




 提出一种层次化文本到图像合成方法,通过推断语义布局,生成符合文本描述的复杂图像,实验证明能提高图像质量和语义准确性。
提出一种层次化文本到图像合成方法,通过推断语义布局,生成符合文本描述的复杂图像,实验证明能提高图像质量和语义准确性。
CVPR 2018 《Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis》

本文完成的也是Text-to-Image的工作,但是如果直接完成输入文本空间到生成图像像素空间的映射,由于数据的高维性,将很难找到合适的映射方式。因此作者在text-to-piexl中间加了几步,将整个任务分解为多个子任务多步进行。
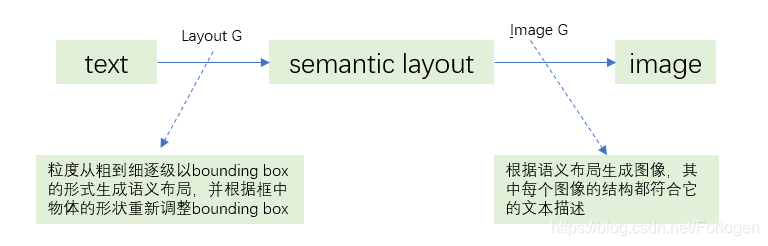
这样的生成方式具有如下的优点:
- 生成在语义上更有意义的图像
- 通过修改生成的场景布局,允许标注生成的图像、用户控制生成的过程
- 实现生成匹配复杂文本描述的复杂图像
具体的效果如下所示:用户输入“People riding on elephants that are walking through a river.”后,首先根据文本针对每个实体生成bounding box,然后根据具体的形状调整bounding box的细节部分,生成binary mask,最后根据语义布局生成最后的图像。
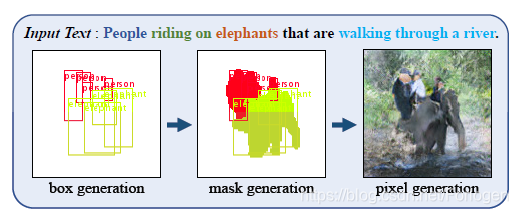
作者通过在MS-COCO数据集上进行实验,证明了提出的模型不仅可以提高生成图像的质量,同时也可以生成更符合语义描述的图像。
模型的整体架构如下所示:
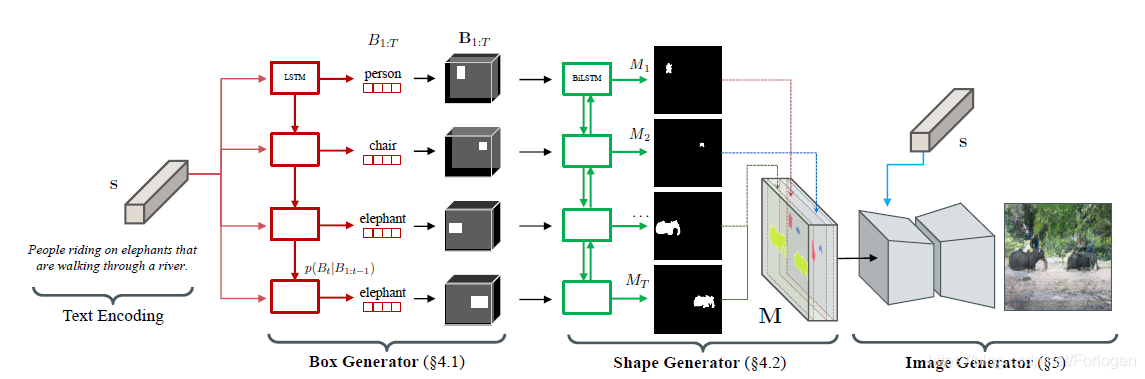
按照图像的生成过程,模型主要包括:
- Text encoding:将输入文本转换为嵌入向量的形式,作为下一阶段Box generator的输入
- Box generator:根据文本向量生成相对粗粒度的布局,输出为bounding bod的集合 B 1 : T = { B 1 , … , B T } B_{1 : T}=\left\{B_{1}, \dots, B_{T}\right\} B1:T={B1,…,BT},其中 B t B_{t} Bt表示第 t t t个实体的位置、形状和类别
- Shape generator:根据上一阶段bounding box的集合预测框中实体的形状,输入二值掩码(binary mask)的集合 M 1 : T = { M 1 , … , M T } M_{1 : T}=\left\{M_{1}, \ldots, M_{T}\right\} M1:T={M1,…,MT},其中 M t M_{t} Mt定义了第 t t t个实体的前景形状
- Image generator:聚合实体掩码和文本嵌入作为输入,通过将语义布局转换为匹配文本描述的像素来生成图像
这样通过将图像生成过程限制在前面得到的语义布局上,使得模型可以生成具有详细形状的实体,更容易识别其中的语义内容。下面分别来看一下每一部分的实现原理。
Bounding Box Generation
为了将bounding box和图像中具体的实体对应起来,这里在 B t B_{t} Bt中加了实体的类别标签,记为 B t = ( b t , l t ) B_{t}=(b_{t},l_{t}) Bt=(bt,lt),其中 b t = [ b t , x , b t , y , b t , w , b t , h ] ∈ R 4 b_{t}=\left[b_{t, x}, b_{t, y}, b_{t, w}, b_{t, h}\right] \in \mathbb{R}^{4} bt=[bt,x,bt,y,bt,w,bt,h]∈R4表示框的位置和大小,整个框的范围可通过坐标 ( x , y ) (x,y) (x,y)和宽 w w w和高 h h h计算而得。 l t ∈ { 0 , 1 } L + 1 l_{t} \in\{0,1\}^{L+1} lt∈{0,1}L+1是one-hot向量,表示 L L L个类别实体, L + 1 L+1 L+1作为终止的标志,即当向量的 L + 1 L+1 L+1维上取值为1时,表示已生成图中所有实体的bounding box。
