripgrep不可用,则回退使用 Python 正则表达式。 -
max_file_size_mb
类型:整数,默认值:“10”
要搜索的最大文件大小,单位 MB。大于此大小的文件将被跳过。
该中间件为代理添加了两个搜索工具:
-
Glob 工具 - 快速文件模式匹配:
支持如**/*.py、src/**/*.ts等模式
返回按修改时间排序的匹配文件路径 -
Grep 工具 - 使用正则表达式的内容搜索:
支持完整的正则表达式语法
可使用include参数按文件模式过滤
提供三种输出模式:files_with_matches、content、count
from langchain.agents import create_agent
from langchain.agents.middleware import FilesystemFileSearchMiddleware
from langchain_core.messages import HumanMessage
agent = create_agent(
model="gpt-4o",
tools=[],
middleware=[
FilesystemFileSearchMiddleware(
root_path="/workspace",
use_ripgrep=True,
max_file_size_mb=10,
),
],
)
# 代理现在可以使用 glob_search 和 grep_search 工具
result = agent.invoke({
"messages": [HumanMessage("Find all Python files containing 'async def'")]
})
# 代理将使用:
# 1. glob_search(pattern="**/*.py") 查找 Python 文件
# 2. grep_search(pattern="async def", include="*.py") 查找包含 async 函数的文件
自定义中间件
通过实现特定执行点的钩子来构建自定义中间件,控制代理执行流程。
中间件提供两种风格的钩子来拦截代理执行:
- 节点风格钩子
按顺序在特定的执行点运行。 - 包裹风格钩子
在每次模型或工具调用时运行。
节点风格钩子 按顺序在特定执行点运行。适用于日志记录、验证和状态更新。
可用的钩子:
before_agent- 代理开始之前(每次调用一次)before_model- 每次模型调用之前after_model- 每次模型响应之后after_agent- 代理完成之后(每次调用一次)
示例:
from langchain.agents.middleware import before_model, after_model, AgentState
from langchain.messages import AIMessage
from langgraph.runtime import Runtime
from typing import Any
@before_model(can_jump_to=["end"])
def check_message_limit(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
if len(state["messages"]) >= 50:
return {
"messages": [AIMessage("Conversation limit reached.")],
"jump_to": "end"
}
return None
@after_model
def log_response(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print(f"Model returned: {state['messages'][-1].content}")
return None
或
from langchain.agents.middleware import AgentMiddleware, AgentState, hook_config
from langchain.messages import AIMessage
from langgraph.runtime import Runtime
from typing import Any
class MessageLimitMiddleware(AgentMiddleware):
def __init__(self, max_messages: int = 50):
super().__init__()
self.max_messages = max_messages
@hook_config(can_jump_to=["end"])
def before_model(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
if len(state["messages"]) == self.max_messages:
return {
"messages": [AIMessage("Conversation limit reached.")],
"jump_to": "end"
}
return None
def after_model(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print(f"Model returned: {state['messages'][-1].content}")
return None
包裹风格钩子
拦截执行并控制处理程序何时被调用。适用于重试、缓存和转换操作。
你可以决定处理程序是被调用零次(短路)、一次(正常流程)还是多次(重试逻辑)。
可用的钩子:
wrap_model_call- 每次模型调用时wrap_tool_call- 每次工具调用时
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from typing import Callable
@wrap_model_call
def retry_model(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
for attempt in range(3):
try:
return handler(request)
except Exception as e:
if attempt == 2:
raise
print(f"Retry {attempt + 1}/3 after error: {e}")
或
from langchain.agents.middleware import AgentMiddleware, ModelRequest, ModelResponse
from typing import Callable
class RetryMiddleware(AgentMiddleware):
def __init__(self, max_retries: int = 3):
super().__init__()
self.max_retries = max_retries
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
for attempt in range(self.max_retries):
try:
return handler(request)
except Exception as e:
if attempt == self.max_retries - 1:
raise
print(f"Retry {attempt + 1}/{self.max_retries} after error: {e}")
创建中间件
可以通过两种方式创建中间件:
- 基于装饰器的中间件
- 基于类的中间件
基于装饰器的中间件快速简便,适用于单一钩子的中间件。使用装饰器来包装单个函数。
节点风格:
@before_agent- 代理开始之前运行(每次调用一次)@before_model- 每次模型调用之前运行@after_model- 每次模型响应之后运行@after_agent- 代理完成之后运行(每次调用一次)
包裹风格:
@wrap_model_call- 用自定义逻辑包装每次模型调用@wrap_tool_call- 用自定义逻辑包装每次工具调用
便利:
@dynamic_prompt- 生成动态系统提示
from langchain.agents.middleware import before_model, wrap_model_call
from langchain.agents.middleware import AgentState, ModelRequest, ModelResponse
from langchain.agents import create_agent
from langgraph.runtime import Runtime
from typing import Any, Callable
@before_model
def log_before_model(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print(f"About to call model with {len(state['messages'])} messages")
return None
@wrap_model_call
def retry_model(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
for attempt in range(3):
try:
return handler(request)
except Exception as e:
if attempt == 2:
raise
print(f"Retry {attempt + 1}/3 after error: {e}")
agent = create_agent(
model="gpt-4o",
middleware=[log_before_model, retry_model],
tools=[...],
)
何时使用装饰器:
- 只需要单个钩子
- 不需要复杂配置
- 快速原型开发
基于类的中间件适用于更复杂的中间件,涉及多个钩子或配置。使用类时,当您需要为同一钩子定义同步和异步实现,或者当您希望将多个钩子合并为一个中间件时。
from langchain.agents.middleware import AgentMiddleware, AgentState, ModelRequest, ModelResponse
from langgraph.runtime import Runtime
from typing import Any, Callable
class LoggingMiddleware(AgentMiddleware):
def before_model(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print(f"About to call model with {len(state['messages'])} messages")
return None
def after_model(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print(f"Model returned: {state['messages'][-1].content}")
return None
agent = create_agent(
model="gpt-4o",
middleware=[LoggingMiddleware()],
tools=[...],
)
何时使用类:
- 为同一钩子定义同步和异步实现
- 在一个中间件中需要多个钩子
- 需要复杂的配置(例如,可配置的阈值、自定义模型)
- 需要跨项目复用,并且有初始化时的配置
自定义状态Schema
中间件可以通过自定义属性扩展代理的状态。
from langchain.agents.middleware import AgentState, AgentMiddleware
from typing_extensions import NotRequired
from typing import Any
class CustomState(AgentState):
model_call_count: NotRequired[int]
user_id: NotRequired[str]
class CallCounterMiddleware(AgentMiddleware[CustomState]):
state_schema = CustomState
def before_model(self, state: CustomState, runtime) -> dict[str, Any] | None:
count = state.get("model_call_count", 0)
if count > 10:
return {"jump_to": "end"}
return None
def after_model(self, state: CustomState, runtime) -> dict[str, Any] | None:
return {"model_call_count": state.get("model_call_count", 0) + 1}
agent = create_agent(
model="gpt-4o",
middleware=[CallCounterMiddleware()],
tools=[...],
)
# 使用自定义状态调用
result = agent.invoke({
"messages": [HumanMessage("Hello")],
"model_call_count": 0,
"user_id": "user-123",
})
中间件执行顺序
当使用多个中间件时,了解它们的执行顺序非常重要:
示例:
agent = create_agent(
model="gpt-4o",
middleware=[middleware1, middleware2, middleware3],
tools=[...],
)
执行流程:
-
before 钩子按顺序运行:
middleware1.before_agent()middleware2.before_agent()middleware3.before_agent()
-
代理循环开始:
middleware1.before_model()middleware2.before_model()middleware3.before_model()
-
包裹 钩子像函数调用一样嵌套:
middleware1.wrap_model_call()→middleware2.wrap_model_call()→middleware3.wrap_model_call()→ 模型
-
代理循环结束:
middleware3.after_model()middleware2.after_model()middleware1.after_model()
-
after 钩子按反向顺序运行:
middleware3.after_agent()middleware2.after_agent()middleware1.after_agent()
关键规则:
before_*钩子:从第一个到最后一个after_*钩子:从最后一个到第一个(反向)wrap_*钩子:嵌套(第一个中间件包裹所有其他中间件)
代理跳转
为了在中间件中提前退出,可以返回一个包含 jump_to 的字典:
可用的跳转目标:
