




 本文探讨了深度学习网络架构的选择,包括浅层网络和深层网络的特点与应用场景,以及网络权重初始化的重要性。介绍了Autoencoder和Linear Autoencoder的概念,及其与主成分分析(PCA)的关系,讨论了模型复杂度控制和过拟合的正则化方法。
本文探讨了深度学习网络架构的选择,包括浅层网络和深层网络的特点与应用场景,以及网络权重初始化的重要性。介绍了Autoencoder和Linear Autoencoder的概念,及其与主成分分析(PCA)的关系,讨论了模型复杂度控制和过拟合的正则化方法。
这一讲的是对Deep Learning这个热门方向的一个介绍,虽然很多知识在现在看起来有点老了,但还是有很多的启发意义。主要从以下四个面进行介绍:
- Deep Neutral Network
- Autoencoder
- Denoising Autoencoder
- Principal Component Analysis
下图是在第12讲中提到了一个关于神经网络的简单的示例,它包括输入层、两个隐藏层和一个输出层,在层与层之间是转换的权重矩阵,每个隐藏层中的神经元的激活函数为tanhtanhtanh ,输出层为线性输出。同样为了方便计算,这里在每一层中添加了x0i=1x_{0}^{i}=1x0i=1 。其中每一个的隐藏层负责从输入的数据中来发现某些有趣的东西,或说是有关数据的某种模式。
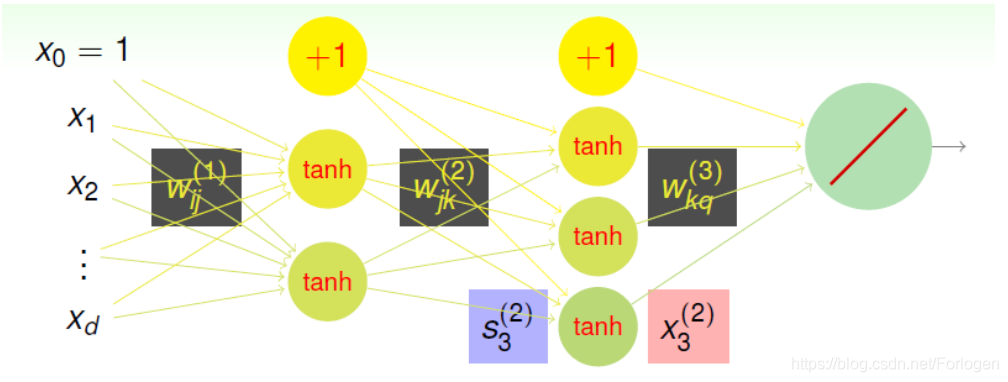
那么在设计神经网络的时候,我们应该选择多少层?每一层中包含多少了神经元呢?或者说什么样的网络架构才是最好的呢?严格来说,我们很难设计出一个通用性和效果都很好的网络,在实际中往往是针对具体的问题设计相关的架构,所以出现了类如VGG、Res-Net等等架构方式。也许你会想我们能否在不同的架构中使用之前学习的验证方式来找到最好的呢?答案是这样的方式是不太实际的!针对于网络架构的研究也有很多人在做,比如最近何凯明发的一篇论文阐述了随机连接的网络性能要优于人工精心设计的网络,有兴趣的可以看一下。
那么如何来选择不同的网络架构呢?通常来说,我们可以讲其分为如下的两大类:
- Shallow net:它表示网络中含有较少的隐藏层,使用这样的构架方式,它的有点在于:网络的训练更加有效、网络结构简单、理论上如果有足够的神经元,它的能力也会足够的强
- Deep Net:它表示网络中含有很多的隐藏层,使用这样的方式,由于网络很深,参数众多,训练难度自然也就很大;结构更加的复杂;理论上,如果我们网络足够的深、神经元足够的多,模型的能力自然也会足够的强;此外它相比浅层的网络,得到的结果更加的有意义。所以如果我们的网络设计的足够的深、足够的好,理论上它可以解决很多之前无法解决的问题,因此deep learning 在如今如此的火爆。
