







一、前情提要
在高并发系统中,“稳定运行” 需要解决三大核心痛点:数据库压力过载、日志定位困难、敏感信息泄露。前两者关乎 “系统可用性”,后者关乎 “数据安全性”,三者缺一不可。
1、缓存的意义:解决数据库 “慢 IO 与并发上限” 瓶颈。
数据库(如 MySQL)本质是磁盘存储系统,磁盘 IO 速度远慢于内存(内存读写毫秒级,磁盘读写秒级,差距超 1000 倍),且默认并发连接数有限(如 MySQL 默认最大连接数 151)。一旦系统并发量上来(比如每秒 1000 次查询),数据库会因 “慢 IO 堆积” 和 “连接耗尽” 成为瓶颈,极端情况会触发 “锁表”“连接超时”,直接宕机。
核心思路是:尽可能让请求不碰数据库。Redis 作为内存数据库,读写速度极快(每秒支持 10 万 + 操作),能将高频查询结果暂存在内存中,让后续请求直接从内存拿数据 —— 这就是缓存的核心价值:用 “内存的快” 替代 “磁盘的慢”,拦截 90%+ 的高频请求,从源头减少数据库负担,是系统的 “长期防护屏障”。
2、Redis分布式锁的意义:解决缓存异常时的 “瞬时高并发”。
缓存虽能拦截绝大多数请求,但存在 “漏洞”:当缓存过期、缓存穿透(查询不存在的数据)时,大量请求会瞬间绕过缓存涌向数据库,即 “缓存击穿 / 穿透” 问题,仍会直接压垮数据库。
这时候需要分布式锁来 “限流兜底”:让 1000 个并发请求 “排队”,只允许 1 个请求抢锁成功后查数据库,其他请求自旋等待(如每隔 100ms 重试);待抢锁请求将数据库结果回写缓存后,释放锁,剩余请求直接从缓存拿数据。最终数据库最多只处理 1 次请求,完美避免 “瞬时高并发压垮数据库”,是系统的 “应急防护屏障”。
简言之,缓存 + 分布式锁是 “数据库防护组合拳”:缓存负责 “日常拦截”,分布式锁负责 “异常兜底”,二者结合确保数据库稳定。
3、日志追踪与敏感脱敏的意义:解决 “日志难找 + 信息泄露” 问题。
当系统上线后,新的痛点随之出现:
- 日志定位难:高并发场景下,每秒有成百上千条日志输出,一条请求的 “入口→Controller→Service→响应” 日志分散在海量记录中,前端反馈 bug 时,后端需翻遍日志才能匹配对应请求,效率极低;
- 敏感信息泄露:请求参数(如手机号、身份证号)、返回值(如用户密码)若直接打印到日志,会违反数据安全规范,存在隐私泄露风险。
这些 “日志治理” 需求,本质也是与业务无关的通用逻辑:如果每个接口都手动写 “生成唯一标识、过滤敏感参数、打印日志” 代码,会导致代码臃肿、易遗漏(比如忘记脱敏某字段)。
解决方案:用 “全链路 traceId 串联日志 + 注解式敏感脱敏”—— 在请求入口生成唯一 traceId,贯穿整个请求生命周期(日志输出、返回值),前端反馈 bug 时只需提供 traceId,后端即可快速定位所有关联日志;
同时通过注解标记敏感参数 / 返回值,自动过滤不打印,既解决 “日志难找” 问题,又保障 “数据安全”,是系统的 “可观测性与安全防护屏障”。
二、项目需求
高并发系统的 “稳定三角”。
缓存、分布式锁、日志追踪与敏感脱敏,三者共同构成高并发系统的 “稳定三角”:
- 缓存:长期防护,减少数据库日常请求;
- 分布式锁:应急兜底,解决缓存异常时的瞬时高并发;
- 日志追踪 + 脱敏:可观测性 + 安全,解决 bug 定位难与敏感信息泄露;
而这三者的实现,都面临同一个问题:通用逻辑与业务逻辑耦合—— 缓存需写 “查缓存→回写缓存”,锁需写 “抢锁→释放锁”,日志需写 “生成 traceId→脱敏”,这些代码与 “查数据库、返回结果” 等核心业务无关,却要在每个方法中重复编写。
AOP(面向切面编程)正是解决这类问题的 “利器”:将缓存、锁、日志等通用逻辑抽离成独立 “切面”,通过注解灵活插入业务方法,让开发者专注于核心业务。本文将通过三个实战案例,完整覆盖这三大场景,实现 “注解即功能” 的简洁代码。
三、实现方法
AOP的核心逻辑:它本质是“代理模式”的延伸,通过在“目标方法执行前后”插入通用逻辑,实现“业务与非业务逻辑解耦”。
假如我们要实现 “查询用户信息” 的功能,核心逻辑是查数据库,附加逻辑是:“先查 Redis、没查到再查库、查到后回写 Redis”,如果不用 AOP,代码会是这样:
// 不用AOP的写法:附加逻辑与核心逻辑耦合