'end':跳转到代理执行的结束(或第一个after_agent钩子)'tools':跳转到工具节点'model':跳转到模型节点(或第一个before_model钩子)
示例:
from langchain.agents.middleware import AgentMiddleware, hook_config, AgentState
from langchain.messages import AIMessage
from langgraph.runtime import Runtime
from typing import Any
class BlockedContentMiddleware(AgentMiddleware):
@hook_config(can_jump_to=["end"])
def after_model(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
last_message = state["messages"][-1]
if "BLOCKED" in last_message.content:
return {
"messages": [AIMessage("I cannot respond to that request.")],
"jump_to": "end"
}
return None
最佳实践:
-
保持中间件专注:每个中间件应该专注于做一件事,并做得好。
-
优雅处理错误:不要让中间件中的错误导致代理崩溃。
-
使用适当的钩子类型:
- 节点风格用于顺序逻辑(例如,日志记录、验证)。
- 包裹风格用于控制流(例如,重试、回退、缓存)。
-
清晰地记录自定义状态属性。
-
在集成之前独立单元测试中间件。
-
考虑执行顺序:将关键的中间件放在列表的最前面。
-
尽可能使用内置中间件。
下面是对应的中文翻译(在不改变代码的前提下,对说明性文字做了准确、偏工程语境的翻译,并保持结构清晰):
自定义中间件示例
动态模型选择
from langchain.agents.middleware import AgentMiddleware, ModelRequest, ModelResponse
from langchain.chat_models import init_chat_model
from typing import Callable
complex_model = init_chat_model("gpt-4o")
simple_model = init_chat_model("gpt-4o-mini")
class DynamicModelMiddleware(AgentMiddleware):
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
# 根据对话长度使用不同的模型
if len(request.messages) > 10:
model = complex_model
else:
model = simple_model
return handler(request.override(model=model))
工具调用监控
from langchain.tools.tool_node import ToolCallRequest
from langchain.agents.middleware import AgentMiddleware
from langchain.messages import ToolMessage
from langgraph.types import Command
from typing import Callable
class ToolMonitoringMiddleware(AgentMiddleware):
def wrap_tool_call(
self,
request: ToolCallRequest,
handler: Callable[[ToolCallRequest], ToolMessage | Command],
) -> ToolMessage | Command:
print(f"正在执行工具: {request.tool_call['name']}")
print(f"参数: {request.tool_call['args']}")
try:
result = handler(request)
print(f"工具执行成功")
return result
except Exception as e:
print(f"工具执行失败: {e}")
raise
动态选择工具
在运行时选择相关工具,以提升性能和准确性。
- 更短的提示词:只暴露相关工具,降低上下文复杂度
- 更高的准确率:模型在更少的候选工具中更容易做出正确选择
- 权限控制:可根据用户权限动态过滤可用工具
from langchain.agents import create_agent
from langchain.agents.middleware import AgentMiddleware, ModelRequest, ModelResponse
from typing import Callable
class ToolSelectorMiddleware(AgentMiddleware):
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
"""根据状态 / 上下文选择相关工具的中间件"""
# 基于 state / runtime 选择一个小而相关的工具子集
relevant_tools = select_relevant_tools(request.state, request.runtime)
return handler(request.override(tools=relevant_tools))
agent = create_agent(
model="gpt-4o",
tools=all_tools, # 所有可用工具需要在初始化时提前注册
middleware=[ToolSelectorMiddleware()],
)
使用 system message(系统消息)
可以在中间件中通过 ModelRequest.system_message 字段修改系统消息。
system_message 字段始终是一个 SystemMessage 对象(即使在创建 agent 时传入的是字符串形式的 system_prompt)。
示例:为 system message 添加上下文
from langchain.agents.middleware import AgentMiddleware, ModelRequest, ModelResponse
from langchain.messages import SystemMessage
from typing import Callable
class ContextMiddleware(AgentMiddleware):
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
# 始终以内容块(content blocks)的形式处理
new_content = list(request.system_message.content_blocks) + [
{"type": "text", "text": "额外的上下文信息。"}
]
new_system_message = SystemMessage(content=new_content)
return handler(request.override(system_message=new_system_message))
示例:使用缓存控制(Anthropic)
在使用 Anthropic 模型时,可以通过结构化的内容块(content blocks)并结合缓存控制指令,对较大的系统提示词进行缓存:
from langchain.agents.middleware import AgentMiddleware, ModelRequest, ModelResponse
from langchain.messages import SystemMessage
from typing import Callable
class CachedContextMiddleware(AgentMiddleware):
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
# 始终以内容块形式处理
new_content = list(request.system_message.content_blocks) + [
{
"type": "text",
"text": "这里是一份需要分析的大型文档:\n\n<document>...</document>",
"cache_control": {"type": "ephemeral"} # 该内容将被缓存
}
]
new_system_message = SystemMessage(content=new_content)
return handler(request.override(system_message=new_system_message))
说明(Notes)
ModelRequest.system_message始终是一个SystemMessage对象,即使 agent 是通过system_prompt="字符串"创建的- 使用
SystemMessage.content_blocks可以统一以内容块列表的形式访问 system message,无论原始内容是字符串还是列表 - 修改 system message 时,应基于
content_blocks并追加新的 block,以保留原有结构 - 在需要高级用法(如缓存控制)时,可以直接将
SystemMessage对象传给create_agent的system_prompt参数
高级用法
合规
Guardrails 帮助你在智能体执行过程中的关键节点,对内容进行校验与过滤,从而构建安全、合规的 AI 应用。它们可以检测敏感信息、强制执行内容策略、校验输出结果,并在问题发生前阻止不安全行为。
常见使用场景包括:
- 防止个人敏感信息(PII)泄露
- 检测并阻断 Prompt Injection(提示注入)攻击
- 屏蔽不恰当或有害内容
- 强制执行业务规则与合规要求
- 校验输出结果的质量与准确性
你可以通过 中间件(Middleware) 的方式来实现 Guardrails,在关键执行节点拦截流程,例如:
- 智能体启动之前
- 智能体执行完成之后
- 模型调用或工具调用的前后
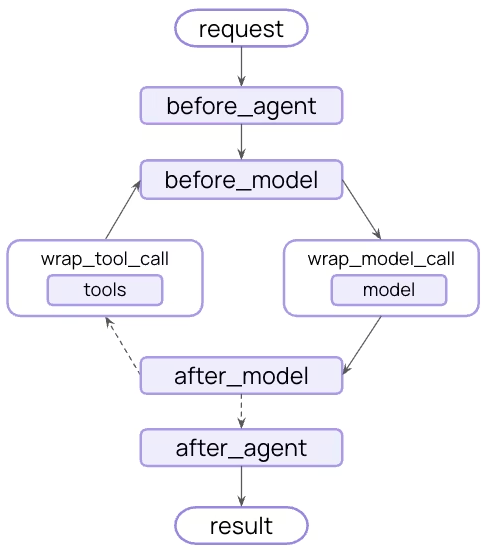
Guardrails 通常通过两种互补的方式来实现:
-
确定性 Guardrails(Deterministic Guardrails)
使用基于规则的逻辑,例如正则表达式、关键词匹配或显式条件判断。
优点是速度快、行为可预测、成本低;
缺点是可能无法识别语义层面较为细微或复杂的违规情况。 -
基于模型的 Guardrails(Model-based Guardrails)
使用大语言模型(LLM)或分类模型对内容进行语义级别的评估。
可以捕获规则难以发现的隐性问题,但执行速度较慢、成本也更高。
LangChain 同时提供了 内置 Guardrails(例如 PII 检测、人类介入机制)以及一个灵活的中间件系统,支持你基于上述任意一种方式构建自定义的 Guardrails。
内置 Guardrails
PII 检测
LangChain 提供了用于检测和处理对话中**个人可识别信息(PII)**的内置中间件。该中间件可以识别常见的 PII 类型,例如邮箱地址、信用卡号、IP 地址等。
PII 检测中间件适用于以下场景:
例如对合规性要求较高的医疗和金融应用、需要对日志进行脱敏处理的客服智能体,以及任何涉及敏感用户数据的应用。
PII 中间件支持多种处理已检测到 PII 的策略:
| 策略 | 描述 | 示例 |
|---|---|---|
| redact | 替换为 [REDACTED_{PII_TYPE}] | [REDACTED_EMAIL] |
| mask | 部分遮挡(例如仅保留后 4 位) | ****-****-****-1234 |
| hash | 替换为确定性哈希值 | a8f5f167... |
| block | 检测到时直接抛出异常 | 抛出错误 |
from langchain.agents import create_agent
from langchain.agents.middleware import PIIMiddleware
agent = create_agent(
model="gpt-4o",
tools=[customer_service_tool, email_tool],
middleware=[
# 在发送给模型前,对用户输入中的邮箱进行脱敏
PIIMiddleware(
"email",
strategy="redact",
apply_to_input=True,
),
# 对用户输入中的信用卡号进行掩码处理
PIIMiddleware(
"credit_card",
strategy="mask",
apply_to_input=True,
),
# 阻断 API Key —— 一旦检测到就抛出错误
PIIMiddleware(
"api_key",
detector=r"sk-[a-zA-Z0-9]{32}",
strategy="block",
apply_to_input=True,
),
],
)
# 当用户提供 PII 时,会按照对应策略进行处理
result = agent.invoke({
"messages": [
{
"role": "user",
"content": "My email is john.doe@example.com and card is 5105-1051-0510-5100"
}
]
})
内置 PII 类型:
email—— 邮箱地址credit_card—— 信用卡号(通过 Luhn 算法校验)ip—— IP 地址mac_address—— MAC 地址url—— URL
配置项说明:
| 参数 | 描述 | 默认值 |
|---|---|---|
pii_type | 要检测的 PII 类型(内置或自定义) | 必填 |
strategy | 处理检测到的 PII 的方式(block / redact / mask / hash) | "redact" |
detector | 自定义检测函数或正则表达式 | None(使用内置检测器) |
apply_to_input | 是否在模型调用前检查用户消息 | True |
apply_to_output | 是否在模型调用后检查 AI 输出 | False |
apply_to_tool_results | 是否在工具执行结果上进行检查 | False |
人类介入(Human-in-the-loop)
LangChain 提供了内置中间件,用于在执行敏感操作之前要求人工审批。这是在高风险决策场景下最有效的 Guardrails 之一。
Human-in-the-loop 中间件适用于以下场景:
例如金融交易和转账、删除或修改生产环境数据、向外部对象发送通信内容,以及任何具有重大业务影响的操作。
from langchain.agents import create_agent
from langchain.agents.middleware import HumanInTheLoopMiddleware
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.types import Command
agent = create_agent(
model="gpt-4o",
