






 提出了一种新的使用生成对抗网络(GAN)的方法DiscoGAN,可在无显式配对数据的情况下发现不同域间的关系,实现风格迁移并保留关键信息。
提出了一种新的使用生成对抗网络(GAN)的方法DiscoGAN,可在无显式配对数据的情况下发现不同域间的关系,实现风格迁移并保留关键信息。
《Learning to Discover Cross-Domain Relations with Generative Adversarial Networks》

摘要
人类可以很容易的识别两个不同域的东西,但是让机器去做这件事就需要给它大量的对于基本事实对的描述,这是一件很具挑战性的工作。本文作者提出了一种的新的使用GAN的方法,可以在预先没有任何事实对的的基础上发现不同域的相互关系,将这种方法称为DiscoGAN。使用它可以实现风格的不同图像之间的风格迁移,同时保留原始图像的关键性信息。
背景
在DiscoGAN之前,也有人提出了相关的算法,但是它们依赖于人工或是其他算法提供的显示的事实对数据。而很多情况下这样的事实对数据是不易获取的,同时也是一项破费人力的工作。同时如果某个领域中缺少相应的图像,或者有多个对应的图像,将它们进行配对也是一项棘手的工作。
而DiscoGAN的提出,解决了在没有任何显式配对数据的情况下发现两个域之间的关系的难题。它使用两组图像进行训练,不需要任何显示的配对标签,同样不需要预训练。将一个域的图像输入到生成器,生成另一个领域的图像。
DiscoGAN的核心在于它使用了两个不同的GAN,将它们耦合起来来确保每一个域都有到另一个域的映射。此外它还加了如下的两个限制:
- 对原图像的重构后得到的新图像应该接近原图像
- 转换到另一个域中的图像应该尽可能的符合那个域中图像的特征
经过相关的实验证明,DiscoGAN相对于之前的模型,鲁棒性更好,同时也能很好的解决模式崩溃的问题。另外当将其应用到图像转换时,转换后的图像可以在保持其他属性不变的情况下,始终改变指定的属性。
三种模型的对比
在讨论模型前,我们先做一些相关的定义:
-
A A A 、 B B B :表示两个域
-
G A B G_{AB} GAB :表示 A A A 域元素到 B B B 域元素之间的映射
-
G B A G_{BA} GBA :表示 B B B 域元素到 A A A 域元素之间的映射
-
条件:将映射关系约束为一种双射,即 G A B G_{AB} GAB 和 G B A G_{BA} GBA 互为对方的逆映射
对于 A A A 域中所有 x A x_{A} xA 来说, G A B G_{AB} GAB 所有可能的结果值的完整集合,都应该包含在 B B B 域中, G B A ( x B ) G_{BA}(x_{B}) GBA(xB)也是如此。
- G A B o G B A ( x A ) G_{AB} \ o\ G_{BA}(x_{A}) GAB o GBA(xA) : 表示经过两个对应的G重构后的 x A x_{A} xA的结果
