




 介绍CVPR2018论文《PhotographicText-to-ImageSynthesiswithaHierarchically-nestedAdversarialNetwork》,提出一种新模型HDGAN,通过层次嵌套对抗性目标和单流生成器架构,生成高分辨率图像。模型采用多用途对抗性损失和视觉语义相似度度量,提升图像质量和语义一致性。
介绍CVPR2018论文《PhotographicText-to-ImageSynthesiswithaHierarchically-nestedAdversarialNetwork》,提出一种新模型HDGAN,通过层次嵌套对抗性目标和单流生成器架构,生成高分辨率图像。模型采用多用途对抗性损失和视觉语义相似度度量,提升图像质量和语义一致性。
CVPR 2018 《Photographic Text-to-Image Synthesis with a Hierarchically-nested Adversarial Network》

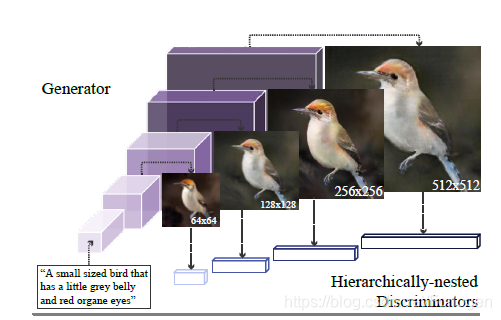
本文所提出的HDGAN从文章的名字我们也可以看出任务的主要关注点,那就是如何产生高质量或高分辨率的图像。在本文提出之前,比较有名的产生高分辨图像的模型主要是StackGAN和StackGAN++,但是它们只能分两个阶段来进行,第一阶段生成 64 × 64 64 \times 64 64×64的图像,第二阶段生成 256 × 256 256 \times 256 256×256的高分辨率图像,并不是目前常见的end-to-end的风格。因此,作者在本文中提出了一种称为伴随层次嵌套对抗性目标(accompanying hierarchical-nested adversarial objectives),通过规范在不同的中间层生成的低分辨率图像来使得生成器可以捕获复杂的图像信息。另外,提出了一种可扩展的单流生成器架构(extensile single-stream generator architecture)来更好的联合判别器进行训练,从而生成高分辨率的图像。同时为了同时提高语义一致性和图像保真度,采用了一种多用途的对抗性损失(multi-purpose adversarial loss)来鼓励更有效地使用图像和文本信息。最后还提出了一种新的视觉语义相关性度量标准,并在此标准和其他常见的评估标准上进行实验,均取得了不错的效果。
其中层次嵌套对抗性网络的示意图如下所示,它是一种逐步生成不同分辨率图像的架构,在每个中间层都嵌套了一个对应的判别器来区分生成图像的真假和对于描述文本的语义相关性。
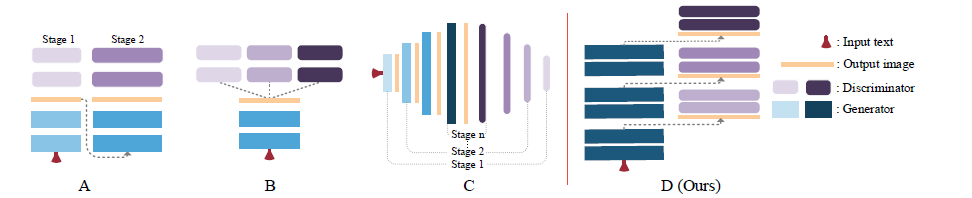
我们可以从下面这张图中看一下HDGAN的架构和之前模型架构的区别。图A表示的就是类似StackGAN的多阶段生成的建构方式,前一阶段的输出作为下阶段的输入,逐步的提高生成图像的分辨率;图B是一个生成器对应对应多个判别器,这样的方式实现了对于生成图像不同方面的关注;图C是逐步训练对称判别器和生成器的架构,同样也是一种对阶段生成的方式;图D表示的就是HDGAN,通过单流的生成器和层次嵌套判别器的架构来实现端到端的训练。
下面来逐个的看一下作者所提出的几个比较重要的东西
- Hierarchicalnested adversarial objectives
- Multipurpose adversarial losses
- Visual-semantic similarity
Hierarchicalnested adversarial objectives