public User getUserById(Long id) {
// 1. 查Redis(附加逻辑)
String key = "user:" + id;
User user = redisTemplate.opsForValue().get(key);
if (user != null) return user;
// 2. 查数据库(核心业务逻辑)
user = userMapper.selectById(id);
// 3. 回写Redis(附加逻辑)
if (user != null) redisTemplate.opsForValue().set(key, user);
return user;
}
如果有10个查询方法,就要写 10 遍 “查缓存 - 回写缓存” 的逻辑。而用 AOP 后,我们只需:
- 把 “查缓存 - 回写缓存” 抽成一个切面;
- 定义一个注解(如
@MyRedisCache); - 给需要加缓存的方法贴注解,切面自动生效。
这就是AOP的核心价值:通用逻辑抽离成切面,通过注解按需切入,业务代码只保留核心逻辑。
1、实战一:用AOP实现Redis缓存插件
第一个案例是 “基于 AOP 的 Redis 缓存插件”—— 目标是让任意查询方法贴个注解,就能自动实现 “先查 Redis、再查 DB、回写 Redis” 的逻辑。
要实现这个插件,需要三步:
- 定义注解:作为 “切面的触发标识”,让方法知道 “需要加缓存”,同时通过注解参数传递缓存键前缀等配置;
- 编写切面:实现 “查缓存 - 查 DB - 回写缓存” 的通用逻辑,通过 AOP 的环绕通知(
@Around)在目标方法执行前后插入逻辑; - 业务中使用:在 Service 层的查询方法上贴注解,测试效果。
1.1 步骤1:定义缓存注解@MyRedisCache
注解的作用是“标记方法需要缓存”,并传入2个关键参数:
· keyPrefix:缓存键的前缀,如“user”、“product”;
· matchValue:Spring EL表达式(如#id),用于动态获取方法参数拼接缓存键。
// 注解只能贴在方法上
@Target(ElementType.METHOD)
// 注解在运行时生效(AOP需要在运行时解析)
@Retention(RetentionPolicy.RUNTIME)
public @interface MyRedisCache {
// 缓存键前缀(必填)
String keyPrefix();
// 动态参数的Spring EL表达式(必填,如#id、#username)
String matchValue();
}
1.2 步骤2:编写缓存切面类MyRedisCacheAspect
切面是AOP的核心,这里用环绕通知(@Around),它能完整控制目标方法的执行(执行前、执行中、执行后),正好满足“查缓存 -> 缓存命中则返回,未命中则执行方法 -> 回写缓存”的逻辑。
// 标记为切面类
@Aspect
// 交给Spring管理
@Component
@Slf4j
public class MyRedisCacheAspect {
// 注入Redis操作模板
@Resource
private RedisTemplate redisTemplate;
// 1. 定义切点:所有贴了@MyRedisCache注解的方法,都会被切面拦截
@Pointcut("@annotation(com.atguigu.study.annotations.MyRedisCache)")
public void cachePointCut() {}
// 2. 环绕通知:在目标方法执行前后插入缓存逻辑
@Around("cachePointCut()")
public Object doCache(ProceedingJoinPoint joinPoint) throws Throwable {
Object result = null;
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
// 3. 解析方法上的@MyRedisCache注解,获取配置参数
MyRedisCache cacheAnnotation = method.getAnnotation(MyRedisCache.class);