那么通过deep net得到的结果更加有意义是什么意思呢?我们知道在deep net中会有很多的隐藏层,那么不同的层就会提取出数据中不同的特征,层数越多,提取出的特征的个数就越多。而且每一层提取的特征都具有相应的物理意义。这种各司其职的方式建立的网络,在解决复杂问题方面的能力就越强, 效果就会更好。。
但是deep learning同样有一些问题需要引起我们的注意,如下所示:
- 模型结构的选择:因为网络中的层数、神经元的个数都不是固定,我们我们需要针对不同的问题,选择合适的网络架构。比如在处理图像问题中,我们会使用CNN;在处理序列数据时,我们会使用RNN……这样的选择需要网络的架构这具有一定的领域知识
- 模型的复杂度:随着层数和神经元数量的增加,模型的复杂度自然也会增加。当模型的复杂度很高时,处理起来就会有很大的挑战。但在现在看来,如果我们的数据足够的多,它似乎也不是一个很大的问题;另外我们还可以使用很多的手段来降低模型的复杂度,比如dropout、denosing……
- 模型的优化:当网络很复杂时,所涉及的权重参数就会非常的多,这给网络的优化带来了很大的挑战。缓解这个问题的一种方法就是注重权重的初始化,避免在参数更新时困在局部的最小值,这种方式也成为预训练。当然在初始化权重方面,现在也有很多的方法可供选择,网络上也有很好别人预训练好的模型供我们使用。
- 模型的计算复杂度网络越复杂参数越多,计算量就会越大,同时当数据量变大时,同样也会增加模型的计算复杂度。但是在实际中,随着硬件的进步和并行处理技术的发展,使我们可以考虑选择使用很复杂的网络,而不用太过于在意训练的时长。
在上面提到,网络权重的初始化选择很重要,好的初始值能够帮助避免受困于局部最优解。常用的方法就是先进行预训练,得到权重的初始化值,然后在正式的训练中,使用后向传播来微调参数,使最后得到的模型效果更好。基本流程如下所示:
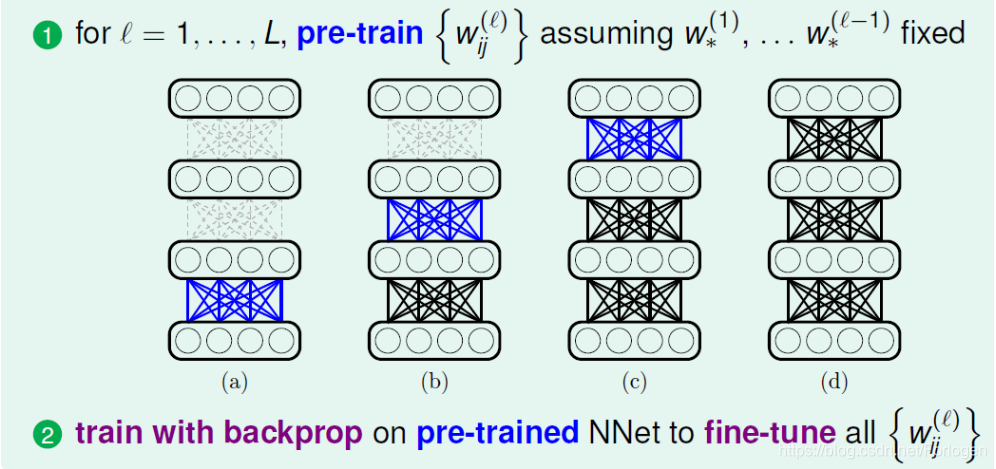
那么网络中的权重是什么呢?在神经网络中,权重可以认为是一种转换,将某一层的特征转换成后一层表示的方式;或者说完成一种编码(encoding)的过程,将某一层的特征使用另一种编码表示。所以好的权重初始值应该是尽可能地保留数据的特征信息,如果我们使用它来重建输入的数据,得到的结果应该很输入很相似。
下面我们使用下图来看一下尽可能的保留特征的信息是什么意思?
