




 本文介绍了计算机视觉中的两种注意机制模型——SENet和CBAM。SENet通过Squeeze-and-Excitation操作建模特征通道间的相互依赖,而CBAM则同时在通道和空间维度上引入注意力,提升网络模型的特征提取能力。这两种模型灵感来源于人眼视觉感知的中央凹和视域特性,能有效增强CNN的表现。
本文介绍了计算机视觉中的两种注意机制模型——SENet和CBAM。SENet通过Squeeze-and-Excitation操作建模特征通道间的相互依赖,而CBAM则同时在通道和空间维度上引入注意力,提升网络模型的特征提取能力。这两种模型灵感来源于人眼视觉感知的中央凹和视域特性,能有效增强CNN的表现。
前言:
接着上篇介绍经典卷积神经网络模型的博文,这两天又发现一类仿生特性的视觉注意机制模型在近两年中逐渐被提出。其中比较有代表性的模型有在2017年ImageNet中获得分类组关键的SENet,以及2018年结合了空间和通道双注意机制的CBAM模型。
毕竟灵感来自人眼的感知,所以在正式介绍模型前增加了一段人眼视觉感知的背景内容。
目录标题
人眼视觉感知中的注意力特性
中央凹(foveal)
感觉光暗的杆状细胞和感觉色彩的锥状细胞在视网膜表面并不是平均分布的,在感知中起重要作用的锥细胞大部分集中在视网膜中的一小片称为黄点的地方。因此我们在观看景物和阅读时,注意力只是集中在视野范围一半不到的区域。