String keyPrefix = cacheAnnotation.keyPrefix(); // 如"user"
String matchValueEl = cacheAnnotation.matchValue(); // 如"#id"
// 4. 用Spring EL解析matchValue,动态获取方法参数(如#id对应的值1001)
SpelExpressionParser parser = new SpelExpressionParser();
Expression expression = parser.parseExpression(matchValueEl);
EvaluationContext context = new StandardEvaluationContext();
// 把方法参数名和值存入EL上下文(让EL表达式能找到#id对应的参数值)
Object[] args = joinPoint.getArgs();
Parameter[] parameters = method.getParameters();
for (int i = 0; i < parameters.length; i++) {
context.setVariable(parameters[i].getName(), args[i]);
}
String dynamicValue = expression.getValue(context).toString(); // 如"1001"
// 5. 拼接最终的Redis缓存键(如"user:1001")
String cacheKey = keyPrefix + ":" + dynamicValue;
log.info("生成Redis缓存键:{}", cacheKey);
// 6. 先查Redis:命中则直接返回,不执行目标方法
result = redisTemplate.opsForValue().get(cacheKey);
if (result != null) {
log.info("Redis缓存命中,直接返回结果:{}", result);
return result;
}
// 7. Redis未命中:执行目标方法(即查数据库)
log.info("Redis缓存未命中,执行数据库查询");
result = joinPoint.proceed(); // 触发Service方法执行(如userMapper.selectById)
// 8. 回写Redis:将数据库结果存入缓存,下次查询直接命中
if (result != null) {
log.info("数据库查询成功,回写Redis缓存:{}", result);
redisTemplate.opsForValue().set(cacheKey, result);
}
return result;
}
}
1.3 在业务中使用注解
以“根据ID查询用户”为例,只需在Service方法上贴@MyRedisCache,无需写任何缓存逻辑:
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
@Resource
private UserMapper userMapper;
// 贴注解:keyPrefix是"user",matchValue是#id(动态获取方法参数id)
@Override
@MyRedisCache(keyPrefix = "user", matchValue = "#id")
public User getById(Serializable id) {
// 核心业务逻辑:只查数据库,缓存逻辑由切面自动处理
return userMapper.selectById(id);
}
}
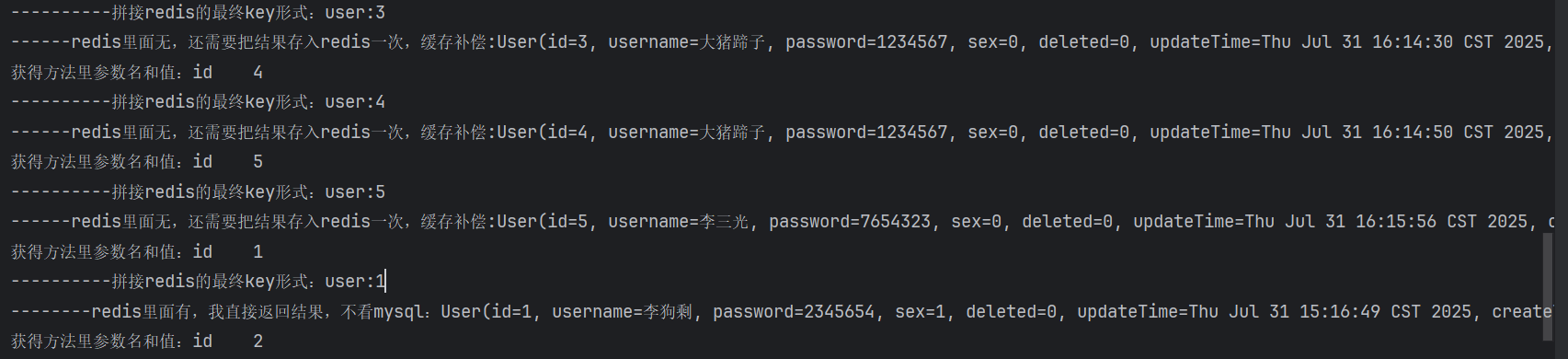
1.4 测试效果
- 第一次调用
getById(1):- Redis 中没有
user:1,切面执行userMapper.selectById(1); - 数据库查询成功后,回写
user:1到 Redis。
- Redis 中没有
- 第二次调用
getById(1):- Redis 中命中
user:1,直接返回结果,不查数据库。
- Redis 中命中
完美实现 “缓存自动生效”,业务代码极其简洁!
