




目录
一、内存访问模式
GPU对片外DRAM的访问延迟大,带宽低,导致其成为很多应用的性能瓶颈。因此对DRAM访问的进一步优化可以有效改善程序性能。优化之前,首先看一下GPU对内存的访问模式
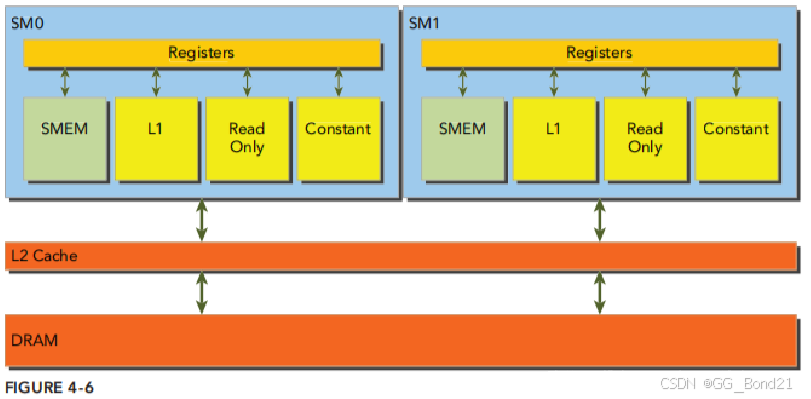
如上图所示,DRAM内存的读写在物理上是从 片外DRAM -> 片上Cache -> 寄存器。 其中,片外DRAM到片上Cache是主要性能瓶颈。DRAM 到 Cache 之间的一次传输(transaction)设计为32、64或者128字节,并且内存地址按照32、64或者128字节的间隔对齐
注意:后文中 transaction 特指设备内存(DRAM)到片内存储(Cache)的传输
以读数据为例,DRAM 数据首先进入 L2 Cache,之后根据 GPU 架构的不同,有些会继续传输到 L1 Cache,最后进入线程寄存器。L2 cache 是所有 SM 共有,而 L1 cache 是 SM 私有
若使用了 L1+L2 Cache,那么执行一次 DRAM 到 Cache 之间的传输(transaction),是 128 字节。若仅使用 L2 Cache,那么就是 32 字节
是否启用L1 Cache取决于GPU架构与编译选项
关闭L1 cache
-Xptxas -dlcm=cg
打开L1 cache
-Xptxas -dlcm=ca由于采用 SIMT 的架构,GPU 对内存的访问指令是由 warp 发起的,即 warp 中每个线程同时执行内存操作指令,不过每个线程所访问的数据地址可以不同,GPU 会根据这些不同的地址发起一次或多次 DRAM -> Cache 的传输(transaction),直到所有线程都拿到各自所需的数据(Cache->Registers)。显然,可以通过减少DRAM->Cache的transaction次数来优化程序性能
warp 执行内存指令时会有很长的延迟,此时 warp 进入 Stalled 状态,warp 调度器调度其他 eligible warp 执行
内存指令延迟的原因:
- 访问设备内存本身存在大的延迟
- SIMT 的执行模型,意味着只有当 warp 内所有32个线程都得到了数据后,才会从 Stalled 态转为 Eligible 态
最好的情况下,GPU发起一次 DRAM -> Cache 的transaction就把 warp 中所有线程所需的数据全部获取到 Cache,最坏的情况下,则需要 32 次 transaction
Read-Only cache
Read-Only cache原本用于纹理内存的缓存。GPU 3.5以上的版本可以使用该缓存替代L1,作为Global内存的缓存。此cache采用32字节对齐间隔,因此比原128字节的缓冲区更适合非对齐非合并的情况
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 934
934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