tools=[search_tool, send_email_tool, delete_database_tool],
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
# 对敏感操作要求人工审批
"send_email": True,
"delete_database": True,
# 安全操作自动放行
"search": False,
}
),
],
# 在中断之间持久化状态
checkpointer=InMemorySaver(),
)
# Human-in-the-loop 需要一个线程 ID 来保证状态持久化
config = {"configurable": {"thread_id": "some_id"}}
# 在执行敏感工具前,智能体会暂停并等待人工审批
result = agent.invoke(
{"messages": [{"role": "user", "content": "Send an email to the team"}]},
config=config
)
result = agent.invoke(
Command(resume={"decisions": [{"type": "approve"}]}),
config=config # 使用相同的 thread_id 来恢复被暂停的会话
)
自定义 Guardrails
对于更复杂的防护需求,你可以创建自定义中间件,在智能体执行之前或之后运行,从而对校验逻辑、内容过滤和安全检查拥有完全的控制权。
Agent 执行前 Guardrails(Before agent guardrails)
使用 “before agent” 钩子,可以在每次调用开始时对请求进行一次性校验。这非常适合用于会话级别的检查,例如身份认证、限流,或在任何处理开始之前直接拦截不恰当的请求。
from typing import Any
from langchain.agents.middleware import AgentMiddleware, AgentState, hook_config
from langgraph.runtime import Runtime
class ContentFilterMiddleware(AgentMiddleware):
"""确定性 Guardrail:阻止包含被禁关键词的请求。"""
def __init__(self, banned_keywords: list[str]):
super().__init__()
self.banned_keywords = [kw.lower() for kw in banned_keywords]
@hook_config(can_jump_to=["end"])
def before_agent(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
# 获取第一条用户消息
if not state["messages"]:
return None
first_message = state["messages"][0]
if first_message.type != "human":
return None
content = first_message.content.lower()
# 检查是否包含被禁关键词
for keyword in self.banned_keywords:
if keyword in content:
# 在任何处理开始之前直接阻断执行
return {
"messages": [{
"role": "assistant",
"content": "我无法处理包含不当内容的请求,请重新表述你的问题。"
}],
"jump_to": "end"
}
return None
# 使用自定义 Guardrail
from langchain.agents import create_agent
agent = create_agent(
model="gpt-4o",
tools=[search_tool, calculator_tool],
middleware=[
ContentFilterMiddleware(
banned_keywords=["hack", "exploit", "malware"]
),
],
)
# 该请求会在任何处理开始之前被阻断
result = agent.invoke({
"messages": [{"role": "user", "content": "How do I hack into a database?"}]
})
Agent 执行后 Guardrails(After agent guardrails)
使用 “after agent” 钩子,可以在最终结果返回给用户之前,对完整的智能体输出进行一次校验。这非常适合用于基于模型的安全检查、质量验证,或对最终响应进行合规扫描。
from langchain.agents.middleware import AgentMiddleware, AgentState, hook_config
from langgraph.runtime import Runtime
from langchain.messages import AIMessage
from langchain.chat_models import init_chat_model
from typing import Any
class SafetyGuardrailMiddleware(AgentMiddleware):
"""基于模型的 Guardrail:使用 LLM 评估响应的安全性。"""
def __init__(self):
super().__init__()
self.safety_model = init_chat_model("gpt-4o-mini")
@hook_config(can_jump_to=["end"])
def after_agent(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
# 获取最终的 AI 响应
if not state["messages"]:
return None
last_message = state["messages"][-1]
if not isinstance(last_message, AIMessage):
return None
# 使用模型评估安全性
safety_prompt = f"""请评估以下回复是否安全、合适。
仅返回 'SAFE' 或 'UNSAFE'。
回复内容:{last_message.content}"""
result = self.safety_model.invoke([
{"role": "user", "content": safety_prompt}
])
if "UNSAFE" in result.content:
last_message.content = "我无法提供该内容,请重新表述你的请求。"
return None
# 使用安全 Guardrail
from langchain.agents import create_agent
agent = create_agent(
model="gpt-4o",
tools=[search_tool, calculator_tool],
middleware=[SafetyGuardrailMiddleware()],
)
result = agent.invoke({
"messages": [{"role": "user", "content": "How do I make explosives?"}]
})
组合多个 Guardrail
你可以通过将多个 guardrail 添加到 middleware 数组中来进行叠加。它们会按照顺序执行,从而让你构建分层的安全防护机制:
from langchain.agents import create_agent
from langchain.agents.middleware import PIIMiddleware, HumanInTheLoopMiddleware
agent = create_agent(
model="gpt-4o",
tools=[search_tool, send_email_tool],
middleware=[
# 第 1 层:确定性的输入过滤(agent 执行前)
ContentFilterMiddleware(banned_keywords=["hack", "exploit"]),
# 第 2 层:PII(个人敏感信息)保护(模型前与模型后)
PIIMiddleware("email", strategy="redact", apply_to_input=True),
PIIMiddleware("email", strategy="redact", apply_to_output=True),
# 第 3 层:对敏感工具进行人工审批
HumanInTheLoopMiddleware(interrupt_on={"send_email": True}),
# 第 4 层:基于模型的安全检查(agent 执行后)
SafetyGuardrailMiddleware(),
],
)
运行时(Runtime)
LangChain 的 create_agent 在底层是运行在 LangGraph 的 Runtime 之上的。
LangGraph 对外暴露了一个 Runtime 对象,包含以下信息:
- Context(上下文):静态信息,例如用户 ID、数据库连接,或一次 agent 调用所需的其他依赖
- Store(存储):一个
BaseStore实例,用于长期记忆 - Stream writer(流写入器):一个用于通过
"custom"流模式进行信息流式输出的对象
Runtime 上下文为你的工具(tools)和中间件(middleware)提供了依赖注入能力。
与其将值硬编码或依赖全局状态,不如在调用 agent 时注入运行时依赖(如数据库连接、用户 ID 或配置)。这样可以让你的工具更加易测试、可复用且灵活。
你可以在 工具和中间件 中访问这些 Runtime 信息。
在使用 create_agent 创建 agent 时,你可以通过 context_schema 来定义存储在 agent Runtime 中的上下文结构。
在调用 agent 时,通过 context 参数传入本次运行所需的配置:
from dataclasses import dataclass
from langchain.agents import create_agent
@dataclass
class Context:
user_name: str
agent = create_agent(
model="gpt-5-nano",
tools=[...],
context_schema=Context
)
agent.invoke(
{"messages": [{"role": "user", "content": "What's my name?"}]},
context=Context(user_name="John Smith")
)
在工具(Inside tools)中
你可以在工具内部访问运行时(Runtime)信息,用于:
- 访问上下文(context)
- 读取或写入长期记忆(long-term memory)
- 向自定义流(custom stream)写入内容(例如:工具执行进度 / 状态更新)
在工具中使用 ToolRuntime 参数即可访问 Runtime 对象。
from dataclasses import dataclass
from langchain.tools import tool, ToolRuntime
@dataclass
class Context:
user_id: str
@tool
def fetch_user_email_preferences(runtime: ToolRuntime[Context]) -> str:
"""从存储中获取用户的邮件偏好设置。"""
user_id = runtime.context.user_id
preferences: str = "用户更希望你撰写简短且礼貌的邮件。"
if runtime.store:
if memory := runtime.store.get(("users",), user_id):
preferences = memory.value["preferences"]
return preferences
在中间件(Inside middleware)中
你可以在中间件中访问运行时信息,以便根据用户上下文创建动态提示词、修改消息,或控制 agent 的行为。
在中间件装饰器中,通过 request.runtime 访问 Runtime 对象。
该 runtime 对象会包含在传递给中间件函数的 ModelRequest 参数中。
from dataclasses import dataclass
from langchain.messages import AnyMessage
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import (
dynamic_prompt,
ModelRequest,
before_model,
after_model
)
from langgraph.runtime import Runtime
@dataclass
class Context:
user_name: str
# 动态提示词
@dynamic_prompt
def dynamic_system_prompt(request: ModelRequest) -> str:
user_name = request.runtime.context.user_name
system_prompt = f"你是一个有帮助的助手,请称呼用户为 {user_name}。"
return system_prompt
# 模型调用前钩子
@before_model
def log_before_model(state: AgentState, runtime: Runtime[Context]) -> dict | None:
print(f"正在处理用户请求:{runtime.context.user_name}")
return None
# 模型调用后钩子
@after_model
def log_after_model(state: AgentState, runtime: Runtime[Context]) -> dict | None:
print(f"已完成用户请求:{runtime.context.user_name}")
return None
agent = create_agent(
model="gpt-5-nano",
tools=[...],
middleware=[dynamic_system_prompt, log_before_model, log_after_model],
context_schema=Context
)
agent.invoke(
{"messages": [{"role": "user", "content": "What's my name?"}]},
context=Context(user_name="John Smith")
)
Agent 中的上下文工程(Context engineering in agents)
构建 agent(或任何基于 LLM 的应用)中最困难的部分,是让它们足够可靠。
它们在原型阶段可能运行良好,但在真实世界的使用场景中往往会失败。
为什么 agent 会失败?(Why do agents fail?)
