







1.环境配置
我采用的是Anaconda+Pycharm的配置,python=3.8。
Anaconda安装自己百度
创建conda环境:
conda create --name 改成你的环境名称 python=3.82.下载Yolov5
https://github.com/ultralytics/yolov5
github:
https://github.com/ultralytics/yolov5/releases/tag/v6.0
下载yolov5s.pt文件
权重文件下载放到Yolov5根目录
3.安装依赖库
conda创建环境
conda create -n goods python=3.8使用conda进入你创建的环境
activate 你的环境linux添加环境变量
export PATH=$PATH:/root/anaconda3/binlinux使用,如果你使用的是较早版本的Conda(如Conda 4.6之前的版本)
source activate 你的环境进入YOLO5根目录,安装需要的库
pip install -r requirements.txt4.测试:detect.py文件
运行detect.py文件,若没有问题在runs/detect/exp目录会得到以下图片

五、训练文件修改
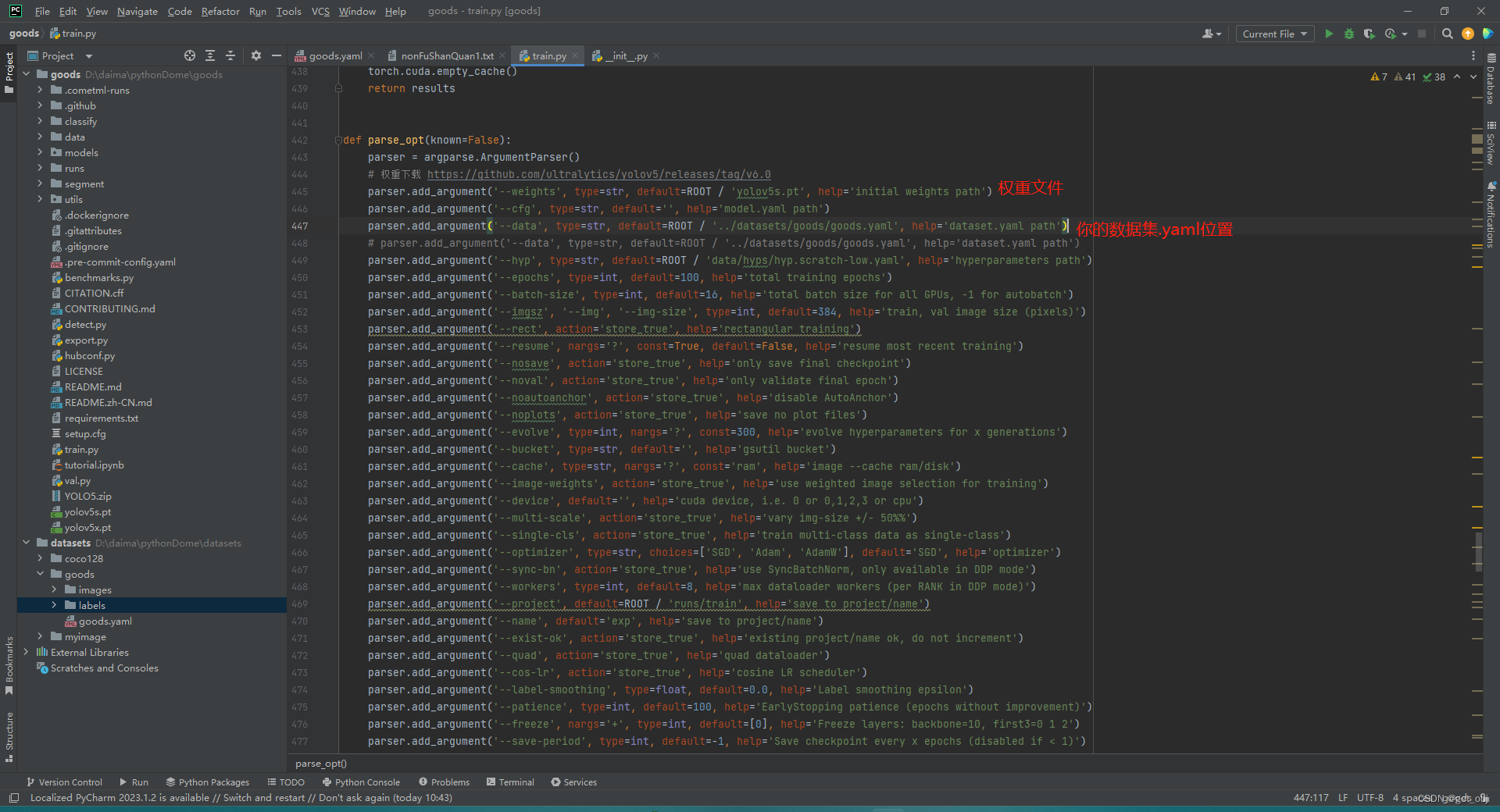
1、修改train.py
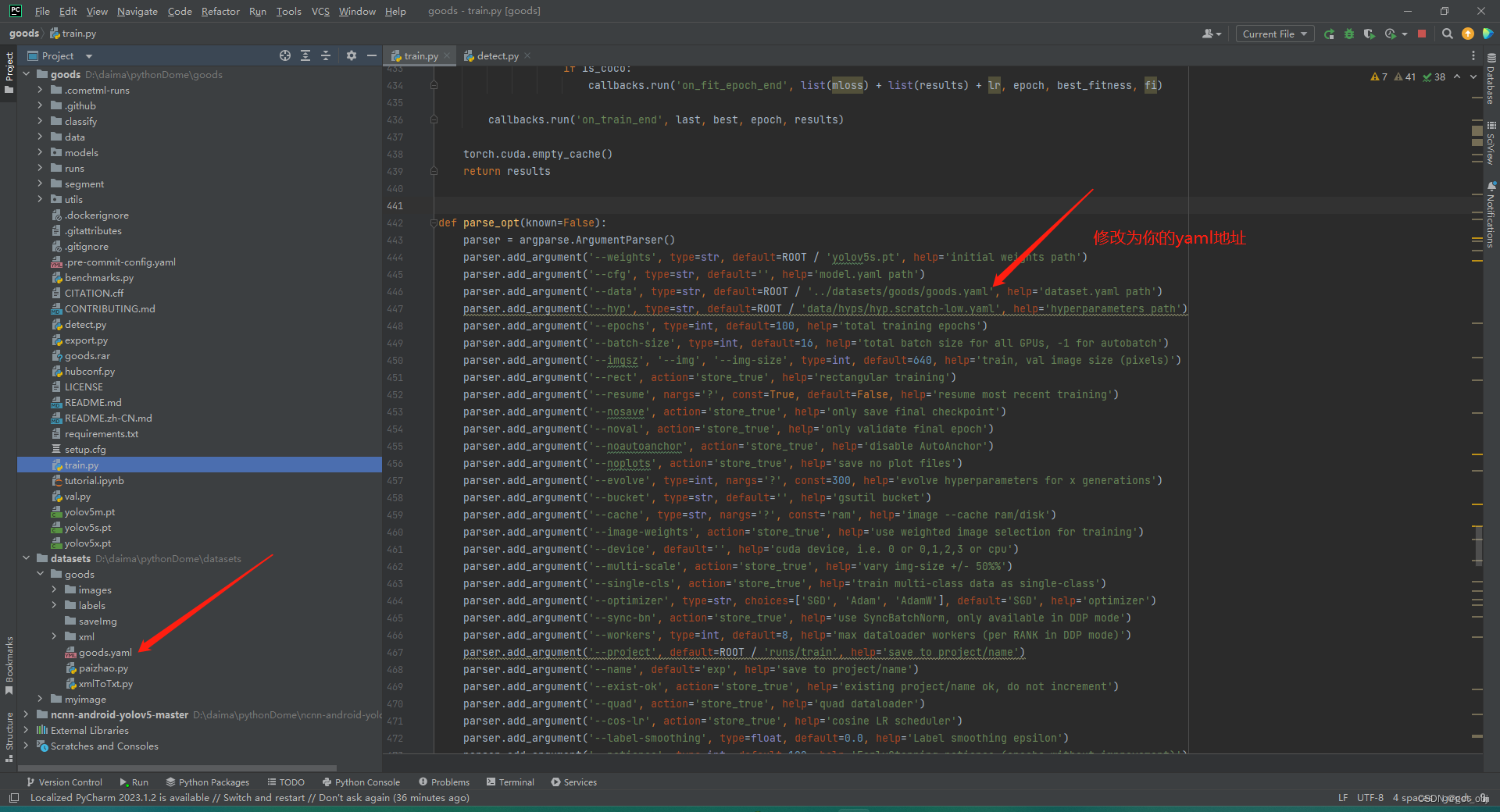
修改goods.yaml文件
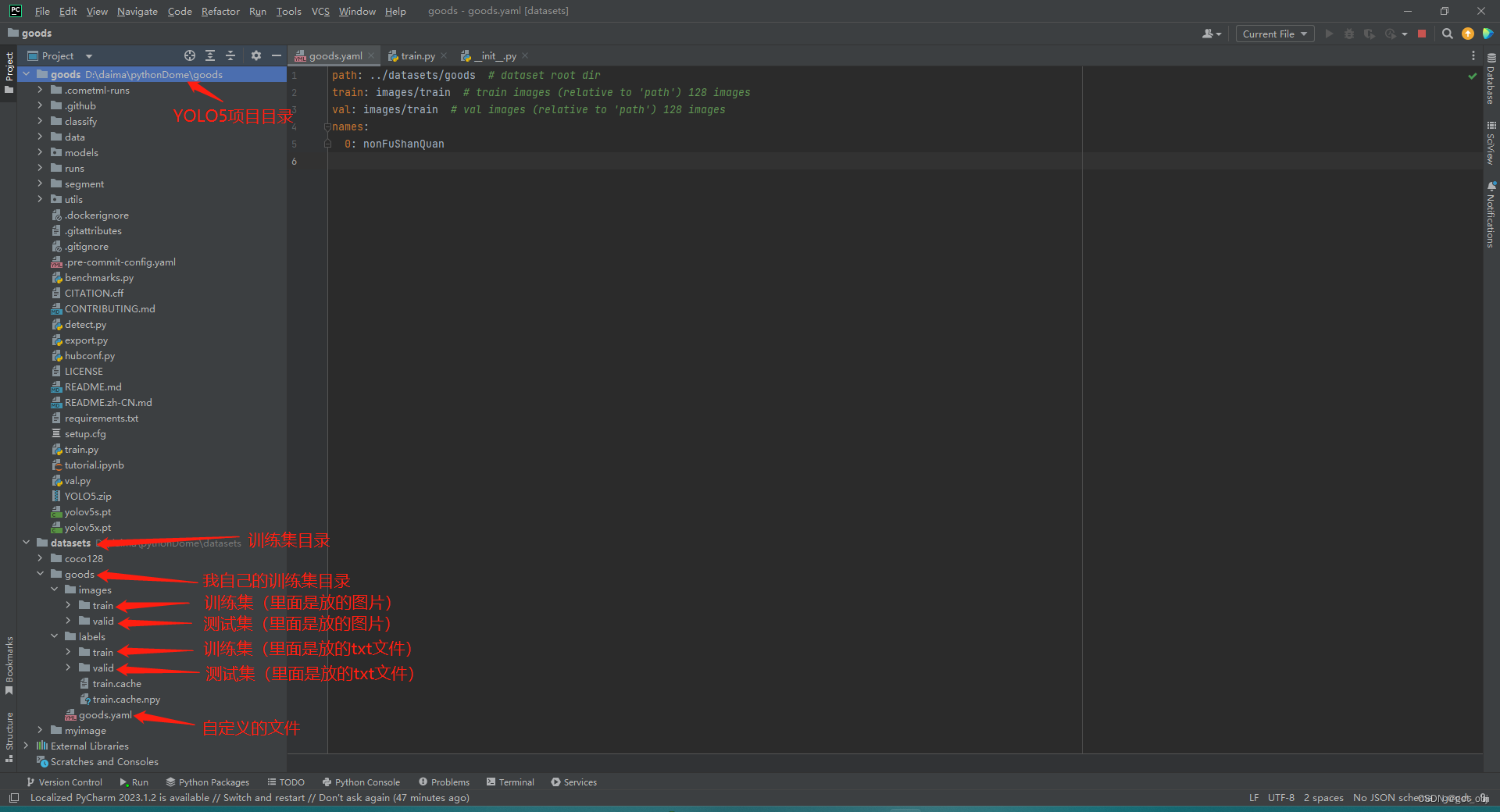
goods.yaml文件参数
path训练集参数在项目中的绝对路径
train训练集文件地址
val测试集文件地址
names你创建的标签列表(如何创建标签查看第六步)
六、制作自己的数据集之制作标签
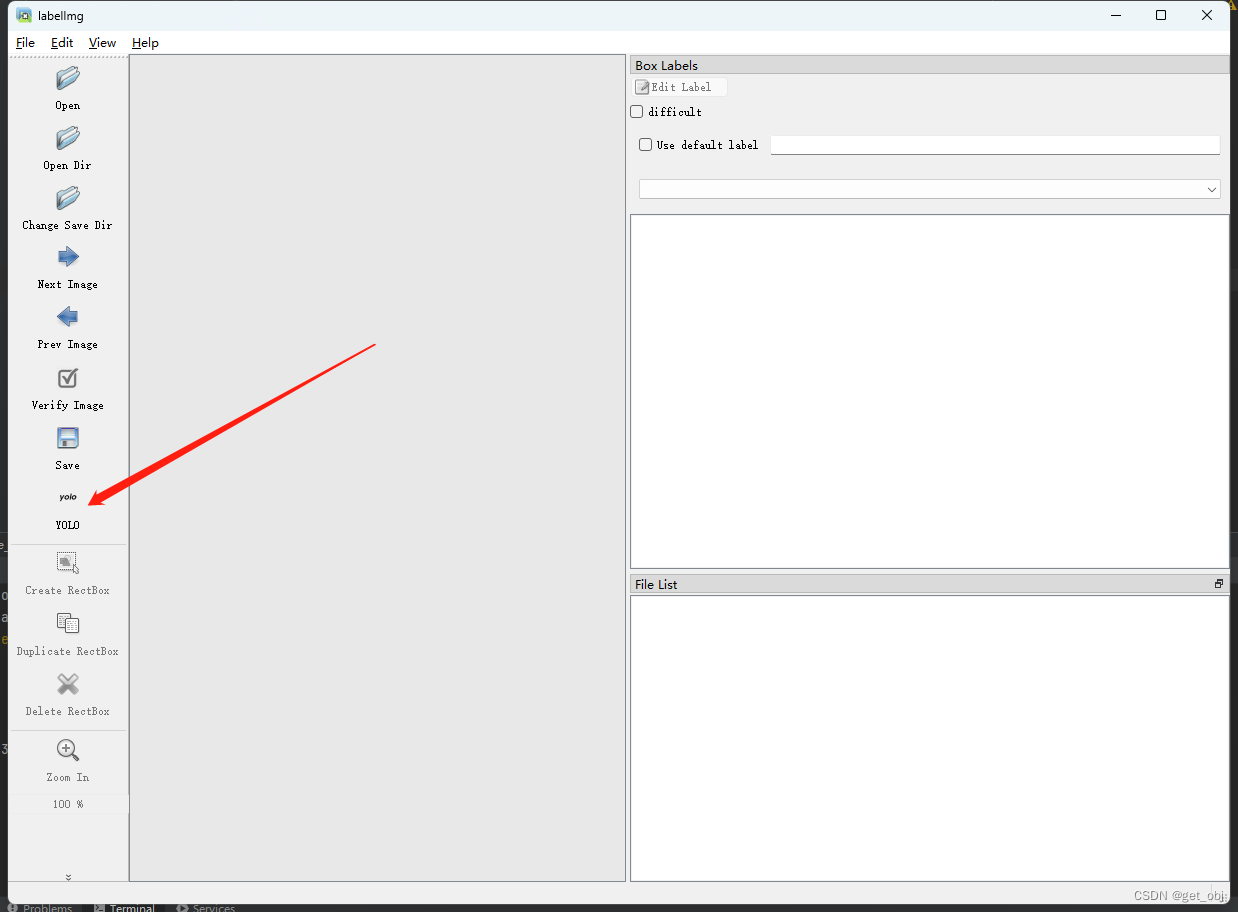
常用的制作标签软件labelme、labelImg
我使用的是labelImg
安装labelImg
pip install labelImg启动labelImg
labelImg然后打开图片框选要识别的物体 - 输入标签保存即可
训练的图片放到datasets/goods/images/train里面
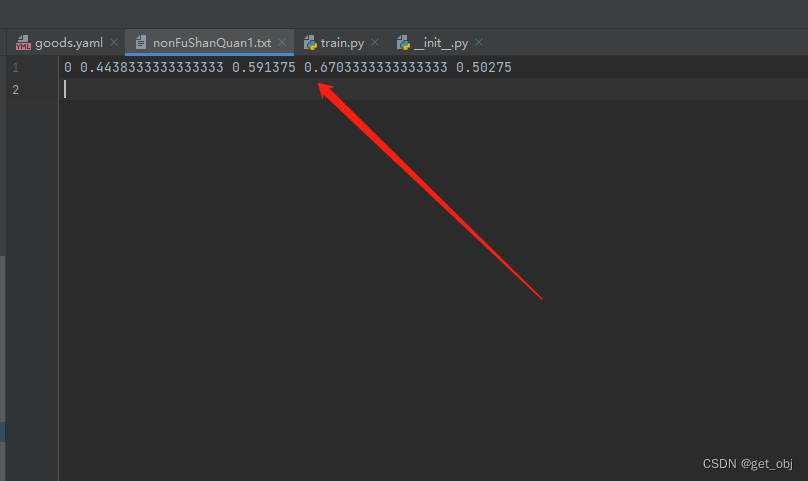
labelImg保存的txt文件放到datasets/goods/labels/train里面
注意:需要修改这个为YOLO
注意:训练图片名称和标签名称必须是一样的