2、实战二:升级AOP,整合分布式锁防止缓存击穿
基础版缓存有个问题:当缓存key过期时,如果大量请求同时进来,会同时查数据库(即缓存击穿),压垮数据库。解决办法是加分布式锁—— 让只有一个请求能查数据库,其他请求等待锁释放后查缓存。
我们基于第一个案例升级,用 AOP 实现 “缓存 + 分布式锁” 的整合,核心思路是:在 “查缓存未命中” 后,先抢锁,抢到锁的查数据库,没抢到的自旋等待。
2.1 核心升级点
- 新增注解
@LockCache(支持更多配置,如缓存过期时间); - 切面中整合 Redisson 分布式锁(比原生 Redis 锁更安全,支持自动续期、可重入);
- 处理 “缓存穿透”:数据库查不到时,存入一个空值到缓存(避免每次都查库)。
2.2 代码实现
2.2.1 步骤1:定义增强注解@LockCache
新增缓存过期时间参数,让注解更灵活。
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface LockCache {
// 缓存键前缀(默认"cache")
String prefix() default "cache";
// 缓存过期时间(默认30分钟)
long timeout() default 1800;
// 时间单位(默认秒)
TimeUnit timeUnit() default TimeUnit.SECONDS;
// 空值缓存时间(防穿透,默认5分钟)
long nullTimeout() default 300;
}
2.2.2 步骤2:编写“缓存+分布式锁”切面
整合Redisson,核心逻辑是“缓存未命中 -> 抢锁 -> 抢到锁查数据库,回写进缓存 -> 释放锁”。
@Aspect
@Component
public class LockCacheAspect {
@Autowired
private RedisTemplate redisTemplate;
// 注入Redisson客户端(需提前配置Redisson)
@Autowired
private RedissonClient redissonClient;
// 环绕通知:整合缓存+分布式锁
@SneakyThrows
@Around("@annotation(com.atguigu.tingshu.common.cache.LockCache)")
public Object cacheWithLock(ProceedingJoinPoint joinPoint) {
Object result = null;
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
LockCache cacheAnnotation = signature.getMethod().getAnnotation(LockCache.class);
// 1. 解析注解参数
String prefix = cacheAnnotation.prefix();
long timeout = cacheAnnotation.timeout();
TimeUnit timeUnit = cacheAnnotation.timeUnit();
long nullTimeout = cacheAnnotation.nullTimeout();
// 2. 拼接缓存键(用方法参数列表作为动态值,适配多参数场景)
Object[] args = joinPoint.getArgs();
String cacheKey = prefix + ":" + Arrays.asList(args).toString();
String lockKey = cacheKey + ":lock"; // 分布式锁的key(与缓存键绑定)
try {
// 3. 先查缓存:命中则返回
result = redisTemplate.opsForValue().get(cacheKey);
if (result != null) {
// 处理空值缓存(如果是之前存入的空对象,返回null)
if (result instanceof JSONObject && ((JSONObject) result).isEmpty()) {
return null;
}
return result;
}
// 4. 缓存未命中(得查数据库了):抢分布式锁
RLock lock = redissonClient.getLock(lockKey);
// 尝试抢锁:最多等3秒,抢到后锁自动释放时间为10秒(防死锁)
boolean isLockSuccess = lock.tryLock(3, 10, TimeUnit.SECONDS);
if (isLockSuccess) {
try {
// 5. 抢到锁:执行目标方法(查数据库)
result = joinPoint.proceed();
// 6. 处理查询结果:分“有值”和“空值”回写缓存
if (result != null) {
// 有值:按正常过期时间存缓存
redisTemplate.opsForValue().set(cacheKey, result, timeout, timeUnit);
} else {
// 空值:按短过期时间存缓存(防穿透)
