




 本文介绍了一种改进的生成对抗网络(GANs)——辅助分类器GAN(AC-GAN),用于合成高质量图像。该方法引入了类标签作为条件,提高了图像的全局一致性,避免了模式崩塌问题。通过引入新的评估指标,展示了AC-GAN生成的128×128像素图像具有更高的分辨力和多样性。
本文介绍了一种改进的生成对抗网络(GANs)——辅助分类器GAN(AC-GAN),用于合成高质量图像。该方法引入了类标签作为条件,提高了图像的全局一致性,避免了模式崩塌问题。通过引入新的评估指标,展示了AC-GAN生成的128×128像素图像具有更高的分辨力和多样性。
《Conditional Image Synthesis with Auxiliary Classifier GANs》

合成高分辨率并且真实的图片在机器学习是一个一直存在的挑战。在本文中我们引入新的方法,来提高用于图像合成的生成对抗网络(GANs)的训练。我们利用标签条件构造了GANs的变种,它产生了 128 × 128 128 \times128 128×128像素的样本并展示出了全局一致性。我们通过扩展之前用于图像质量评估的工作,来提供两种新的分析方法来评估以类为条件的图片合成模型中,生成样本的可分辨性和多样性。这些分析方法表明高分辨率的样本提供了低分辨率样本中没有的类别信息。在ImageNet的1000类别中, 128 × 128 128 \times128 128×128的样本比起人工变小的 32 × 32 32 \times32 32×32大小的样本的分辨性的两倍以上。除此之外,比起真实的ImageNet数据,84.7%的这些类有样本显示出了多样性。
本文提出了一个新的条件对抗生成网络的框架,其具体的网络结果如下图所示:生成器的输入除了GAN结构中常见的噪声Z以外,还加入了类标签,而分辨器的判别也不再仅限于输入数据真伪的判断,同时会给出数据所属类标签的判断,因而分辨器成了强化的分类器(虽然之前也是二分类的分类器,但是其监督信号并不是很强)。如此设计的GAN在文中被称作AC-GAN(auxiliary classifier GAN,有辅助分类器的GAN)。
因为修改了分辨器,所以AC-GAN的训练Loss更改如下:
L
S
=
E
[
log
P
(
S
=
r
e
a
l
∣
X
r
e
a
l
)
]
+
E
[
log
P
(
S
=
f
a
k
e
∣
X
f
a
k
e
)
]
L
C
=
E
[
log
P
(
C
=
c
∣
X
r
e
a
l
)
]
+
E
[
log
P
(
C
=
c
∣
X
f
a
k
e
)
]
\begin{array}{c}{L_{S}=E\left[\log P\left(S=r e a l | X_{r e a l}\right)\right]+E\left[\log P\left(S=f a k e | X_{f a k e}\right)\right]} \\ {L_{C}=E\left[\log P\left(C=c | X_{r e a l}\right)\right]+E\left[\log P\left(C=c | X_{f a k e}\right)\right]}\end{array}
LS=E[logP(S=real∣Xreal)]+E[logP(S=fake∣Xfake)]LC=E[logP(C=c∣Xreal)]+E[logP(C=c∣Xfake)]
