




 介绍SeqAttnGAN模型,一种基于交互式对话的图像生成技术,允许用户通过多轮对话细化图像,强调其创新性及在Zap-Seq和DeepFashion-Seq数据集上的表现。
介绍SeqAttnGAN模型,一种基于交互式对话的图像生成技术,允许用户通过多轮对话细化图像,强调其创新性及在Zap-Seq和DeepFashion-Seq数据集上的表现。
《Sequential Attention GAN for Interactive Image Editing via Dialogue》
有关Text-to-Image的文章已经看了很多了,但是大多都是根据单句描述生成高质量的图像。本文提出了一种基于交互式对话的图像生成任务,它不仅要求模型可以根据文本描述生成相应的图像,还可以实现在多轮对话中根据后续的对话对生成图像进行不断修改。由于任务的特殊性,现有的数据集难以满足训练的需求,因此作者根据现有的数据集提出了两个新的数据集Zap-Seq和DeepFashion-Seq(可惜的是作者至今仍未放出数据集)。
本文的贡献主要在于:
-
本文提出的SeqAttnGAN采用了序列化的GAN的架构方式,并采用了注意力机制,期望以类似对话的形式根据用户的描述和先前给出的图像生成新的更符合需求的结果,从而实现交互式的图像生成过程。
-
使用neural state tracker在每一轮编码原图像和文本描述,从而产生更高质量的图像和对话的上下文
-
在Zap-Seq和DeepFashion-Seq两个数据集上均取得了较好的效果
模型的整体架构如下所示:
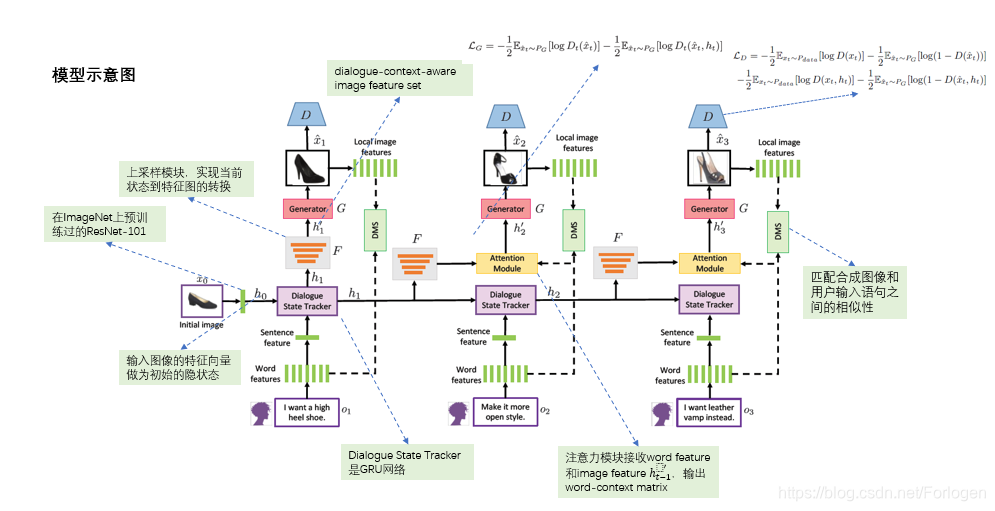
整个模型的示意图是按对话的轮数展开的,因此我们只需要看下前两个阶段就可以理解它做了什么。初始时,用户的输入文本记为 o 1 o_{1} o1,通过BiLSTM得到word feature,将所有词的表示采用简单的拼接或是其他的方式便可以得到Sentence feature。初始时,使用一张图像的表示作为Dialogue State Tracker的初始状态,Dialogue State Tracker负责融合输入的表示Sentence feature和图像的表示,得到隐状态 h 1 h_{1} h1。 h 1 h_{1} h1经过上采样模块得到融合描述和图像的表示(dialugue-context-aware image feature) h 1 ′ h_{1}' h1′,接着经过G便可以生成相应的图像 x 1 ^ \hat{x_{1}} x1^。
后续阶段中,在得到输入的表示Sentence feature和上一阶段Dialogue State Tracker的输出
h
i
−
1
h_{i-1}
hi−1后,并不是根据Dialogue State Tracker的输出来上采样得到G的输入,而是使用注意力模块(Attention Module)得到
h
i
′
h_{i}'
hi′。其中注意力模块根据上采样得到的表示和用户此时的输入,实现在生成图像的某个局部时应该关注于文本哪个位置的描述,最后得到隐状态
h
i
′
h_{i}'
hi′,再将其输入到G中生成此阶段的图像。
h
t
=
GRU
(
h
t
−
1
,
o
t
)
h
t
′
=
F
a
t
t
n
(
o
t
,
F
(
h
t
−
1
)
)
x
t
=
G
(
h
t
′
,
ϵ
t
)
h_{t}=\text{GRU}(h_{t-1},o_{t}) \\ h_{t}'=F_{attn}(o_{t},F(h_{t-1})) \\ x_{t} = G(h_{t}',\epsilon_{t})
ht=GRU(ht−1,ot)ht′=Fattn(ot,F(ht−1))xt=G(ht′,ϵt)
其中
F
(
⋅
)
F(\cdot)
F(⋅)表示上采样模块,
ϵ
t
\epsilon_{t}
ϵt表示采样自正态分布的噪声向量。
不过在Attention Module小节中由这样的一段描述:

按照这里的描述,应该是 h t − 1 ′ h_{t-1}' ht−1′的每一列和输入 o t o_{t} ot中的每个词计算注意力权重得到word-content向量 c i c_{i} ci。 ( c 0 , c 1 , . . . , c N ) (c_{0},c_{1},...,c_{N}) (c0,c1,...,cN)才是第 t t t阶段G的输入。这样的话就和前面的公式有些不符了,不知道是不是我的理解有问题。
另一个重要部分是图中的DMS,它用来匹配G生成的图像和用户输入之间的相似性,这里相当于起到正则化的作用。对于给定的数据集
{
x
0
,
x
1
,
o
1
,
.
.
.
,
x
T
,
o
t
}
\{x_{0},x_{1},o_{1},...,x_{T},o_{t}\}
{x0,x1,o1,...,xT,ot},首先将
x
t
x_{t}
xt作为输入图像
I
i
I_{i}
Ii,
x
t
−
1
x_{t-1}
xt−1和
o
t
o_{t}
ot拼接为向量的文本向量
D
i
D_{i}
Di,这样便得到了转换后的数据集
{
I
i
,
D
i
}
i
=
1
N
\{I_{i},D_{i}\}_{i=1}^N
{Ii,Di}i=1N。
D
i
D_{i}
Di和
I
i
I_{i}
Ii之间的匹配度通过计算后验概率得到
P
(
D
i
∣
I
i
)
=
exp
(
γ
R
(
I
i
,
D
i
)
)
∑
j
=
1
M
exp
(
γ
R
(
I
i
,
D
j
)
)
P(D_{i}|I_{i})=\frac{\exp(\gamma R(I_{i},D_{i}))}{\sum_{j=1}^M \exp(\gamma R(I_{i},D_{j}))}
P(Di∣Ii)=∑j=1Mexp(γR(Ii,Dj))exp(γR(Ii,Di))
其中
γ
\gamma
γ是平滑系数,
R
(
⋅
)
R(\cdot)
R(⋅)表示图像的子区域和文本中的词之间注意力权重的计算。
那么对于 M M M对配对数据的损失函数为 L D M S i → d = − ∑ i = 1 M log P ( D i ∣ I i ) L_{DMS}^{i \rightarrow d}=-\sum_{i=1}^M \log P(D_{i}|I_{i}) LDMSi→d=−i=1∑MlogP(Di∣Ii)对称的存在 L D M S d → i L_{DMS}^{d \rightarrow i} LDMSd→i,那么DMS的整体的损失函数为 L D M S = L D M S d → i + L D M S i → d L_{DMS}=L_{DMS}^{d \rightarrow i}+L_{DMS}^{i \rightarrow d} LDMS=LDMSd→i+LDMSi→d
通过 L D M S L_{DMS} LDMS迫使模型生成更符合描述的图像,同时保证生成图像的质量。
关于GAN的部分,G的损失函数为 L G = − 1 2 E x ^ t ∼ P G [ log D t ( x t ^ ) ] − − 1 2 E x ^ t ∼ P G [ log D t ( x t ^ , h t ) ] L_{G}=-\frac{1}{2} E_{\hat{x}_{t} \sim P_{G}}[\log D_{t}(\hat{x_{t}})] - -\frac{1}{2} E_{\hat{x}_{t} \sim P_{G}}[\log D_{t}(\hat{x_{t}},h_{t})] LG=−21Ex^t∼PG[logDt(xt^)]−−21Ex^t∼PG[logDt(xt^,ht)]
D的损失函数为 L D = − 1 2 E x t ∼ P d a t a [ log D ( x t ) ] − 1 2 E x ^ t ∼ P G [ log ( 1 − D ( x t ^ ) ) ] − − 1 2 E x t ∼ P d a t a [ log D ( x t , h t ) ] − 1 2 E x ^ t ∼ P G [ log ( 1 − D ( x t ^ , h t ) ) ] L_{D}=-\frac{1}{2} E_{{x}_{t} \sim P_{data}}[\log D(x_{t})]-\frac{1}{2}E_{\hat{x}_{t} \sim P_{G}}[\log (1-D(\hat{x_{t}}))] --\frac{1}{2} E_{{x}_{t} \sim P_{data}}[\log D(x_{t},h_{t})]-\frac{1}{2}E_{\hat{x}_{t} \sim P_{G}}[\log (1-D(\hat{x_{t}},h_{t}))] LD=−21Ext∼Pdata[logD(xt)]−21Ex^t∼PG[log(1−D(xt^))]−−21Ext∼Pdata[logD(xt,ht)]−21Ex^t∼PG[log(1−D(xt^,ht))]
最后模型整体的损失函数为 L = 1 T ∑ t = 1 T L G + L D + L D M S L=\frac{1}{T} \sum_{t=1}^T L_{G}+L_{D}+L_{DMS} L=T1t=1∑TLG+LD+LDMS
实验
数据集为Zap-Seq和DeepFashion-Seq,基准模型为StackGAN、AttnGAN和LIBE。
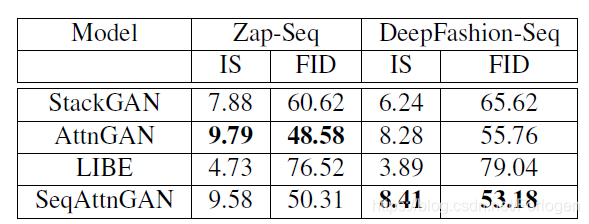
在两个数据集上IS和FID值的情况如下所示,从中可以看出在单轮图像生成中,AttenGAN在Zap-Seq上效果更好,SeqAttnGAN在Deep Fashion-Seq上效果更好一些

