



在 Transformer 横空出世前,自然语言处理(NLP)领域就已历经了诸多探索。早期,人们试图通过制定复杂的语法规则,让计算机理解和处理语言。然而,自然语言灵活多变,规则模型就像被戴上了沉重枷锁,面对稍复杂的句子便束手无策。
随后,基于统计方法的模型出现,它们通过分析大量文本数据中的统计规律来处理语言,相比规则模型有了明显进步。但这类模型在捕捉长距离语义依赖关系时存在短板。
以 “那个在山顶眺望远方的老人,他的眼神满了故事,那是岁月沉淀下来的痕迹” 为例,模型很难精准把握 “那” 与 “故事” 的指代关联。紧接着,基于神经网络的模型崭露头角,如循环神经网络(RNN)及其变体 —— 长短期记忆网络(LSTM)。它们能够处理序列数据,在一定程度上缓解了长距离依赖问题。不过,计算效率较低,处理超长序列时依旧力不从心。正是在这样的背景下,Transformer 诞生了,为 NLP 乃至整个 AI 领域带来了新的曙光。
一、怎么用? 以Transformer 如何助力文本生成为例
当我们有创作需求,比如写一篇关于旅行的游记时,输入 “分享一次难忘的海边旅行经历” 这样的主题,Transformer 模型便开始运作。
首先,编码器将输入文本转化为对应的向量表示,在这个过程中,自注意力机制与多头注意力机制协同工作,模型能充分理解主题中的关键信息,像 “海边旅行”“难忘经历” 这些重点词汇,以及它们之间的关联,确定哪些部分在生成文本时需要着重关注。