黄斑中央凹陷称中央凹,是视网膜中视觉(辨色力、分辨力)最敏锐的区域。此处视网膜最薄,只有色素上皮细胞和视锥细胞两层细胞,双极细胞和节细胞均斜向周围排列。此处视锥细胞与双极细胞均一对一联系,故视觉最为敏锐而精确,称中心视觉。
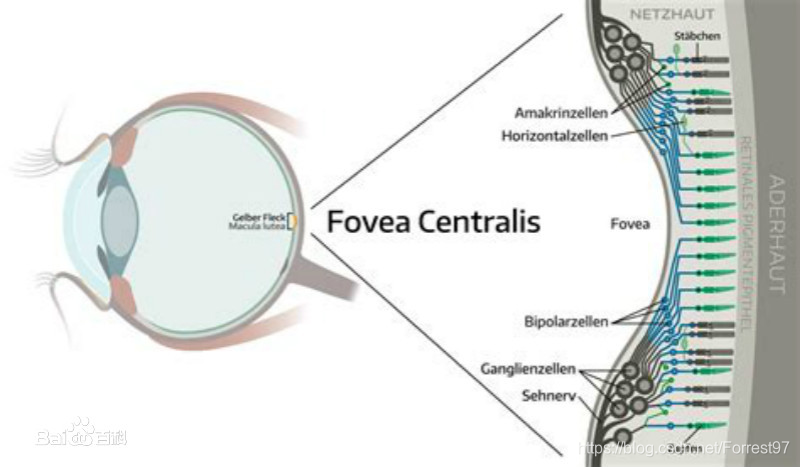
参考:https://baike.baidu.com/item/%E4%B8%AD%E5%A4%AE%E5%87%B9/1365085?fr=aladdin
https://baike.baidu.com/item/%E8%A7%86%E8%A7%89%E6%84%9F%E7%9F%A5/1473317?fr=aladdin
人眼视域(Field of View)
顾名思义就是视力可见区域,需要拆成横向和纵向两种来看。人有两只眼睛,两眼视物(Binocular Vision)系统的优点之一是视域更宽,人类横向视域最大接近190度。但空间感知、颜色识别最好的区域只有50到60度。
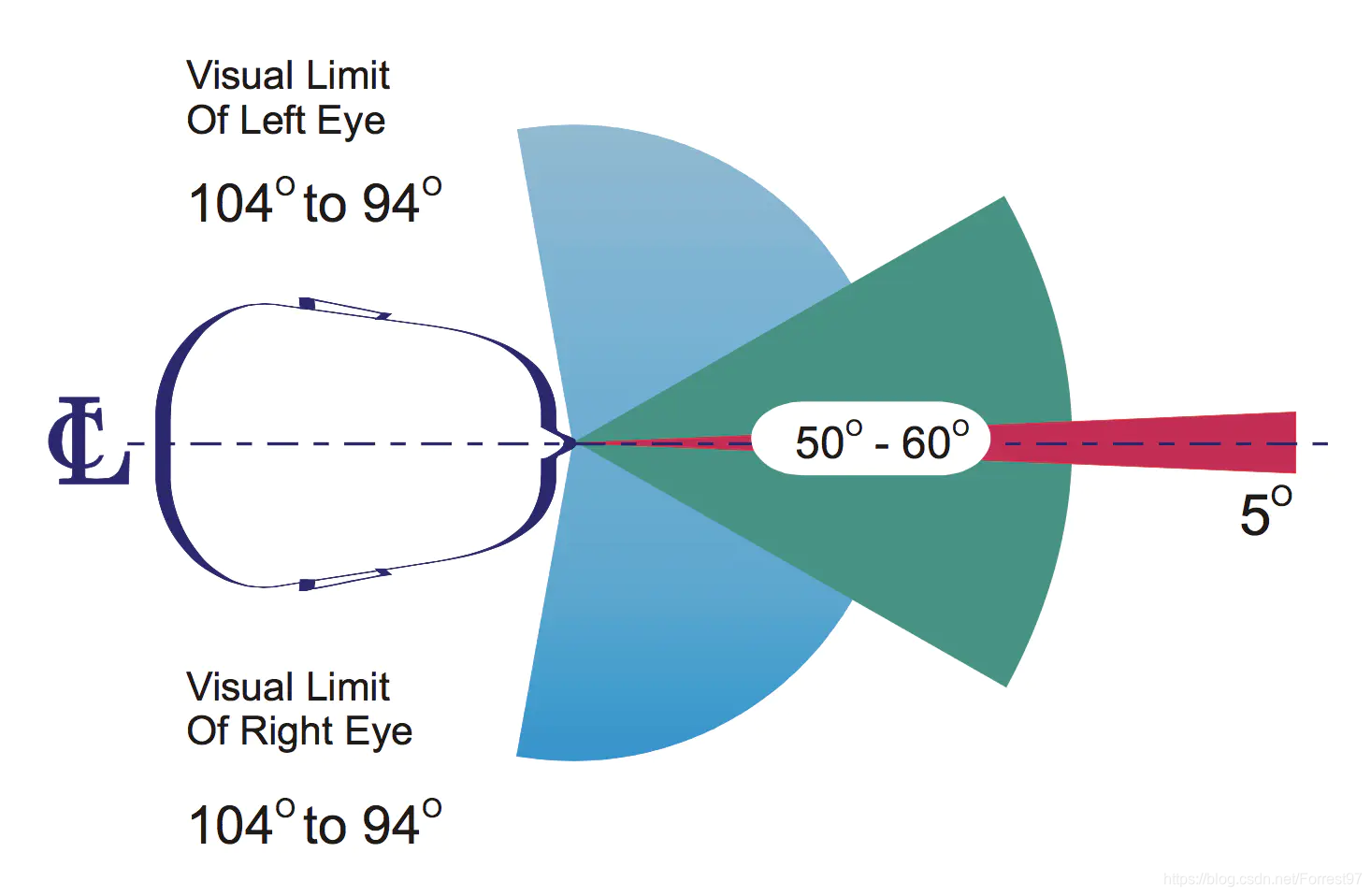
纵向视域如上图所示最大接近120度,颜色识别界限在55度左右。站立情况下视线会低于水平10度;坐着时低于水平15度。
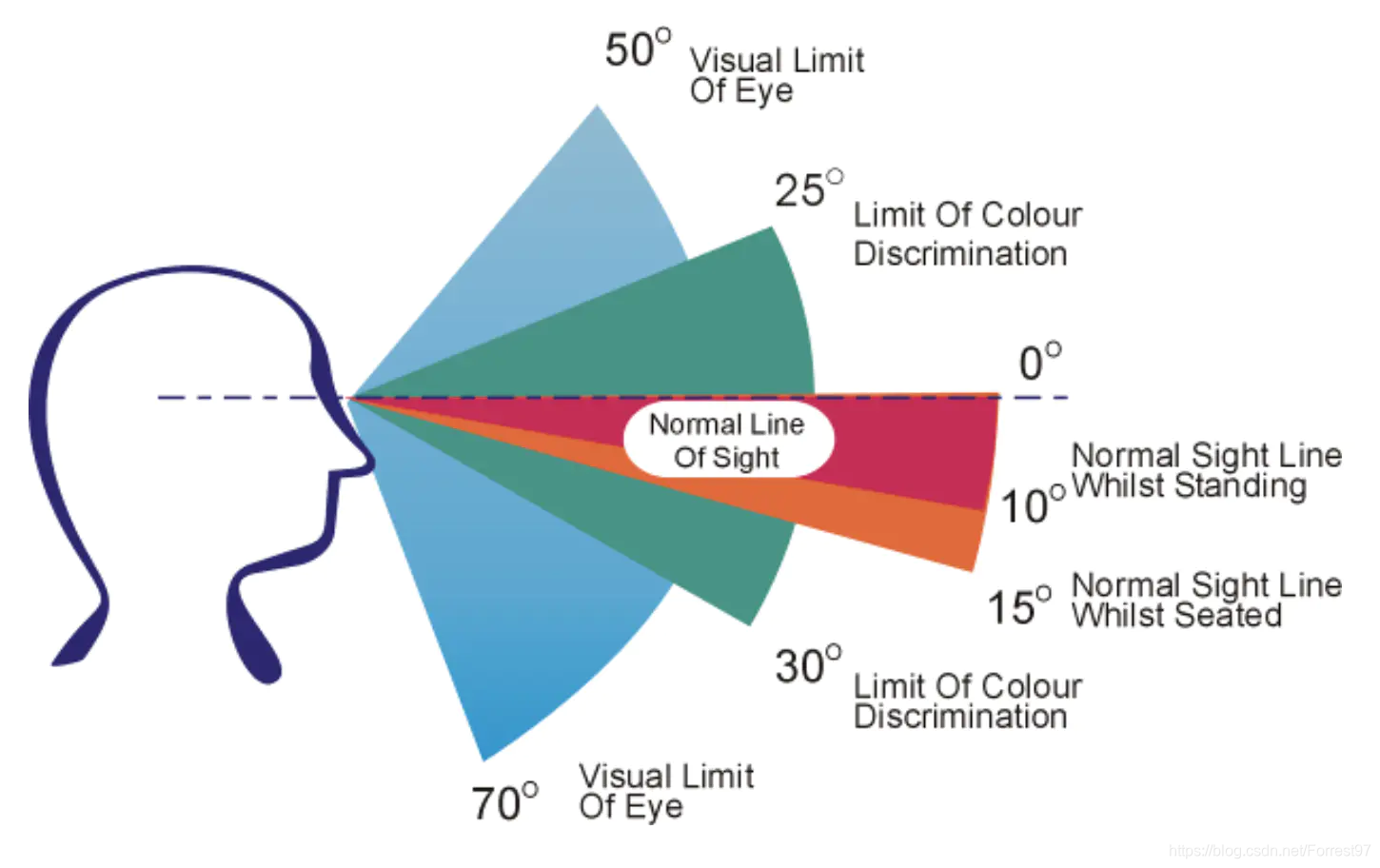