- d ( G A B o G B A ( x A ) , x A ) d(G_{AB} \ o\ G_{BA}(x_{A}),x_{A}) d(GAB o GBA(xA),xA) :表示重构后的图像与原图像之间的差距,理论上希望重构后的图像和原图像要一样,但是这是不实际的,所以更多的是比较两者之间的差距。 d ( G B A o G A B ( x B ) , x B ) d(G_{BA} \ o\ G_{AB}(x_{B}),x_{B}) d(GBA o GAB(xB),xB) 同理
但是上面的评估方法通常也是很难优化的,所以继续放宽约束,而使用类似于GAN一样的损失函数:
−
E
x
A
∼
P
A
[
log
D
B
(
G
A
B
(
x
A
)
)
]
−
E
x
B
∼
P
B
[
log
D
A
(
G
B
A
(
x
B
)
)
]
-E_{x_{A}\sim P_{A} [\log D_{B}(G_{AB}(x_{A}))]} \\ -E_{x_{B}\sim P_{B} [\log D_{A}(G_{BA}(x_{B}))]}
−ExA∼PA[logDB(GAB(xA))]−ExB∼PB[logDA(GBA(xB))]
标准GAN
如下图所示为标准GAN的架构,其中可以将G看作是Auto-encoder中的encoder和decoder的一种配对,而在D类似于G中的encoder。论文中所涉及的实验配置,具体可见论文中的2.2部分。
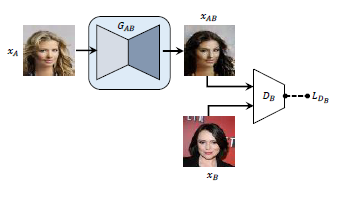
重构损失函数的GAN
为了更好的适合要解决的问题,作者对于标准GAN进行了一些修改,例如使用图像做为G的输入部分,而不再是使用随机的噪声。
使用标准的GAN只能学到A域到B域单向的映射,作者通过增加了一个G以及重构损失函数来保证从B域同样也可以学到A域的映射。这样的架构就保证了每一个G都可以学到从input域到output域的映射,这样的映射就是一种双射。
它的架构如下所示:
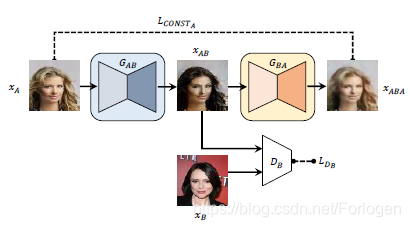
x A x_{A} xA 由 G A B G_{AB} GAB 生成 x A B x_{AB} xAB ,再由 G B A G_{BA} GBA 生成 x A x_{A} xA的重构图像 x A B A x_{ABA} xABA ,我们可以使用很多种的方式来比较两者的差距,比如MSE、余弦距离、合页损失等。同时将 x A B x_{AB} xAB和真实的图像 x B x_{B} xB 一起输入到 D B D_{B} DB 中进行判别。
上面的过程可以用以下的数学表达式进行表述:
x
A
B
=
G
A
B
(
x
A
)
x
A
B
A
=
G
B
A
(
x
A
B
)
=
G
B
A
o
G
A
B
(
x
A
)
L
C
O
N
S
T
A
=
d
(
G
B
A
o
G
A
B
(
x
A
)
,
x
A
)
L
G
A
N
B
=
−
E
x
A
∼
P
A
[
log
D
B
(
G
A
B
(
x
A
)
)
]