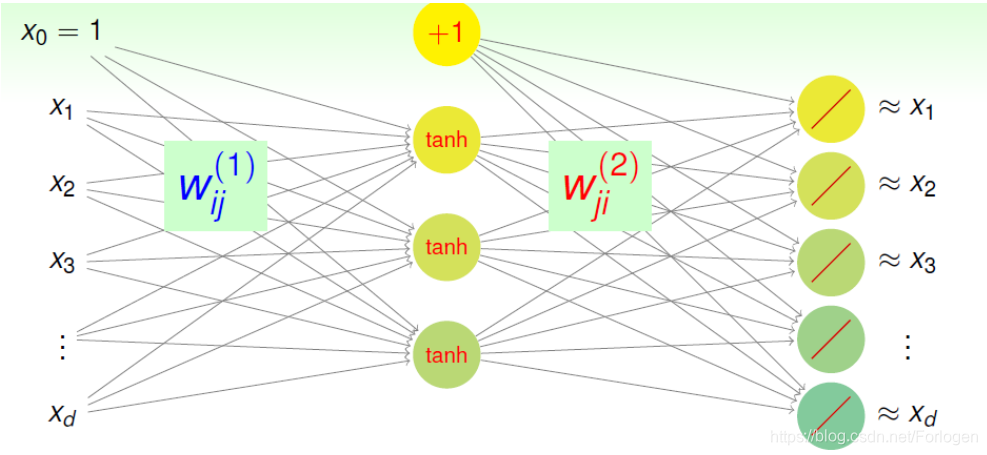
如上图所示,网络只有输入层、一个隐藏层和输出层三层,层与层之间有权重矩阵Wij1W_{ij}^1Wij1 和Wij2W_{ij}^2Wij2 。整个网络可以看成是d− dˇ− dd -\ \check{d} -\ dd− dˇ− d 的结构,其中输入层到隐藏层可以看作encoding的过程,隐藏层到输出层可以看作decoding的过程,那么整个网络就可以看作是一个Autoencoder。我们希望输入经过这个Autoencoder后,输出的结果和对应的输入尽可能的相似,这个过程类似于学习得到ggg ,使g(x)≈xg(x) ≈xg(x)≈x 。
那么使用Autoencoder这样形式的网络有什么好处呢?总体来说,通过这样的结构,我们可以更好的观察到数据中隐藏的结构信息。
- 监督学习: 隐藏层的输出可以看成使对原始数据完成了一次特征转换,从中可以得到一些更有代表性的信息
- 无监督学习: 可以用来做密度估计,或者说是判断原始数据的稀疏程度。如果g(x)≈xg(x) ≈xg(x)≈x,则表示密度较大;如果g(x)与x差别很大,则表示密度较小。使用这样的思想,我们也可以用来进行离群点的探测,找出哪些数据是典型的,哪些是关系不大的,这样就可以从原始数据中学习到一些典型的表达信息

对于Basic Autoencoder来说,它的结构是如上面所述的d− dˇ− dd -\ \check{d} -\ dd− dˇ− d ,因为希望重建后的结果和原始的输入尽可能的相似,所以误差评估函数为平方误差∑i=1d(gi(x)−xi)2\sum_{i=1}^d (g_{i}(x)-x_{i})^2∑i=1d(gi(x)−xi)2 。此外它还具有如下的特点:
- 基本的Autoencoder只包括基本的三层,因此使用后向传播的计算量较小,便于训练
- 隐层的大小为dˇ\check{d}dˇ 满足dˇ<d\check{d} < ddˇ<d ,因此它往往可以得到原始数据的一种压缩表示,便于编码
- 因为我们的输出是对于输入的逼近,因此可以看成是一种无监督的学习
- 通常会添加限制条件Wij(1)=Wij(2)W_{ij}^{(1)}=W_{ij}^{(2)}Wij(1)=Wij(2) ,将其作为一种正则化的手段,但是在计算梯度时会变的复杂一些
通常使用Autoencoder做一个预训练的事情,从对无标签的数据经过编码、解码的过程中,学习到一个有意义的编码权重WijW_{ij}Wij ,将其做为后面神经网络一个比较好的初始化权重。
因此在每两层之间,我们都可以使用Autoencoder进权重的初始化,然后在正式的训练中,再根据数据使用后向传播进行参数的微调,最后获得一个效果还不错的模型。
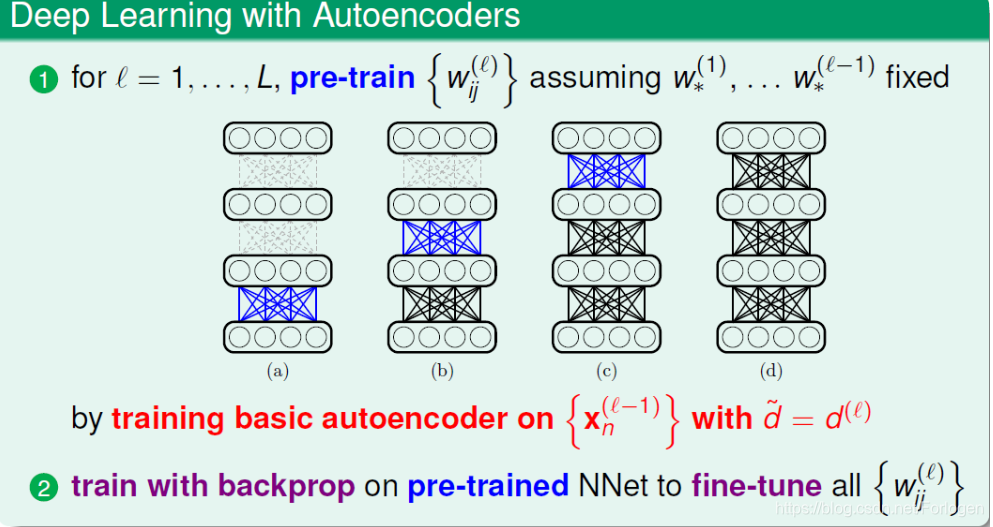