因此使用自回归解码器的框生成器(box generator)将实现输入文本 s s s到实体框的集合 B 1 : T = { B 1 , … , B T } B_{1 : T}=\left\{B_{1}, \dots, B_{T}\right\} B1:T={B1,…,BT}的随机映射,记为 B ^ 1 : T ∼ G b o x ( s ) \widehat{B}_{1 : T} \sim G_{\mathrm{box}}(\mathrm{s}) B 1:T∼Gbox(s)。直接完成 s s s到 B 1 : T B_{1 : T} B1:T的映射难度较大,因此这里在计算联合概率 p ( B 1 : T ∣ s ) p\left(B_{1 : T} | \mathbf{s}\right) p(B1:T∣s)时将其分解为多个条件概率的乘积,即每一个框的生成都受前面已经生成的框的影响,具体表示为 p ( B 1 : T ∣ s ) = ∏ t = 1 T p ( B t ∣ B 1 : t − 1 , s ) p\left(B_{1 : T} | \mathbf{s}\right)=\prod_{t=1}^{T} p\left(B_{t} | B_{1 : t-1}, \mathbf{s}\right) p(B1:T∣s)=t=1∏Tp(Bt∣B1:t−1,s)而这样的生成流程和LSTM的过程很相似,因此作者这里也是使用了LSTM来计算右侧的条件概率。在实际的生成过程中,往往是先由实体得到类标签 l t l_{t} lt,然后根据 l t l_{t} lt得到 b t b_{t} bt,最后根据 B t = ( b t , l t ) B_{t}=(b_{t},l_{t}) Bt=(bt,lt)和上式计算得到最后的联合概率 p ( B 1 : T ∣ s ) p\left(B_{1 : T} | \mathbf{s}\right) p(B1:T∣s)。这个过程可简单的表示为 p ( B t ∣ ⋅ ) = p ( b t , l t ∣ ⋅ ) = p ( l t ∣ ⋅ ) p ( b t ∣ l t , ⋅ ) p\left(B_{t} | \cdot\right)=p\left(\mathbf{b}_{t}, l_{t} | \cdot\right)=p\left(\boldsymbol{l}_{t} | \cdot\right) p\left(\mathbf{b}_{t} | \boldsymbol{l}_{t}, \cdot\right) p(Bt∣⋅)=p(bt,lt∣⋅)=p(lt∣⋅)p(bt∣lt,⋅)
这样又将一个条件概率的计算分解为两个条件概率的计算,而作者这里又使用了高斯混合模型(GMM)对其进行建模: p ( l t ∣ B 1 : t − 1 , s ) = Softmax ( e t ) p ( b t ∣ l t , B 1 : t − 1 , s ) = ∑ k = 1 K π t , k N ( b t ; μ t , k , Σ t , k ) \begin{aligned} p\left(l_{t} | B_{1 : t-1}, \mathbf{s}\right) &=\operatorname{Softmax}\left(\mathbf{e}_{t}\right) \\ p\left(\mathbf{b}_{t} | l_{t}, B_{1 : t-1}, \mathbf{s}\right) &=\sum_{k=1}^{K} \pi_{t, k} \mathcal{N}\left(\mathbf{b}_{t} ; \boldsymbol{\mu}_{t, k}, \mathbf{\Sigma}_{t, k}\right) \end{aligned} p(lt∣B1:t−1,s)p(bt∣lt,B1:t−1,s)=Softmax(et)=k=1∑Kπt,kN(bt;μt,k,Σt,k)其中上式中的参数 e t 、 π t , k 、 μ t , k 、 Σ t , k e_{t}、\pi_{t,k}、\mu_{t,k}、\Sigma_{t,k} et、πt,k、μt,k、Σt,k都是由LSTM在每个时间步 t t t学习得到的。具体可表示为 [ h t , c t ] = LSTM ( B t − 1 ; [ h t − 1 , c t − 1 ] ) l t = W l h t + b l θ t x y = W x y [ h t , l t ] + b x y θ t w h = W w h [ h t , l t , b x , b y ] + b w h \begin{aligned}\left[h_{t}, c_{t}\right] &=\operatorname{LSTM}\left(B_{t-1} ;\left[h_{t-1}, c_{t-1}\right]\right) \\ l_{t} &=W^{l} h_{t}+\mathbf{b}^{l} \\ \boldsymbol{\theta}_{t}^{x y} &=W^{x y}\left[h_{t}, l_{t}\right]+\mathbf{b}^{x y} \\ \boldsymbol{\theta}_{t}^{w h} &=W^{w h}\left[h_{t}, l_{t}, b_{x}, b_{y}\right]+\mathbf{b}^{w h} \end{aligned} [ht,ct]ltθtxyθtwh=LSTM(Bt−1;[ht−1,ct−1])=Wlht+bl=Wxy[ht,lt]+bxy=Wwh[ht,lt,bx,by]+bwh其中 θ t = [ π t , 1 : K ⋅ , μ t , 1 : K ∗ , Σ t , 1 : K ] \theta_{t}=\left[\boldsymbol{\pi}_{t, 1 : K}^{\cdot}, \boldsymbol{\mu}_{t, 1 : K}^{*}, \boldsymbol{\Sigma}_{t, 1 : K}\right] θt=[πt,1:K⋅,μt,1:K∗,Σt,1:K]就是包含所需参数的向量。
作者为了减少计算的难度,在计算 p ( b t ∣ l t ⋅ ) p(b_{t}|l_{t}\cdot) p(bt∣lt⋅)是并不是直接计算得到 b t = [ b t , x , b t , y , b t , w , b t , h ] b_{t}=\left[b_{t, x}, b_{t, y}, b_{t, w}, b_{t, h}\right] bt=[bt,x,bt,y,bt,w,bt,h],而也是分为两部进行 p ( b t x , b t y ∣ l t ) = ∑ k = 1 K π t , k x y N ( b t x , b t y ; μ t , k x y , Σ t , k x y ) p ( b t w , b t h ∣ b t x , b t y , l t ) = ∑ i = k K π t , k w h N ( b t w , b t h ; μ t , k w h , Σ t , k w h ) \begin{aligned} p\left(b_{t}^{x}, b_{t}^{y} | l_{t}\right) &=\sum_{k=1}^{K} \pi_{t, k}^{x y} \mathcal{N}\left(b_{t}^{x}, b_{t}^{y} ; \boldsymbol{\mu}_{t, k}^{x y}, \boldsymbol{\Sigma}_{t, k}^{x