



 文章对比分析了国内几款知名大模型在语言理解、知识丰富性、逻辑推理和内容生成能力上的表现,指出AI技术正快速进化,但仍有提升空间。
文章对比分析了国内几款知名大模型在语言理解、知识丰富性、逻辑推理和内容生成能力上的表现,指出AI技术正快速进化,但仍有提升空间。
自从 chatGPT 火热出圈,由生成式 AI 掀起的全球人工智能新浪潮就拉开了序幕,围绕认知大模型的类 ChatGPT 技术和产品正在不断涌现。
对于国内用户来说,目前不少大模型产品已经开放内测。不过,目前这些大模型产品在完善度、功能性、易用性等方面都各有不同,那让我们用几个常用的AI平台来感受一下国产AI进化到了哪一步。目前我们选择了知名度比较高的四款产品,分别是某心一言、某飞星火、某义千问和某脑。

一、语言理解能力测试
AI 大模型的本质其实就是大语言模型,因此语言理解可以说是影响各种大模型产品体验的基础要素。这里小编先测试上面四款产品对中文语意的理解能力——语意理解
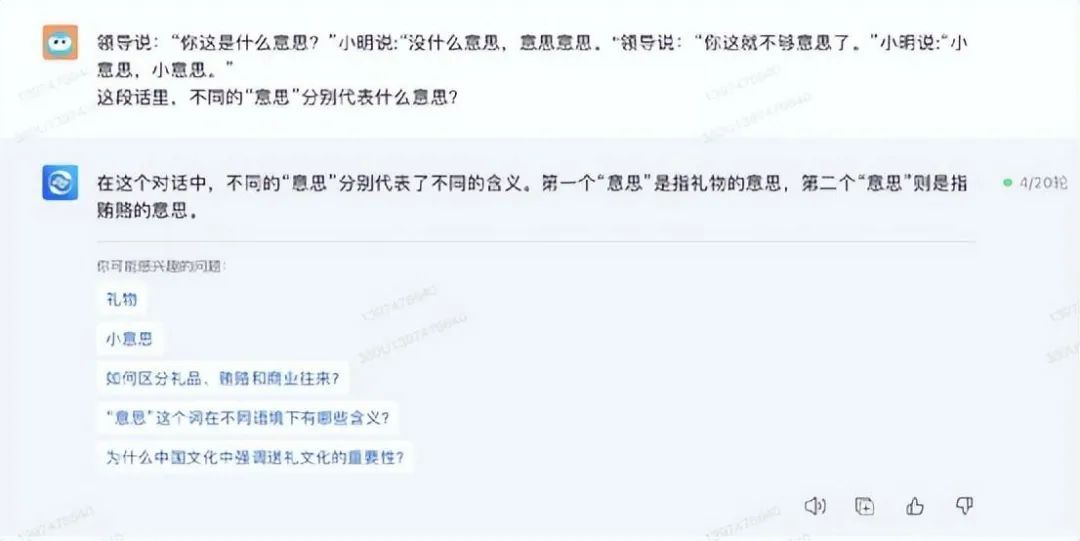
首先用经典的一词多意的段子来考验大模型们:
领导说:“你这是什么意思?”小明说:“没什么意思,意思意思。" 领导说:“你这就不够意思了。”小明说:“小意思,小意思。”
这段话里,不同的“意思”分别代表什么意思?
先看某心一言的解释,具体、准确,没有遗漏:

某义千问不仅回答了每个“意思”的意思,更给出了职场沟通的建议,回答很有逻辑性:

某飞星火的回答也是比较靠谱的,对每个“意思”的解释相比前两者更详尽深入,特别是最后一句,讯飞星火对一句话里的两个“小意思”都做了解释。

某脑的回答就有点简单了,回答得比较模糊笼统:
二、知识丰富性测试
很多人会用 AI 大模型会取代搜索引擎,因为用大模型搜索各种知识类信息很方便,还没有广告。这时候大模型的知识丰富度就比较重要了。本次测试IT之家针对四个类别的知识对所选大模型进行考验测试——生活常识类。
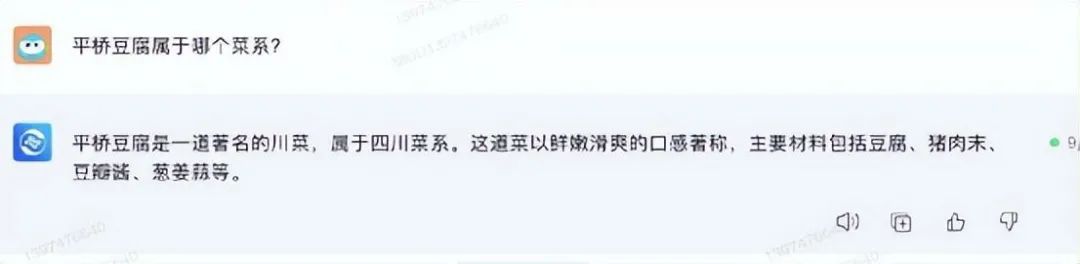
生活常识方面,IT之家首先用“平桥豆腐属于哪个菜系?”分别问四款大模型。其中,某飞星火和某心一言给出了正确回答,属于淮扬菜,而且还给出了这道菜的做法。


这个问题中,某义千问和某脑回答错误,分别说成了豫菜和川菜。

三、逻辑推理能力测试
AI 大模型是否足够聪明,很大程度上取决于大模型是否具备足够强大的逻辑推理能力。因此本次横评,IT之家也准备了一些逻辑思维相关的考题来分别考验四款大模型——逻辑推理问题测试。
首先,用一个经典的逻辑推理问题来考验参与评测的 AI 大模型产品,问题如下:
“小明牵着一只狗和两只小羊回家,路上遇到一条河,没有桥,只有一条小船,并且船很小,他每次只能带一只狗或一只小羊过河。你能帮他想想办法,把狗和小羊都带过河去,又不让狗吃到小羊吗?”
对于这个问题,某心一言的回答就出现了小问题,先带一只羊过河,那么原岸的狗就会将另一只羊吃掉看得人云里雾里。

某义千问的回答也不对。

某飞星火的回答基本正确。

某脑这次的回答还是比较完美的,步骤全,而且能看懂。

四、内容生成能力测试
用户使用大模型的另一大用途就是让它们帮助写一些实用性文案,比如招聘文案、通知文书、店面评价、甚至让他们创作文章、小说、论文等等。我们把这些统称为内容生成能力。这也应该成为评测体验大模型的重要项目之一——文案创作
我们首先来看四款大模型产品的实用文案创作能力,小编让分别它们写一段招聘文案,并给出了详细要求。
还是先看某心一言的回答,它创作的文案是符合要求的,并且条理清晰,风格也没跑偏,属于稍微改改就能直接用的水平。

某义千问创作的文案整体是不错的,但是最后一段让人看着有点蒙圈,可见它对要求的理解还是有点问题。

某脑创作的文案有点过于简洁了,虽然条件也都符合,但文案看着有些机械,格式也不够清晰明了。

最后是某飞星火,它创作的文案也是挺好的,基本没什么问题,也是稍微改改就能直接使用了。

最后要说的是本次测试所使用的问题样本毕竟有限,实际选择时,大家还是要根据自身的感受来选用适合自己的 AI 大模型。同时也期待随着云端、终端算力的增强,训练推理的轮数不断深入以及语料库的持续丰富,各家国产 AI 大模型产品能够千帆竞渡,在可用性、成熟度和使用体验方面能够以比想象中更快的速度进化,持续推动 AI 深刻变革我们的生产和生活。

迦太利华(自由客)是高端灵活用工、服务外包、软件与互联网外包的开创者,是国内发展最快的软件与互联网外包服务企业之一,公司始终致力于探索新技术、新模式、新平台、新生态,以满足中国市场不断发展的在软件、互联网及大数据类技术开发与运营的服务外包需求,业务范围涉及“高端灵活用工”和“技术服务”两大板块。已在北京、贵阳、上海、深圳、成都、杭州、青岛、广州等地成立分子公司,企业业务覆盖全国及港、澳,当下海外业务已拓展到美国及日韩,为中石油、中国建筑、中石化、国家电网、华能电力、中国人寿、新华保险、太平集团、IBM、德勤、埃森哲、源讯、抖音、美团、哔哩哔哩等众多国内大型国企、世界500强及独角兽企业提供过解决方案。


















 1378
1378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