随后,解码器依据编码器生成的 “内部表示” 开始逐字生成文本。每生成一个字或词,都会再次利用注意力机制,参考已经生成的前文内容,确保新生成的部分与前文连贯且语义相符。比如,模型可能会先写出 “那是一个阳光明媚的夏日,我踏上了前往海边的旅程”,随着文本的推进,它会不断根据已生成的内容,从海量的语言知识储备中挑选合适的词汇,描绘海边的景色、旅途中的趣事等,保证生成的游记情节丰富、逻辑合理。
得益于 Transformer 强大的长距离依赖捕捉能力,它在生成较长文本时,也能始终保持前后一致性,不会出现前文提到要去海边看日出,后文却写成在森林中看日落这样前后矛盾的情况。而且,Transformer 经过大量文本数据的训练,积累了丰富的语言模式和知识,无论是正式的商务报告,还是轻松活泼的网络短文,它都能依据不同的风格要求,生成符合预期的文本,为创作者们提供高效且优质的辅助。
二、为啥能这么用?Transformer 的神奇工作原理
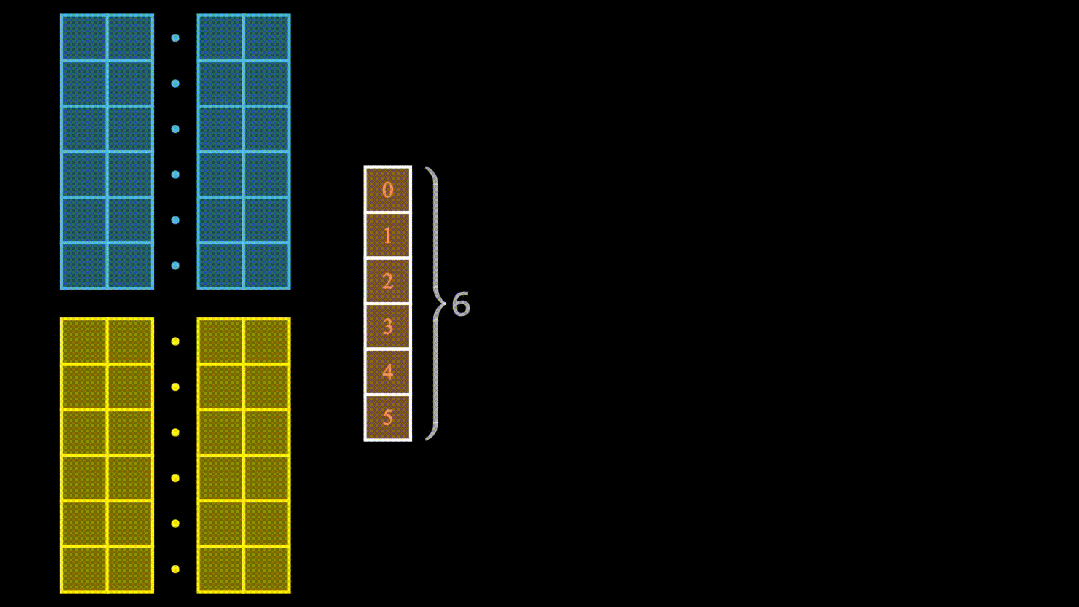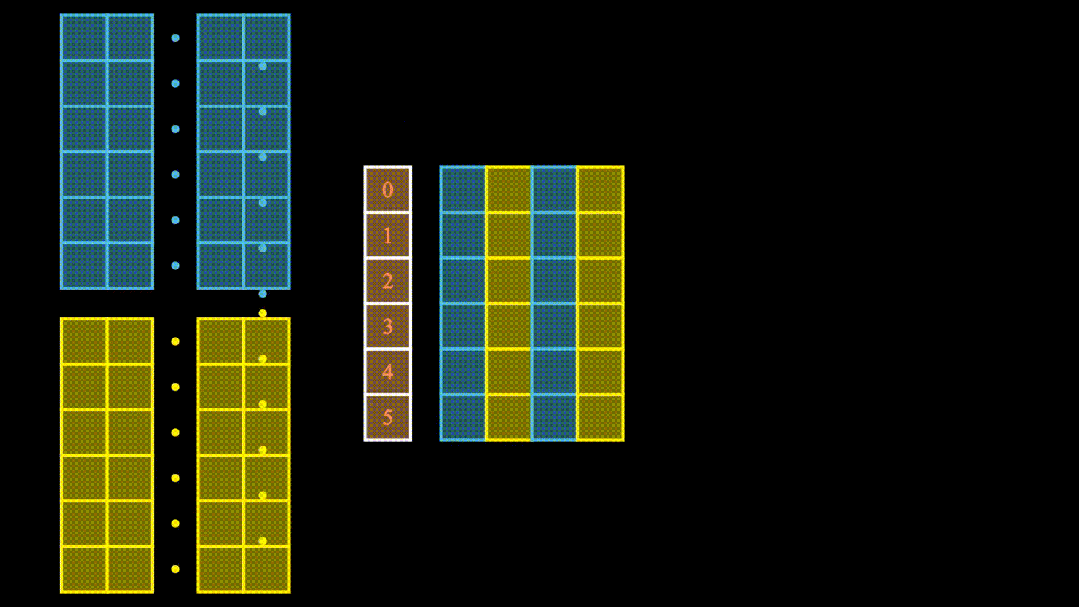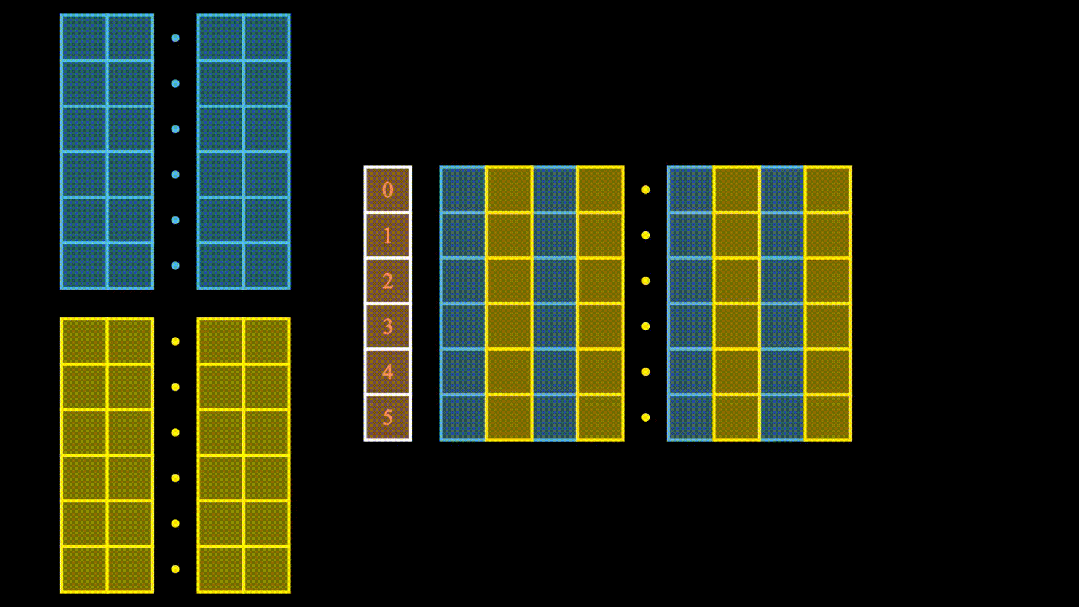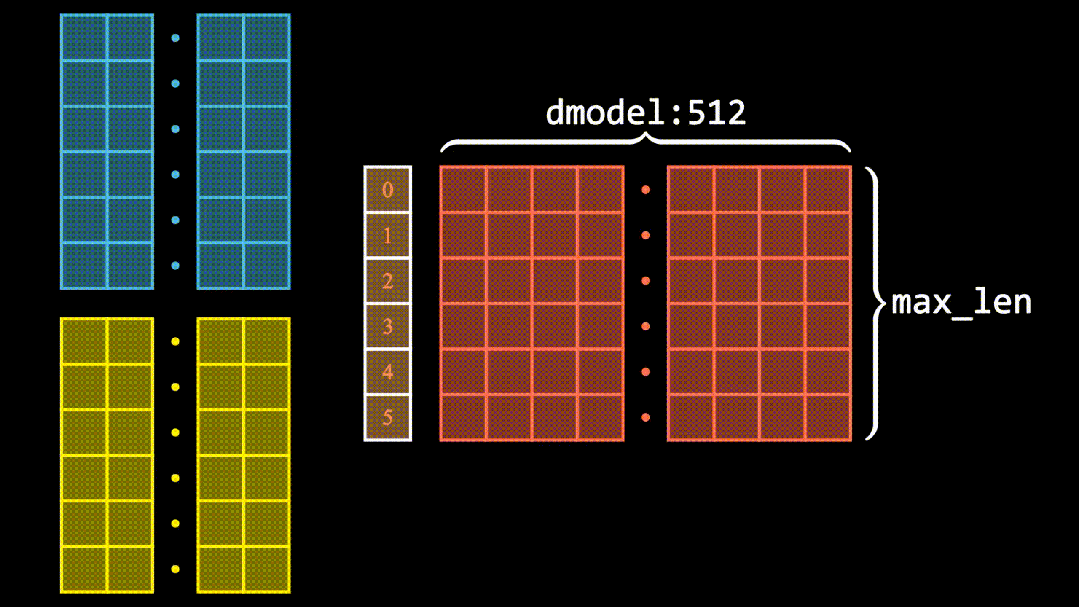