x_{AB}=G_{AB}(x_{A}) \\ x_{ABA}=G_{BA}(x_{AB})=G_{BA}\ o\ G_{AB}(x_{A}) \\ L_{CONST_{A}}=d(G_{BA}\ o\ G_{AB}(x_{A}),x_{A}) \\ L_{GAN_{B}}=-E_{x_{A}\sim P_{A} [\log D_{B}(G_{AB}(x_{A}))]}
xAB=GAB(xA)xABA=GBA(xAB)=GBA o GAB(xA)LCONSTA=d(GBA o GAB(xA),xA)LGANB=−ExA∼PA[logDB(GAB(xA))]
其中
L
C
O
N
S
T
A
L_{CONST_{A}}
LCONSTA 表示经过两个G重构后的图像与原始图像的差距;
L
G
A
N
B
L_{GAN_{B}}
LGANB 表示生成的图像有多真实。因此对于
G
A
B
G_{AB}
GAB 来说,它的损失可以看做是
L
C
O
N
S
T
A
L_{CONST_{A}}
LCONSTA 和
L
G
A
N
B
L_{GAN_{B}}
LGANB 的和,而对于
D
B
D_{B}
DB 来说,它的损失函数为:
L
D
B
=
−
E
x
B
∼
P
B
[
log
D
B
(
x
B
)
]
−
E
x
A
∼
P
A
[
log
(
1
−
D
B
(
G
A
B
(
x
A
)
)
)
]
L_{D_{B}}=-E_{x_{B}\sim P_{B} [\log D_{B}(x_{B})]}-E_{x_{A}\sim P_{A} [\log(1-D_{B}(G_{AB}(x_{A})))]}
LDB=−ExB∼PB[logDB(xB)]−ExA∼PA[log(1−DB(GAB(xA)))]
但是这样的模型同样存在一个问题:由于所有的映射都是单射,且没有从B到A的映射,所以无法保证很好的学到两个域之间的关系。
比如考虑两个可能的多模态图像域A和B。如下图所示显示了从输入域A到域B的理想映射其中,每个数据模式都映射到目标域中的一个单独模式。但是在图3b中出现了GAN中很普遍的模式崩溃问题,即来自一个域的多个模式的数据映射到另一个域的单个模式。例如,两个 G A B G_{AB} GAB 将两个不同方向的汽车图像映射到B域的一种模式下
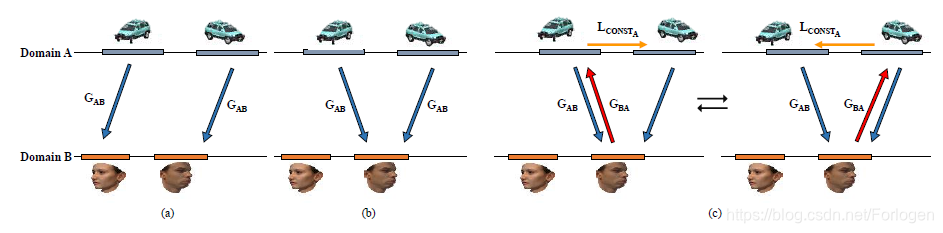
从某种意义上说,在标准GAN中加入重构损失是为了解决模式崩溃问题。但是如在图3c所示,域A中的模式与域B中的模式匹配,但是域B模式只能直接指向两个域A模式中的一个。虽然额外的重构损失LCONSTA迫使重构后的样本与原始样本匹配,但是这种更改会导致两种状态之间的振荡,并不能解决模崩溃问题。
DiscoGAN
而作者提出的DiscoGAN的架构如下所示:
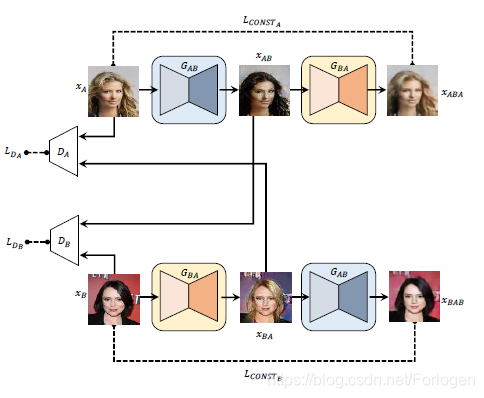
这种模型可以看做成上面重构损失函数的GAN的耦合,它不仅可以学习到一个域和另一个域之间互相的映射,同时也有同一个域的反向映射。两个模型同时训练,两个 G A B G_{AB} GAB 和 G B A G_{BA} GBA 共享参数,而且生成的 x A B x_{AB} xAB 和 x B A x_{BA} xBA 分别输入到 D B D_{B} DB 和 D A D_{A} DA 中。