y}\right) \\ p\left(b_{t}^{w}, b_{t}^{h} | b_{t}^{x}, b_{t}^{y}, l_{t}\right) &=\sum_{i=k}^{K} \boldsymbol{\pi}_{t, k}^{w h} \mathcal{N}\left(b_{t}^{w}, b_{t}^{h} ; \boldsymbol{\mu}_{t, k}^{w h}, \boldsymbol{\Sigma}_{t, k}^{w h}\right) \end{aligned} p(btx,bty∣lt)p(btw,bth∣btx,bty,lt)=k=1∑Kπt,kxyN(btx,bty;μt,kxy,Σt,kxy)=i=k∑Kπt,kwhN(btw,bth;μt,kwh,Σt,kwh)
这一阶段训练过程的目标函数如下所示,即最大化根据类标签生成接近真实情况的框的概率 min L b o x = − λ l 1 T ∑ t = 1 T l t ∗ log p ( l t ) − λ b 1 T ∑ t = 1 T log p ( b t ∗ ) \min\mathcal{L}_{\mathrm{box}}=-\lambda_{l} \frac{1}{T} \sum_{t=1}^{T} l_{t}^{*} \log p\left(l_{t}\right)-\lambda_{b} \frac{1}{T} \sum_{t=1}^{T} \log p\left(\mathbf{b}_{t}^{*}\right) minLbox=−λlT1t=1∑Tlt∗logp(lt)−λbT1t=1∑Tlogp(bt∗)
其中 T T T表示实体的个数; λ l = 4 \lambda_{l}=4 λl=4和 λ b = 1 \lambda_{b}=1 λb=1是超参数, b t ∗ b_{t}^* bt∗和 l t ∗ l_{t}^* lt∗是第 t t t个实体真实的坐标和类标签。
Shape Generation
在前一阶段已经得到了图中所有实体的bounding box,但是它们都是一些矩形的框,并不能准确的表示出框中物体的形状,进而准确的表示框中实体。因此这一阶段实现以二值掩码的形式
M
t
∈
R
H
×
W
M_{t} \in \mathbb{R}^{H \times W}
Mt∈RH×W预测框中实体具体的形状,实现下面的过程
M
^
1
:
T
=
G
m
a
s
k
(
B
1
:
T
,
z
1
:
T
)
\widehat{M}_{1 : T}=G_{\mathrm{mask}}\left(\mathbf{B}_{1 : T}, \mathbf{z}_{1 : T}\right)
M
1:T=Gmask(B1:T,z1:T)
这里
B
1
:
T
B_{1:T}
B1:T已经变成了取值只为0或1的二值形式,
z
z
z是采样自高斯分布
N
(
0
,
I
)
\mathcal{N}(0, I)
N(0,I)的随机噪声。那么一个好的
M
t
M_{t}
Mt应满足以下的两个要求:
- M t M_{t} Mt应该匹配 B t B_{t} Bt所表示的实体的位置和类别信息,且只能表示一个独立实体
- 预测的形状应符合文本的描述
这一部分的模型架构如下所示:
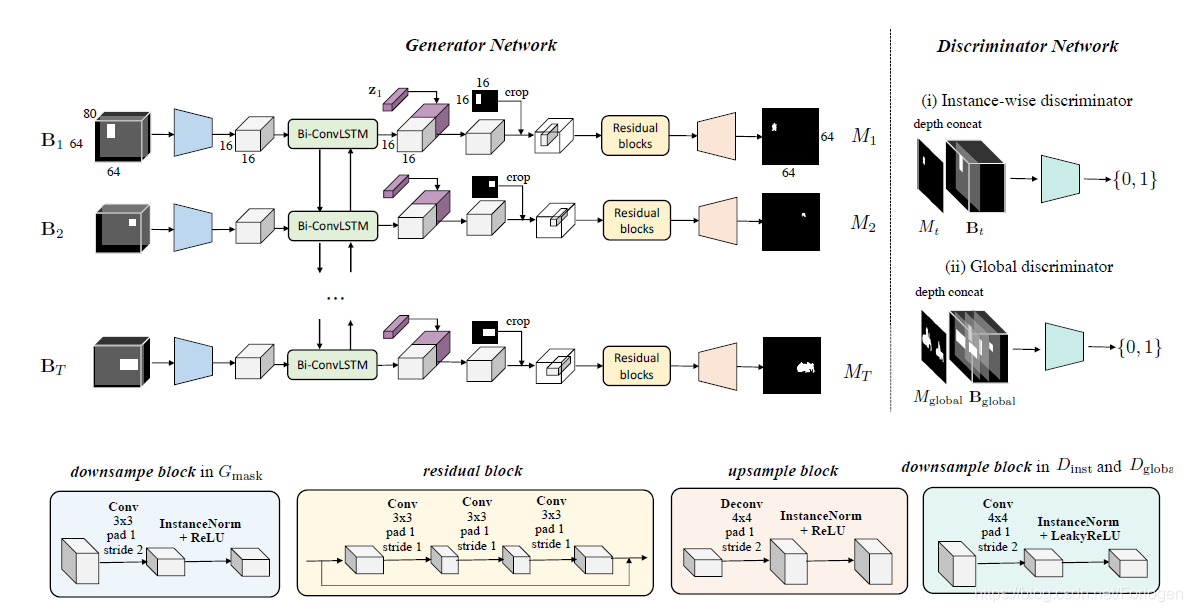
这个模型是一个卷积循环神经网络。具体的流程为:
- 每个 B t B_{t} Bt 经过两个步长为2、填充为1、卷积核大小为 3 × 3 3 \times 3 3×3的下采样块,接着做Instance Normalization(对单个layer的所有像素求均值和标准差),经过RELU层最终得到编码的T个 16 × 16 × d 16 \times 16 \times d 16×16×d的特征图。