当 agent 失败时,通常是因为 agent 内部的 LLM 调用采取了错误的行动,或没有按我们的预期行事。
LLM 失败通常有两个原因:
- 底层 LLM 的能力不足
- 没有向 LLM 传递“正确的”上下文
在大多数情况下,真正导致 agent 不可靠的其实是第二个原因。
上下文工程(Context engineering),就是以正确的格式向 LLM 提供正确的信息和工具,从而让它能够完成任务。这是 AI 工程师最核心的工作。
缺乏“正确”的上下文,是构建更可靠 agent 的头号障碍,而 LangChain 的 agent 抽象正是为上下文工程而专门设计的。
Agent 循环(The agent loop)
一个典型的 agent 循环包含两个主要步骤:
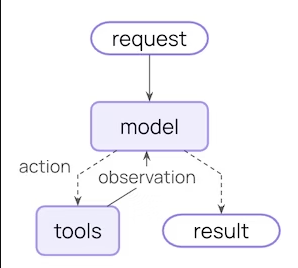
-
模型调用(Model call)
使用提示词和可用工具调用 LLM,返回模型回复,或返回一个需要执行工具的请求 -
工具执行(Tool execution)
执行 LLM 请求的工具,并返回工具执行结果
该循环会持续进行,直到 LLM 决定结束。
你可以控制的内容(What you can control)
要构建可靠的 agent,你需要控制 agent 循环中每一个步骤发生的事情,以及步骤之间发生的事情。
| 上下文类型 | 你能控制的内容 | 临时 / 持久 |
|---|---|---|
| 模型上下文(Model Context) | 进入模型调用的内容(指令、消息历史、工具、响应格式) | 临时 |
| 工具上下文(Tool Context) | 工具可以访问和产出的内容(对状态、存储、运行时上下文的读写) | 持久 |
| 生命周期上下文(Life-cycle Context) | 模型与工具调用之间发生的事情(摘要、guardrails、日志等) | 持久 |
临时上下文(Transient context)
LLM 在单次调用中能看到的内容。你可以修改消息、工具或提示词,而不会改变保存到状态中的内容。
持久上下文(Persistent context)
在多轮对话中被保存到状态里的内容。生命周期钩子和工具写入会永久修改这些内容。
数据来源(Data sources)
在整个过程中,agent 会访问(读取 / 写入)不同的数据源:
| 数据源 | 别名 | 作用范围 | 示例 |
|---|---|---|---|
| 运行时上下文(Runtime Context) | 静态配置 | 会话级 | 用户 ID、API Key、数据库连接、权限、环境配置 |
| 状态(State) | 短期记忆 | 会话级 | 当前消息、上传文件、认证状态、工具结果 |
| 存储(Store) | 长期记忆 | 跨会话 | 用户偏好、提取的洞察、记忆、历史数据 |
工作原理(How it works)
在 LangChain 中,中间件(middleware) 是让上下文工程在开发者侧真正可落地的底层机制。
中间件允许你在 agent 生命周期的任何阶段进行挂钩,并且可以:
- 更新上下文
- 跳转到 agent 生命周期中的其他步骤
模型上下文(Model Context)
用于控制每一次模型调用中包含的内容——指令、可用工具、所使用的模型以及输出格式。这些决策会直接影响可靠性和成本。
-
System Prompt(系统提示词)
开发者向 LLM 提供的基础指令。 -
Messages(消息)
发送给 LLM 的完整消息列表(对话历史)。 -
Tools(工具)
agent 可用于执行动作的工具集合。 -
Model(模型)
实际被调用的模型(包含相关配置)。 -
Response Format(响应格式)
对模型最终响应的 Schema 规范。
以上所有类型的模型上下文,都可以来源于 State(短期记忆)、Store(长期记忆),或 Runtime Context(运行时上下文 / 静态配置)。
系统提示词(System Prompt)
系统提示词决定了 LLM 的行为方式和能力边界。
不同的用户、上下文或对话阶段,往往需要不同的指令。成功的 agent 会利用记忆、用户偏好和配置,在当前对话状态下提供最合适的指令。
可用的信息来源包括:
- State(状态)
- Store(存储)
- Runtime Context(运行时上下文)
从 State 中访问消息数量或对话上下文
from langchain.agents import create_agent
from langchain.agents.middleware import dynamic_prompt, ModelRequest
@dynamic_prompt
def state_aware_prompt(request: ModelRequest) -> str:
# request.messages 是 request.state["messages"] 的快捷访问方式
message_count = len(request.messages)
base = "You are a helpful assistant."
if message_count > 10:
base += "\nThis is a long conversation - be extra concise."
return base
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[state_aware_prompt]
)
从长期记忆(Store)中访问用户偏好
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.agents.middleware import dynamic_prompt, ModelRequest
from langgraph.store.memory import InMemoryStore
@dataclass
class Context:
user_id: str
@dynamic_prompt
def store_aware_prompt(request: ModelRequest) -> str:
user_id = request.runtime.context.user_id
# 从 Store 中读取:获取用户偏好
store = request.runtime.store
user_prefs = store.get(("preferences",), user_id)
base = "You are a helpful assistant."
if user_prefs:
style = user_prefs.value.get("communication_style", "balanced")
base += f"\nUser prefers {style} responses."
return base
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[store_aware_prompt],
context_schema=Context,
store=InMemoryStore()
)
从运行时上下文(Runtime Context)中访问用户 ID 或配置信息
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.agents.middleware import dynamic_prompt, ModelRequest
@dataclass
class Context:
user_role: str
deployment_env: str
@dynamic_prompt
def context_aware_prompt(request: ModelRequest) -> str:
# 从 Runtime Context 中读取:用户角色与运行环境
user_role = request.runtime.context.user_role
env = request.runtime.context.deployment_env
base = "You are a helpful assistant."
if user_role == "admin":
base += "\nYou have admin access. You can perform all operations."
elif user_role == "viewer":
base += "\nYou have read-only access. Guide users to read operations only."
if env == "production":
base += "\nBe extra careful with any data modifications."
return base
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[context_aware_prompt],
context_schema=Context
)
消息(Messages)
消息组成了发送给 LLM 的提示(prompt)。管理好消息内容非常关键,以确保 LLM 拥有正确的信息来做出良好响应。
消息内容可以来源于 State(状态)、Store(存储) 或 Runtime Context(运行时上下文)。
从 State 中注入上传文件的上下文(Transient)
当当前查询相关时,可以将用户在本会话中上传的文件信息注入到消息中:
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from typing import Callable
@wrap_model_call
def inject_file_context(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""在本会话中注入用户上传文件的上下文。"""
# 从 State 中读取已上传文件的元数据
uploaded_files = request.state.get("uploaded_files", [])
if uploaded_files:
file_descriptions = [
f"- {file['name']} ({file['type']}): {file['summary']}"
for file in uploaded_files
]
file_context = f"""Files you have access to in this conversation:
{chr(10).join(file_descriptions)}
Reference these files when answering questions."""
# 在最近消息之前注入文件上下文
messages = [
*request.messages,
{"role": "user", "content": file_context},
]
request = request.override(messages=messages)
return handler(request)
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[inject_file_context]
)
临时 vs 持久消息更新
上述示例使用wrap_model_call做临时更新 —— 只修改单次调用发送给模型的消息,而不改变 State 中保存的内容。
若需持久更新(如 Life-cycle Context 示例中的摘要),应使用生命周期钩子(before_model或after_model)来永久修改对话历史。
从 Store 中注入用户邮件写作风格
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from typing import Callable
from langgraph.store.memory import InMemoryStore
@dataclass
class Context:
user_id: str
@wrap_model_call
def inject_writing_style(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""从 Store 注入用户的邮件写作风格。"""
user_id = request.runtime.context.user_id
store = request.runtime.store
writing_style = store.get(("writing_style",), user_id)
if writing_style:
style = writing_style.value
style_context = f"""Your writing style:
- Tone: {style.get('tone', 'professional')}
- Typical greeting: "{style.get('greeting', 'Hi')}"
- Typical sign-off: "{style.get('sign_off', 'Best')}"
- Example email you've written:
{style.get('example_email', '')}"""
# 附加到消息末尾 —— 模型会更关注最后的消息
messages = [
*request.messages,
{"role": "user", "content": style_context}
]
request = request.override(messages=messages)
return handler(request)
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[inject_writing_style],
context_schema=Context,
store=InMemoryStore()
)
从 Runtime Context 中注入合规规则,根据用户所在司法管辖区,注入相关合规约束:
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from typing import Callable
@dataclass
class Context:
user_jurisdiction: str
industry: str
compliance_frameworks: list[str]
@wrap_model_call
def inject_compliance_rules(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""从 Runtime Context 注入合规约束。"""
jurisdiction = request.runtime.context.user_jurisdiction
industry = request.runtime.context.industry
frameworks = request.runtime.context.compliance_frameworks
rules = []
if "GDPR" in frameworks:
rules.append("- Must obtain explicit consent before processing personal data")
rules.append("- Users have right to data deletion")
if "HIPAA" in frameworks:
rules.append("- Cannot share patient health information without authorization")
rules.append("- Must use secure, encrypted communication")
if industry == "finance":
rules.append("- Cannot provide financial advice without proper disclaimers")
if rules:
compliance_context = f"""Compliance requirements for {jurisdiction}:
{chr(10).join(rules)}"""
messages = [
*request.messages,
{"role": "user", "content": compliance_context}
]
request = request.override(messages=messages)
return handler(request)
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[inject_compliance_rules],
context_schema=Context
)
工具(Tools)
工具允许模型与数据库、API 以及外部系统交互。你如何定义和选择工具,会直接影响模型能否高效完成任务。
每个工具都需要明确的 名称、描述、参数名和参数描述。
这些不仅仅是元数据,它们指导模型何时以及如何使用该工具。
from langchain.tools import tool
@tool(parse_docstring=True)
def search_orders(
user_id: str,
status: str,
limit: int = 10
) -> str:
"""根据订单状态搜索用户订单。
当用户询问订单历史或想要查看订单状态时使用。
始终按照提供的状态过滤结果。
Args:
user_id: 用户的唯一标识
status: 订单状态:'pending'、'shipped' 或 'delivered'
limit: 返回结果的最大数量
"""
# 具体实现
pass
选择工具(Selecting tools)
并非每个工具都适用于所有场景。
- 工具过多可能让模型感到“信息过载”,增加错误率
- 工具过少会限制能力
动态工具选择(Dynamic tool selection) 会根据认证状态、用户权限、功能开关或对话阶段来调整可用工具集。
根据 State(状态)启用工具
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from typing import Callable
@wrap_model_call
def state_based_tools(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""根据会话 State 过滤工具。"""
state = request.state
is_authenticated = state.get("authenticated", False)
message_count = len(state["messages"])
# 仅在认证后启用敏感工具
if not is_authenticated:
tools = [t for t in request.tools if t.name.startswith("public_")]
request = request.override(tools=tools)
elif message_count < 5:
# 对话初期限制工具
tools = [t for t in request.tools if t.name != "advanced_search"]
request = request.override(tools=tools)
return handler(request)
agent = create_agent(
model="gpt-4o",
tools=[public_search, private_search, advanced_search],
middleware=[state_based_tools]
)
根据 Store(存储)中的用户偏好或功能开关过滤工具
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from typing import Callable
from langgraph.store.memory import InMemoryStore
@dataclass
class Context:
user_id: str
@wrap_model_call
def store_based_tools(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""根据 Store 中用户偏好过滤工具。"""
user_id = request.runtime.context.user_id
store = request.runtime.store
feature_flags = store.get(("features",), user_id)
if feature_flags:
enabled_features = feature_flags.value.get("enabled_tools", [])
tools = [t for t in request.tools if t.name in enabled_features]
request = request.override(tools=tools)
return handler(request)
agent = create_agent(
model="gpt-4o",
tools=[search_tool, analysis_tool, export_tool],
middleware=[store_based_tools],
context_schema=Context,
store=InMemoryStore()
)
根据 Runtime Context(运行时上下文)中的用户权限过滤工具