如果是json文件需要转换成txt文件
import json
import os
name2id = {'nonFuShanQuan':0}#标签名称
def convert(img_size, box):
dw = 1. / (img_size[0])
dh = 1. / (img_size[1])
x = (box[0] + box[2]) / 2.0 - 1
y = (box[1] + box[3]) / 2.0 - 1
w = box[2] - box[0]
h = box[3] - box[1]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def decode_json(json_floder_path, json_name):
txt_name = 'D:\\daima\\pythonDome\\goods\\' + json_name[0:-5] + '.txt'
#存放txt的绝对路径
txt_file = open(txt_name, 'w')
json_path = os.path.join(json_floder_path, json_name)
data = json.load(open(json_path, 'r', encoding='gb2312',errors='ignore'))
img_w = data['imageWidth']
img_h = data['imageHeight']
for i in data['shapes']:
label_name = i['label']
if (i['shape_type'] == 'rectangle'):
x1 = int(i['points'][0][0])
y1 = int(i['points'][0][1])
x2 = int(i['points'][1][0])
y2 = int(i['points'][1][1])
bb = (x1, y1, x2, y2)
bbox = convert((img_w, img_h), bb)
txt_file.write(str(name2id[label_name]) + " " + " ".join([str(a) for a in bbox]) + '\n')
if __name__ == "__main__":
json_floder_path = 'D:\\daima\\pythonDome\\goods\\'
#存放json的文件夹的绝对路径
json_names = os.listdir(json_floder_path)