- T个map作为每一个双向 CONV-LSTM的输入。在每一个LSTM输出的前段增加随机向量 z i z_{i} zi。然后经过一层卷积后,按照之前将分离的 B t B_{t} Bt转化为一个张量的形式,它是将box框内的值保留,box外的值置为0
- 然后通过残差块,接着进行上采样得到一个mask
最后使用判别器判断生成MASK是否符合我们前面提到的两个要求
-
为了满足第一个条件,这里使用instance-wise的D,将每一步得到的 B t B_{t} Bt 和与之对应的 M t M_{t} Mt ,在通道方向进行深度相连,然后D判定是否正确。
目标函数为: L inst ( t ) = E ( B t , M t ) [ log D inst ( B t , M t ) ] + E B t , z t [ log ( 1 − D inst ( B t , G mask ( t ) ( B 1 : T , z 1 : T ) ) ) ] \begin{aligned} \mathcal{L}_{\text { inst }}^{(t)}=& \mathbb{E}_{\left(\mathbf{B}_{t}, M_{t}\right)}\left[\log D_{\text { inst }}\left(\mathbf{B}_{t}, M_{t}\right)\right] \\ &+\mathbb{E}_{\mathbf{B}_{t}, \mathbf{z}_{t}}\left[\log \left(1-D_{\text { inst }}\left(\mathbf{B}_{t}, G_{\text { mask }}^{(t)}\left(\mathbf{B}_{1 : T}, \mathbf{z}_{1 : T}\right)\right)\right)\right] \end{aligned} L inst (t)=E(Bt,Mt)[logD inst (Bt,Mt)]+EBt,zt[log(1−D inst (Bt,G mask (t)(B1:T,z1:T)))]然后对所有实体的结果求平均 -
为了满足第二个条件,这里使用Global D。将输入变为所有的mask连接所有的 B t B_{t} Bt,同样下采样后,D判别生成是否合理。
因为图像中不同实体之间不是独立存在的,它们彼此之间存在着一些联系,因此这里将所有实体的mask聚合成一个全局的mask G global ( B 1 : T , z 1 : T ) = ∑ t G mask ( t ) ( B 1 : t , z 1 : t ) G_{\text { global }}\left(\mathbf{B}_{1 : T}, \mathbf{z}_{1 : T}\right)=\sum_{t} G_{\text { mask }}^{(t)}\left(\mathbf{B}_{1 : t}, \mathbf{z}_{1 : t}\right) G global (B1:T,z1:T)=∑tG mask (t)(B1:t,z1:t),那么目标函数为 L global = E ( B 1 : T , M 1 : T ) [ log D global ( B global , M global ) ] + E B 1 : T , z 1 : T [ log ( 1 − D global ( B global ( B global ( B 1 : T , z 1 : T ) ) ) ] \begin{array}{l}{\mathcal{L}_{\text { global }}=\mathbb{E}_{\left(\mathbf{B}_{1 : T}, M_{1 : T}\right)}\left[\log D_{\text { global }}\left(\mathbf{B}_{\text { global }}, M_{\text { global }}\right)\right]} \\ {\quad+\mathbb{E}_{\mathbf{B}_{1 : T, \mathbf{z}_{1 : T}}}\left[\log \left(1-D_{\text { global }}\left(\mathbf{B}_{\text { global }}\left(\mathbf{B}_{\text { global }}\left(\mathbf{B}_{1 : T}, \mathbf{z}_{1 : T}\right)\right)\right)\right]\right.