







 这篇博客详细介绍了PyTorch中的torch.where函数,它根据条件选择张量中的元素。当条件满足时,保留原张量的值,否则替换为另一个张量的对应值。文章通过例子展示了如何使用该函数,并指出张量与标量的组合要求。此外,还提到了torch.nonzero(condition, astuple=True)与torch.where(condition)在查找满足条件元素位置上的等价性。
这篇博客详细介绍了PyTorch中的torch.where函数,它根据条件选择张量中的元素。当条件满足时,保留原张量的值,否则替换为另一个张量的对应值。文章通过例子展示了如何使用该函数,并指出张量与标量的组合要求。此外,还提到了torch.nonzero(condition, astuple=True)与torch.where(condition)在查找满足条件元素位置上的等价性。
第49个方法
torch.where(condition, x, y) → Tensor
此方法是将x中的元素和条件相比,如果符合条件就还等于原来的元素,如果不满足条件的话,那就去y中对应的值,公式为
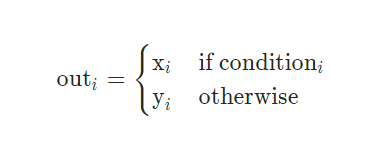
举个例子就清楚了,官方例子如下:
>>> x = torch.randn(3, 2)
>>> y = torch.ones(3, 2)
>>> x
tensor([[-0.4620, 0.3139],
[ 0.3898, -0.7197],
[ 0.0478, -0.1657]])
>>> torch.where(x > 0, x, y)
tensor([[ 1.0000, 0.3139],
[ 0.3898, 1.0000],
[ 0.0478, 1.0000]])
>>> x = torch.randn(2, 2, dtype=torch.double)
>>> x
tensor([[ 1.0779, 0.0383],
[-0.8785, -1.1089]], dtype=torch.float64)
>>> torch.where(x > 0, x, 0.)
tensor([[1.0779, 0.0383],
[0.0000, 0.0000]], dtype=torch.float64)
其中第一个例子,取x大于零,那么x中小于0的值就会变成y中与之相对应位置的值,由于y里面都是1,所以x中小于0的位置都变成了1。
第二个例子条件仍然为x>0,但是这时的y是0,那么x中小于0的值就都变成了0。
其实是有对应位置关系的,x中元素不满足条件时,取得是y中对应的元素来填充里面的值。如下所示:

a中第一个小于零的值为-1,被b中对应的值3直接填补,而-2被7填补,所以填补是有对应关系的,所以x和y必须是可广播的,否则就会报错。
标量和张量也可以组合,就如同官方的第二个示例,其中x就是张量,而y就是标量。目前有效地标量和张量的组合为:
- float型和double型
- integral型和long型
- complex型和complex 128型
而torch.where(condition)与torch.nonzero(condition, as tuple=True)相等,就是返回了其中满足条件的元素的位置,不过是以元组的形式返回的,第一个元组代表了第一个维度的位置,第二个代表第二维,一次类推,如下所示:

其中取了a中大于0的元素,返回了它们的位置,取第一个里面的为第一维,第二个里面的为第二维,即位置为(0, 0), (0, 3)…,详情请看torch.nonzero()

















 1165
1165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