redisTemplate.opsForValue().set(cacheKey, new JSONObject(), nullTimeout, timeUnit);
}
} finally {
// 7. 释放锁(必须在finally中,防止方法异常导致锁不释放)
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
} else {
// 8. 没抢到锁:自旋等待(递归调用自己,直到抢到锁或查到缓存)
Thread.sleep(100); // 休眠100ms再试,减少CPU占用
return cacheWithLock(joinPoint);
}
} catch (Throwable e) {
log.error("缓存+分布式锁处理异常", e);
// 异常时直接查数据库(降级策略,保证业务可用)
return joinPoint.proceed();
}
return result;
}
}
2.2.3 步骤3:业务中使用增强注解
贴注解即可自动实现“缓存+分布式锁”:
@Service
public class AlbumInfoServiceImpl implements AlbumInfoService {
@Resource
private AlbumInfoMapper albumInfoMapper;
// 贴注解:前缀是"album:stat",缓存1小时,空值缓存5分钟
//prefix和Timeout是我们自定义注解@LockCache的属性参数,如果不填会隐式设置为默认值
@Override
@LockCache(prefix = RedisConstant.ALBUM_STAT_PREFIX, timeout = 3600)
public AlbumStatVo getAlbumStatVoByAlbumId(Long albumId) {
// 核心业务逻辑:只查数据库,缓存+锁由切面处理
return albumInfoMapper.selectAlbumStat(albumId);
}
}
升级后的优势:
· 防缓存击穿:只有一个请求能查数据库,其他请求等待锁释放后查缓存;
· 防缓存穿透:数据库查不到时,存入空值到缓存(短过期),避免重复查库;
· 锁安全:用 Redisson 锁,支持自动续期、可重入。
3、实战三:AOP 整合链路追踪与日志脱敏,解决 “日志Bug难找 + 敏感信息泄露”
前两个案例用 AOP 解决了 “缓存重复逻辑”,但实际开发中还有个高频痛点:每次接口调试时,日志分散在大量请求中(比如 100 个并发请求,分不清哪条日志对应哪个用户的请求);
同时,请求参数 / 返回值中的密码、手机号等敏感信息,会直接打印到日志,存在安全风险。
这些 “日志追踪”和“敏感脱敏” 逻辑,同样是与业务无关的通用型附加代码—— 如果每个 Controller 方法都写 “生成 traceId→打印日志→脱敏参数”,会导致代码臃肿且易遗漏。
此时 AOP 再次派上用场:我们可以把 “traceId 生成、日志打印、敏感脱敏” 抽成切面,通过自定义注解控制脱敏范围,让业务代码只关注 “查数据 / 返回结果”,无需关心日志细节。
3.1 需求拆解
· 全链路追踪:每个请求生成唯一traceId,串联 “请求入口→Controller→日志输出→返回值”,前端拿到traceId后,后端能快速定位对应日志;
· 敏感信息脱敏:通过注解标记 “不打印的参数 / 返回值”(如密码参数不记录、用户信息返回值不打印);
· 自动增强返回值:所有接口返回值自动附加traceId,无需手动 set;
· 线程安全:traceId需绑定当前请求线程,避免多线程串号。
3.2 实现步骤:注解 + AOP+ThreadLocal 三配合
3.2.1 步骤 1:定义脱敏注解 @NoLogAnnotation(标记 “无需日志的目标”)
和前两个案例的注解逻辑一致:用注解作为 “切面触发标识”,控制 “哪些参数 / 方法不打印日志”,代码如下:
// 可标记在方法(不打印返回值)或参数(不打印该参数)上
@Target({ElementType.METHOD, ElementType.PARAMETER})
// 运行时生效(AOP需动态解析)
@Retention(RetentionPolicy.RUNTIME)
public @interface NoLogAnnotation {
// 无额外参数,仅作为“标记符”
}
3.2.2 步骤 2:编写核心切面(日志处理 + 返回值增强)
需两个切面分工:ControllerLogAspect负责 “日志打印 + 参数脱敏”,ResultTraceIdAspect负责 “返回值注入 traceId”,确保职责单一。
① 切面 1:ControllerLogAspect(日志打印 + 敏感脱敏)
拦截所有 Controller 方法,实现 “打印类名方法名→过滤敏感参数→打印返回值” 逻辑:
@Order(Ordered.HIGHEST_PRECEDENCE) // 优先级最高,确保日志先打印
@Aspect
@Component
@Slf4j
public class ControllerLogAspect {
// 切点:所有Controller的方法
@Pointcut("execution(* com.zzyy..*Controller.*(..))")