}\end{array} L global =E(B1:T,M1:T)[logD global (B global ,M global )]+EB1:T,z1:T[log(1−D global (B global (B global (B1:T,z1:T)))]
此外作者发现附加一个重构损失项 L r e c \mathcal{L}_{\mathrm{rec}} Lrec(这里选择的是perceptual loss)会提高mask预测的准确性、训练的稳定性,记为: L r e c = ∑ l ∥ Φ l ( G g l o b a l ) − Φ l ( M g l o b a l ) ∥ \mathcal{L}_{\mathrm{rec}}=\sum_{l}\left\|\Phi_{l}\left(G_{\mathrm{global}}\right)-\Phi_{l}\left(M_{\mathrm{global}}\right)\right\| Lrec=l∑∥Φl(Gglobal)−Φl(Mglobal)∥
这一部分整体的目标函数为 L shape = λ i L inst + λ g L global + λ r L r e c \mathcal{L}_{\text { shape }}=\lambda_{i} \mathcal{L}_{\text { inst }}+\lambda_{g} \mathcal{L}_{\text { global }}+\lambda_{r} \mathcal{L}_{\mathrm{rec}} L shape =λiL inst +λgL global +λrLrec
Image generation
这一部分的模型架构如下所示,整个模型是一个encoder-decoder架构的卷积神经网络,它是对Pixel2Pixwl的改进
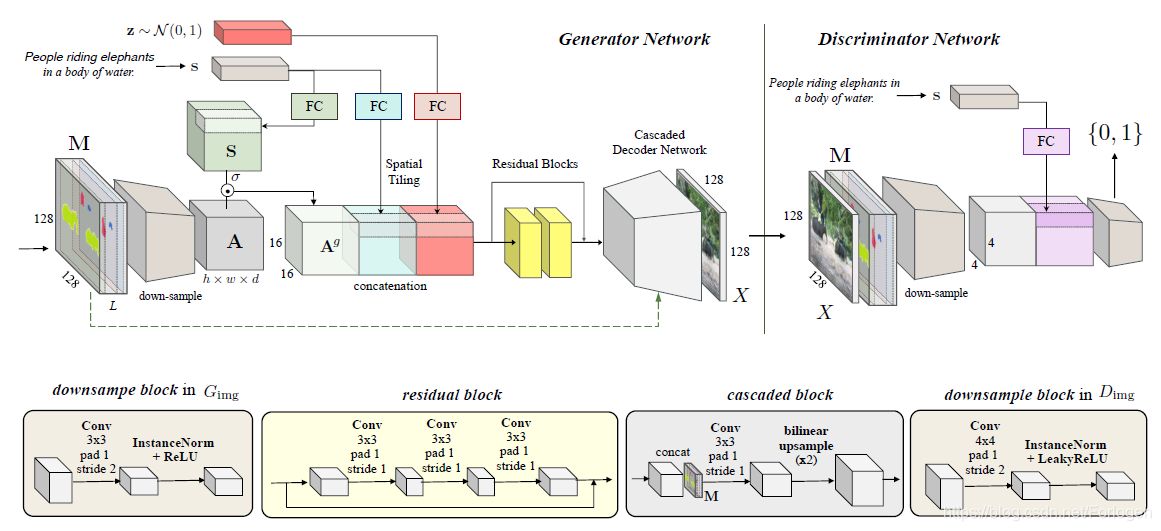
生成图像过程的表达式为 X ^ = G i m g ( M , s , z ) \widehat{X}=G_{\mathrm{img}}(\mathrm{M}, \mathrm{s}, \mathrm{z}) X =Gimg(M,s,z),其中 M M M为上一阶段生成的所有mask的聚合, S S S为输入文本的嵌入向量, z z z为随机噪声。具体流程为:
- M通过一系列的下采样层构建层特征 A ∈ R H × W × d A\in R^{H \times W \times d} A∈RH×W×d。为了自适应地选择与文本相关的上下文,这里在布局特性上上使用了注意力机制
- 然后使用一个类似于LSTM中门的做法,从text得到一个d维向量,让后复制使它成为 H × W × d H \times W \times d H×W×d的张量 S S S,然后做 A g = A ⊙ σ ( S ) \mathbf{A}^{g}=\mathbf{A} \odot \sigma(\mathbf{S}) Ag=A⊙σ(S)
- 为了更好的编码文字中的背景信息,这里使用分开的全连接层和空间复制进行文本的嵌入。
- 然后,橘色部分就是对噪声向量进行空间复制,直接将三部分相连得到新的特征图,接下来将其输入到残差网络,然后d解码得到真实图像
