






DAG有向无环图
倒推
故推导程序的执行计划时,先看代码有几个action算子,从action倒推
一个action会产生一个JOB(DAG)(即一个应用程序内的子任务) 一个action=一个Job=一个DAG
一个application里面可以有多个action组成
带有分区的DAG只有在运行的时候才会生成,因为像指定并行度的逻辑,只有运行的时候才知道你传入的参数是多少
DAG的宽窄依赖
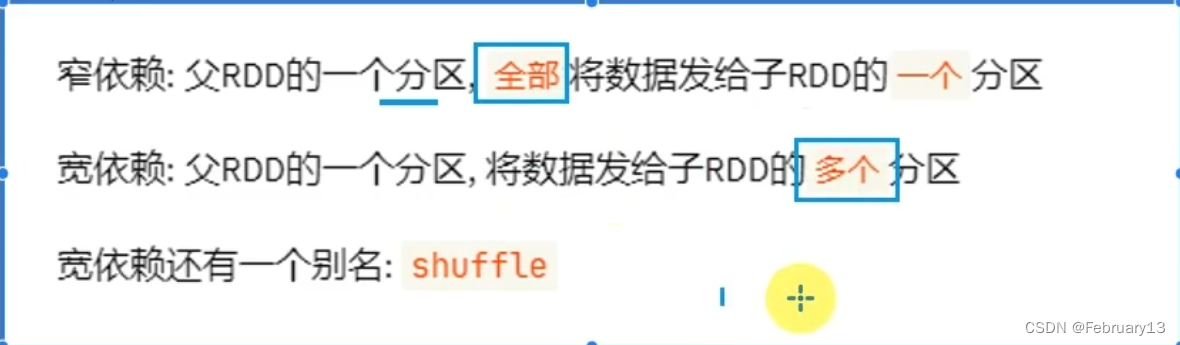
窄依赖的内涵是 父RDD全部转换成一个子RDD
看是否是宽依赖:看父RDD的箭头是否分叉
窄依赖:规整的内存迭代计算管道(pip line)执行(就是一个个具体的task),一个线程对应一个窄依赖,线程间互不影响
任务泡在一个线程内就是内存计算
spark优先考虑并行度,再考虑内存计算管道