public void logPointCut() {}
// 环绕通知:控制日志打印全流程
@Around("logPointCut()")
public Object doLog(ProceedingJoinPoint joinPoint) throws Throwable {
Object result = null;
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
try {
// 1. 打印“类名+方法名”(定位请求归属)
log.info("【traceId:{}】接口方法:{}.{}",
TraceThreadLocal.getTraceId(), // 从ThreadLocal拿当前请求的traceId
signature.getDeclaringTypeName(),
signature.getName());
// 2. 过滤敏感参数后打印(带@NoLogAnnotation的参数不打印)
Map<String, Object> safeParams = this.getSafeParams(signature, joinPoint.getArgs());
log.info("【traceId:{}】方法参数:{}",
TraceThreadLocal.getTraceId(),
JSONUtil.toJsonStr(safeParams));
// 3. 执行目标方法(如Controller的getById)
result = joinPoint.proceed();
return result;
} finally {
// 4. 过滤敏感返回值后打印(方法带@NoLogAnnotation则不打印)
if (this.needPrintResult(signature)) {
log.info("【traceId:{}】方法返回值:{}",
TraceThreadLocal.getTraceId(),
JSONUtil.toJsonStr(result));
}
}
}
// 辅助方法1:过滤敏感参数(带@NoLogAnnotation的参数不加入日志)
private Map<String, Object> getSafeParams(MethodSignature signature, Object[] args) {
Map<String, Object> params = new LinkedHashMap<>();
String[] paramNames = signature.getParameterNames();
for (int i = 0; i < args.length; i++) {
// 跳过带@NoLogAnnotation的参数
if (signature.getMethod().getParameterAnnotations()[i].length > 0
&& signature.getMethod().getParameterAnnotations()[i][0] instanceof NoLogAnnotation) {
params.put(paramNames[i], "***(敏感参数,已脱敏)");
continue;
}
// 跳过ServletRequest/ServletResponse等无意义参数
if (args[i] instanceof ServletRequest || args[i] instanceof ServletResponse) {
continue;
}
params.put(paramNames[i], args[i]);
}
return params;
}
// 辅助方法2:判断返回值是否需要打印(方法带@NoLogAnnotation则不打印)
private boolean needPrintResult(MethodSignature signature) {
return signature.getMethod().getAnnotation(NoLogAnnotation.class) == null;
}
}
① 切面 2:ResultTraceIdAspect(返回值注入 traceId)
所有返回值(包括异常场景)自动附加traceId,前端直接获取:
@Aspect
@Component
public class ResultTraceIdAspect {
// 切点:Controller方法 + 全局异常处理器(确保异常返回也带traceId)
@Pointcut("execution(* com.zzyy..*Controller.*(..)) || " +
"execution(* com.zzyy..*GlobalExceptionHandler.*(..))")
