




转载请注明出处:http://blog.youkuaiyun.com/gamer_gyt
博主微博:http://weibo.com/234654758
Github:https://github.com/thinkgamer
公众号:搜索与推荐Wiki
个人网站:http://thinkgamer.github.io
本文分为四部分介绍机器学习在微博信息流中的应用实践,分别为:微博信息流推荐场景介绍,内容理解与用户画像,大规模推荐系统实践和总结展望。
微博信息流推荐场景介绍
微博的feed流内容形态各异,有视频,图片,文字,长文,问答等,其用户量也很大,2018年Q2统计DAU(日活)为1.9亿,MAU(月活)为4.3亿,这么庞大的用户量,如何做好首页feed流的个性化推荐就显得格外重要。

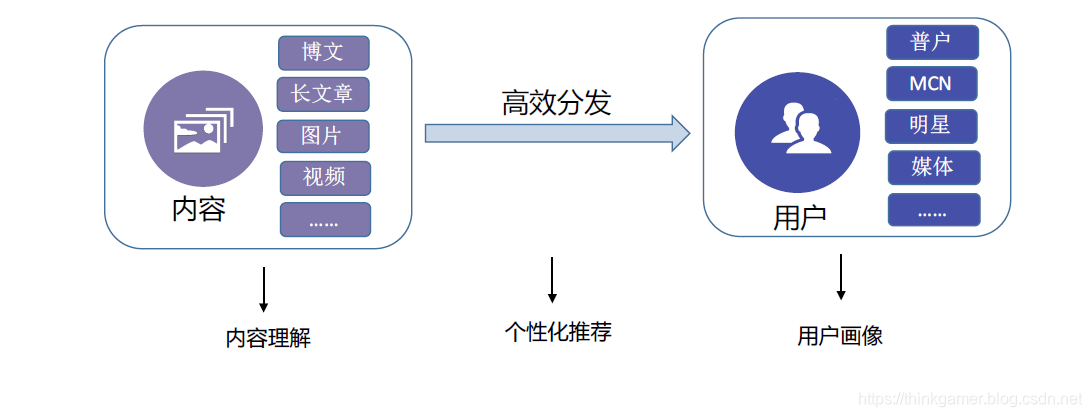
内容理解与用户画像
由于个性化推荐是给用户推荐其感兴趣的内容,所以对于微博的内容理解和用户画像部分就显得格外重要。