(一)核心组件之编码器与解码器
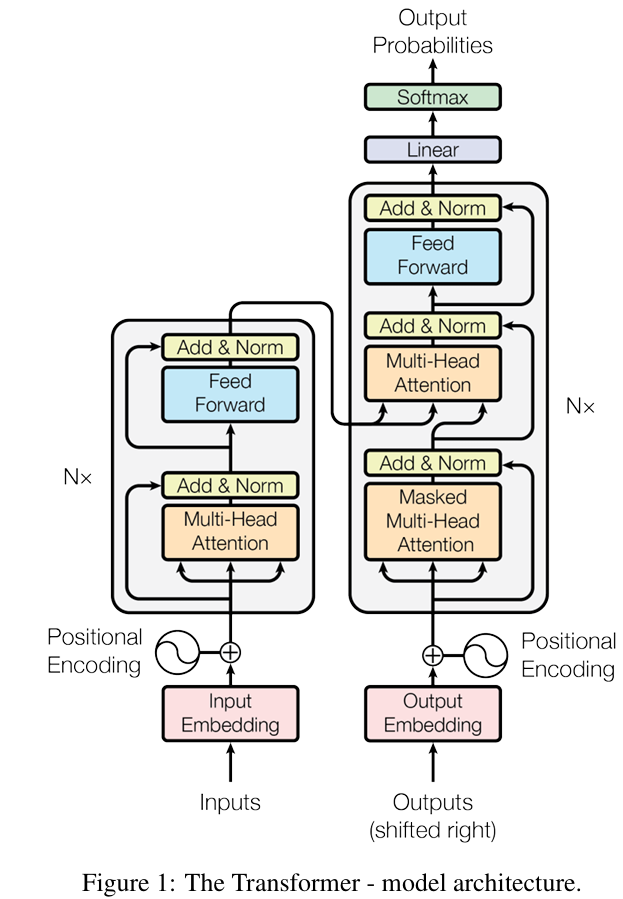
Transformer 就像一座精心搭建的工厂,主要由编码器和解码器两部分构成。编码器负责接收输入的序列数据,比如一段文本,经过一系列复杂处理,将其转化为更易于理解和操作的 “内部表示”。解码器则依据编码器输出的 “内部表示”,生成我们期望的结果,比如翻译后的文本。
(二)基石之力:自注意力机制
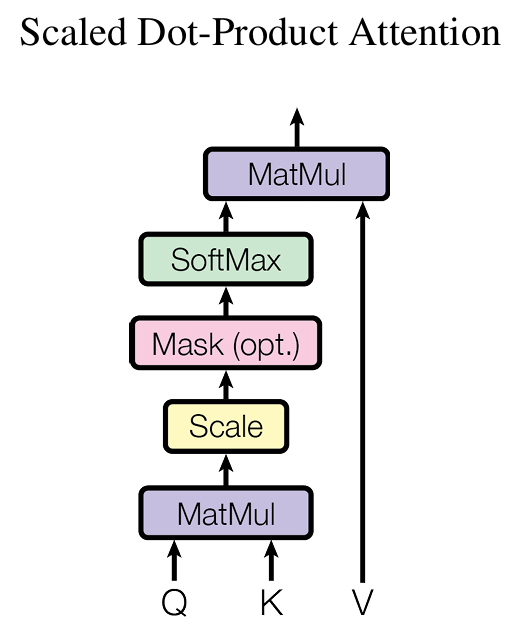
自注意力机制堪称 Transformer 的灵魂。打个比方,我们阅读小说时,看到某个情节,会自动回忆起前文相关内容,以便更好地理解当前情节。自注意力机制在处理文本时亦是如此,它让模型在处理每个单词时,能同时关注句子中其他所有单词与它的关联。例如在 “小狗欢快地跑向主人,摇着尾巴” 这句话中,模型处理 “摇着尾巴” 时,通过自注意力机制能同时聚焦 “小狗”,从而更好地理解句子含义。
(三)拓展视野:多头注意力机制
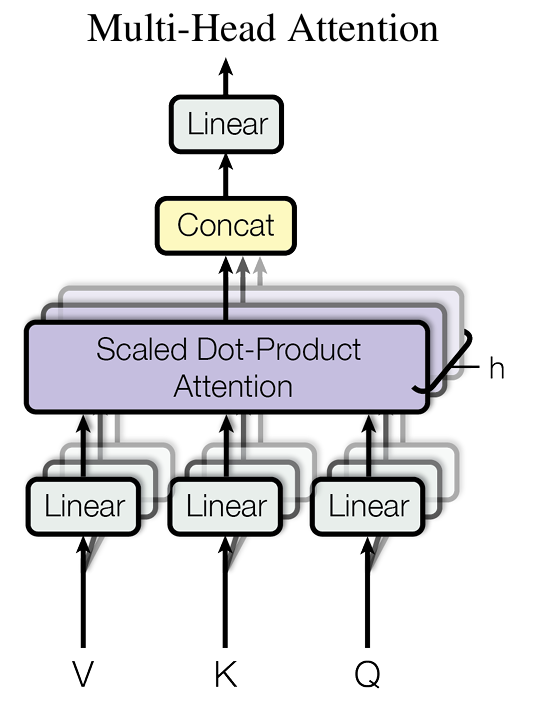
多头注意力机制如同给模型配备了多个不同视角的 “望远镜”。它通过多个独立的注意力头,从不同角度处理输入,再整合这些不同角度的结果。如此一来,模型能够捕捉到更丰富的信息,表达能力大幅提升。
(四)不可或缺:位置编码