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from typing import Callable
@dataclass
class Context:
user_role: str
@wrap_model_call
def context_based_tools(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""根据 Runtime Context 中的用户权限过滤工具。"""
user_role = request.runtime.context.user_role
if user_role == "admin":
# 管理员可以使用所有工具
pass
elif user_role == "editor":
# 编辑者不能删除数据
tools = [t for t in request.tools if t.name != "delete_data"]
request = request.override(tools=tools)
else:
# 仅允许只读工具
tools = [t for t in request.tools if t.name.startswith("read_")]
request = request.override(tools=tools)
return handler(request)
agent = create_agent(
model="gpt-4o",
tools=[read_data, write_data, delete_data],
middleware=[context_based_tools],
context_schema=Context
)
模型(Model)
不同模型在能力、成本和上下文窗口(context window)上存在差异。为具体任务选择合适的模型非常重要,而且在 agent 执行过程中可能会需要动态调整。
模型选择可以依据 State(状态)、Store(存储) 或 Runtime Context(运行时上下文)。
根据 State 中的对话长度选择模型
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from langchain.chat_models import init_chat_model
from typing import Callable
# 在中间件外初始化模型
large_model = init_chat_model("claude-sonnet-4-5-20250929")
standard_model = init_chat_model("gpt-4o")
efficient_model = init_chat_model("gpt-4o-mini")
@wrap_model_call
def state_based_model(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""根据 State 中的对话长度选择模型。"""
message_count = len(request.messages) # request.messages 是 request.state["messages"] 的快捷方式
if message_count > 20:
model = large_model # 长对话使用大上下文窗口模型
elif message_count > 10:
model = standard_model # 中等对话
else:
model = efficient_model # 短对话使用轻量模型
request = request.override(model=model)
return handler(request)
agent = create_agent(
model="gpt-4o-mini",
tools=[...],
middleware=[state_based_model]
)
根据 Store 中的用户偏好选择模型
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from langchain.chat_models import init_chat_model
from typing import Callable
from langgraph.store.memory import InMemoryStore
@dataclass
class Context:
user_id: str
# 初始化可用模型
MODEL_MAP = {
"gpt-4o": init_chat_model("gpt-4o"),
"gpt-4o-mini": init_chat_model("gpt-4o-mini"),
"claude-sonnet": init_chat_model("claude-sonnet-4-5-20250929"),
}
@wrap_model_call
def store_based_model(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""根据 Store 中的用户偏好选择模型。"""
user_id = request.runtime.context.user_id
store = request.runtime.store
user_prefs = store.get(("preferences",), user_id)
if user_prefs:
preferred_model = user_prefs.value.get("preferred_model")
if preferred_model and preferred_model in MODEL_MAP:
request = request.override(model=MODEL_MAP[preferred_model])
return handler(request)
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[store_based_model],
context_schema=Context,
store=InMemoryStore()
)
根据 Runtime Context 中的成本等级或环境选择模型
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from langchain.chat_models import init_chat_model
from typing import Callable
@dataclass
class Context:
cost_tier: str
environment: str
# 初始化模型
premium_model = init_chat_model("claude-sonnet-4-5-20250929")
standard_model = init_chat_model("gpt-4o")
budget_model = init_chat_model("gpt-4o-mini")
@wrap_model_call
def context_based_model(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""根据 Runtime Context 中的成本等级和环境选择模型。"""
cost_tier = request.runtime.context.cost_tier
environment = request.runtime.context.environment
if environment == "production" and cost_tier == "premium":
model = premium_model # 生产环境高级用户使用最佳模型
elif cost_tier == "budget":
model = budget_model # 预算等级使用轻量模型
else:
model = standard_model # 标准等级使用标准模型
request = request.override(model=model)
return handler(request)
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[context_based_model],
context_schema=Context
)
响应格式(Response Format)
结构化输出可以将非结构化文本转换为经过验证的结构化数据。当需要提取特定字段或向下游系统返回数据时,自由文本(free-form text)通常不够用。
工作原理:提供一个响应格式的 schema 后,模型的最终输出将保证符合该 schema。Agent 会在模型/工具调用循环中执行,直到模型完成工具调用,然后将最终响应转换为指定格式。
使用 schema 定义来指导模型。字段名称、类型和描述明确指定输出应遵循的格式:
from pydantic import BaseModel, Field
class CustomerSupportTicket(BaseModel):
"""从客户消息中提取的结构化工单信息。"""
category: str = Field(
description="问题类别:'billing'(账单)、'technical'(技术)、'account'(账户)或 'product'(产品)"
)
priority: str = Field(
description="紧急程度:'low'、'medium'、'high' 或 'critical'"
)
summary: str = Field(
description="客户问题的一句话概述"
)
customer_sentiment: str = Field(
description="客户情绪:'frustrated'(沮丧)、'neutral'(中立)或 'satisfied'(满意)"
)
动态响应格式选择可根据用户偏好、对话阶段或角色调整 schema:
- 对话初期返回简洁格式
- 对话深入或复杂时返回详细格式
根据 State(状态)配置输出格式
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from pydantic import BaseModel, Field
from typing import Callable
class SimpleResponse(BaseModel):
"""对话初期的简洁响应。"""
answer: str = Field(description="简短回答")
class DetailedResponse(BaseModel):
"""对话深入时的详细响应。"""
answer: str = Field(description="详细回答")
reasoning: str = Field(description="推理说明")
confidence: float = Field(description="置信度 0-1")
@wrap_model_call
def state_based_output(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""根据 State 选择输出格式。"""
message_count = len(request.messages)
if message_count < 3:
request = request.override(response_format=SimpleResponse)
else:
request = request.override(response_format=DetailedResponse)
return handler(request)
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[state_based_output]
)
根据 Store(存储)中的用户偏好配置输出格式
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from pydantic import BaseModel, Field
from typing import Callable
from langgraph.store.memory import InMemoryStore
@dataclass
class Context:
user_id: str
class VerboseResponse(BaseModel):
"""详细响应,包含额外信息。"""
answer: str = Field(description="详细回答")
sources: list[str] = Field(description="使用的来源")
class ConciseResponse(BaseModel):
"""简洁响应。"""
answer: str = Field(description="简短回答")
@wrap_model_call
def store_based_output(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""根据 Store 中用户偏好选择输出格式。"""
user_id = request.runtime.context.user_id
store = request.runtime.store
user_prefs = store.get(("preferences",), user_id)
if user_prefs:
style = user_prefs.value.get("response_style", "concise")
if style == "verbose":
request = request.override(response_format=VerboseResponse)
else:
request = request.override(response_format=ConciseResponse)
return handler(request)
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[store_based_output],
context_schema=Context,
store=InMemoryStore()
)
根据 Runtime Context(运行时上下文)如用户角色或环境配置输出格式
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from pydantic import BaseModel, Field
from typing import Callable
@dataclass
class Context:
user_role: str
environment: str
class AdminResponse(BaseModel):
"""面向管理员的详细响应,包括技术细节。"""
answer: str = Field(description="回答")
debug_info: dict = Field(description="调试信息")
system_status: str = Field(description="系统状态")
class UserResponse(BaseModel):
"""普通用户的简洁响应。"""
answer: str = Field(description="回答")
@wrap_model_call
def context_based_output(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""根据 Runtime Context 选择输出格式。"""
user_role = request.runtime.context.user_role
environment = request.runtime.context.environment
if user_role == "admin" and environment == "production":
request = request.override(response_format=AdminResponse)
else:
request = request.override(response_format=UserResponse)
return handler(request)
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[context_based_output],
context_schema=Context
)
工具上下文(Tool Context)
工具(Tools)具有特殊性:它们既可以读取上下文,也可以写入上下文。
在最基本的场景中,当工具执行时,它会接收 LLM 的请求参数并返回工具消息。工具执行自己的操作并生成结果。工具还可以获取对模型重要的信息,使模型能够完成任务。
读取(Reads)
大多数实际工具不仅仅依赖 LLM 的参数,还需要:
- 数据库查询的用户 ID
- 外部服务的 API Key
- 当前会话状态等
工具从 State(状态)、Store(存储) 和 Runtime Context(运行时上下文) 中读取这些信息。
从 State 读取当前会话信息
from langchain.tools import tool, ToolRuntime
from langchain.agents import create_agent
@tool
def check_authentication(runtime: ToolRuntime) -> str:
"""检查用户是否已认证。"""
current_state = runtime.state
is_authenticated = current_state.get("authenticated", False)
return "User is authenticated" if is_authenticated else "User is not authenticated"
agent = create_agent(
model="gpt-4o",
tools=[check_authentication]
)
从 Store 读取持久化的用户偏好
from dataclasses import dataclass
from langchain.tools import tool, ToolRuntime
from langchain.agents import create_agent
from langgraph.store.memory import InMemoryStore
@dataclass
class Context:
user_id: str
@tool
def get_preference(preference_key: str, runtime: ToolRuntime[Context]) -> str:
"""从 Store 获取用户偏好。"""
user_id = runtime.context.user_id
store = runtime.store
existing_prefs = store.get(("preferences",), user_id)
if existing_prefs:
value = existing_prefs.value.get(preference_key)
return f"{preference_key}: {value}" if value else f"No preference set for {preference_key}"
return "No preferences found"
agent = create_agent(
model="gpt-4o",
tools=[get_preference],
context_schema=Context,
store=InMemoryStore()
)
从 Runtime Context 读取配置(如 API Key、用户 ID 等)
from dataclasses import dataclass
from langchain.tools import tool, ToolRuntime
from langchain.agents import create_agent
@dataclass
class Context:
user_id: str
api_key: str
db_connection: str
@tool
def fetch_user_data(query: str, runtime: ToolRuntime[Context]) -> str:
"""使用 Runtime Context 配置获取数据。"""
user_id = runtime.context.user_id
api_key = runtime.context.api_key
db_connection = runtime.context.db_connection
results = perform_database_query(db_connection, query, api_key)
return f"Found {len(results)} results for user {user_id}"
agent = create_agent(
model="gpt-4o",
tools=[fetch_user_data],
context_schema=Context
)
result = agent.invoke(
{"messages": [{"role": "user", "content": "Get my data"}]},
context=Context(
user_id="user_123",
api_key="sk-...",
db_connection="postgresql://..."