参考:https://www.jianshu.com/p/5312677111e3
当我们要看清一件对象时,我们会转动眼球,直至影像聚焦在视野的中央凹上。离开中央凹越远,感光细胞越少,影像越不清晰。如影像聚焦在黄斑以外的地方,我们可看见一件对象的存在,但未必知道这件对象是甚么。
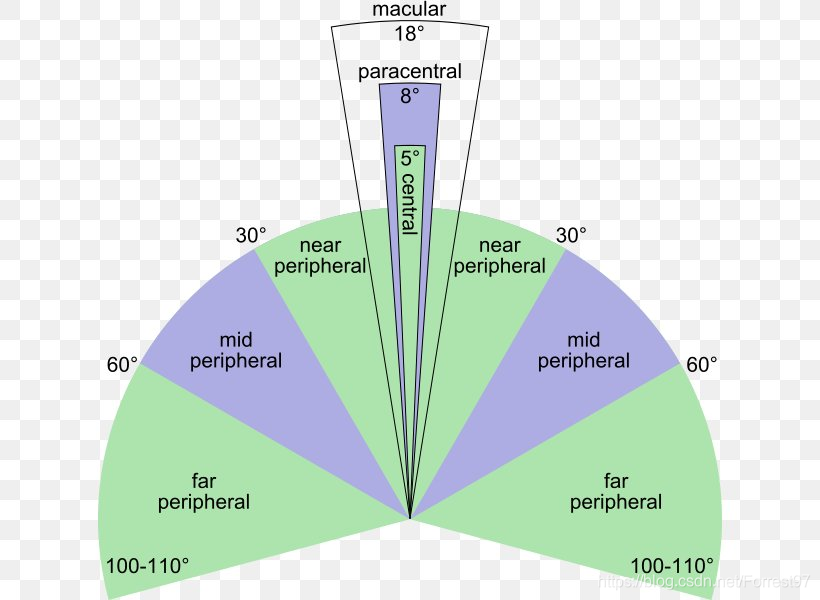

计算机视觉感知中的注意特性
SENet:Squeeze-and-Excitation Networks
背景
卷积神经网络由一系列卷积层、非线性层和下采样层构成,这样它们能够从全局感受野上去捕获图像的特征来进行图像的描述。而卷积核作为卷积神经网络的核心,通常被看做是在局部感受野上,将空间上(spatial)的信息和特征维度上(channel-wise)的信息进行聚合的信息聚合体。已经有很多工作在空间维度上来提升网络的性能, 如 Inception 结构中嵌入了多尺度信息,聚合多种不同感受野上的特征来获得性能增益;在 Inside-Outside 网络中考虑了空间中的上下文信息;还有将 Attention 机制引入到空间维度上。
网络是否可以从其他层面来考虑去提升性能,比如考虑特征通道之间的关系?我们的工作就是基于这一点并提出了 Squeeze-and-Excitation Networks(简称 SENet)。