内容理解即通过文本内容理解和视觉理解技术,对微博内容进行细粒度表征,即形成每篇微博内容的表征向量。
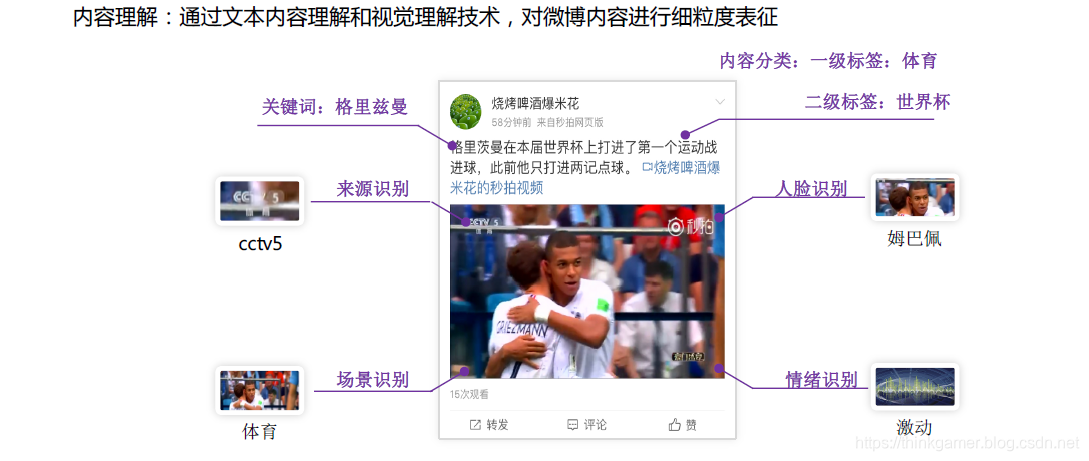
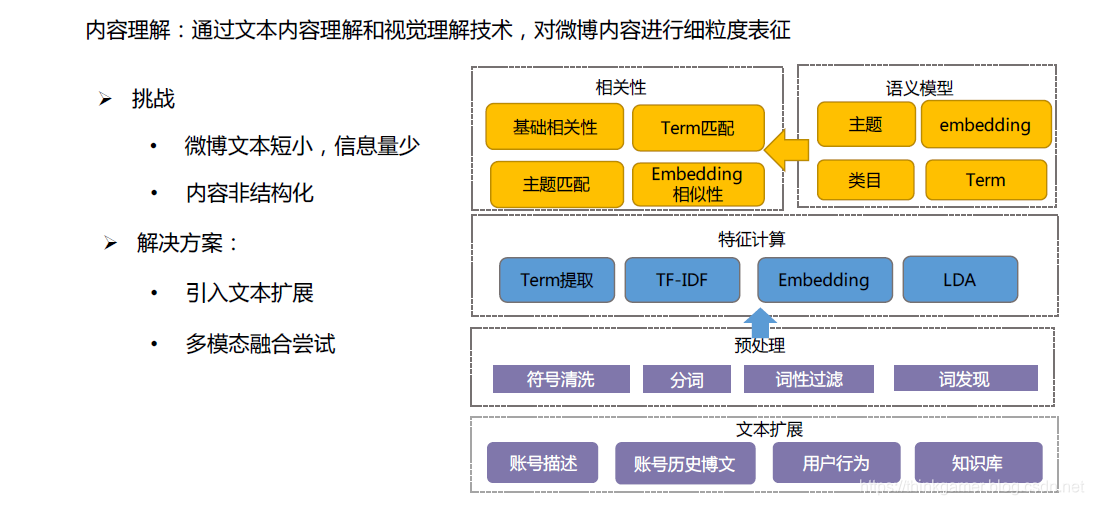
用户画像即基于用户的发博内容,行为数据,自填信息等进行深度挖掘,精准分析刻画用户,从而在进行微博内容推送时能够实现其个性化。

大规模推荐系统实践
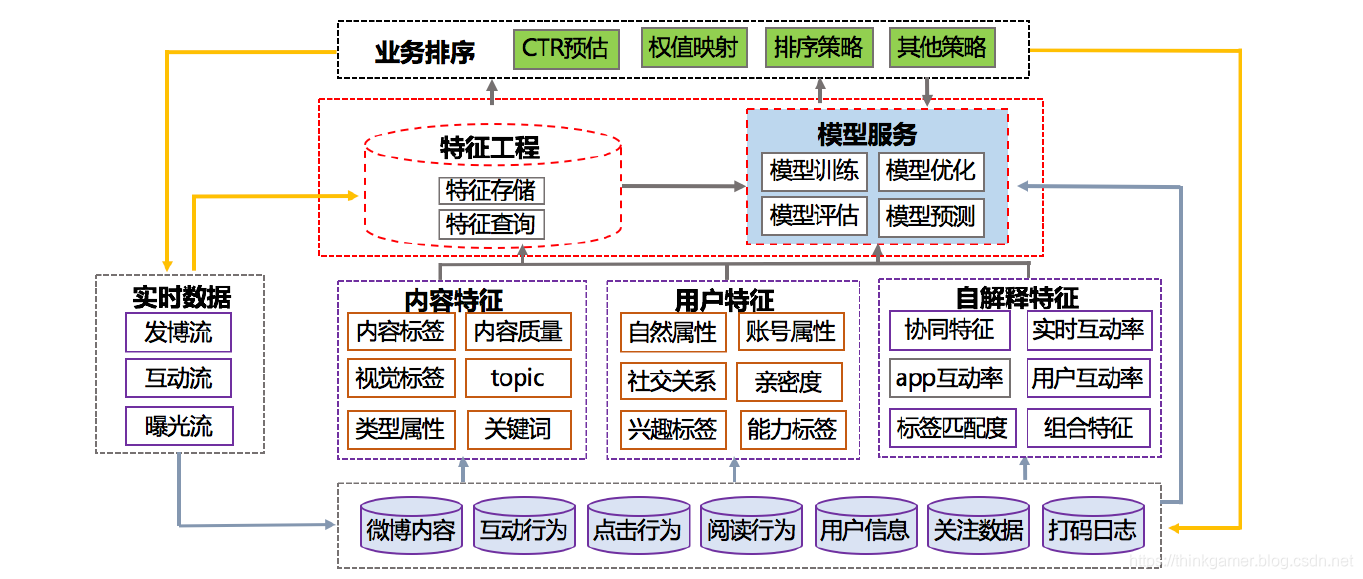