由于 Transformer 处理序列数据时,不像 RNN 那样按顺序依次处理,为了让模型知晓每个元素在序列中的位置信息,位置编码便派上了用场。它为每个位置赋予独特编码,如同给每个座位贴上编号,使模型能够区分不同位置的元素。
三、还能怎么用?Transformer 解决的实际问题
无论是语言、图像还是声音的智能化升级,Transformer技术正在重塑千行百业。你的业务场景是否也暗藏Transformer的可能呢?
(一)自然语言处理领域
-
机器翻译:Transformer 在机器翻译领域成绩斐然,能精准将一种语言翻译成另一种语言,无论是日常交流的简单句子,还是专业领域的复杂文献,都不在话下。如今我们使用的在线翻译工具,能快速将中文文章翻译成英文,背后或许就是 Transformer 在发挥作用。
-
文本生成:从撰写新闻报道、小说故事,到创作诗歌、歌词,Transformer 都展现出强大实力。一些智能写作助手,能依据给定的主题或开头,迅速生成连贯且逻辑清晰的文本,大大提高了创作效率。比如学术论文自动摘要、实验报告结构化生成、代码注释补全……Transformer 正在成为科研文本生产力的「隐形协作者」。如何让它适配你的研究方向?或许只需一个轻量级微调方案。
-
问答系统:当领域知识图谱遇上 Transformer 的动态表征能力,前沿课题中的长尾问题检索效率可提升 300%。这一技术组合正在生物医学、法律文献等领域掀起研究热潮。
(二)计算机视觉领域
在计算机视觉领域,Transformer 也逐渐崭露头角。例如在图像分类任务中,它能将图像数据转化为类似文本序列的形式,借助自身强大的处理能力,精准识别和分类图像中的物体。在目标检测任务中,Transformer 能帮助模型更好地定位和识别图像中的多个目标物体。
在医疗影像分析中,ViT 模型通过病灶区域全局建模,将罕见病识别准确率提升至 92.3%;天文观测领域,基于 Swin Transformer 的星系分类系统,处理百万级巡天数据的速度比 CNN 快 17 倍;材料科学研究者正利用视觉-文本多模态 Transformer,实现显微图像与物性参数的联合推理。
(三)语音识别领域
Transformer 同样为语音识别带来新突破。它能将语音信号转化为文本,在处理不同口音、语速及复杂语言环境时,展现出较高的准确率和稳定性。如今许多智能语音助手能精准识别我们的语音指令,Transformer 功不可没。
基于自监督学习的语音表征框架,仅需 1/10 标注数据即可达到 SOTA 性能;融合说话人特征的多任务 Transformer,正在突破跨方言语音合成的自然度阈值。


















 881
881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