GAN的目标函数可写为 G ∗ , D ∗ = arg min G max D V ( D , G , Y , z ) = G ∗ , D ∗ = arg min G max D E Y ∼ p data [ log D ( Y ) ] + E z ∼ p z [ log ( 1 − D ( G ( z ) ) ) ] G^{*}, D^{*}=\arg \min _{G} \max _{D} \mathcal{V}(D, G, Y, \boldsymbol{z})=G^{*}, D^{*}=\arg \min _{G} \max _{D}\mathbb{E}_{Y \sim p_{\text { data }}}[\log D(Y)]+\mathbb{E}_{\boldsymbol{z} \sim p_{z}}[\log (1-D(G(\boldsymbol{z})))] G∗,D∗=argGminDmaxV(D,G,Y,z)=G∗,D∗=argGminDmaxEY∼p data [logD(Y)]+Ez∼pz[log(1−D(G(z)))]
而本文所提出的层次嵌套结构的生成器 G \mathcal{G} G通过对隐空间中图像的正则化以及使生成器更快的接收到梯度信息,促使生成器更快的生成逼真的图像,同时也助于提高训练过程的稳定性。这里的 G \mathcal{G} G是CNN的架构模型,可表示为 X 1 , … , X s = G ( t , z ) X_{1}, \ldots, X_{s}=\mathcal{G}(t, z) X1,…,Xs=G(t,z)其中 t t t表示描述语句的嵌入向量,它由char-RNN的文本编码器训练而得; z z z表示随机噪声向量; X i X_{i} Xi表示不同中间层生成的图像, X s X_{s} Xs是最后生成的高分辨率图像。对于每层生成器的输出,都会有一个对应的判别器进行判别,因此min-max目标函数可写为 G ∗ , D ∗ = arg min G max D V ( G , D , Y , t , z ) \mathcal{G}^{*}, \mathcal{D}^{*}=\arg \min _{\mathcal{G}} \max _{\mathcal{D}} \mathcal{V}(\mathcal{G}, \mathcal{D}, \mathcal{Y}, t, \boldsymbol{z}) G∗,D∗=argGminDmaxV(G,D,Y,t,z)其中 D = { D 1 , . . . , D s } \mathcal{D}=\{D_{1},...,D_{s}\} D={D1,...,Ds}表示对应的判别器, Y = { Y 1 , . . . , Y s } \mathcal{Y}=\{Y_{1},...,Y_{s}\} Y={Y1,...,Ys}表示对应的不同分辨率下的真实图像。
低分辨率层的输出主要用于学习语义一致的图像结构(例如对象草图、颜色和背景),随后的高分辨率层的输出用于呈现细粒度的细节。由于是以端到端的方式训练的,低分辨率的输出也可以充分利用来自高分辨率鉴别器的自顶向下的知识。因此这样的架构可以在低分辨率和高分辨率图像的输出中观察到一致的图像结构、颜色和样式。
Multipurpose adversarial losses
这个损失项的提出主要是为了让低分辨率层的判别器关注全局的特征,高分辨率的判别器更专注于局部细粒度的特征,从而提高生成图像的保真度。每个判别器都包含两个分支,其中一个分支是,用于生成一个 R i × R i R_{i} \times R_{i} Ri×Ri概率映射,判断图像的每个局部区域的真假(对应local image loss);另一个分支首先把 512 × 4 × 4 512 \times 4 \times 4 512×4×4的特征图和一个 128 × 4 × 4 128 \times 4 \times 4 128×4×4的文本嵌入向量拼接起来,再做 4 × 4 4 \times 4 4×4的卷积来判断 图像-文本对是真还是假。这样的过程就形成了下图所示的金字塔的形式
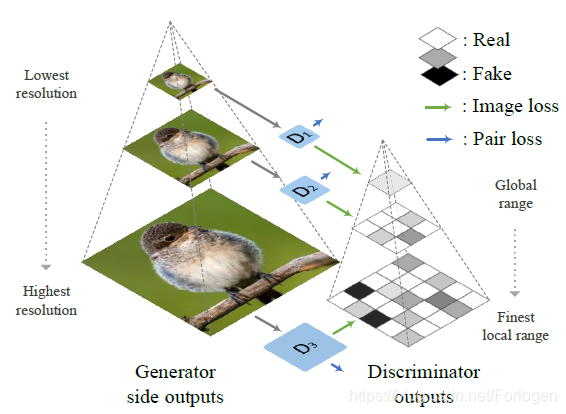