目前推荐架构的实现思路都是先从海量原始数据中,依据用户画像,召回用户偏好的数据,在利用排序算法对其进行排序,最终选择top K返回给用户。微博推荐亦是如此。其整体的流程图如下所示:
物料召回:即从候选物料集合中粗筛物料,作为进行模型的待排序物料。
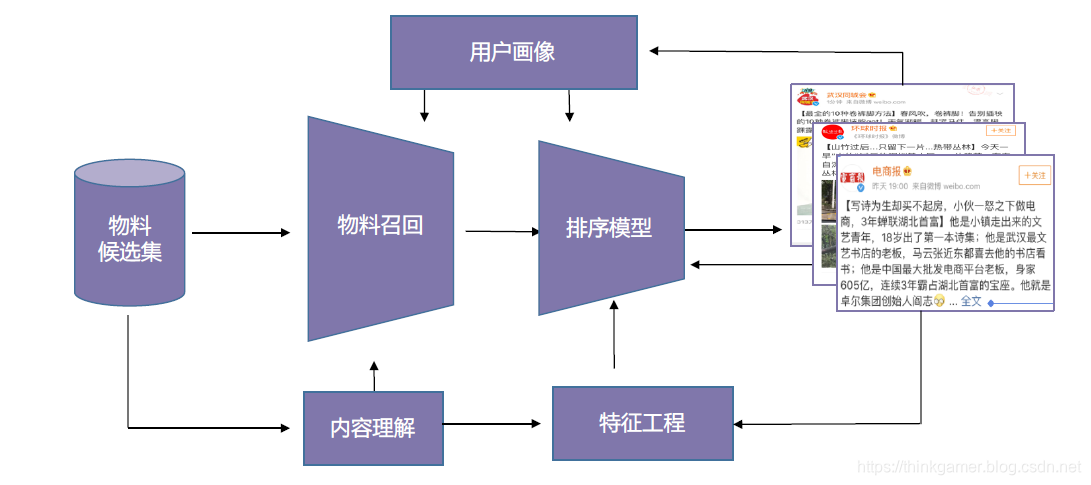
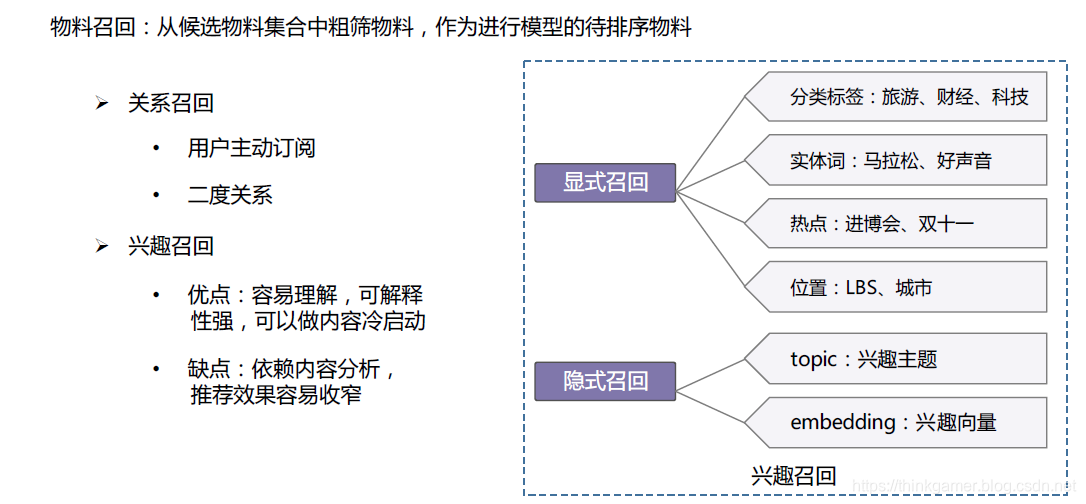
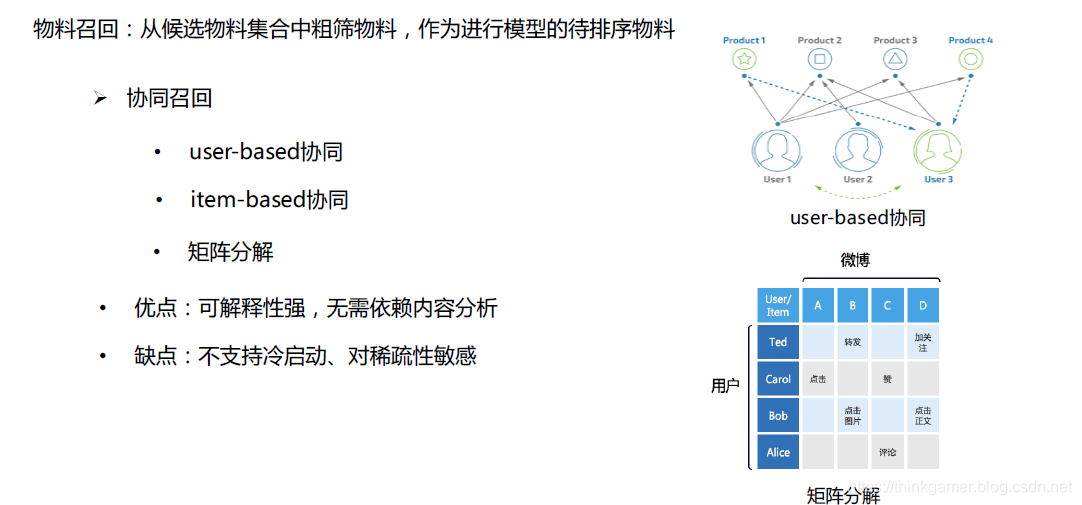
