




 本文详细介绍了一次基于波士顿房价数据集的预测过程,包括数据预处理、模型训练及评估等步骤,并最终实现了线性回归模型的有效应用。
本文详细介绍了一次基于波士顿房价数据集的预测过程,包括数据预处理、模型训练及评估等步骤,并最终实现了线性回归模型的有效应用。
目录
一、分析数据
import numpy as np
from sklearn import datasets
from sklearn.linear_model import LinearRegression
boston = datasets.load_boston()
'''
data 即数据,这些数据影响了房价,统计指标
target指房价,单位(万美金)
feature_names 具体的指标,比如CRIM:犯罪率 NOX:空气污染
'''
boston它有三个部分:
data部分:506条数据 (13个属性(特征)-影响房价的因素)
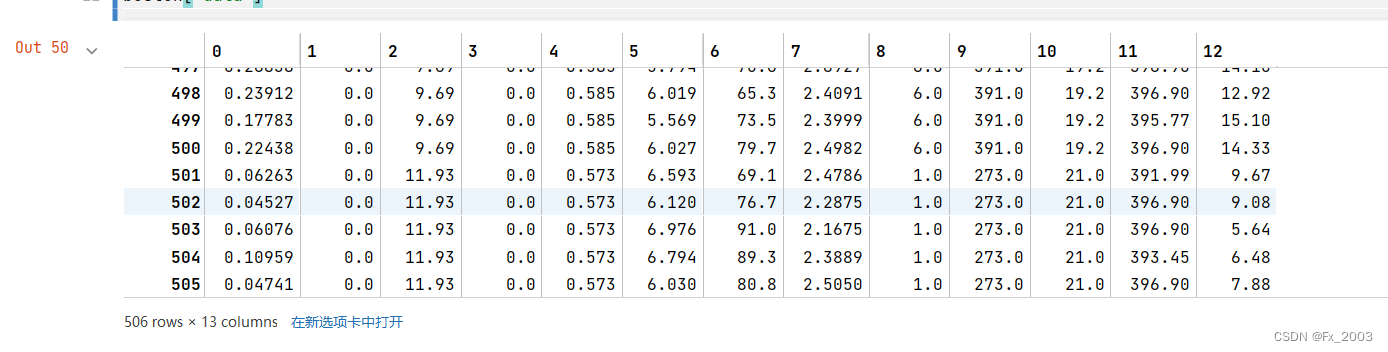
target部分: 506条(就是506个房子的房价)单位是万美金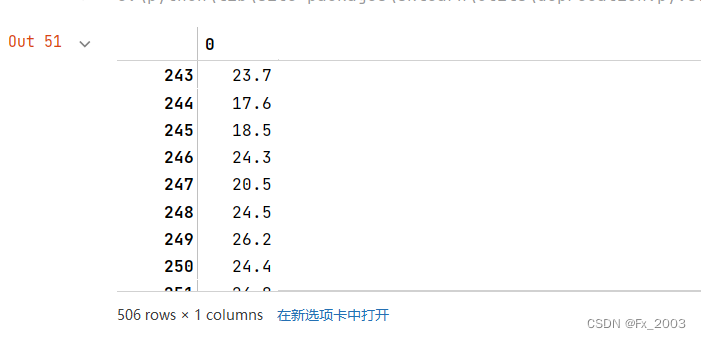
feature_names部分: 13个影响房价的因素
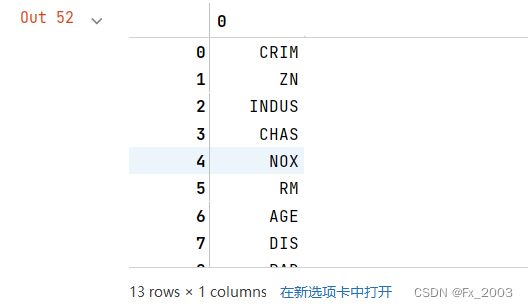
代码如下:
X = boston['data']
y = boston['target']
feature_names = boston['feature_names']
print(X.shape) # (506, 13)
# x # 506个房子(条数据),影响房价的13个属性
print(y.shape) # (506,) 506个房价
print(feature_names)
print(feature_names.shape) #(13,) 13个具体指标
#['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO''B' 'LSTAT']输出如下:

二、拆分训练集和预测集
1、避免随机性我们打乱以下数据
# 506个数据、样本
# 拆分成两份:80% 20%
# 80%:训练集
# 20%:验证集
index = np.arange(506) #生成0-505的‘索引’
np.random.shuffle(index) # 打乱索引
index
2、拆分
train_index = index[:405] # 80%约为405个
test_index = index[405:] # 剩余验证
print(type(train_index)) # <class 'numpy.ndarray'>
# 训练集
X_train = X[train_index] # 用打乱后数组里面的“索引” 去取数据
y_train = y[train_index]
# 验证集
X_test = X[test_index]
y_test = y[test_index]
# 训练集第一个数据
print(X_train[0])输出如下:

注:e-01(科学计数法)
三、训练模型
from IPython.core.display_functions import display
model = LinearRegression(fit_intercept=True)
model.fit(X_train, y_train)
print(model.coef_,model.intercept_)model.coef_:斜率 正值说明正相关,负值说明负相关model.intercept_:截距(用的默认的----fit_intercept=True)

四、开始预测
# 开始预测
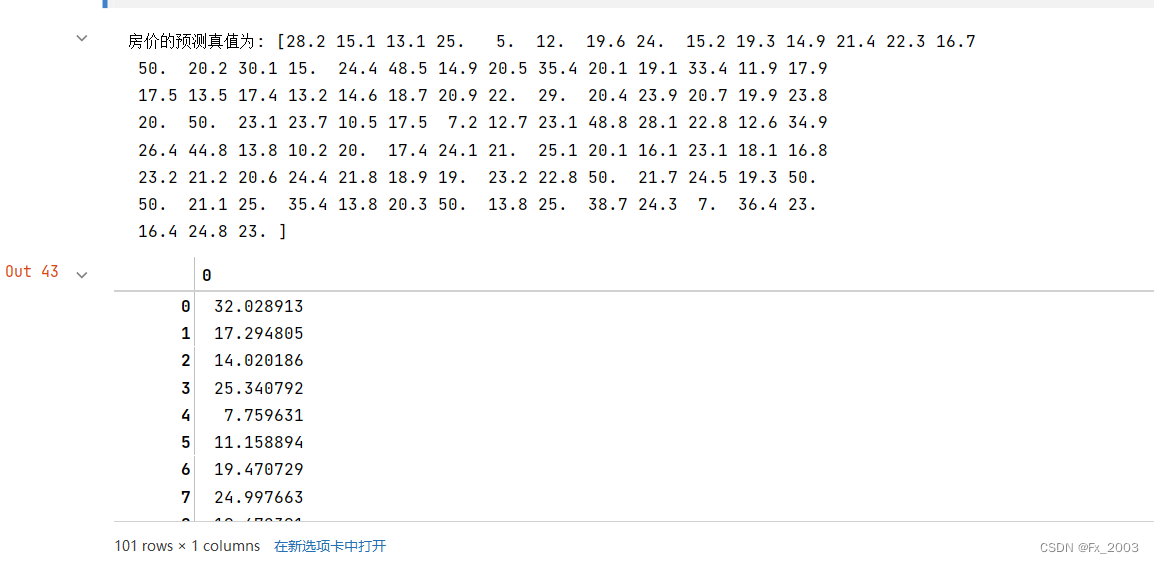
y_pred = model.predict(X_test)
print("房价的预测真值为:",y_test)
# print("通过训练后获得的预测值:",y_pred)
y_pred
输出如下:
五、评价
print("给模型打分:",model.score(X_test, y_test))输出如下:
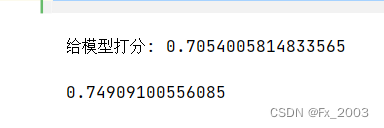
越接近1说明拟合的方程越好

















 1015
1015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









