




 pandas的groupby函数是数据处理的关键,它通过split-apply-combine原理进行数据切割、应用操作和合并。文章探讨了groupby的sort和as_index参数,强调在性能和内存使用上的考虑。此外,对比了apply、agg和transform的区别,指出agg用于单个结果计算,而transform适用于扩展计算结果到所有行,尤其在窗口函数场景中。
pandas的groupby函数是数据处理的关键,它通过split-apply-combine原理进行数据切割、应用操作和合并。文章探讨了groupby的sort和as_index参数,强调在性能和内存使用上的考虑。此外,对比了apply、agg和transform的区别,指出agg用于单个结果计算,而transform适用于扩展计算结果到所有行,尤其在窗口函数场景中。
pandas的groupby是一个极其重要的函数,熟悉掌握能解决非常多的问题
#groupby的基本语法参数
DataFrame.groupby(self, by=None, axis=0, level=None, as_index: bool = True
, sort: bool = True, group_keys: bool = True, squeeze: bool = False
, observed: bool = False)
这是一个非常好的解释groupby的图,原理是先把数据切割,计算,合并。
- Splitting 由
groupby实现 - Applying 由
agg、apply、transform、filter实现具体的操作 - Combining 由
concat等实现
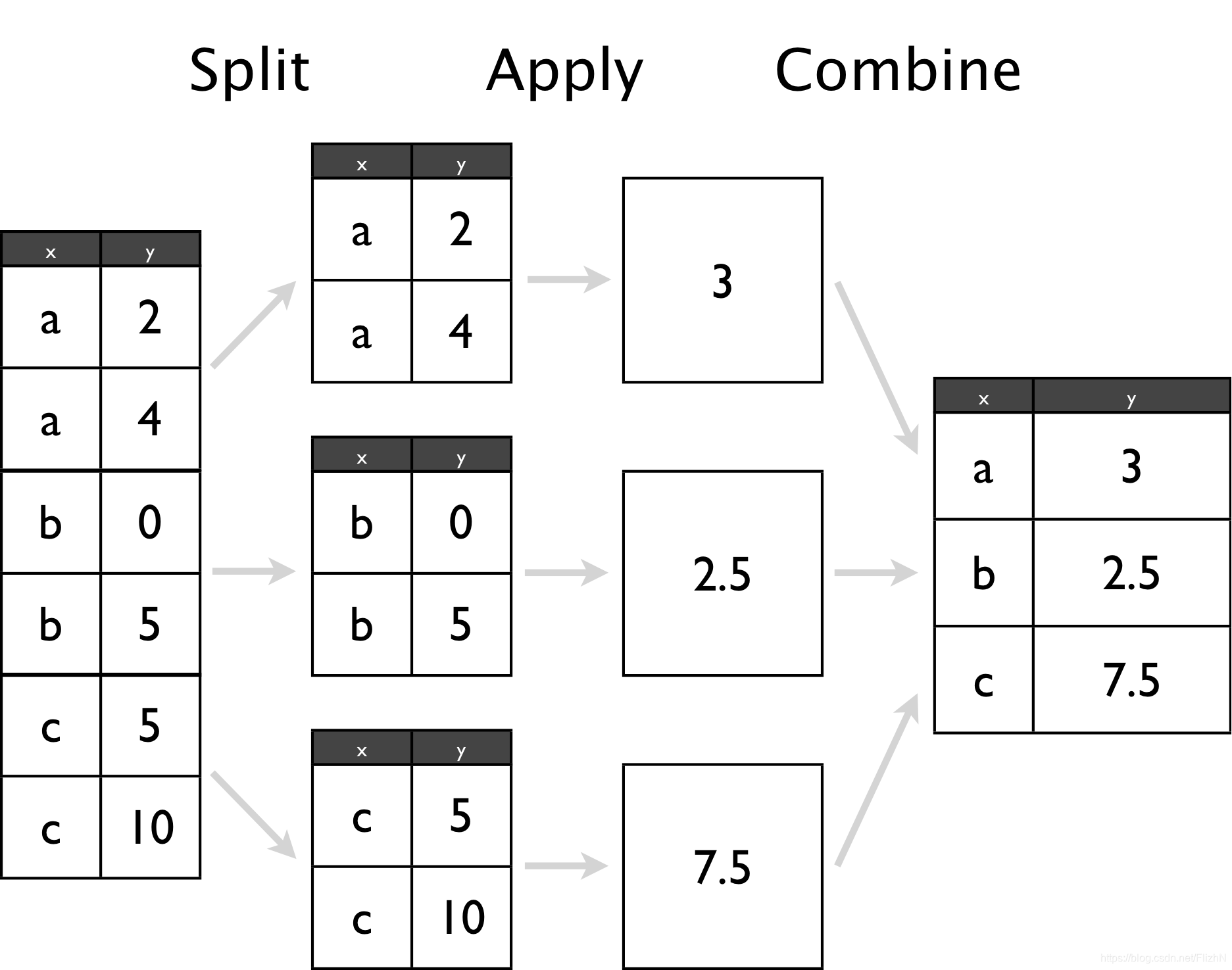
两个重要参数的使用
#对A,B两列的数据进行分组汇总
df.groupby(["A", "B"], as_index=False, sort=False).agg({"C": "sum", "D": "mean"}) #方法1
df.groupby(["A", "B"]).agg({"C": "sum", "D": "mean"}).reset_index() #方法2
方法1和方法2最后能得到相同的结果,但是从性能角度考虑,方法1更优
- sort参数默认是开启的,分组完之后会对数据做排序,排序耗内存,不用要设置关闭。
- as_index参数可以节约调用reset_index() 的时间。且该参数仅对aggregation操作有效,如果是transform,则不会有效果。
groupby配合apply,agg,transform
agg VS apply