)
)
写入(Writes)
工具结果不仅可以直接返回给模型,还可以更新 Agent 的记忆,使未来步骤能够访问重要上下文。
写入 State 以追踪会话信息
from langchain.tools import tool, ToolRuntime
from langchain.agents import create_agent
from langgraph.types import Command
@tool
def authenticate_user(password: str, runtime: ToolRuntime) -> Command:
"""认证用户并更新 State。"""
if password == "correct":
return Command(update={"authenticated": True})
else:
return Command(update={"authenticated": False})
agent = create_agent(
model="gpt-4o",
tools=[authenticate_user]
)
写入 Store 以实现跨会话数据持久化
from dataclasses import dataclass
from langchain.tools import tool, ToolRuntime
from langchain.agents import create_agent
from langgraph.store.memory import InMemoryStore
@dataclass
class Context:
user_id: str
@tool
def save_preference(
preference_key: str,
preference_value: str,
runtime: ToolRuntime[Context]
) -> str:
"""将用户偏好保存到 Store。"""
user_id = runtime.context.user_id
# 读取已有偏好
store = runtime.store
existing_prefs = store.get(("preferences",), user_id)
# 与新偏好合并
prefs = existing_prefs.value if existing_prefs else {}
prefs[preference_key] = preference_value
# 写入 Store:保存更新后的偏好
store.put(("preferences",), user_id, prefs)
return f"已保存偏好: {preference_key} = {preference_value}"
agent = create_agent(
model="gpt-4o",
tools=[save_preference],
context_schema=Context,
store=InMemoryStore()
)
说明:
Store允许工具在不同会话间持久化数据。结合State、Store与Runtime Context,可以实现完整的上下文访问和管理。
生命周期上下文(Life-cycle Context)
生命周期上下文控制 核心 agent 步骤之间的操作,可用于跨切面处理,如:
- 对话摘要(summarization)
- 安全防护(guardrails)
- 日志记录(logging)
中间件(Middleware)是实现上下文工程的关键机制。它允许你在任意 agent 生命周期步骤中:
- 更新上下文 — 修改 State 或 Store,更新对话历史或保存洞察
- 跳转步骤 — 根据上下文决定跳过或重复某些步骤
示例:自动对话摘要
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[
SummarizationMiddleware(
model="gpt-4o-mini",
trigger={"tokens": 4000},
keep={"messages": 20},
),
],
)
功能说明:
- 当对话超过 token 限制时,中间件会自动调用 LLM 对旧消息进行摘要
- 用摘要消息替换旧消息(永久更新 State)
- 保留最近消息以保持上下文
最佳实践
- 从简单开始 — 使用静态提示和工具,按需添加动态功能
- 逐步测试 — 每次只添加一个上下文工程特性
- 监控性能 — 跟踪模型调用次数、Token 使用量和延迟
- 使用内置中间件 — 如
SummarizationMiddleware、LLMToolSelectorMiddleware - 文档化上下文策略 — 明确哪些上下文被传递及原因
- 理解瞬态 vs 持久 — 模型上下文变化为瞬态(每次调用),生命周期上下文变化持久保存在 State
人工干预(Human-in-the-Loop)
Human-in-the-Loop(HITL)中间件允许在代理工具调用时加入人工审查。当模型提出可能需要人工复核的操作(例如写文件或执行 SQL)时,中间件可以暂停执行,等待人工决策。
它通过检查每次工具调用是否符合可配置的策略来实现这一点。如果需要干预,中间件会发出中断信号暂停执行。图状态会使用 LangGraph 的持久化层保存,从而安全暂停并在稍后恢复执行。
人工决策会决定接下来的操作:可以直接批准(approve)、修改后执行(edit)、或拒绝并提供反馈(reject)。
中断决策类型
| 决策类型 | 描述 | 示例场景 |
|---|---|---|
| ✅ approve | 直接批准操作,按原样执行 | 发送草稿邮件 |
| ✏️ edit | 修改工具调用后执行 | 修改收件人后发送邮件 |
| ❌ reject | 拒绝工具调用,并在对话中添加说明 | 拒绝邮件草稿并说明如何修改 |
每个工具可用的决策类型取决于你在 interrupt_on 中配置的策略。当多个工具调用同时被暂停时,每个动作需要单独决策,且决策顺序必须与中断请求中动作出现的顺序一致。
编辑工具参数时应谨慎。对原始参数进行大幅修改可能导致模型重新评估策略,甚至多次执行工具或采取意外动作。
在创建代理时,将 HITL 中间件添加到代理的中间件列表中。
你需要配置一个工具动作到允许决策类型的映射。当工具调用匹配映射中的动作时,中间件会中断执行。
from langchain.agents import create_agent
from langchain.agents.middleware import HumanInTheLoopMiddleware
from langgraph.checkpoint.memory import InMemorySaver
agent = create_agent(
model="gpt-4o",
tools=[write_file_tool, execute_sql_tool, read_data_tool],
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
"write_file": True, # 所有决策(approve, edit, reject)允许
"execute_sql": {"allowed_decisions": ["approve", "reject"]}, # 不允许编辑
"read_data": False, # 安全操作,无需审批
},
description_prefix="Tool execution pending approval", # 中断消息前缀
),
],
checkpointer=InMemorySaver(), # HITL 需要检查点来处理中断
)
-
检查点配置:必须配置检查点以在中断间持久化图状态。生产环境中推荐使用持久化检查点(如
AsyncPostgresSaver),测试或原型可使用InMemorySaver。 -
执行调用:在调用代理时传入包含线程 ID 的配置,以将执行与对话线程关联。详细内容请参考 LangGraph 中断文档。
配置选项
-
interrupt_on(dict,必填)
工具名称到审批配置的映射。值可以是:True:中断并使用默认配置False:自动批准InterruptOnConfig对象
-
description_prefix(string,默认"Tool execution requires approval")
动作请求描述的前缀
InterruptOnConfig 可选项
-
allowed_decisions(list[string])
允许的决策列表:'approve'、'edit'或'reject' -
description(string 或 callable)
静态字符串或可调用函数,用于自定义描述
响应中断(Responding to Interrupts)
当你调用代理时,它会一直运行,直到完成或触发中断。
中断在工具调用匹配 interrupt_on 配置策略时触发。此时,调用结果会包含一个 __interrupt__ 字段,其中列出需要人工审查的操作。你可以将这些操作展示给审核人员,并在提供决策后恢复执行。
from langgraph.types import Command
# HITL 使用 LangGraph 的持久化层
config = {"configurable": {"thread_id": "some_id"}}
# 运行代理直到触发中断
result = agent.invoke(
{
"messages": [
{"role": "user", "content": "Delete old records from the database"}
]
},
config=config
)
# 查看中断请求详情
print(result['__interrupt__'])
输出示例:
[
Interrupt(
value={
'action_requests': [
{
'name': 'execute_sql',
'arguments': {'query': 'DELETE FROM records WHERE created_at < NOW() - INTERVAL \'30 days\';'},
'description': 'Tool execution pending approval\n\nTool: execute_sql\nArgs: {...}'
}
],
'review_configs': [
{
'action_name': 'execute_sql',
'allowed_decisions': ['approve', 'reject']
}
]
}
)
]
使用 approve 执行
agent.invoke(
Command(
resume={
"decisions": [{"type": "approve"}] # 按原样批准
}
),
config=config
)
使用 edit 修改执行,在执行前修改工具调用,提供新工具名和参数:
agent.invoke(
Command(
resume={
"decisions": [
{
"type": "edit",
"edited_action": {
"name": "new_tool_name",
"args": {"key1": "new_value", "key2": "original_value"},
}
}
]
}
),
config=config
)
注意:修改工具参数时应谨慎。大幅修改可能导致模型重新评估策略,多次执行工具或产生意外操作。
使用 reject 拒绝执行,拒绝工具调用并提供反馈,帮助代理理解原因和改进操作:
agent.invoke(
Command(
resume={
"decisions": [
{
"type": "reject",
"message": "No, this is wrong because ..., instead do this ..."
