




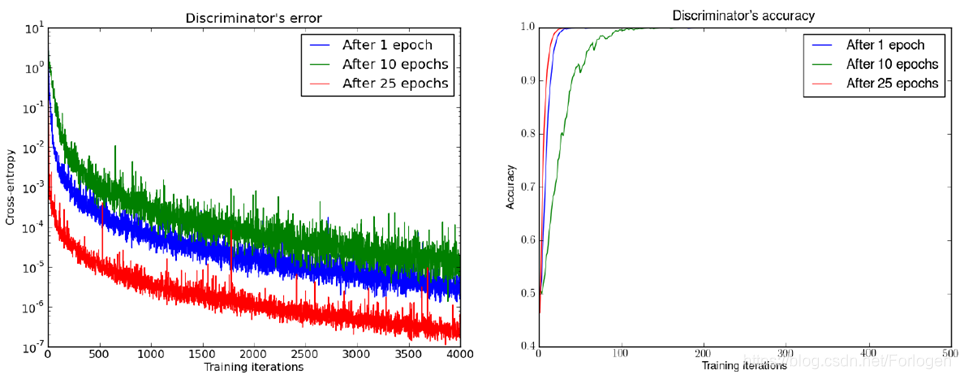
在Martin Arjovsky, Léon Bottou, Towards Principled Methods for Training Generative Adversarial Networks, 2017, arXiv preprint这篇论文中,作者发现在选择不同的epoch时,随着迭代次数的增加,它们的交叉熵都会减小到一个很低的值,同时准确度也都会到达1.0
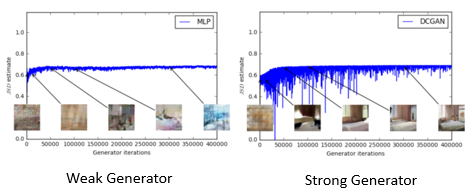
但是通过JS散度来直到GAN的训练过程,从中得到的信息却是很少的。如下图所示,即使使用了一个很强的Generator,JS divergence 大体上仍然是处在某一个固定的值附近
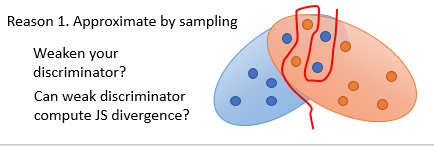
其中的原因一个可能是由于我们是使用了抽样的方法,虽然真实数据和随机噪声数据之间有一定的重叠部分,但是可能抽样取到的值不在其中,或是D太强,可以找到一个边界将其完美的分割开,这时候就需要我们使用一个弱一点的D来训练。
另一个原因可能是由于数据本身的特质导致的,比如当我们的数据是如下的二维线性的形式,它们重叠的部分本身就很小。

再想一下GAN的基本思想是什么?GAN希望pG(x)p_{G}(x)pG(x)和pdata(x)p_{data}(x)pdata(x)越接近越好,对于JS散度来说,就是希望它越小越好。但是如果JS散度变化不明显的话,使得pG(x)p_{G}(x)pG(x)接近pdata(x)p_{data}(x)pdata(x)动力就变得很小,训练的过程将会很慢。

那么解决这个问题的一个办法就是人为的添加一些噪声,比如往D的输入中添加噪声、对于图像的真实标签做一些扰动……这样做就会使得数据的范围变宽,重叠部分就会大一些。当然随着训练的推进,噪声要逐渐减小。


















 452
452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









