






 本文介绍了条件生成对抗网络(CGAN)的概念及其在可控生成任务中的应用。CGAN通过在生成器和判别器中引入条件信息,使得生成样本变得可控。文章详细解释了CGAN的工作原理,并展示了其在MNIST数据集上根据指定类标签生成手写数字图像的实验结果。
本文介绍了条件生成对抗网络(CGAN)的概念及其在可控生成任务中的应用。CGAN通过在生成器和判别器中引入条件信息,使得生成样本变得可控。文章详细解释了CGAN的工作原理,并展示了其在MNIST数据集上根据指定类标签生成手写数字图像的实验结果。
《Conditional Generative Adversarial Nets》

前言
GAN的提出为生成模型的学习提供了一种新的方法(具体内容可参见:https://blog.youkuaiyun.com/Forlogen/article/details/88903711), 但是它存在一个很大的问题就是:生成器生成的假样本是不可控的,它完全取决于输入的随机噪声,我们无法预测生成的假样本是什么,所以这就导致了条件生成对抗网络(Conditional Generative Adversarial Nets,CGAN)的出现。CGAN中引入了一个新的数据 y y y ,也就是名字中的Condition,它对于G和D都是有效的。这样在G生成假样本时,输入不光是随机噪声,还有希望它生成的样本的类标签,对于D来说,输入也多了类标签这一项,从而一定程度上解决GAN生成不可控的问题。
在这篇论文中,作者通过在MNIST数据集上进行实验,显示了可以根据指定的类标签生成对应的手写数字的图像。同时提出这种方法可以用于多模态模型的学习,并且可以产生丰富的不属于训练标签的描述性标记。
CGAN
在GAN中包含如下的两部分:
- 生成器(Generator,G):用来掌握真实数据的分布,具体来说就是输入一个随机的噪声,生成一个假样本
- 判别器(Discriminator,D):用来判断输入的样本是真实的还是G生成的
G和D都是非线性的函数,例如通常都用多层感知机构建。总体来说它要解决如下这个最大最小化的博弈问题:
min
G
max
D
V
(
G
,
D
)
=
E
x
∼
p
d
a
t
a
(
x
)
l
o
g
D
(
x
i
)
+
E
x
∼
p
z
(
z
)
l
o
g
(
1
−
D
(
G
(
z
i
)
)
)
\min \limits_{G} \max \limits _{D} V(G,D)=E_{x \sim p_{data}(x) } logD(x_{i})+E_{x \sim p_{z}(z)}log(1-D(G(z_{i})))
GminDmaxV(G,D)=Ex∼pdata(x)logD(xi)+Ex∼pz(z)log(1−D(G(zi)))
但是如果G和D都依赖于一些额外的信息
y
y
y ,那么GAN就变成了CGAN。其中
y
y
y 可以是任何类型的信息,可以是类标签,也可以是其他模式的数据。我们可以将
y
y
y 做为G和D另加的一个输入层,从而将GAN改造成CGAN。
CGAN的框架如下所示:
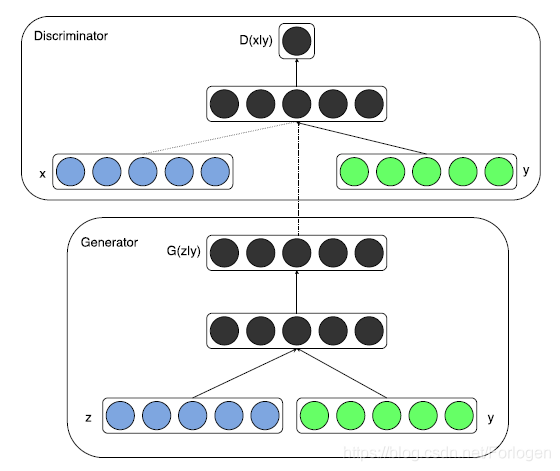
在G部分,随机噪声 z z z 和条件 y y y 组合成一个连接隐藏表达传入G;在D部分,G生成的样本 x x x 和条件 y y y 作为输入,传入D中,输入一个在条件 y y y 下判别 x x x 为真假的概率。
同样的CGAN的目标函数也是G和D博弈的过程,公式表达如下所示:
min
G
max
D
V
(
G
,
D
)
=
E
x
∼
p
d
a
t
a
(
x
)
l
o
g
D
(
x
i
∣
y
)
+
E
x
∼
p
z
(
z
)
l
o
g
(
1
−
D
(
G
(
z
i
∣
y
)
)
)
\min \limits_{G} \max \limits _{D} V(G,D)=E_{x \sim p_{data}(x) } logD(x_{i}|y)+E_{x \sim p_{z}(z)}log(1-D(G(z_{i}|y)))
GminDmaxV(G,D)=Ex∼pdata(x)logD(xi∣y)+Ex∼pz(z)log(1−D(G(zi∣y)))
注意!
这里需要注意的一个问题是:为什么在G和D的输入中都要有条件y呢?这是因为如果D的输入中不包含y,那么将G生成的假样本和真实的数据做为D的输入后,D最后会给出一个分数。但是D此时并不知道条件y的存在,因此它只会判别生成的样本是真实的还是G生成的,这样的话,条件y就会起不到想要的作用。因此需要将y同时输入到D中,这样它就会根据输入的样本的真实性以及是否符合条件的描述,给出一个综合的分数。
实验
单模态实验
作者在MNIST上做了CGAN的实验,以图像的类标签做为条件 y y y ,100维的噪声先验分布是从unit hypercube(单位超方体)的均匀分布采样得到的,模型的训练使用小批次随机梯度下降SGD,mini-batch大小为100,初始化的学习率为0.1,指数衰减因子为1.00004,最终的学习率为0.000001。动量法的参数初始化为0.5,最终增加到0.7。G和D都以0.5的比率使用dropout,最后使用验证集上的最佳对数似然估计作为停止点。
实验结果如下所示:

条件对抗网络的结果显示了,我们的实验结果和基于其他网络得到的结果相近,但是比其中的几种方法更加优越——包括非条件对抗网络。下图则显示了一些CGAN生成的样本,每一行是基于一个标签生成的样本,每一列代表了生成的不同样本。

多模态实验
此外作者还针对多模态的情况做了相关的实验,具体内容可见于原论文。

未来工作
这篇论文展示了CGAN的潜力,同时也为发现更加有用、更加有趣的东西提供了新的思路。在未来进一步的探索当中,作者希望展示更加丰富的模型以及对于模型表现、特性更加具体深入的分析。同样的,作者也在未来的实验中,可以通过一次使用多个标签取得更好的结果。另外一个未来可以探索的方向是可以将对抗网络和语言模型结合到一起训练。

















 1241
1241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