}
]
}
),
config=config
)
反馈会被添加到对话中,用于指导代理后续行为。
多个决策(Multiple Decisions)
当有多个操作同时需要人工审查时,需要按照它们在中断请求中出现的顺序,为每个操作提供决策:
{
"decisions": [
{"type": "approve"},
{
"type": "edit",
"edited_action": {
"name": "tool_name",
"args": {"param": "new_value"}
}
},
{
"type": "reject",
"message": "This action is not allowed"
}
]
}
- approve:批准该操作按原样执行
- edit:修改操作后执行,需提供新的工具名和参数
- reject:拒绝操作,并提供说明信息
带有人类介入的流式处理(Streaming with Human-in-the-Loop)
你可以使用 stream() 方法代替 invoke(),在代理运行并处理中断时获取实时更新。使用 stream_mode=['updates', 'messages'] 可以同时流式传输代理进度和 LLM 的 token。
from langgraph.types import Command
config = {"configurable": {"thread_id": "some_id"}}
# 流式传输代理进度和 LLM token,直到触发中断
for mode, chunk in agent.stream(
{"messages": [{"role": "user", "content": "Delete old records from the database"}]},
config=config,
stream_mode=["updates", "messages"],
):
if mode == "messages":
# LLM token
token, metadata = chunk
if token.content:
print(token.content, end="", flush=True)
elif mode == "updates":
# 检查是否有中断
if "__interrupt__" in chunk:
print(f"\n\nInterrupt: {chunk['__interrupt__']}")
在人工决策后,可继续使用流式处理恢复执行:
# 根据人工决策恢复流式处理
for mode, chunk in agent.stream(
Command(resume={"decisions": [{"type": "approve"}]}),
config=config,
stream_mode=["updates", "messages"],
):
if mode == "messages":
token, metadata = chunk
if token.content:
print(token.content, end="", flush=True)
执行生命周期(Execution Lifecycle)
中间件定义了 after_model 钩子,在模型生成响应后但工具调用执行前运行:
- 代理调用模型生成响应。
- 中间件检查响应中是否有工具调用。
- 如果某些调用需要人工输入,中间件会构建
HITLRequest,包含action_requests和review_configs,并触发interrupt。 - 代理等待人工决策。
- 根据
HITLResponse的决策,中间件执行已批准或已编辑的调用,为被拒绝的调用合成ToolMessage,然后恢复执行。
自定义 HITL 逻辑(Custom HITL Logic)
对于更复杂的工作流,可以直接使用 interrupt 原语和中间件抽象来构建自定义 HITL 逻辑。
多代理系统(Multi-agent)
多代理系统将复杂应用拆分为多个专业化的代理(agents),它们协作解决问题。与依赖单一代理处理每一步不同,多代理架构允许你将小型、专注的代理组合成协调的工作流。
多代理系统适用场景:
- 单一代理拥有过多工具,导致无法合理选择使用哪个工具。
- 上下文或记忆量过大,单个代理无法有效跟踪。
- 任务需要专业化(例如:规划者、研究者、数学专家)。
多代理模式(Multi-agent Patterns)
| 模式 | 工作原理 | 控制流 | 示例用例 |
|---|---|---|---|
| 工具调用(Tool Calling) | 主管代理调用其他代理作为工具。“工具”代理不直接与用户交互,只执行任务并返回结果。 | 集中式:所有路由通过调用代理。 | 任务编排、结构化工作流 |
| 交接(Handoffs) | 当前代理决定将控制权转交给另一代理。活跃代理发生变化,用户可以直接与新代理继续交互。 | 去中心化:代理可以改变谁是活跃代理。 | 多领域对话、专家接管 |
选择模式(Choosing a Pattern)
| 问题 | 工具调用 | 交接 |
|---|---|---|
| 需要对工作流进行集中控制? | ✅ 是 | ❌ 否 |
| 希望代理直接与用户交互? | ❌ 否 | ✅ 是 |
| 专家间复杂的人类式对话? | ❌ 有限 | ✅ 强 |
两种模式可以混合使用——使用交接实现代理切换,每个代理也可以调用子代理作为工具来完成专业化任务。
自定义代理上下文(Customizing Agent Context)
多代理设计的核心是上下文工程(context engineering)——决定每个代理可以看到哪些信息。LangChain 提供了精细控制能力:
- 决定哪些对话或状态部分传递给每个代理
- 为子代理定制专门的提示(prompts)
- 决定是否包含中间推理过程
- 为每个代理自定义输入/输出格式
系统质量在很大程度上依赖于上下文工程。目标是确保每个代理能够访问执行任务所需的正确数据,无论它是作为工具运行,还是作为活跃代理参与任务。
工具调用(Tool Calling)
在工具调用模式下,一个代理(称为“控制器”)将其他代理视为可在需要时调用的工具。控制器负责整体编排,而工具代理执行特定任务并返回结果。
- 控制器接收输入,并决定调用哪个工具(子代理)。
- 工具代理根据控制器的指令执行任务。
- 工具代理将结果返回给控制器。
- 控制器决定下一步操作或完成任务。
用作工具的代理通常不与用户继续对话,它们的职责是执行任务并将结果返回给控制器代理。如果需要子代理能够与用户对话,应使用“交接(Handoffs)”模式。
实现(Implementation)
下面是一个最小示例,主代理通过工具定义访问单个子代理:
from langchain.tools import tool
from langchain.agents import create_agent
subagent1 = create_agent(model="...", tools=[...])
@tool(
"subagent1_name",
description="subagent1_description"
)
def call_subagent1(query: str):
result = subagent1.invoke({
"messages": [{"role": "user", "content": query}]
})
return result["messages"][-1].content
agent = create_agent(model="...", tools=[call_subagent1])
在这个模式下:
- 主代理在任务匹配子代理描述时调用
call_subagent1。 - 子代理独立运行并返回结果。
- 主代理接收结果并继续编排。
可自定义点(Where to customize)
- 子代理名称 (
"subagent1_name"):主代理引用子代理的名称,影响提示生成(prompt),需谨慎命名。 - 子代理描述 (
"subagent1_description"):主代理对该子代理的“认知”,直接影响何时调用它。 - 输入给子代理:可以定制输入,使子代理更准确地理解任务。示例中直接传递代理生成的查询。
- 子代理输出:返回给主代理的响应,可以调整返回内容,以控制主代理如何解析结果。示例中返回最后一条消息文本,也可返回额外状态或元数据。
控制传给子代理的输入(Control the input)
两种主要方式:
- 修改提示(Modify the prompt):调整主代理的提示或工具元数据(子代理名称和描述),以指导何时以及如何调用子代理。
- 上下文注入(Context injection):通过调整工具调用,从主代理状态中添加不适合放在静态提示中的输入(如完整消息历史、先前结果、任务元数据)。
示例:
from langchain.agents import AgentState
from langchain.tools import tool, ToolRuntime
class CustomState(AgentState):
example_state_key: str
@tool(
"subagent1_name",
description="subagent1_description"
)
def call_subagent1(query: str, runtime: ToolRuntime[None, CustomState]):
subagent_input = some_logic(query, runtime.state["messages"])
result = subagent1.invoke({
"messages": subagent_input,
"example_state_key": runtime.state["example_state_key"]
})
return result["messages"][-1].content
控制子代理输出(Control the output)
两种常见策略:
-
修改提示(Modify the prompt):优化子代理的提示,使其准确返回所需内容。
- 当输出不完整、冗长或缺少关键细节时使用。
- 避免子代理执行工具调用或推理后未包含结果在最终消息中。
-
自定义输出格式(Custom output formatting):在返回主代理前,通过代码调整或丰富子代理响应。
- 示例:除了最终文本,还返回特定状态键。
- 需要将结果包装在
Command中,以便合并自定义状态与子代理响应。
示例:
from typing import Annotated
from langchain.agents import AgentState
from langchain.tools import InjectedToolCallId
from langgraph.types import Command, ToolMessage
@tool(
"subagent1_name",
description="subagent1_description"
)
def call_subagent1(
query: str,
tool_call_id: Annotated[str, InjectedToolCallId],
) -> Command:
result = subagent1.invoke({
"messages": [{"role": "user", "content": query}]
})
return Command(update={
"example_state_key": result["example_state_key"],
"messages": [
ToolMessage(
content=result["messages"][-1].content,
tool_call_id=tool_call_id
)
]
})
tool_call_id用于匹配正确的工具调用。- 返回
Command可包含比最终工具调用更多的信息,包括状态或元数据。
交接(Handoffs)
在交接模式下,代理可以直接将控制权传递给其他代理。此时“活跃”代理会发生变化,用户将与当前拥有控制权的代理直接交互。
- 当前代理判断自己需要另一个代理的帮助。
- 它将控制权(及状态)传递给下一个代理。
- 新的代理直接与用户交互,直到它再次决定交接或完成任务。
检索(Retrieval)
大语言模型(LLM)非常强大,但存在两个主要局限:
- 有限上下文 — 无法一次性处理整个语料库。
- 静态知识 — 训练数据在某个时间点被冻结,无法反映最新信息。
检索通过在查询时获取相关的外部知识来解决这些问题。这也是**检索增强生成(RAG, Retrieval-Augmented Generation)**的基础:使用上下文相关的信息增强 LLM 的回答。