public void resultPointCut() {}
@Around("resultPointCut()")
public Object fillTraceId(ProceedingJoinPoint joinPoint) throws Throwable {
Object result = joinPoint.proceed();
// 若返回值是统一封装的ResultData,注入traceId
if (result instanceof ResultData) {
((ResultData<?>) result).setTraceId(TraceThreadLocal.getTraceId());
}
return result;
}
}
3.2.3 步骤 3:ThreadLocal+Filter 保障 traceId 线程安全
traceId需要 “请求入口生成→线程内传递→请求结束清理”,用ThreadLocal存储(避免多线程串号),Filter控制生命周期:
① TraceThreadLocal(线程级存储 traceId):
public class TraceThreadLocal {
private static final ThreadLocal<String> TRACE_ID_HOLDER = new ThreadLocal<>();
public static final String TRACE_ID_KEY = "traceId";
// 设置traceId,并同步到MDC(日志模板可直接引用)
public static void setTraceId(String traceId) {
TRACE_ID_HOLDER.set(traceId);
MDC.put(TRACE_ID_KEY, traceId); // 配合logback.xml,日志自动带traceId
}
// 获取当前线程的traceId
public static String getTraceId() {
return TRACE_ID_HOLDER.get();
}
// 请求结束清理,避免内存泄漏
public static void removeTraceId() {
TRACE_ID_HOLDER.remove();
MDC.remove(TRACE_ID_KEY);
}
}
② TraceFilter(请求入口生成 traceId)
@Order(Ordered.HIGHEST_PRECEDENCE) // 比AOP更早执行,确保traceId先生成
@WebFilter(urlPatterns = "/**", filterName = "TraceFilter")
@Slf4j
public class TraceFilter extends OncePerRequestFilter {
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain chain) throws IOException, ServletException {
try {
// 1. 生成唯一traceId(UUID)
String traceId = IdUtil.fastSimpleUUID();
// 2. 绑定到当前线程
TraceThreadLocal.setTraceId(traceId);
log.info("【traceId:{}】请求开始:{}", traceId, request.getRequestURL());
long startTime = System.currentTimeMillis();
chain.doFilter(request, response); // 放行请求
// 3. 打印请求耗时
log.info("【traceId:{}】请求结束,耗时:{}ms", traceId, System.currentTimeMillis() - startTime);
} finally {
// 4. 清理traceId(必须在finally,避免异常导致内存泄漏)
TraceThreadLocal.removeTraceId();
}
}
}
3.2.4 步骤 4:日志模板配置(logback.xml)
让所有日志自动带上traceId,无需手动拼接:
<configuration>
<!-- 日志格式:强制包含traceId(从MDC中取) -->
<property name="LOG_PATTERN" value="%d{yyyy-MM-dd HH:mm:ss} [traceId:%X{traceId}] - %msg%n"/>
<!-- 控制台输出 -->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder><pattern>${LOG_PATTERN}</pattern></encoder>
</appender>
<!-- 文件输出(按时间滚动) -->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>D:/logs/app.log</file>
<encoder><pattern>${LOG_PATTERN}</pattern></encoder>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>D:/logs/app-%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>30</maxHistory> <!-- 保留30天日志 -->
</rollingPolicy>
</appender>
<root level="info">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="FILE"/>
</root>