综上,整个模型的目标函数为 V ( G , D , Y , t , z ) = ∑ i = 1 s ( L 2 ( D i ( Y i ) ) + L 2 ( D i ( Y i , t Y ) ) + L 2 ‾ ( D i ( X i ) ) + L 2 ‾ ( D i ( X i , t X i ) ) + L 2 ‾ ( D i ( Y i , t Y ‾ ) ) ) \begin{array}{c}{\mathcal{V}(\mathcal{G}, \mathcal{D}, \mathcal{Y}, t, \boldsymbol{z})=\sum_{i=1}^{s}\left(L_{2}\left(D_{i}\left(Y_{i}\right)\right)+L_{2}\left(D_{i}\left(Y_{i}, \boldsymbol{t}_{Y}\right)\right)+\right.} \\ {\overline{L_{2}}\left(D_{i}\left(X_{i}\right)\right)+\overline{L_{2}}\left(D_{i}\left(X_{i}, \boldsymbol{t}_{X_{i}}\right)\right)+\overline{L_{2}}\left(D_{i}\left(Y_{i}, \boldsymbol{t}_{\overline{Y}}\right)\right) )}\end{array} V(G,D,Y,t,z)=∑i=1s(L2(Di(Yi))+L2(Di(Yi,tY))+L2(Di(Xi))+L2(Di(Xi,tXi))+L2(Di(Yi,tY)))
visual-sementic similarity
提出的新的度量标准是为了自动化的评估生成图像和描述文本的语义一致性,基本思想是将图像和文本嵌入到同一个向量空间中,通过 c ( x , y ) = x ⋅ y ∥ x ∥ 2 ⋅ ∥ y ∥ 2 c(\boldsymbol{x}, \boldsymbol{y})=\frac{\boldsymbol{x} \cdot \boldsymbol{y}}{\|\boldsymbol{x}\|_{2} \cdot\|\boldsymbol{y}\|_{2}} c(x,y)=∥x∥2⋅∥y∥2x⋅y来计算一致性,模型通过最小化下面的双向的排名损失来训练模型 ∑ v ∑ t σ ‾ max ( 0 , δ − c ( f v ( v ) , f t ( t v ) ) + c ( f v ( v ) , f t ( t v ‾ ) ) ) + ∑ t ∑ v τ ‾ max ( 0 , δ − c ( f t ( t ) , f v ( v v ) ) + c ( f t ( t ) , f v ( v t ‾ ) ) ) \begin{array}{l}{\sum_{\boldsymbol{v}} \sum_{t_{\overline{\sigma}}} \max \left(0, \delta-c\left(f_{v}(\boldsymbol{v}), f_{t}\left(\boldsymbol{t}_{v}\right)\right)+c\left(f_{v}(\boldsymbol{v}), f_{t}\left(\boldsymbol{t}_{\overline{v}}\right)\right)\right)+} \\ {\sum_{\boldsymbol{t}} \sum_{\boldsymbol{v}_{\overline{\tau}}} \max \left(0, \delta-c\left(f_{t}(\boldsymbol{t}), f_{v}\left(\boldsymbol{v}_{v}\right)\right)+c\left(f_{t}(\boldsymbol{t}), f_{v}\left(\boldsymbol{v}_{\overline{t}}\right)\right)\right)}\end{array} ∑v∑tσmax(0,δ−c(fv(v),ft(tv))+c(fv(v),ft(tv)))+∑t∑vτmax(0,δ−c(ft(t),fv(vv))+c(ft(t),fv(vt)))
关于实验部分可见原论文啦~

















 214
214




 到【灌水乐园】发言
到【灌水乐园】发言