从检索到 RAG
检索让 LLM 在运行时访问相关上下文。但大多数实际应用进一步将检索与生成结合,产生有依据的、上下文感知的回答。这正是 RAG 的核心思想:检索管道成为结合搜索与生成的系统基础。
典型工作流程如下:
- 数据源(Google Drive、Slack、Notion 等)
- 文档加载器 → 获取文档
- 文档切分 → 分块处理
- 生成嵌入 → 转换为向量
- 向量存储 → 存储与检索
- 用户查询 → 转换为查询嵌入
- 检索器 → 获取相关文档
- LLM 使用检索信息生成回答
每个组件都是模块化的,可替换加载器、分块器、嵌入模型或向量存储,而无需重写应用逻辑。
构建模块(Building Blocks)
- 文档加载器:从外部来源(Google Drive、Slack、Notion 等)获取数据,返回标准化的 Document 对象。
- 文本切分器:将大型文档拆分成更小的块,以便单独检索并适配模型上下文窗口。
- 嵌入模型:将文本转换为向量,使语义相似的文本在向量空间中靠近。
- 向量存储:专门存储和检索嵌入向量的数据库。
- 检索器:给定非结构化查询返回文档的接口。
RAG 架构(RAG Architectures)
| 架构 | 描述 | 控制 | 灵活性 | 延迟 | 示例用例 |
|---|---|---|---|---|---|
| 2-Step RAG | 检索始终发生在生成之前,简单且可预测 | ✅ 高 | ❌ 低 | ⚡ 快 | FAQ、文档机器人 |
| Agentic RAG | LLM 代理在推理过程中决定何时以及如何检索 | ❌ 低 | ✅ 高 | ⏳ 可变 | 访问多工具的研究助手 |
| Hybrid | 结合两者特性并增加验证步骤 | ⚖️ 中 | ⚖️ 中 | ⏳ 可变 | 领域特定问答与质量验证 |
延迟说明:
- 在 2-Step RAG 中,延迟较可预测,因为 LLM 调用次数已知并有限制。
- 实际延迟还可能受到检索步骤性能影响(如 API 响应时间、网络延迟或数据库查询),具体取决于使用的工具和基础设施。
2-Step RAG(两步检索增强生成)
在 2-Step RAG 中,检索步骤始终在生成步骤之前执行。该架构简单且可预测,非常适合在明确需要检索相关文档才能生成答案的应用场景中使用。
流程示意:
- 用户提出问题
- 检索相关文档
- 根据检索结果生成答案
- 将答案返回给用户
Agentic RAG(代理式检索增强生成)
Agentic RAG 将 RAG 与基于代理的推理结合。与 2-Step RAG 不同,代理在生成答案时按步骤推理,并决定何时以及如何检索信息。
- 代理需要的唯一条件是可以访问一个或多个获取外部知识的工具,如文档加载器、Web API 或数据库查询。
流程示意:
- 用户输入/问题
- LLM 代理判断是否需要外部信息
- 使用工具进行搜索
- 判断检索结果是否足够回答
- 生成最终答案
- 返回给用户
示例代码:
import requests
from langchain.tools import tool
from langchain.chat_models import init_chat_model
from langchain.agents import create_agent
@tool
def fetch_url(url: str) -> str:
"""从 URL 获取文本内容"""
response = requests.get(url, timeout=10.0)
response.raise_for_status()
return response.text
system_prompt = """\
当需要从网页获取信息时使用 fetch_url;引用相关片段。
"""
agent = create_agent(
model="claude-sonnet-4-5-20250929",
tools=[fetch_url], # 检索工具
system_prompt=system_prompt,
)
Hybrid RAG(混合型 RAG)
Hybrid RAG 结合了 2-Step 和 Agentic RAG 的特性,引入中间步骤,如查询预处理、检索验证和生成后检查。该系统比固定流水线更灵活,同时保留对执行的部分控制。
典型组件:
- 查询增强:修改输入问题以提高检索质量,如改写不清楚的问题、生成多个变体或扩展上下文。
- 检索验证:评估检索文档是否相关且充分,如不足,则优化查询重新检索。
- 答案验证:检查生成答案的准确性、完整性及与源内容的一致性,如有需要可重新生成或修订答案。
流程示意:
- 用户提出问题
- 查询增强
- 检索文档
- 判断信息是否充分
- 优化查询(如必要)
- 生成答案
- 检查答案质量
- 尝试不同方法(如需要)
- 返回最佳答案给用户
适用场景:
- 查询模糊或信息不足的应用
- 需要验证或质量控制的系统
- 涉及多来源或迭代优化的工作流
长期记忆(Long-term memory)
LangChain 代理使用 LangGraph 持久化 来实现长期记忆。这是一个高级主题,需要对 LangGraph 有一定了解才能使用。
记忆存储
LangGraph 将长期记忆存储为 JSON 文档,每条记忆都组织在自定义 命名空间(类似文件夹)和唯一 键(类似文件名)下。命名空间通常包含用户或组织 ID 或其他标签,以便更好地组织信息。
这种结构支持层级化组织记忆,并可通过内容过滤实现跨命名空间搜索。
from langgraph.store.memory import InMemoryStore
def embed(texts: list[str]) -> list[list[float]]:
# 用实际 embedding 函数或 LangChain embedding 对象替换
return [[1.0, 2.0] * len(texts)]
# InMemoryStore 保存数据到内存字典,生产环境使用数据库支持的存储
store = InMemoryStore(index={"embed": embed, "dims": 2})
user_id = "my-user"
application_context = "chitchat"
namespace = (user_id, application_context)
store.put(
namespace,
"a-memory",
{
"rules": [
"User likes short, direct language",
"User only speaks English & python",
],
"my-key": "my-value",
},
)
# 按 ID 获取记忆
item = store.get(namespace, "a-memory")
# 在命名空间内搜索记忆,按向量相似度排序
items = store.search(
namespace, filter={"my-key": "my-value"}, query="language preferences"
)
在工具中读取长期记忆
代理可以通过工具查找用户信息。
from dataclasses import dataclass
from langchain_core.runnables import RunnableConfig
from langchain.agents import create_agent
from langchain.tools import tool, ToolRuntime
from langgraph.store.memory import InMemoryStore
@dataclass
class Context:
user_id: str
store = InMemoryStore() # 生产环境使用数据库支持的存储
# 写入示例数据
store.put(
("users",),
"user_123",
{"name": "John Smith", "language": "English"}
)
@tool
def get_user_info(runtime: ToolRuntime[Context]) -> str:
"""查找用户信息"""
store = runtime.store
user_id = runtime.context.user_id
user_info = store.get(("users",), user_id)
return str(user_info.value) if user_info else "Unknown user"
agent = create_agent(
model="claude-sonnet-4-5-20250929",
tools=[get_user_info],
store=store,
context_schema=Context
)
# 运行代理
agent.invoke(
{"messages": [{"role": "user", "content": "look up user information"}]},
context=Context(user_id="user_123")
)
在工具中写入长期记忆
示例:代理更新用户信息的工具。
from dataclasses import dataclass
from typing_extensions import TypedDict
from langchain.agents import create_agent
from langchain.tools import tool, ToolRuntime
from langgraph.store.memory import InMemoryStore
store = InMemoryStore() # 生产环境使用数据库支持的存储
@dataclass
class Context:
user_id: str
class UserInfo(TypedDict):
name: str
@tool
def save_user_info(user_info: UserInfo, runtime: ToolRuntime[Context]) -> str:
"""保存用户信息"""
store = runtime.store
user_id = runtime.context.user_id
store.put(("users",), user_id, user_info)
return "Successfully saved user info."
agent = create_agent(
model="claude-sonnet-4-5-20250929",
tools=[save_user_info],
store=store,
context_schema=Context
)
# 运行代理,更新用户信息
agent.invoke(
{"messages": [{"role": "user", "content": "My name is John Smith"}]},
context=Context(user_id="user_123")
)
# 直接从存储中获取更新后的值
store.get(("users",), "user_123").value
总结
总结来说,写完这篇博客,我对 LangChain v1.0 的感受越来越清晰:如果说 v0.3.x 是在 langchain-core 的基础上做了一层 SDK 抽象,让开发者能够快速搭建自己的 agent,那么 v1.0 的方向似乎完全偏离了初衷。在 v1.0 中,langchain-core 和 langgraph 上的“抽象+抽象”堆叠出来的模块,复杂、命名混乱、内部充斥魔法字符串,让人很难把握全局。
其实,一个 agent 的本质非常简单:你只需要一个大模型实例、一些工具调用逻辑、用户上下文管理,以及短期/长期记忆的拼接而已。完全可以基于 openai 库或者其他模型库自己实现,完全掌控流程。可 v1.0 引入的那些层层抽象和职责重叠的模块,并没有降低开发成本,反而增加了学习曲线和开发周期,这和一个优秀框架“事半功倍”的初衷背道而驰。
从最近几个月参与的开发者大会来看,大家对 LangChain 的评价普遍不高,但对 LangGraph 则相对正面。一些公司甚至直接选择用 LangGraph 自己实现 agent 功能,而完全绕过 LangChain 的工具集。这也印证了一个事实:框架应该服务于开发者,而不是让开发者为理解框架本身付出过多代价。


















 616
616


 到【灌水乐园】发言
到【灌水乐园】发言