</configuration>
3.3 业务中使用:注解贴一贴,功能全生效
和前两个案例一样,业务代码只需贴注解,无需关心日志逻辑:
@RestController
public class UserController {
@Resource
private UserService userService;
// 1. 正常场景:打印参数+返回值,返回值带traceId
@GetMapping("/user/get/{id}")
public ResultData<User> getById(@PathVariable Integer id) {
return ResultData.success(userService.getById(id));
}
// 2. 脱敏返回值:方法带@NoLogAnnotation,不打印返回值(避免User的password泄露)
@GetMapping("/user/getv2/{id}")
@NoLogAnnotation
public ResultData<User> getByIdV2(@PathVariable Integer id) {
return ResultData.success(userService.getById(id));
}
// 3. 脱敏参数:参数带@NoLogAnnotation,不打印id(假设id是敏感信息)
@GetMapping("/user/getv3/{id}")
public ResultData<User> getByIdV3(@NoLogAnnotation @PathVariable Integer id) {
return ResultData.success(userService.getById(id));
}
}
3.4 测试效果:日志可追踪,敏感信息安全
3.4.1 请求/user/get/1:
日志自动带traceId,参数和返回值完整打印:
2025-10-12 10:00:00 [traceId:1a2b3c] - 【traceId:1a2b3c】请求开始:http://localhost:8080/user/get/1
2025-10-12 10:00:00 [traceId:1a2b3c] - 【traceId:1a2b3c】接口方法:com.zzyy.study.controller.UserController.getById
2025-10-12 10:00:00 [traceId:1a2b3c] - 【traceId:1a2b3c】方法参数:{"id":1}
2025-10-12 10:00:00 [traceId:1a2b3c] - 【traceId:1a2b3c】方法返回值:{"code":200,"msg":"success","data":{"id":1,"username":"zhangsan","password":"123456"...},"traceId":"1a2b3c"}
2025-10-12 10:00:00 [traceId:1a2b3c] - 【traceId:1a2b3c】请求结束,耗时:50ms
3.4.2 请求/user/getv3/2:
参数id带@NoLogAnnotation,日志脱敏显示:
2025-10-12 10:01:00 [traceId:4d5e6f] - 【traceId:4d5e6f】方法参数:{"id":"***(敏感参数,已脱敏)"}
四、知识点总结
1、使用Redis和Redis分布式锁的意义:都在于保护脆弱的数据库;Redis 缓存负责 “日常拦截”,减少 90%+ 的数据库请求,是 “长期防护”;Redis 分布式锁负责 “特殊情况兜底”,解决缓存过期 / 穿透时的瞬时高并发,是 “应急防护”。
2、AOP的核心思想:通用内容抽离成独立切面,通过注解形式有选择性地插入业务方法里。
3、AOP的核心价值:通用逻辑 “一次编写,到处使用”。无论是 “缓存查询”“分布式锁” 还是 “日志追踪”,只要是 “与业务无关、重复出现” 的逻辑,都可以用 AOP 抽成切面。比如:
- 缓存逻辑:切面控制 “查缓存→查 DB→回写缓存”;
- 锁逻辑:切面控制 “抢锁→执行方法→释放锁”;
- 日志逻辑:切面控制 “生成 traceId→打印日志→脱敏敏感信息”;
业务代码只需贴注解,实现 “注解即功能” 的简洁性。
4、AOP的使用步骤:定义注解 -> 定义切面类 -> 在需要插入该切面类的业务方法上添加注解。
5、AOP+ThreadLocal:解决 “线程安全的上下文传递”。新插件中,traceId通过ThreadLocal绑定当前请求线程,避免多线程串号;同时结合Filter控制traceId的 “生成→清理” 生命周期,防止内存泄漏。这种 “Filter 初始化上下文→AOP 使用上下文→finally 清理” 的模式,可复用在 “用户登录态传递”“请求耗时统计” 等场景。
6、MDC:日志上下文传递的 “利器”。SLF4J 的 MDC(Mapped Diagnostic Context)可将traceId等上下文信息 “隐式” 传入日志模板,无需在每个log.info()中手动拼接traceId,只需在logback.xml配置%X{traceId},所有日志自动带上上下文,极大简化日志编写。
7、注解精准控制切面范围:自定义注解不仅是 “切面触发标识”,还能实现 “精细化控制”:
- @MyRedisCache:通过keyPrefix控制缓存键前缀;
- @LockCache:通过timeout控制缓存过期时间;
- @NoLogAnnotation:通过 “标记方法 / 参数” 控制脱敏范围;
这种 “注解参数 + 切面解析” 的模式,让 AOP 逻辑更灵活,适配不同业务场景。


















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









