







 本文档介绍了如何爬取孔夫子旧书网上所有店铺的评论。首先,通过正则表达式获取店铺网址,接着获取每个店铺的userId,再设置最大页数爬取评论内容。当返回值为空时,结束爬取。
本文档介绍了如何爬取孔夫子旧书网上所有店铺的评论。首先,通过正则表达式获取店铺网址,接着获取每个店铺的userId,再设置最大页数爬取评论内容。当返回值为空时,结束爬取。
我们上次爬去了孔夫子店铺的一家评论
现在我们要爬去孔夫子店铺的所有评论
一,
首先,找到一个店铺网站的目录:该网站地址
从这个网站中获取到各家店铺的网址。
用最简单的正则表达式就可以爬取到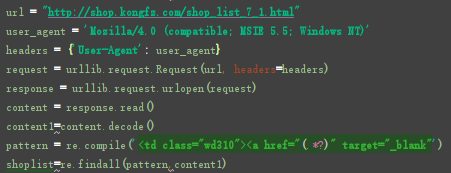
二,上次我们得知每个店铺的url都是稍微不同其中:

所以我们先要获取到每个店铺的userId
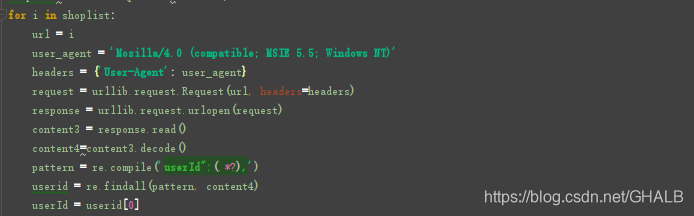
然后进行爬去内容。
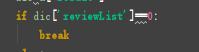
三,要爬取完所有的内容,我们必须要将页数设置到最大。
但是会返回值为空。当返回值为空时。我们要结束该循环。
因为爬取的内容在列表中,列表为空返回值就是空的
完整代码:
```python
import urllib.request
import re
import json
import pymysql
import urllib.request
# -*-coding:utf-8-*-
conn = pymysql.connect(host='localhost',
user='root',
database='r_l',
password='123456789',
charset='utf8')
print('链接数据库成功')
cur=conn.cursor()
sql="""CREATE TABLE kfzpl (commodity CHAR(20),content text(255),name CHAR(20))"""
cur.execute("DROP TABLE IF EXISTS kfzpl")
cur. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