#apply一次只能计算一个结果,只能对多个列调用相同的一个函数
df.groupby("name", sort=False).score.apply(lambda x: x.sum()) #apply计算score的和
df.groupby("name", sort=False).score.apply(lambda x: x.min()) #apply计算score的最小值
df.groupby("name", sort=False).score.apply(lambda x: x.max()) #apply计算score的最大值
#agg一次计算多个结果,多个列独立地调用不同的函数
df.groupby("name", sort=False).agg({"score": [np.sum, np.max, np.min]}) #agg同时计算3个值
#两种计算方式最后得到的数据结果一样
#上面通过agg调用的函数是numpy的计算函数,实际可以修改成pandas的sum,max,和min。大数据集下,效率更高。
#agg中na值是被忽略的,可以好好利用这一个属性
- apply一次只能计算一个结果,只能对多个列调用相同的一个函数
- agg一次计算多个结果,多个列独立地调用不同的函数
transform VS agg
transfrom本身不是一个非常常用的函数,但是在某些特定的计算场景非常好用。transform作用于数据框自身,并且返回变换后的值。返回的对象和原对象拥有相同数目的行,但可以扩展列。
df #源数据
df.groupby("A").agg('sum') #通过agg计算
df.groupby("A").transform('sum') #通过transform计算
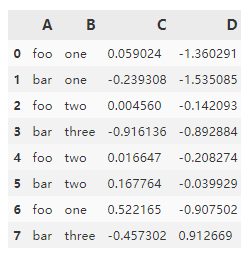
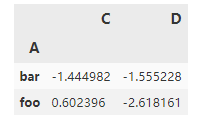
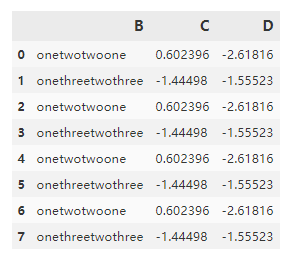
第一张图是源数据,第二张图是agg后的数据,第三张图是transform后的数据。
- 通过agg计算的数据,是对分组数据的聚合计算;
- 通过transform后的数据,是一种类似于窗口函数的计算,如果是聚合函数,直接将聚合结果拓展到其他每个分组行,非聚合函数,则是对每个分组的值单独计算。(一般用聚合函数比较多,其他自定义函数尽量少用,会出现一些奇怪的情况)

















 5028
5028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