与前一个模型的一个关键区别是,来自两个域的输入图像都被重构,并且存在两个重构损失
L
G
=
L
G
A
B
+
L
G
B
A
=
L
G
A
N
B
+
L
C
O
N
S
T
A
+
L
G
A
N
A
+
L
C
O
N
S
T
B
L
D
=
L
D
A
+
L
D
B
L_{G}=L_{G_{AB}}+L_{G_{BA}}=L_{GAN_{B}}+L_{CONST_{A}}+L_{GAN_{A}}+L_{CONST_{B}} \\L_{D}=L_{D_{A}}+L_{D_{B}}
LG=LGAB+LGBA=LGANB+LCONSTA+LGANA+LCONSTBLD=LDA+LDB
实验
Toy Experiment
首先为了证明所提出的这种对称模型对于模式崩溃问题的良好性能,做了一个演示实验。A和B中的数据
都是二维的,真实样本都取自混合高斯模型。过程如下所示:
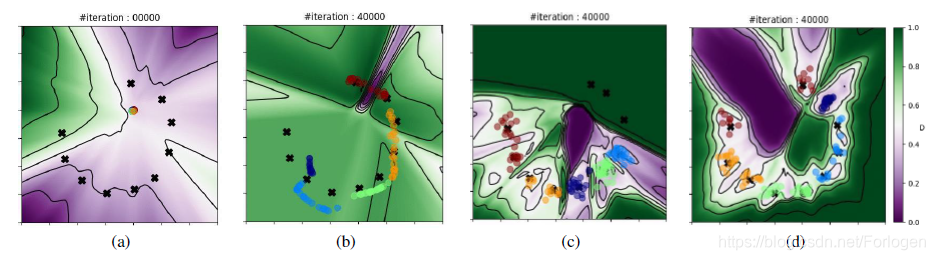
其中彩色背景表示D的输出值,”x”表示B种不同的模式。
- a:标示了10个目标模式和最初的转换结果;
- b:是标准的GAN迭代40000次的结果;
- c:是加入重建损失的网络迭代40000次的结果;
- d:是文章提出的DiscoGAN迭代40000次后的结果。
标准GAN的许多不同颜色的转换点都位于B相同的模式下,海蓝和浅蓝色的点离得很近,橙色和绿色的点也在一起,多种颜色的点(A中的多种模式)都映射到B的同一种模式下。带有重建损失的GAN的模式崩溃问题已经不那么严重了,但是海蓝、绿色和浅蓝色的点仍然会在少数几个模式上重叠。标准的GAN和带有重建损失的GAN都没有覆盖B中的所有模式,DiscoGAN将A中的样本转换为B中有边界不重叠的区域,避免了模式崩溃,并且产生的B样本覆盖了所有10种模式,因此这个映射是双射,从A转换的样本也把B的D给骗过了。
转换实验
车到车的转换实验
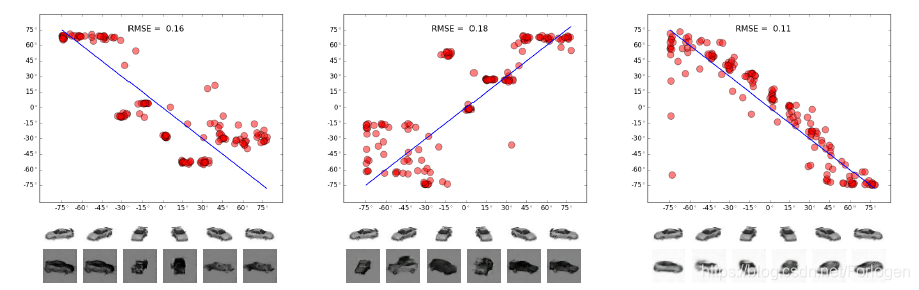
其中横轴表示输入图像的预测方位角,纵轴表示转换图像的预测方位角,三个图像分别代表标准GAN、重构损失函数的GAN和DiscoGAN的结果,从中我们可以看出DiscoGAN的RMSE更小,更能表现出原始图像和转换后的图像之间的关系。
下图是名人头像某一属性的改变,比如性别、发色、是否戴眼镜等。

下图是不同类别图像之间的转换,如从椅子到汽车、从汽车到人脸。

下图是图像的素描轮廓图和实物填充图之间的转换。

结论
本文作者提出了一种利用生成对抗性网络发现跨域关系的学习方法DiscoGAN。它不需要任何显式的配对标签就可以工作,并学会将来自非常不同领域的数据集关联起来。通过实验证明,DiscoGAN可以生成高质量的风格转换图像。未来一个方向是修改DiscoGAN使它可以用来处理混合模式(例如文本和图像)。

















 920
920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