其中分辨器的Loss为最大化 L s + L c L_{s}+L_{c} Ls+Lc,生成器的Loss为最大化 L c − L s L_{c}-L_{s} Lc−Ls,其中 S S S表示判断图片的来源(Source), C C C表示判断图片的类标签(Class Label)。模型的整体架构可简单表示为如下的形式:
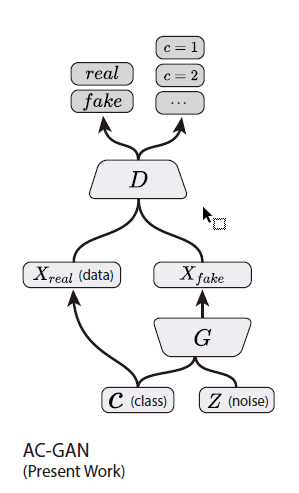
随后,本文就提出的图片生成模型,认为生成图片的网络,不能是将低分辨率的图片进行简单的线性插值而生成高分辨率的图片,与此同时,生成的图片不能犯GAN常见的模式崩塌的问题,产生单一并不多样化的图片。
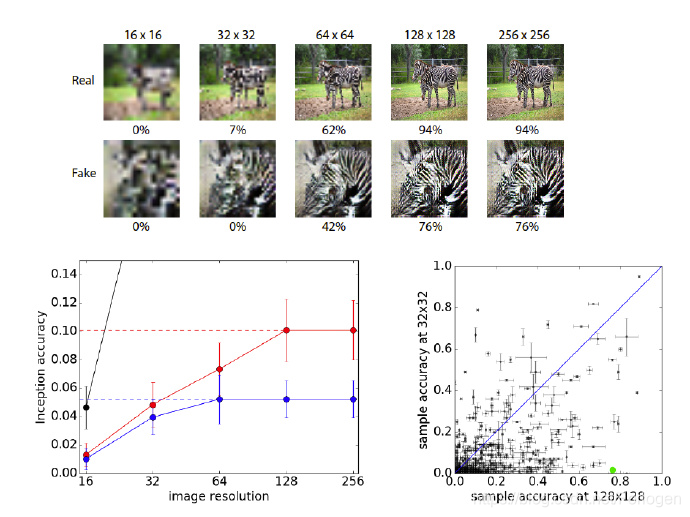
测试生成的图片的分辨力
如上所述,生成高分辨率的图片,需要不是简单的将低分辨率的图片进行线性插值来生成,因而要量化的分析生成的图片的质量,可以从其分辨力。从低分辨率通过插值生成的高分辨率图片,其本质上没有增加多余信息,只是低分辨率的模糊版。结合这样的思路,高分辨率的图片提供了更多的信息,这些信息结合到AC-GAN结构,每个生成图片都有其对应的标签,因而这个更多的信息,可以通过分类来表明,也就是说更多的信息,可以用于分类,也就是文中所说的分辨力(Discriminability)。
因此,文中采用了Inception网络对于生成的图片进行分类,查看其被分类为正确类别的比率,以此来判定生成的图片质量。下图中,图中左下的图,黑色的线,是真实图片,因而其达到的准确率可以说是生成图片的准确率的上限,红色的线表示的是生成的 128 × 128 128 \times128 128×128分辨率的图片的准确率表现,蓝色的线是生成的 64 × 64 64 \times64 64×64分辨率的图片的准确率表现,对于比其高或低分辨率的图片的准确率,是通过插值的方式缩放以后得到的图片得出的准确率表现,可以看到,降低分辨率确实降低了准确率,明确表明低分辨率的类信息更少;同样通过插值方式提高分辨率并不会带来更多的类信息,同时也不会损害已有的类信息,因而准确率保持不变。图中右下的图,每个点代表不同的类别,其坐标分别代码不同的分辨率下的准确率,其中蓝色的线是y=x的函数线,也就表明位于蓝色线上方的点,含义是该类别的图片在 32 × 32 32 \times32 32×32分辨率条件下准确率高于 128 × 128 128 \times128 128×128条件下的准确率,反之,在下方的点表明 32 × 32 32 \times32 32×32的准确率低于 128 × 128 128 \times128 128×128的准确率。文中统计了在线下方的点的比例为84.4%,也可以说大部分的图片在高分辨率的情况下,用于分类准确率会高于低分辨率。
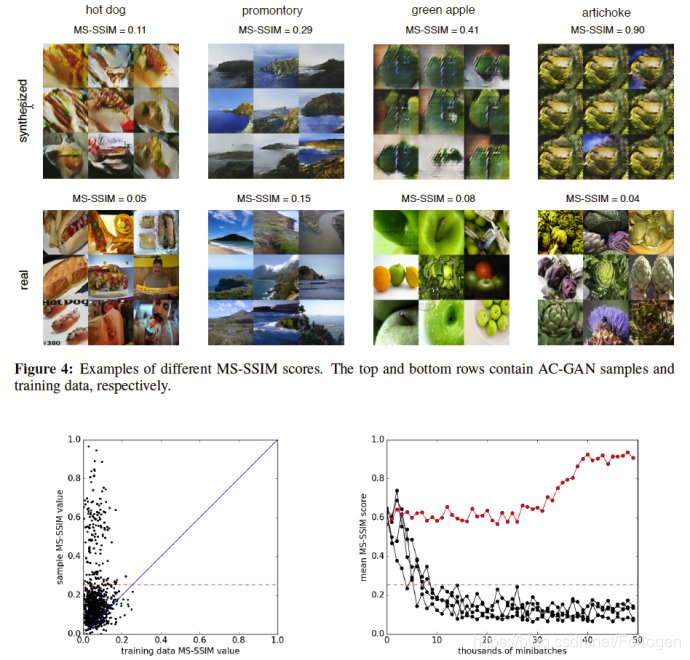
测试图片的多样性
GAN有个最常见的问题就是模式坍塌的问题,就是模型找到一种方式,无论输入的内容是什么,生成的图片都只有一种,然而这种图片能大概率欺骗过分辨器。因而,产生的图片具有多样性,也是可以评估GAN模型好坏的指标。文中采用了图片的多尺度结构相似度来衡量图片与图片之间的相似度(multi-scale structural similarity,MS-SSIM),这个相似度在0和1之间取值,越大说明图片之间越相似。文中在一个给定类中取图片对,计算两者之间的MS-SSIM,如果图片多样性程度越高,那么这个MS-SSIM的分数应该越低。ImageNet的训练数据的平均MS-SSIM值最高的为0.25,这部分的实验结果如下图所示,图中左下角的图,图中每个点代表一个类,分别对应训练数据和生成数据的MS-SSIM的数值,蓝色的线依旧为y=x的函数线。