在我们提出的结构中,Squeeze 和 Excitation 是两个非常关键的操作,所以我们以此来命名。我们的动机是希望显式地建模特征通道之间的相互依赖关系。另外,我们并不打算引入一个新的空间维度来进行特征通道间的融合,而是采用了一种全新的「特征重标定」策略。具体来说,就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征。
网络框架
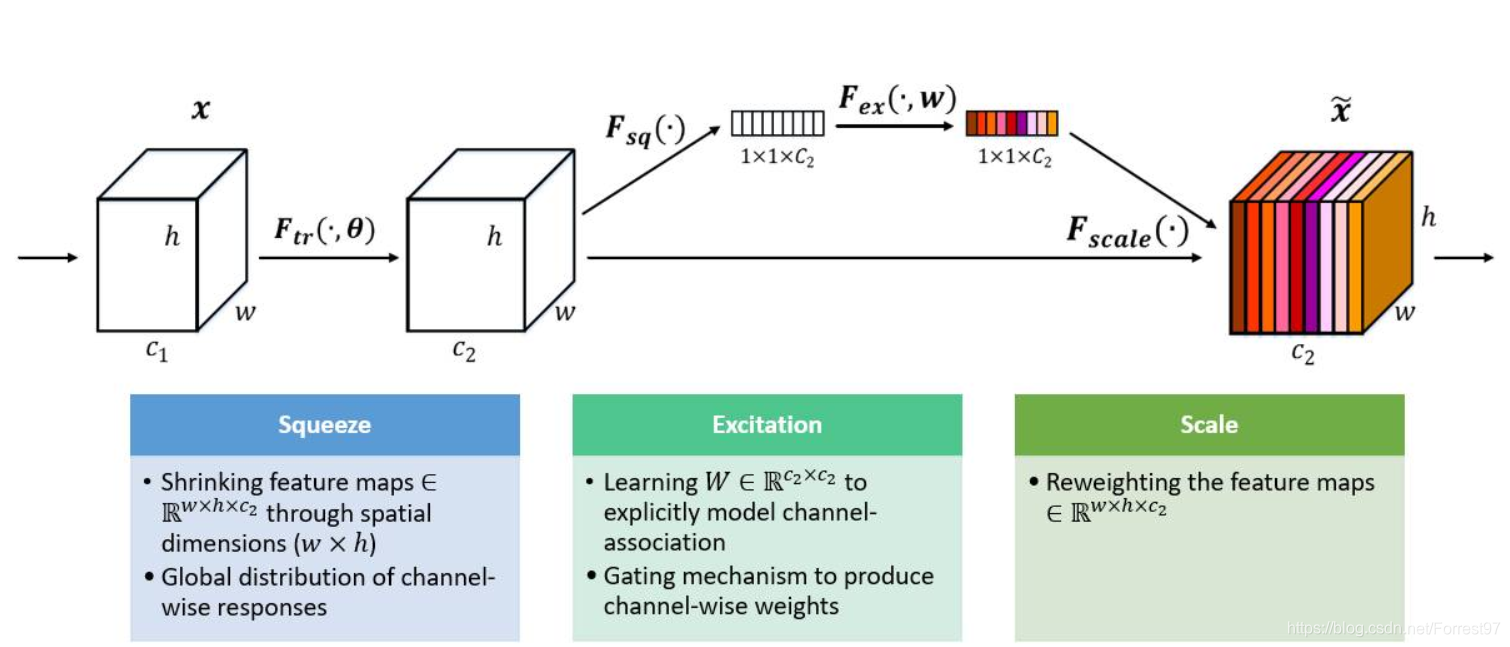
上图是我们提出的 SE 模块的示意图。给定一个输入 x,其特征通道数为 c_1,通过一系列卷积等一般变换后得到一个特征通道数为 c_2 的特征。与传统的 CNN 不一样的是,接下来我们通过三个操作来重标定前面得到的特征。
首先是 Squeeze 操作,我们顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。
其次是 Excitation 操作,它是一个类似于循环神经网络中门的机制。通过参数 w 来为每个特征通道生成权重,其中参数 w 被学习用来显式地建模特征通道间的相关性。
最后是一个 Reweight 的操作,我们将 Excitation 的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
Tensorflow 2.0代码实现:
Squeeze 操作: 全局池化将每个Channel 上的二维维度压缩成一个单一值
Excitation 操作:两个全连接层和一个sigmoid
Reweight 的操作:维度增加与每个对应特征图相乘
def SE_moudle(input_xs,reduction_ratio = 16.):
shape = input_xs.get_shape().as_list()
se_module = tf.reduce_mean(input_xs,[1,2])
se_module = tf.keras.layers.Dense(shape[-1]/reduction_ratio,activation=tf.nn.relu)(se_module)
se_module = tf.keras.layers.Dense(shape[-1], activation=tf.nn.relu)(se_module)
se_module = tf.nn.sigmoid(se_module)
se_module = tf.reshape(se_module,[-1,1,1,shape[-1]])
out_ys = tf.multiply(input_xs,se_ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7531
7531




 到【灌水乐园】发言
到【灌水乐园】发言