我们可以使用Autoencoder来进行权重的初始化工作,,完成一个预训练的工作。下面来看一下如何使用一些正则化(regularization)的方式来控制模型的复杂度。因为当我们的网络很复杂的时候,它可以学得很好,能力很强,但是同时也可能出现过拟合,导致泛化能力下降。像在机器学习中一样,我们也可以使用正则化的方式来控制模型的复杂度。
常见的方法有:
- 对于网络结构做一些限制
- 权重衰减、权重消除
- 早停
在介绍另一种方法之前,先看一下导致过拟合出现的原因有哪些。下面这张图是不是很熟悉呢?它就是之前基石课程中很重要的观察数据量、噪声大小和过拟合之间的关系的一张图。从图中我们可以看出,当样本数量下降、噪声变大都会造成overfitting的出现。
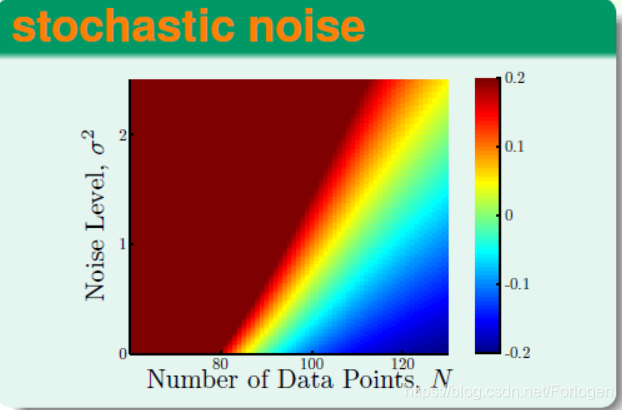
就噪声而言,我们有什么办法降低它的影响呢?最直观的方法可能就是对源头进行治理,即对数据进行清理,使它包含的噪声足够的小,这样训练得到的模型效果看起来就不会很差。但是这样的结果模型只能保证g(x)≈xg(x) ≈ xg(x)≈x,当数据稍微不同时,或有一点噪声时,效果就会很差。所以另一种相对的方法是我们不去尝试减少数据中的噪声,反正人工条件一些噪声,则输入变成xˇ=xi+artificial noise\check{x} =x_{i}+artificial\ noisexˇ=xi+artificial noise ,希望g(xˇ)≈xg(\check{x}) ≈ xg(xˇ)≈x 。经过训练得到的模型,不仅在训练数据上表现得很好,在新的含有噪声的数据上,同样可以有不错的效果,这样我们就得到了一下鲁棒性更好的网络模型。
前面给出的网络示例中,因为激活函数为tanh,所以它其实是一个非线性的自动编码器(nonlinear autoencoder)。下面来看一下linear autoencoder,并且看一下它和主成分分析(PCA)有什么联系。
在linear autoencoder中不适用非线性的激活函数,因此第K层的部分可以表示成如下的形式
hk(x)=∑j=0dˇwjk(2)(∑i=0dwij(1)xi)
h_{k}(x)=\sum_{j=0}^{\check{d}}w_{jk}^{(2)}(\sum_{i=0}^{d} w_{ij}^{(1)}x_{i})
hk(x)=j=0∑dˇwjk(2)(i=0∑dwij(1)xi)
同时有三个特殊的限制条件:
- 移除加入的x0x_{0}x0 ,因为我们希望输出尽可能地接近输入,那么让1逼近1就没有什么意义
- 限制Wij(1)=Wij(2)=WijW_{ij}^{(1)}=W_{ij}^{(2)}=W_{ij}Wij(1)=Wij(2)=Wij
- 使得dˇ<d\check{d} < ddˇ<d
那么上面的h(x)h(x)h(x) 就可以写成h(x)=WWTxh(x)=WW^{T}xh(x)=WWTx。