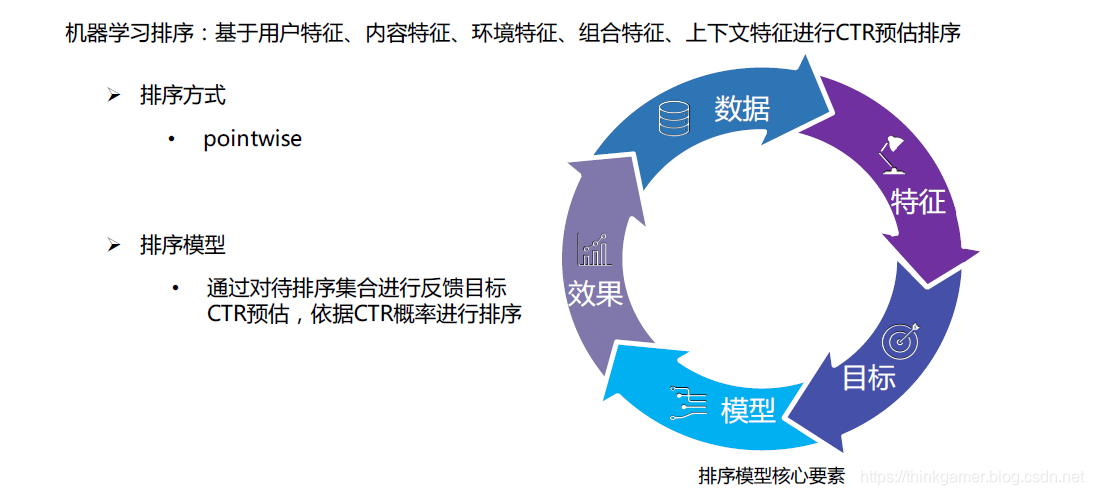
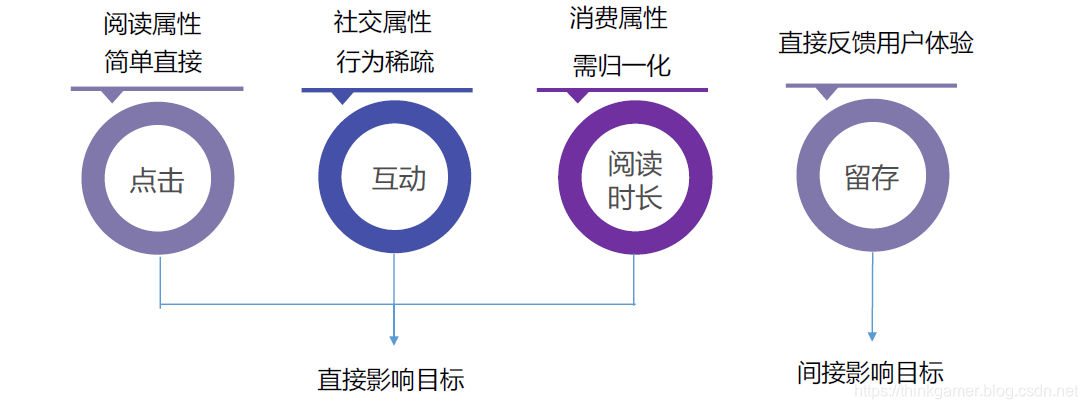
算法排序则是结合相关特征对物料召回的内容进行预估排序,其特征主要分为:用户特征,内容特征,环境特征,组合特征和上下文特征等。
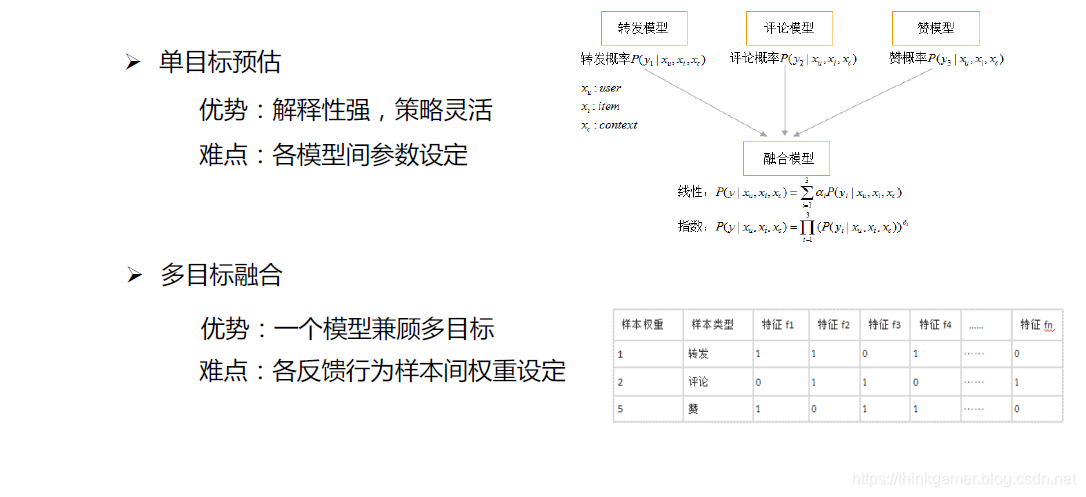
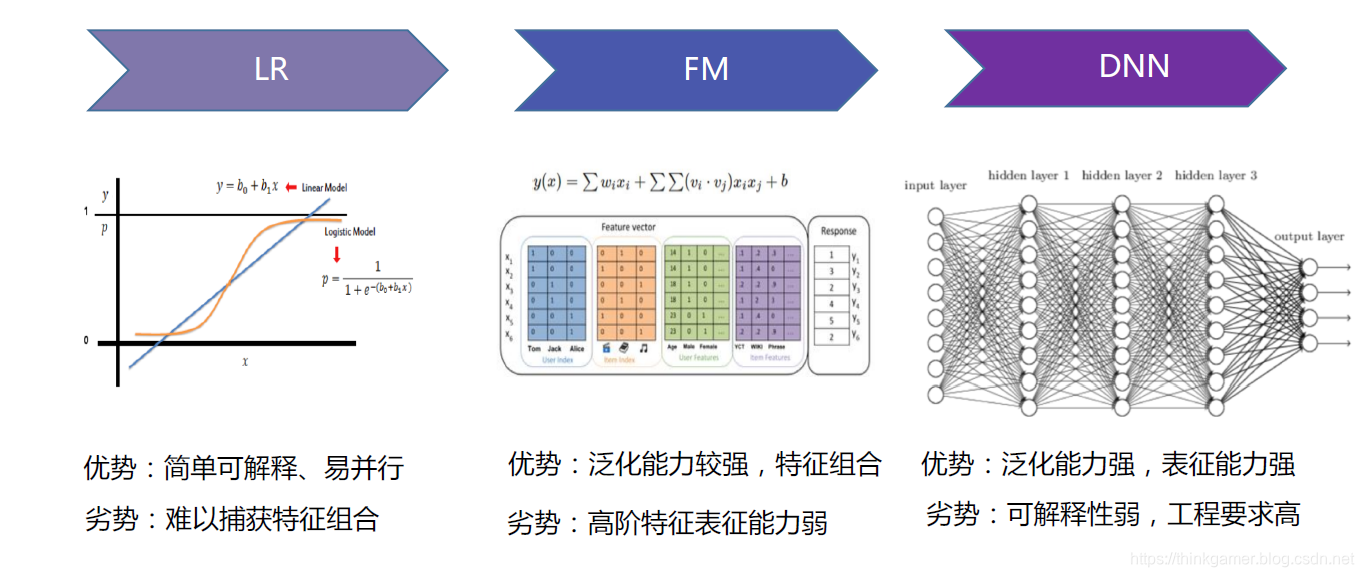
