




 CAP理论指出分布式系统无法同时保证一致性、可用性和分区容错性。大多数互联网应用倾向于保证可用性和分区容错性,牺牲一致性。BASE理论则提出了基本可用、软状态和最终一致性,作为对CAP的补充。在实际应用中,ACID(强一致性)和BASE(最终一致性)常根据场景需求进行结合选择。
CAP理论指出分布式系统无法同时保证一致性、可用性和分区容错性。大多数互联网应用倾向于保证可用性和分区容错性,牺牲一致性。BASE理论则提出了基本可用、软状态和最终一致性,作为对CAP的补充。在实际应用中,ACID(强一致性)和BASE(最终一致性)常根据场景需求进行结合选择。
目录
CAP 定理
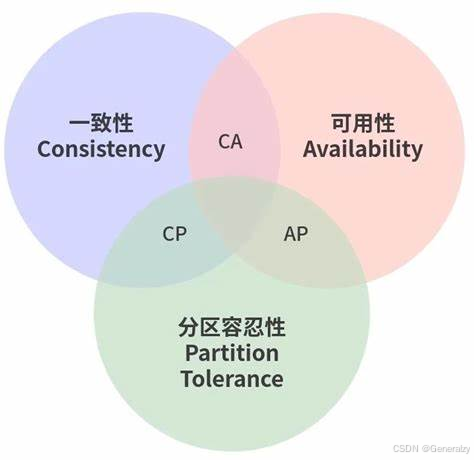
CAP 理论为:一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
-
一致性(Consistency)
一致性指 “all nodes see the same data at the same time”,即更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致。(所有节点在同一时间看到的数据是相同的。当数据被写入时,所有对该数据的读操作都会返回相同的结果。) -
可用性(Availability)
可用性指“Reads and writes always succeed”,即服务一直可用,而且是正常响应时间。(每个请求都会获得响应,无论成功或失败。系统不会挂起或超时。) -
分区容错性(Partition tolerance)
分区容错性指“the system continues to operate despite arbitrary message loss or failure of part of the system”,即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。(即使网络分区发生,系统依然能够继续运行。网络分区指的是分布式系统中的部分节点之间的通信被中断。)
为什么CAP不可兼得呢?
在实际的分布式系统中,网络分区(Partition)往往是不可避免的。当网络分区发生时,系统中的某些节点无法相互通信。这时,系统需要在“一致性”和“可用性”之间做出权衡:
如果保持一致性(C),系统必须确保所有节点的数据是相同的。这意味着在网络分区期间,如果某些节点无法达成一致,则可能需要暂停某些操作,导致系统部分不可用(A)。
如果保持可用性(A),系统会允许每个节点独立地响应请求,即使在网络分区时。但这可能会导致不同节点上的数据不一致(C)。
因此,CAP理论指出,在出现网络分区(P)时,你必须在一致性(C)和可用性(A)之间选择其中之一,而无法同时保证两者。
所以该问题就等价于:为什么无法同时保证一致性和可用性?
如果要牺牲分区容错性,就得把服务和资源放到一个机器,或者一个“同生共死”的集群,那就违背了分布式的初衷。
那么满足分区容错的基础上,能不能同时满足一致性和可用性?
-
假设优先保证一致性(C)
- 假设有两个节点 N1 和 N2。当我们向 N1 写入数据时,为了确保全局一致性,必须让 N2 的读写操作暂时“冻结”。
- 只有当 N1 完成数据同步至 N2 后,N2 才能恢复处理读写请求。在此期间,客户端针对 N2 的请求要么会收到失败响应,要么会因等待超时而得不到及时反馈。
- 这意味着,在追求强一致性的过程中,N2 的可用性不可避免地受到了影响,因为它无法始终如一地对所有请求提供即时响应。
-
假设优先保证可用性(A)
-
这次,我们不让 N2 的读写操作暂停。即使 N1 正在进行数据写入,N2 也继续处理客户端的请求。但这样一来,N2 可能会基于过时数据作出响应,导致客户端接收到与全局最新状态不一致的结果。
-
显然,这种情况下,虽然我们保证了 N2 的高可用性(即对所有请求都有响应),却牺牲了数据的一致性。
-
综上所述,在分布式系统的设计中,由于分区容错性的必然存在,我们无法同时确保一致性和可用性达到理想状态。二者就像是天平的两端,提升一方就意味着另一方的妥协。要根据实际业务需求和容忍度来决定在 CAP 三要素中如何取舍。
为什么“在实际的分布式系统中,网络分区(Partition)往往是不可避免的。”?