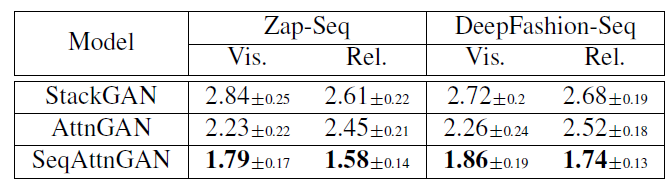
关于SSIM值的评估结果如下,从中看出SeqAttnGAN的效果更好

人评估的结果如下,整体来看也显示了SeqAttnGAN的优异性
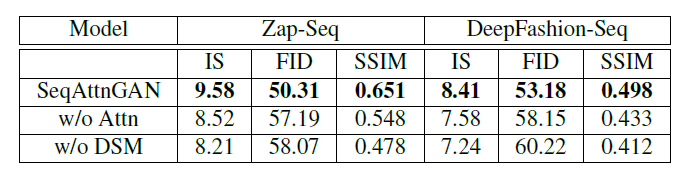
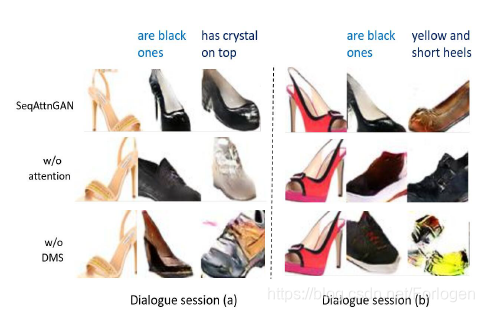
消融实验结果如下,从中可以看出注意力机制和DMS对于模型的效果是有影响的。
总结
作者所提出的这个任务是挺有意义的,但是从模型最后的结果来看,依我愚见,它实现的更像是根据用于的输入来选择对应的图像,不太像对于同一图像的细节补充和修改,另外对于模型的实现也有很多可以再做改进的地方。

















 28
28

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