for json_name in json_names:
decode_json(json_floder_path, json_name)如果是xml文件需要转成txt文件
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
def convert(size, box):
# size=(width, height) b=(xmin, xmax, ymin, ymax)
# x_center = (xmax+xmin)/2 y_center = (ymax+ymin)/2
# x = x_center / width y = y_center / height
# w = (xmax-xmin) / width h = (ymax-ymin) / height
x_center = (box[0] + box[1]) / 2.0
y_center = (box[2] + box[3]) / 2.0
x = x_center / size[0]
y = y_center / size[1]
w = (box[1] - box[0]) / size[0]
h = (box[3] - box[2]) / size[1]
# print(x, y, w, h)
return (x, y, w, h)
def convert_annotation(xml_files_path, save_txt_files_path, classes):
xml_files = os.listdir(xml_files_path)
# print(xml_files)
for xml_name in xml_files:
# print(xml_name)
xml_file = os.path.join(xml_files_path, xml_name)
out_txt_path = os.path.join(save_txt_files_path, xml_name.split('.')[0] + '.txt')
out_txt_f = open(out_txt_path, 'w')
tree = ET.parse(xml_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
# if cls not in classes or int(difficult) == 1:
# continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
# b=(xmin, xmax, ymin, ymax)
# print(w, h, b)
bb = convert((w, h), b)