网络分区(Partition)在实际的分布式系统中往往不可避免,主要是因为分布式系统本质上依赖于多个独立的计算机(或节点)通过网络进行通信,而网络本身并不是完全可靠的。以下是网络分区不可避免的一些原因:
-
物理硬件的局限性
- 网络设备故障:路由器、交换机或网卡等网络设备可能发生故障,导致节点之间的通信中断。这是硬件层面常见的问题。
- 硬件连接问题:断电、线缆损坏、配置错误等问题都可能引发网络分区,使得系统中的某些节点无法相互通信。
-
网络的不可预测性
- 网络拥塞:即使网络设备没有故障,网络拥塞也会导致数据包丢失或延迟,进而引发网络分区。特别是在大规模、跨地域的分布式系统中,网络连接的性能难以完全保证。
- 网络延迟:在分布式系统中,节点可能位于不同的地理位置,不同网络之间的传输延迟、抖动都会导致通信不稳定,可能在某些时刻看起来像分区问题。
-
地理分布
- 地理分散性:许多现代分布式系统是全球分布的,节点可能分布在不同的国家或地区。这使得节点之间的通信依赖于跨洲际的互联网连接,而这些跨国网络路径更加容易受到中断、延迟等问题的影响。
- 海底电缆故障:国际数据传输通常依赖海底光缆,这些光缆偶尔会受到地震、船锚、施工等原因的损坏,导致跨国或跨区域的通信中断。
-
软件层问题
- 分布式系统中的软件Bug:有时候软件问题或配置错误可能导致某些节点无法正确响应其他节点的请求,模拟出类似网络分区的效果。
- 安全问题:防火墙或安全策略的误配置也会导致网络分区,阻止节点之间的正常通信。
-
故障不可预测性
- 局部故障的传播:在一个分布式系统中,局部的小故障可能会逐渐影响到整个系统,导致局部的节点无法正常与其他节点通信。比如一个网络节点的过载或故障可能会导致其后续节点也受到影响,出现局部分区。
- 不确定性(网络波动):分布式系统的规模越大,遇到网络不稳定的概率就越大。即便在小规模系统中,网络传输的偶发性问题也是现实中的一部分,这种不确定性使得网络分区变得难以完全避免。
-
经济与成本的权衡
- 冗余设计成本高昂:虽然可以通过增加网络冗余或提高网络设备的可靠性来减少分区的可能性,但这往往伴随高昂的成本,尤其是在全球范围内部署分布式系统时。因此,分布式系统的设计者通常会权衡成本与性能之间的平衡,而不是试图彻底消除网络分区。
-
总结
在一个广泛分布的、跨多个节点和区域的系统中,网络连接的中断和不稳定是现实问题。即使我们可以通过各种手段降低网络分区的概率,但我们无法完全消除网络分区,因为网络本身具有不确定性和复杂性。这使得在设计分布式系统时,网络分区必须被视为系统不可避免的一部分,并相应地在系统中做出容错设计(即分区容忍性)。
CAP 权衡
对于多数大型互联网应用的场景,主机众多、部署分散,而且现在的集群规模越来越大,所以节点故障、网络故障是常态,而且要保证服务可用性达到 N 个 9,即保证 P 和 A,舍弃C(退而求其次保证最终一致性)。虽然某些地方会影响客户体验,但没达到造成用户流程的严重程度。
对于涉及到钱财这样不能有一丝让步的场景,C 必须保证。网络发生故障宁可停止服务,这是保证 CA,舍弃 P。貌似这几年国内银行业发生了不下 10 起事故,但影响面不大,报到也不多,广大群众知道的少。还有一种是保证 CP,舍弃 A。例如网络故障是只读不写。
孰优孰略,没有定论,只能根据场景定夺,适合的才是最好的。
CAP对应的模型及应用
CP(没A)
放弃A(可用性),相当于每个请求都需要在Server之间强一致,而P(分区)会导致同步时间无限延长,如此CP也是可以保证的。很多传统的数据库分布式事务都属于这种模式。
CP模型的常见应用:
- 分布式数据库
- 分布式锁
AP(没C)
要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。现在众多的NoSQL都属于此类。
AP模型常见应用:
- Web缓存
- DNS
像一些知名的注册中心ZooKeeper、Eureka、Nacos中:
- ZooKeeper 保证的是 CP
- Eureka 保证的则是 AP
- Nacos 不仅支持 CP 也支持 AP
BA-SE 理论