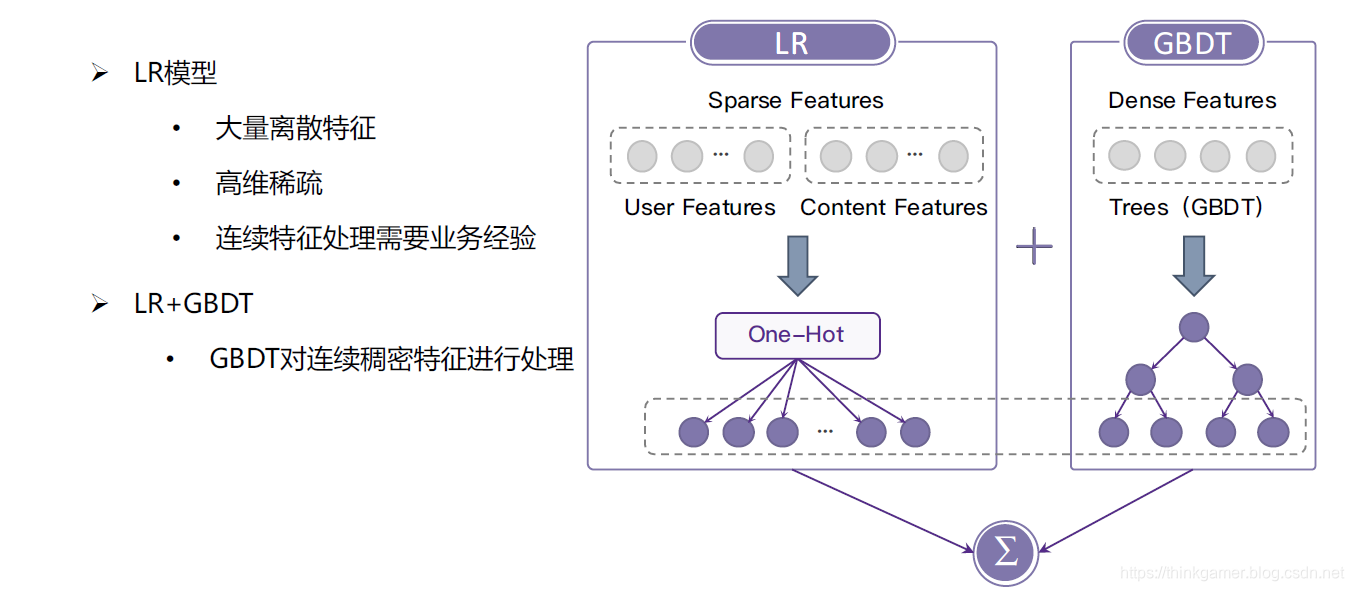
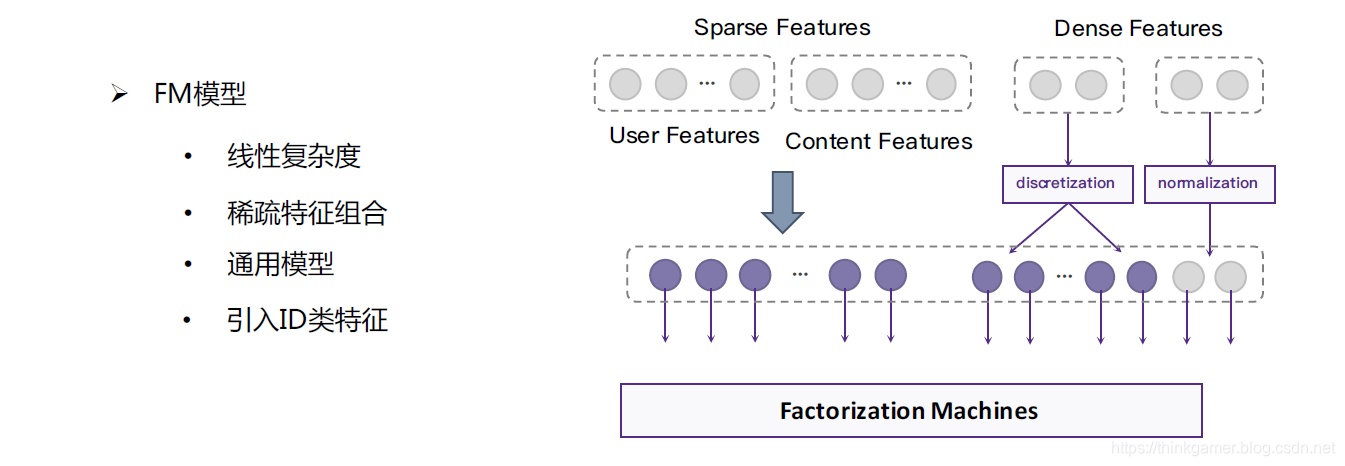
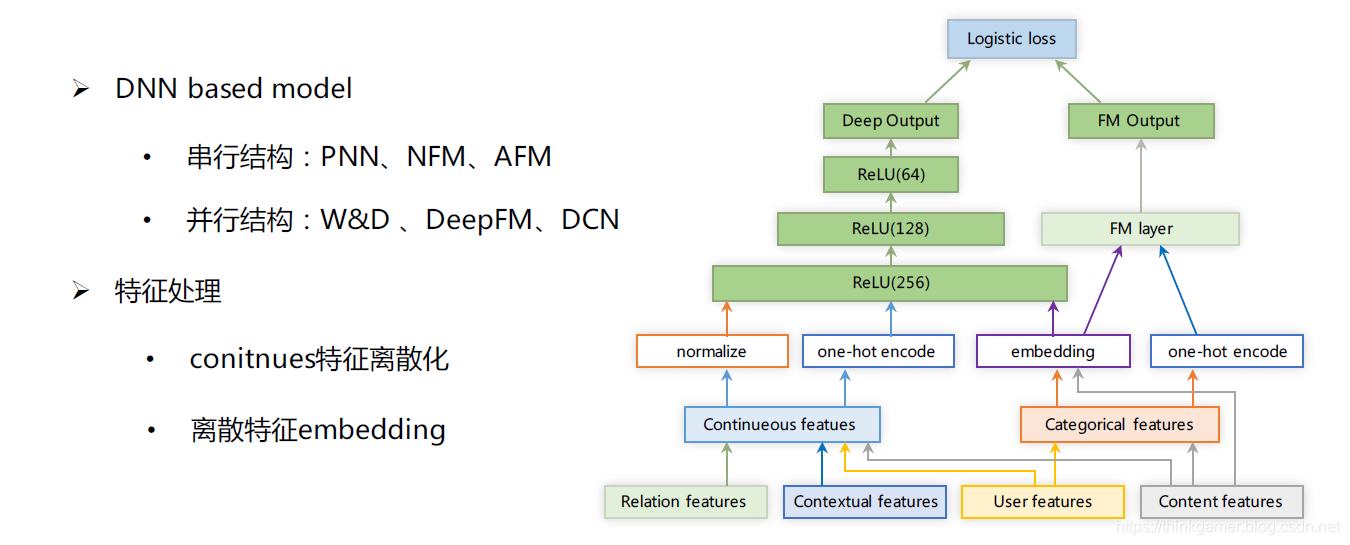

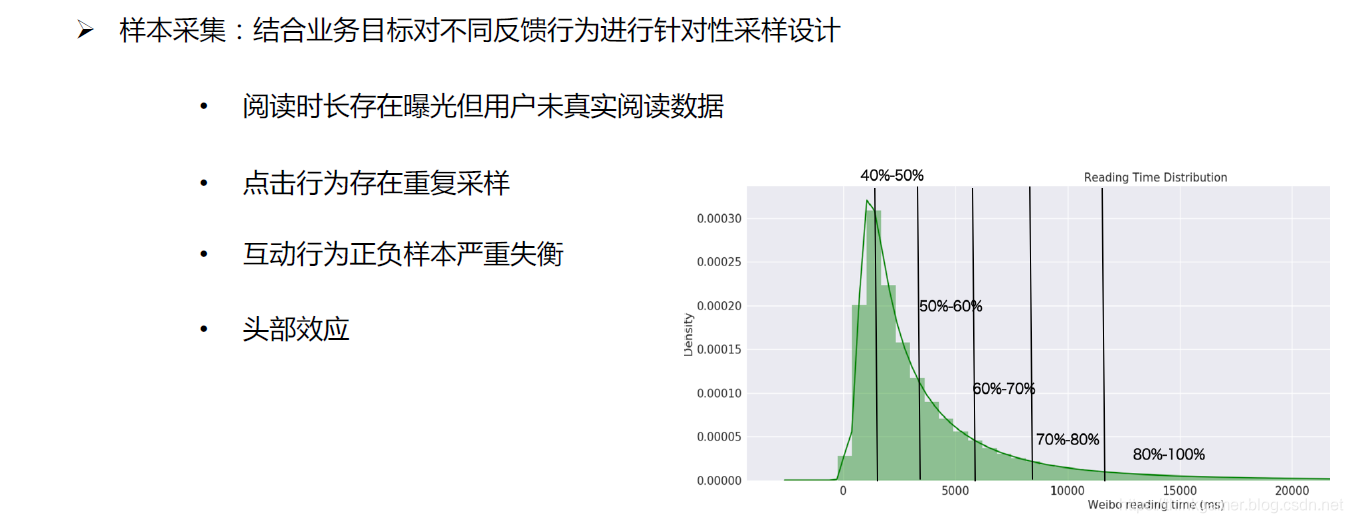
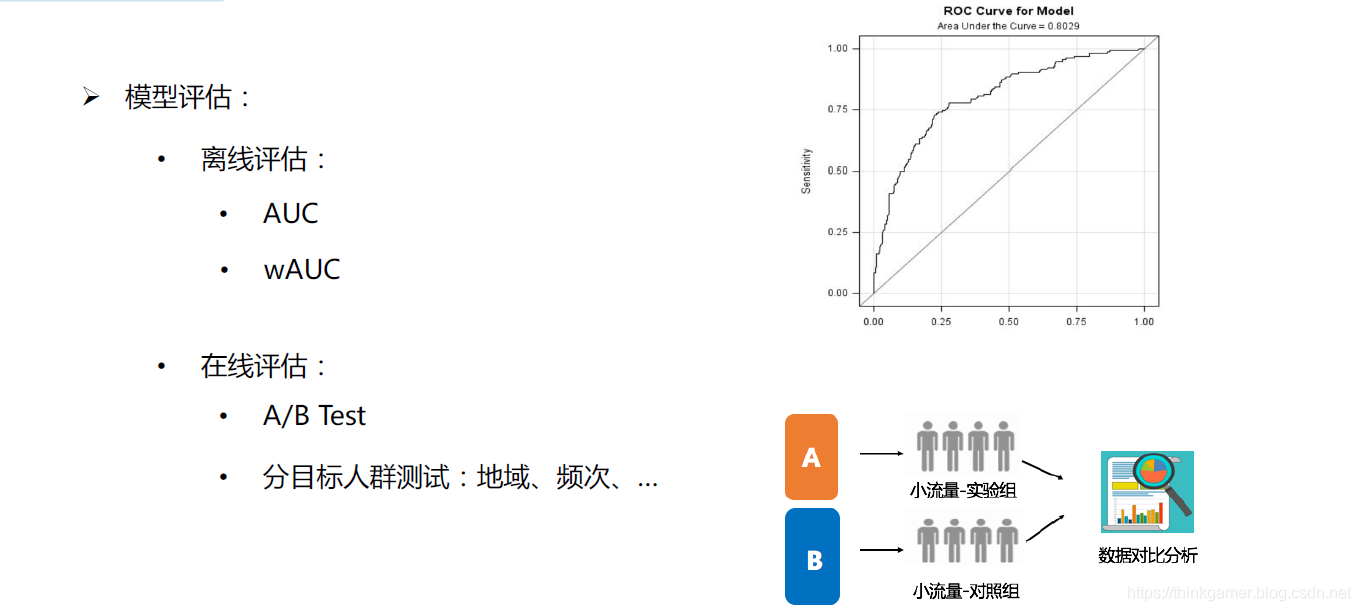
总结与展望
-
总结
-
业务和数据决定了模型算法的应用场景
-
模型算法殊途同归
-
工程能力和算法架构是基本保障
-
-
展望
-
采用多模型融合,能更好的对非结构化内容进行表征
-
更多的融合网络结构适用于CTR预估场景
-
个人网站: 文艺与Code | Thinkgamer的博客
优快云博客: Thinkgamer技术专栏
知乎: Thinkgamer
微博: Thinkgamer的微博
GitHub: Thinkgamer的GitHub
微信公众号: 数据与算法联盟(DataAndAlgorithm)

扫一扫 关注微信公众号!号主 专注于搜索和推荐系统,尝试使用算法去更好的服务于用户,包括但不局限于机器学习,深度学习,强化学习,自然语言理解,知识图谱,还不定时分享技术,资料,思考等文章!
【技术服务】,详情点击查看:https://mp.weixin.qq.com/s/PtX9ukKRBmazAWARprGIAg


















 1623
1623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}