但是这块并不是看生成数据MS-SSIM比训练数据的MS-SSIM大或者小的部分(因为这并没有什么意义,生成的数据多样性比训练数据高或低没有太多意义),而是要看红色的分界线,红色的线为MS-SSIM为0.25,因而低于0.25的数据,可以说生成的数据是比较接近真实图片的,文中统计了这根红线下面的类的数量为847个,也就是说84.7%的AC-GAN生成的类数据的多样性超过了训练集中最小变化量的类(仔细思考下,这样的比较方式可能存在一点问题,个人觉得用所有类的MS-SSIM的平均值可能会更具有代表性)。图中右下角的图,文中表示红色的线是生成数据的MS-SSIM平均值在训练过程中的变化(一直在上升,是不是说明有崩塌的可能,而且接近1了);同时图中黑色的线,应该是训练完成后生成的图片的多样性(文中提及同样标准测试了训练数据,和完成后的生成样本,但是这里存在问题的是,训练完成后的横坐标按理是不存在的,或者,这个缺陷应该不会波动很大,这里也可以理解为横坐标为训练最大次数,然后计算平均的MS-SSIM的数值,不过这里确实没交代太清楚)。
文中除了分开的探索生成图片的分辨力和多样性,也探索了生成图片的分辨力和多样性的相关性,如下图所示,文中得到两者相关性为负相关(相关系数r=-0.16),因此认为AC-GAN的模型并没有以分辨力为代价,来产生多样性的样本。(这里得注意,分辨力的参数是越大越好,多样性的参数是越小越好)。
除了说明生成的图片具有分辨力的同时也具有多样性外,文中通过Inception Score比较了AC-GAN生成的样本的质量,获得了8.25±0.07的分数。同时由于在生成ImageNet的1000个类的数据时,采用了100个AC-GAN来生成数据,每个AC-GAN只需要关注10个类的数据的生成(GAN在存在多个类的情况下,生成的样本效果并不好,这也是GAN的一个研究方向),因此在附录中,文中还探索了这样划分类是否会使得AC-GAN生成效果更好。
在探索AC-GAN是否存在过拟合的实验中,文中提出了两种思路,第一种思路是比较L1距离最近的生成的图片,看起是否类似于训练的数据,从而判定是否存在过拟合,给出的实验结果图比较,依旧是人为的评定是否相似。除此方法之前,文中提出了线性插值噪声z和类标签c,查看其变化,其认为如果是过拟合的模型,那么产生的图片在插值的输入面前会发生图片,结果依旧需要认为判断,不过这样判断是否发生突变会比之前的容易(感觉可以用MS-SSIM来确定插值后产生的图片是否依旧比较大之类的)。
总结
本文提出的GAN结构,修改了Generator,除了输入噪声z之外,还提供了需要生成数据的类标签c;修改了Discriminator,除了判断图片的真伪之外,还需要判断图片的类标签。这样,在加入了监督信号的情况下,提升了GAN生成图片质量,并且没有出现GAN容易出现的模式坍塌现象。在评估GAN生成的图片验证上,提出了采用生成图片分类结果准确性来证实生成图片的质量,与此同时采用MS-SSIM参数的评估,来检验AC-GAN生成数据的多样性,提出这些数值评估的情况,在某种程度上而言,这些量化的分析,都可以设计成对应的Loss近一步提升GAN的生成图片的能力。除此之外,还定性分析了AC-GAN模型的是否产生过拟合的问题。


















 2257
2257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