out_txt_f.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == "__main__":
# 把forklift_pallet的voc的xml标签文件转化为yolo的txt标签文件
# 1、需要转化的类别
classes = ['nonFuShanQuan']
# 2、voc格式的xml标签文件路径
xml_files1 = r'D:\Technology\Python_File\yolov5\M3FD\Annotation_xml'
# xml_files1 = r'C:/Users/GuoQiang/Desktop/数据集/标签1'
# 3、转化为yolo格式的txt标签文件存储路径
save_txt_files1 = r'D:\Technology\Python_File\yolov5\M3FD\Annotation_txt'
convert_annotation(xml_files1, save_txt_files1, classes)七、开始训练train.py
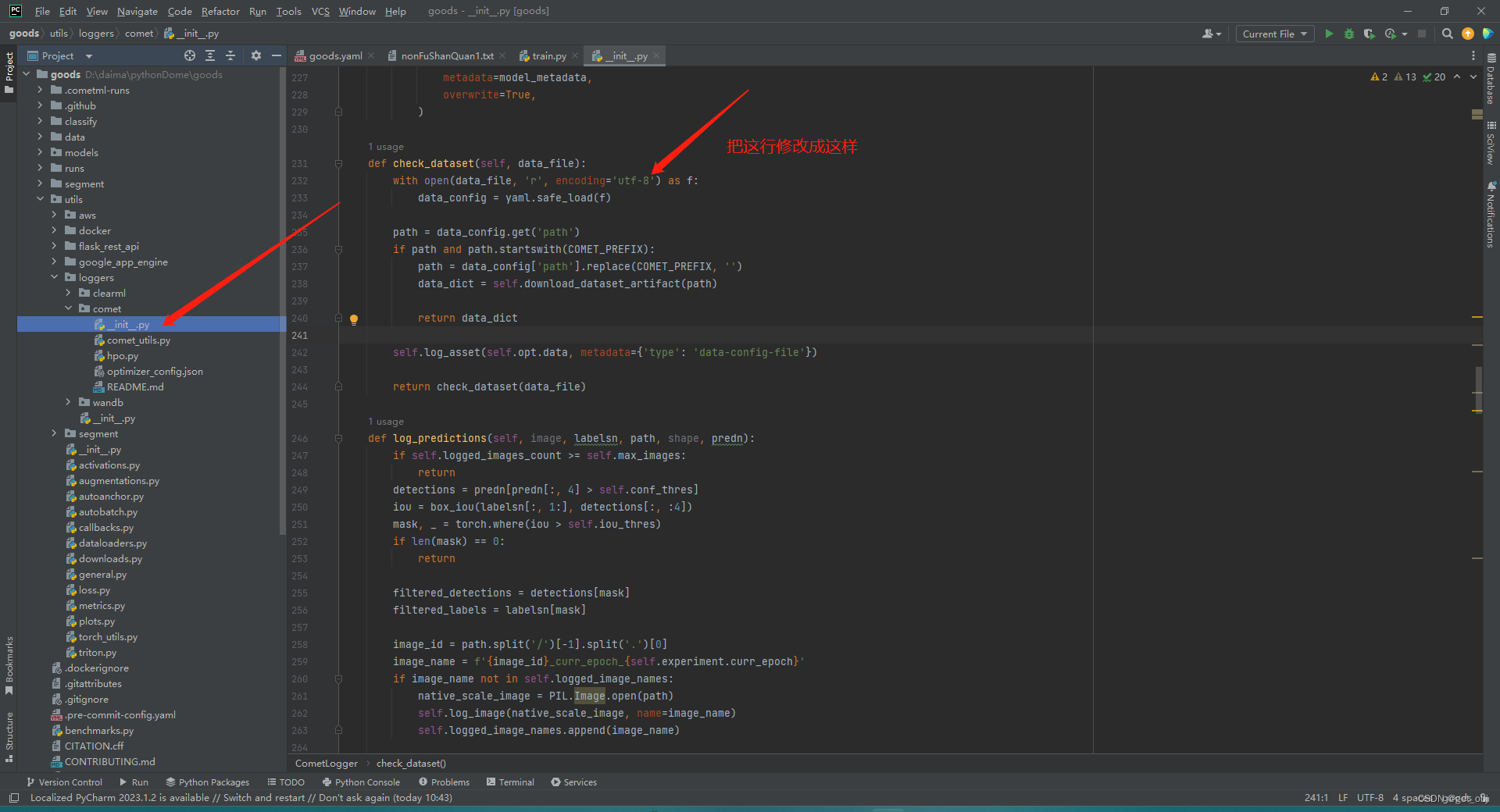
报错:COMET_GIT_DIRECTORY if your Git Repository is elsewhere