从Error function的角度来看,我们希望EinE_{in}Ein 尽可能的小,即希望下式尽可能地小,求出对应的WWW 。
Ein(h)=Ein(W)=1N∑n=1N∣∣xn−WWTxn∣∣2
E_{in}(h)=E_{in}(W)=\frac{1}{N}\sum_{n=1}^{N}||x_{n}-WW^{T}x_{n}||^2
Ein(h)=Ein(W)=N1n=1∑N∣∣xn−WWTxn∣∣2
其中WWTWW^{T}WWT是半正定矩阵,半正定矩阵有性质VVT=VTV=IdVV^{T}=V^{T}V=I_{d}VVT=VTV=Id 。那么根据性质,对WWTWW^{T}WWT进行特征值分解有WWT=VΓVTWW^{T}=V\Gamma V^{T}WWT=VΓVT ,其中Γ\GammaΓ 为对角阵,非零元素不超过dˇ\check{d}dˇ 。同样的我们将xnx_{n}xn 进行类似的操作,得到xn=VIVTxnx_{n}=VIV^{T}x_{n}xn=VIVTxn ,其中Id×dI_{d\times d}Id×d 为单位阵。
这样就将对WWW 的优化问题转变为对VVV 和Γ\GammaΓ 的优化问题了。即如下所示:
minVmaxΓ1N∑n=1N∣∣VIVTxn−VΓVTxn∣∣2
\min \limits_{V} \max \limits_{\Gamma} \frac{1}{N} \sum_{n=1}^{N}||VIV^{T}x_{n}-V \Gamma V^{T}x_{n}||^2
VminΓmaxN1n=1∑N∣∣VIVTxn−VΓVTxn∣∣2
首先来看内层关于Γ\GammaΓ 的优化问题:
minVmaxΓ1N∑n=1N∣∣VIVTxn−VΓVTxn∣∣2\min \limits_{V} \color{lime}{\max \limits_{\Gamma} \frac{1}{N} \sum_{n=1}^{N}||VIV^{T}x_{n}-V \Gamma V^{T}x_{n}||^2}VminΓmaxN1n=1∑N∣∣VIVTxn−VΓVTxn∣∣2
我们希望最小化上式,相当于希望(I−Γ)(I-\Gamma)(I−Γ) 越小越好,即对角线上的零越多越好。因为Γ\GammaΓ 的秩最大为dˇ\check{d}dˇ ,所以最多有dˇ\check{d}dˇ 个1,相对应的可以认为是(I−Γ)(I-\Gamma)(I−Γ) 最多有d−dˇd-\check{d}d−dˇ 个1,Γ\GammaΓ 的最优解表示如下:
minV∑n=1N∣∣[000Id−dˇ]VTxn∣∣2
\min \limits_{V}\sum_{n=1}^{N}||\begin{bmatrix} 0 & 0 \\ 0 & {I_{d-\check{d}}} \\ \end{bmatrix}V^{T}x_{n}||^2