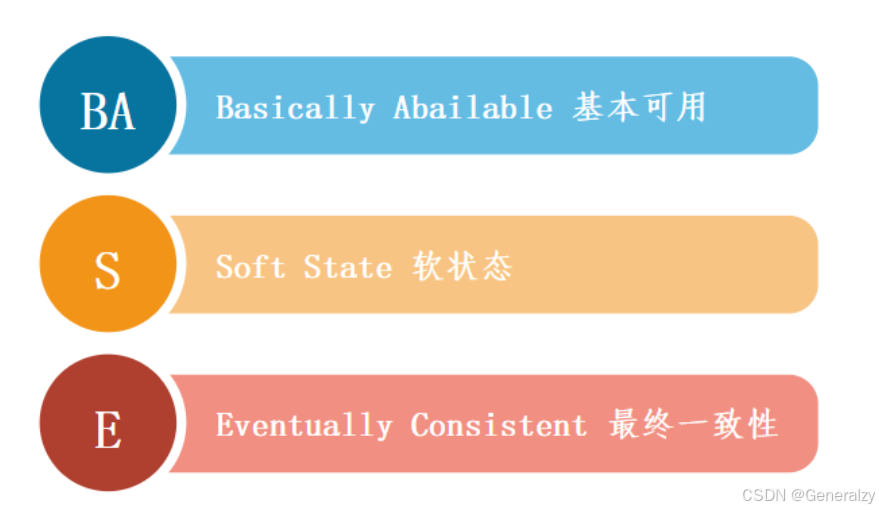
BASE理论是对CAP理论的一种扩展和补充,特别是在AP系统(优先保证可用性和分区容忍性,可能牺牲一致性)中的应用。BASE理论是由大型互联网公司和分布式数据库系统的实际应用中总结出来的,适用于那些无法严格保证CAP中“一致性”的场景。BASE理论提出了一个与ACID模型(用于传统关系数据库)相对的思路,以应对分布式系统中的一致性和可用性问题。
核心思想是即使无法做到强一致性(Strong Consistency,CAP 的一致性就是强一致性),但应用可以采用适合的方式达到最终一致性(Eventual Consitency)。
-
基本可用(Basically Available)
基本可用是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。(系统保证在大部分情况下可用,但并不要求系统在所有情况下都能完全可用。即便出现部分故障,系统也应该能够提供一些退化后的服务。例如,当某个节点不可用时,系统仍然可以响应请求,但可能响应延迟增加,或者返回部分数据。)电商大促时,为了应对访问量激增,部分用户可能会被引导到降级页面,服务层也可能只提供降级服务。这就是损失部分可用性的体现。
-
软状态(Soft State)
软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据至少会有三个副本,允许不同节点间副本同步的延时就是软状态的体现。mysql replication 的异步复制也是一种体现。(系统允许存在中间状态,这些状态不一定是立即一致的。在分布式系统中,状态可能会随着时间而逐渐趋于一致。这意味着系统中的数据副本可能会有一段时间保持不一致,系统并不会立即强制达到一致性。) -
最终一致性(Eventual Consistency)
最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。(系统不会强制在任意时刻都保持严格一致性,但保证在不发生新的数据更新的情况下,系统中的所有副本最终会趋于一致。这是BASE理论的核心思想,系统可以在一定的时间内接受数据的不一致,但会通过一定的机制最终达到一致状态。)
BASE 理论与 CAP 理论的关系/ACID 和 BASE 的区别与联系
CAP理论告诉我们,在网络分区(P)发生时,必须在一致性(C)和可用性(A)之间做出权衡。BASE理论实际上是对CAP理论中“可用性优先”(AP系统)的进一步发展,它不追求严格的强一致性,而是允许系统在短暂时间内出现不一致的状态,只要最终能够达成一致即可。
BASE理论的核心思想是:弱一致性 + 最终一致性 + 高可用性。这与ACID理论形成鲜明对比:
ACID(Atomicity、Consistency、Isolation、Durability)是传统数据库中的事务处理原则,强调严格的强一致性和隔离性,适用于单机或集群中的事务。
BASE 更适合于大规模分布式系统,允许在一定时间内牺牲一致性以换取系统的高可用性和容错性。BASE通过放宽对一致性的要求,利用“最终一致性”来弥补一致性和可用性之间的冲突。
ACID 和 BASE 代表了两种截然相反的设计哲学,在分布式系统设计的场景中,系统组件对一致性要求是不同的,因此 ACID 和 BASE 又会结合使用。
BASE 理论的应用场景
BASE理论在一些互联网大规模分布式系统中非常普遍,尤其是在需要处理海量数据并且要求高可用性的场景下。这类系统通常追求系统的高可用性和良好的用户体验,允许短时间内的暂时不一致。比如:
- 分布式数据库:如Cassandra、DynamoDB等,追求高可用性和最终一致性。
- 消息队列系统:如Kafka、RabbitMQ等,处理海量数据时会利用最终一致性来确保消息传递。
- 社交网络:如微博、Twitter等,用户的状态和帖子在不同节点上可能暂时不同步,但最终所有副本会趋于一致。


















 772
772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