解决:卸载掉comet_ml
pip uninstall comet_ml报错(好像解决上面的就行了):UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 234: illegal multibyte sequence
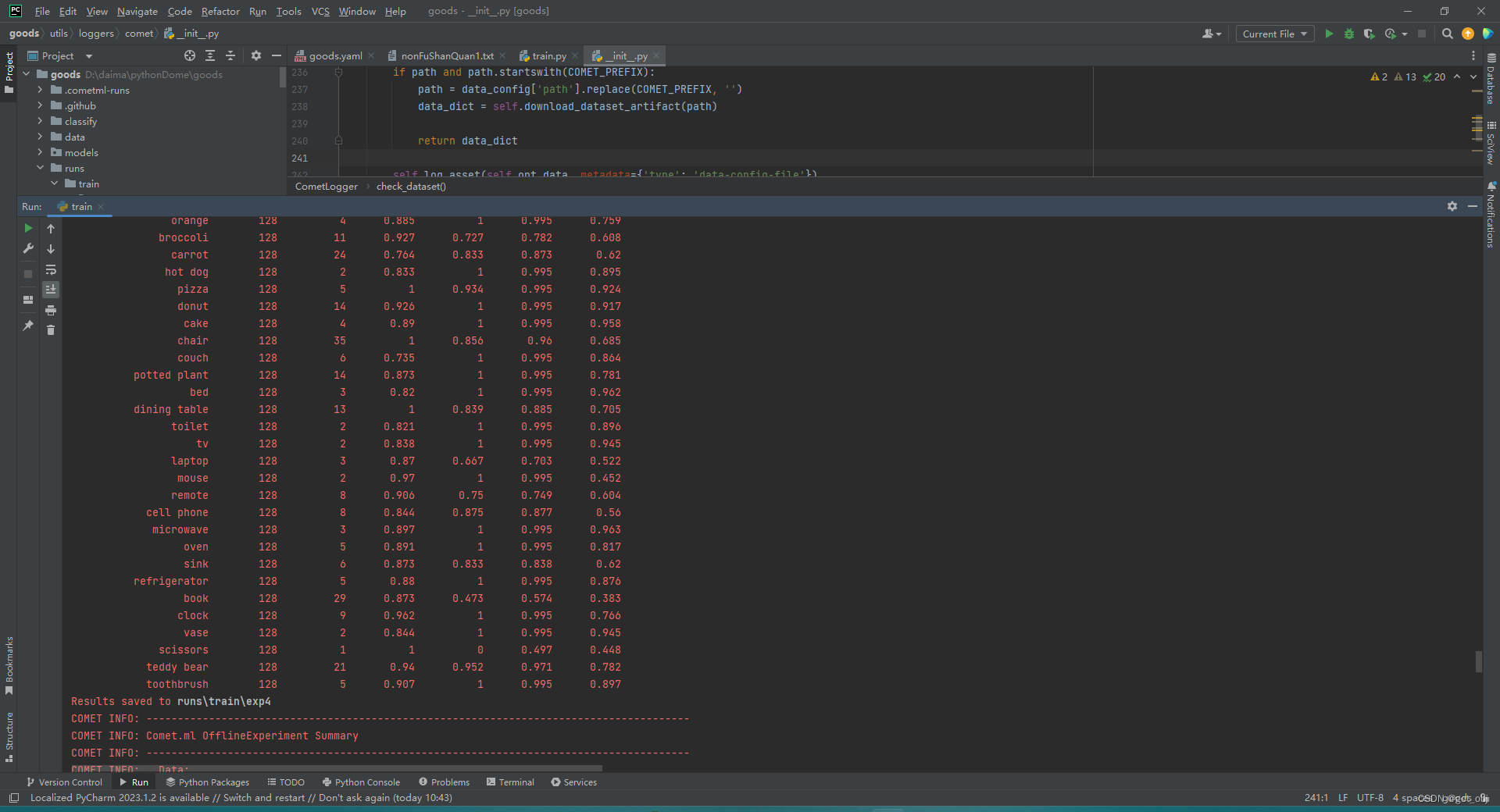
训练成功
八、识别检测detect.py
搜索parse_opt方法
--weights:训练好的权重文件(runs/train/exp/weights中),best.pt为最好的一次,last.pt为最后一次
--source:要检测的文件,可以是图片文件夹、本地图片视频、线上图片视频、摄像头。填0时为打开电脑默认摄像头
--data:数据集参数文件
--imgsz:图片大小
--conf-thres:置信度,当检测出来的置信度大于该数值时才能显示出被检测到
主要修改这三个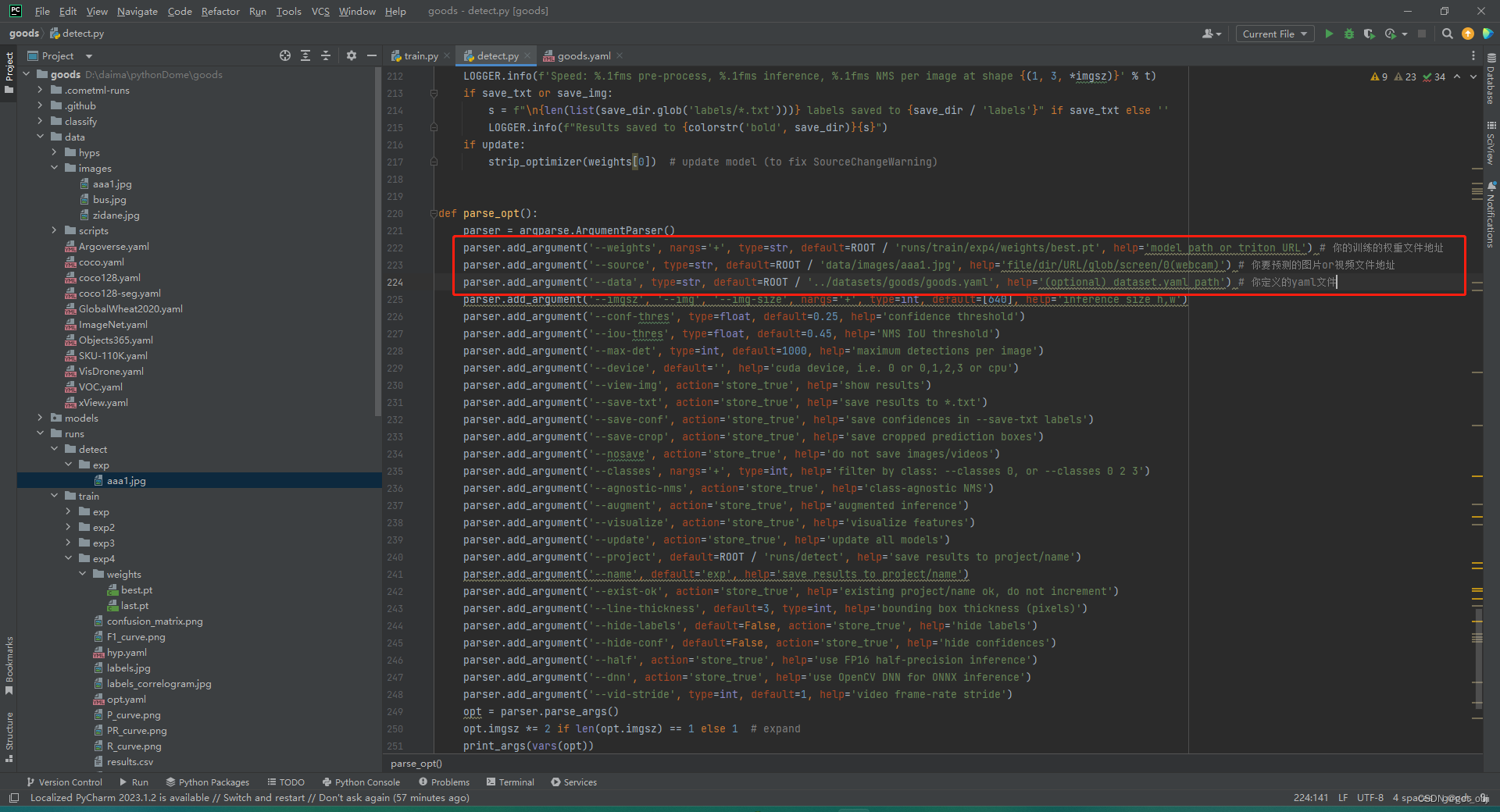
结果在runs/detect/exp中
部署到安卓系统



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









