







1.分组运算
所谓的“分组运算”是多个步骤的一个组合,我们可以拆分为“split-apply-combine”(拆分-应用-合并),我觉得这个词很好的描述了整个过程。分组运算的第一个阶段,pandas对象(无论是Series,DataFrame还是其他的)中的数据会根据你所提供的一个或多个“key”,被拆分(split)为多个组。拆分操作是在对象的特定轴上执行的,例如,DataFrame可以在其行(axis = 0)或者列(axis = 1)上进行分组,然后,将一个函数应用(apply)到各个分组,并产生一个新值。最后,所有的这些函数的执行结果会被合并(combine)到最终的结果对象中。结果对象的形式一般取决于数据上所执行的操作。
注意:apply函数为聚合函数,例如,sum、mean、min、max等
下图展示了分组聚合的过程:
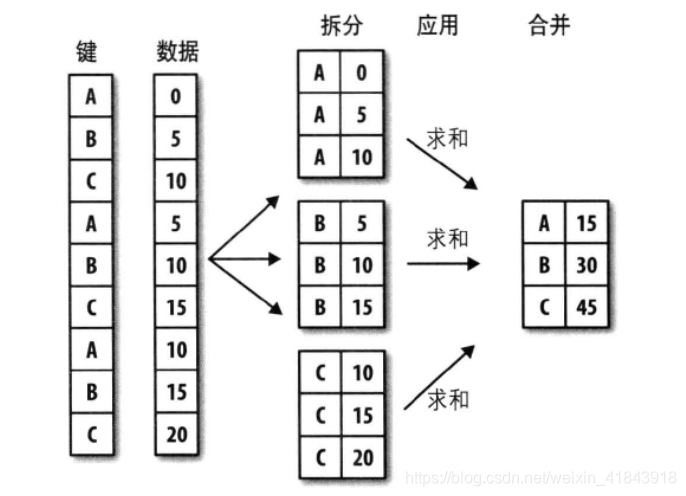
分组的key可以有多种形式,且类型不必相同:
- 1.列表或数组,但是其长度与待分组的轴是一样的。
- 2.表示DataFrame某个列明的值
- 3.字典或者Series,给出带分组轴上的值与分组名之间的对应关系。
- 4.函数,用于处理轴索引或者索引中的各个标签
** 注意:后三种只是快捷方式而已,其最终的目的仍然是产生一组用于拆分对象的值**
2.代码演示
如果觉得上面的东西看起来很抽象,不用担心,我将在下面给出大量示例。首先来看一下下面这个非常简单的表格型数据集(以DataFrame的形式给出)
import pandas as pd
import numpy as np
df = pd.DataFrame({'key1':['a','a','b','b','a'],
'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
print(df)
运行结果:
key1 key2 data1 data2
0 a one 0.015108 0.304983
1 a two 2.054185 -0.009759
2 b one -1.057348 -1.703048
3 b two -3.696947 -0.788548
4 a one 1.452735 0.388301
- 如果想按照‘key1’进行分组,并计算data1列的平均值。实现该功能的方式很多,而我们这里要用的是:访问data1,并根据key1调用groupby:
grouped = df['data1'].groupby(df['key1'])
print(grouped)
运行结果:
<pandas.core.groupby.groupby.SeriesGroupBy object at 0x1a2308ddd8>
- 变量grouped是一个GroupBy对象,它实际上还没有进行任何计算,只是含有一些有关分组键df[‘key1’]的中间数据而已。换句话说,该对象已经有了接下来对各个分组执行运算所需要的一切信息。例如,我们可以调用GroupBy的mean方法来计算分组平均值:
get_mean = grouped.mean()
print(get_mean)
运行结果:
key1
a 1.174009
b -2.377148
Name: data1, dtype: float64
- 稍后会将会详细讲解
.mean()的调用过程,这里最重要的是,数据(Series)根据分组键进行了聚合,产生了一个新的Series,其索引为key1列中的唯一值,之所以结果中的索引名称为key1,是因为原始的DataFrame的列df[‘key1’]就叫这个名字。 - 如果我们一次传入多个数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