Vminn=1∑N∣∣[000Id−dˇ]VTxn∣∣2
然后将其转换成对偶的最大化问题,如下所示:
minV∑n=1N∣∣[000Id−dˇ]VTxn∣∣2=maxV∑n=1N∣∣[Idˇ000]VTxn∣∣2
\min \limits_{V}\sum_{n=1}^{N}||\begin{bmatrix} 0 & 0 \\ 0 & {I_{d-\check{d}}} \\ \end{bmatrix}V^{T}x_{n}||^2= \max \limits_{V}\sum_{n=1}^{N}||\begin{bmatrix} {I_{\check{d}}} & 0 \\ 0 & 0 \\ \end{bmatrix}V^{T}x_{n}||^2
Vminn=1∑N∣∣[000Id−dˇ]VTxn∣∣2=Vmaxn=1∑N∣∣[Idˇ000]VTxn∣∣2
其中当dˇ=1\check{d}=1dˇ=1 时,VTV^{T}VT中只有第一行vTv^{T}vT有用,因此可以将上述的最大化问题转化为:
maxv∑n=1NvTxnxnTv , subject to vTv=1
\max \limits_{v} \sum_{n=1}^{N}v^{T}x_{n}x_{n}^{T}v\ ,\ subject\ to\ v^{T}v=1
vmaxn=1∑NvTxnxnTv , subject to vTv=1
对于这样有条件的问题我们可以使用拉格朗日乘子法,引入拉格朗日因子λ\lambdaλ ,即
∑n=1NxnxnTv=λv
\sum_{n=1}^{N}x_{n}x_{n}^{T}v=\lambda v
n=1∑NxnxnTv=λv
根据线性代数可以知道,vvv 就是XTXX^{T}XXTX的特征向量,而λ\lambdaλ 就是相对应的特征值。我们要求的是最大值,所以最优解vvv就是XTXX^{T}XXTX最大特征值对应的特征向量。当dˇ>1\check{d} > 1dˇ>1时,解法类似,最优解vjv_{j}vj就是XTXX^{T}XXTX前 dˇ\check{d}dˇ 大的特征值对应的 dˇ\check{d}dˇ个特征向量。
上面关于linear autoencoder的求解过程和PCA的推导过程十分相似。有一点不同的是,PCA会首先对数据进行标准化,方便计算。PCA的基本流程如下:

PCA是基于统计学分析得到的,一般认为,将高维数据投影(降维)到低维空间中,应该保证数据本身的方差越大越好,而噪声方差越小越好,而PCA正是基于此原理推导的。因此我们可以使用linear autoencoder与PCA进行数据压缩,实际中PCA应用更多一些。

















 400
400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