D i m g D_{img} Dimg的目标函数记为 L i m g = λ a L a d v + λ r L r e c \mathcal{L}_{\mathrm{img}}=\lambda_{a} \mathcal{L}_{\mathrm{adv}}+\lambda_{r} \mathcal{L}_{\mathrm{rec}} Limg=λaLadv+λrLrec其中各部分分别为 L a d v = E ( M , s , X ) [ log D i m g ( M , s , X ) ] + E ( M , s ) , z [ log ( 1 − D i m g ( M , s , G i m g ( M , s , z ) ) ) ] L r e c = ∑ l ∥ Φ l ( G i m g ( M , s , z ) ) − Φ l ( X ) ∥ \begin{aligned} \mathcal{L}_{\mathrm{adv}}=& \mathbb{E}_{(\mathbf{M}, \mathbf{s}, X)}\left[\log D_{\mathrm{img}}(\mathbf{M}, \mathbf{s}, X)\right] \\ &+\mathbb{E}_{(\mathbf{M}, \mathbf{s}), \mathbf{z}}\left[\log \left(1-D_{\mathrm{img}}\left(\mathbf{M}, \mathbf{s}, G_{\mathrm{img}}(\mathbf{M}, \mathbf{s}, \mathbf{z})\right)\right)\right] \\ \mathcal{L}_{\mathrm{rec}}=& \sum_{l}\left\|\Phi_{l}\left(G_{\mathrm{img}}(\mathbf{M}, \mathbf{s}, \mathbf{z})\right)-\Phi_{l}(X)\right\| \end{aligned} Ladv=Lrec=E(M,s,X)[logDimg(M,s,X)]+E(M,s),z[log(1−Dimg(M,s,Gimg(M,s,z)))]l∑∥Φl(Gimg(M,s,z))−Φl(X)∥
在附录部分,作者给出了关于第一项更详细的描述: L a d v = E ( M , s , X ) [ log D i m g ( M , s , X ) ] + E ( M , s ~ , X ) [ log ( 1 − D i m g ( M , s ~ , X ) ) ] + E ( M , s ) , z [ log ( 1 − D i m g ( M , s , G i m g ( M , s , z ) ) ) ] \begin{aligned} \mathcal{L}_{\mathrm{adv}}=& \mathbb{E}_{(\mathbf{M}, \mathbf{s}, X)}\left[\log D_{\mathrm{img}}(\mathbf{M}, \mathbf{s}, X)\right] \\ &+\mathbb{E}_{(\mathbf{M}, \tilde{\mathbf{s}}, X)}\left[\log \left(1-D_{\mathrm{img}}(\mathbf{M}, \widetilde{\mathbf{s}}, X)\right)\right] \\ &+\mathbb{E}_{(\mathbf{M}, \mathbf{s}), \mathbf{z}}\left[\log \left(1-D_{\mathrm{img}}\left(\mathbf{M}, \mathbf{s}, G_{\mathrm{img}}(\mathbf{M}, \mathbf{s}, \mathbf{z})\right)\right)\right] \end{aligned} Ladv=E(M,s,X)[logDimg(M,s,X)]+E(M,s~,X)[log(1−Dimg(M,s ,X))]+E(M,s),z[log(1−Dimg(M,s,Gimg(M,s,z)))]
它的想法来源于《Generative Adversarial Text to Image Synthesis》这篇文章中的损失项设计,如下所示: s r ← D ( x , h ) { real image, right text } s w ← D ( x , h ^ ) { real image, wrong text } s f ← D ( x ^ , h ) { fake image, right text } L D ← log ( s r ) + ( log ( 1 − s w ) + log ( 1 − s f ) ) / 2 \begin{array}{l}{s_{r} \leftarrow D(x, h)\{\text { real image, right text }\}} \\ {s_{w} \leftarrow D(x, \hat{h})\{\text { real image, wrong text }\}} \\ {s_{f} \leftarrow D(\hat{x}, h)\{\text { fake image, right text }\}} \\ {\mathcal{L}_{D} \leftarrow \log \left(s_{r}\right)+\left(\log \left(1-s_{w}\right)+\log \left(1-s_{f}\right)\right) / 2}\end{array} sr←D(x,h){ real image, right text }sw←D(x,h^){ real image, wrong text }sf←D(x^,h){ fake image, right text }LD←log(sr)+(log(1−sw)+log(1−sf))/2
那么对应到本文中的损失项 L a d v \mathcal{L}_{\mathrm{adv}} Ladv可以看出
- 第一部分表示mask+与之对应的正确句子+真实的图片
- 第二部分表示mask+随机生成的错误的句子+真实的图片
- 第三部分表示mask+与之对应的正确句子+假的图片
Experiment
文中给出了具体的实验结果,这里就不详细的写啦,只给出一张图有个直观的感受,感兴趣的还是好好研读原paper~
下图是本文提出的模型和其他模型的对比

下图显示的是每一步的效果

下图显示的是更改描述文本的不同部分就会生成相应的图像

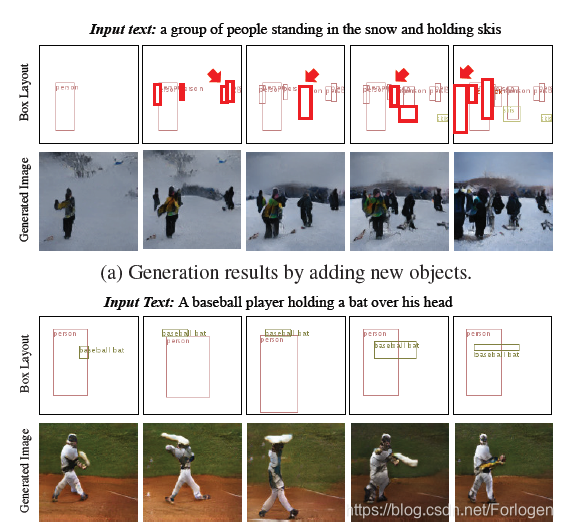
下图显示的是改变布局,生成的图像中的实体也会做出相应的改变
总结
整体来看,本文的思想和以下的几篇文章具有一定的相似之处,都是希望借助一些中间步骤,不管是语义结构还是实体的布局等来帮助提高生成图像的质量,后面希望可以对这几篇文章做一个总结,找到它们额共通之处,并思考我们可以来做什么~
CVPR 2019 Object-driven Text-to-Image Synthesis via Adversarial Training
CVPR 2018 Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis
CVPR 2019 Image Generation from Layout
CVPR 2019 Text2Scene: Generating Compositional Scenes from Textual Descriptions
ICLR 2019Generating Multiple Objects at Spatially Distinct Locations
NIPS 2016 Learning What and Where to Draw

















 2586
2586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