dag的作用是使用内存计算,stage的作用是构建内存计算
前后RDD分区数不一样,必然引起shuffle,故尽量不改并行度,遵循全局并行度设置
不要轻易修改分区数
面试题:spark为什么比mr块?
1.spark算子多,可以一个程序搞定复杂任务,而mr是多个mr任务拼接才能实现。
2.spark通过stage可以走内存计算,而mr任务间走的磁盘IO,效率低
spark并行度:
是因为并行度,才有的分区数
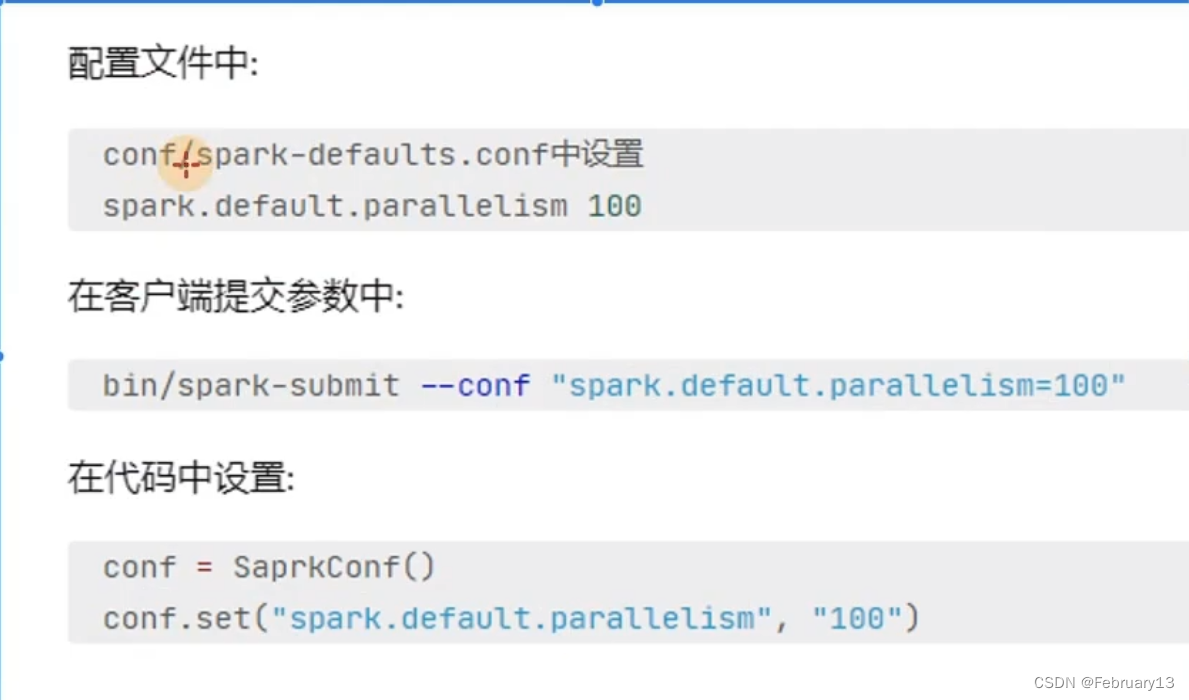
手动设置并行度: repartition、coalesce、partitionBy
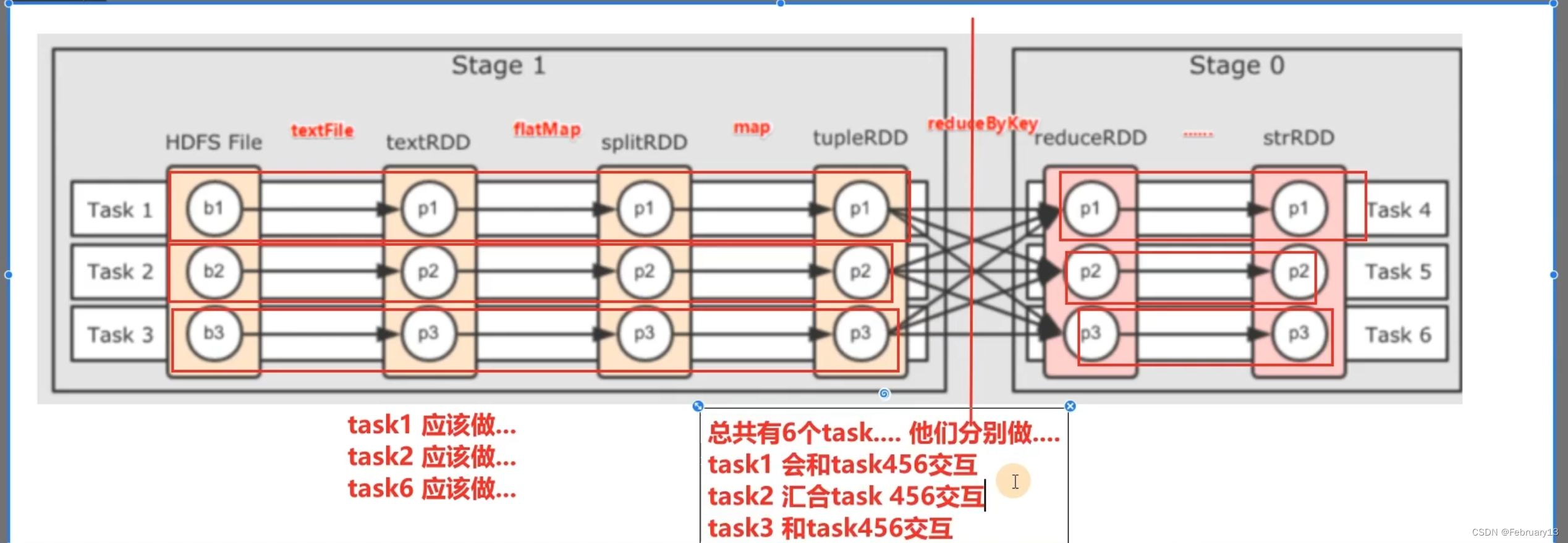
rDD在横向上一个task可以处理多个RDD一个分区,竖向上每个分区都需要有一个task去处理
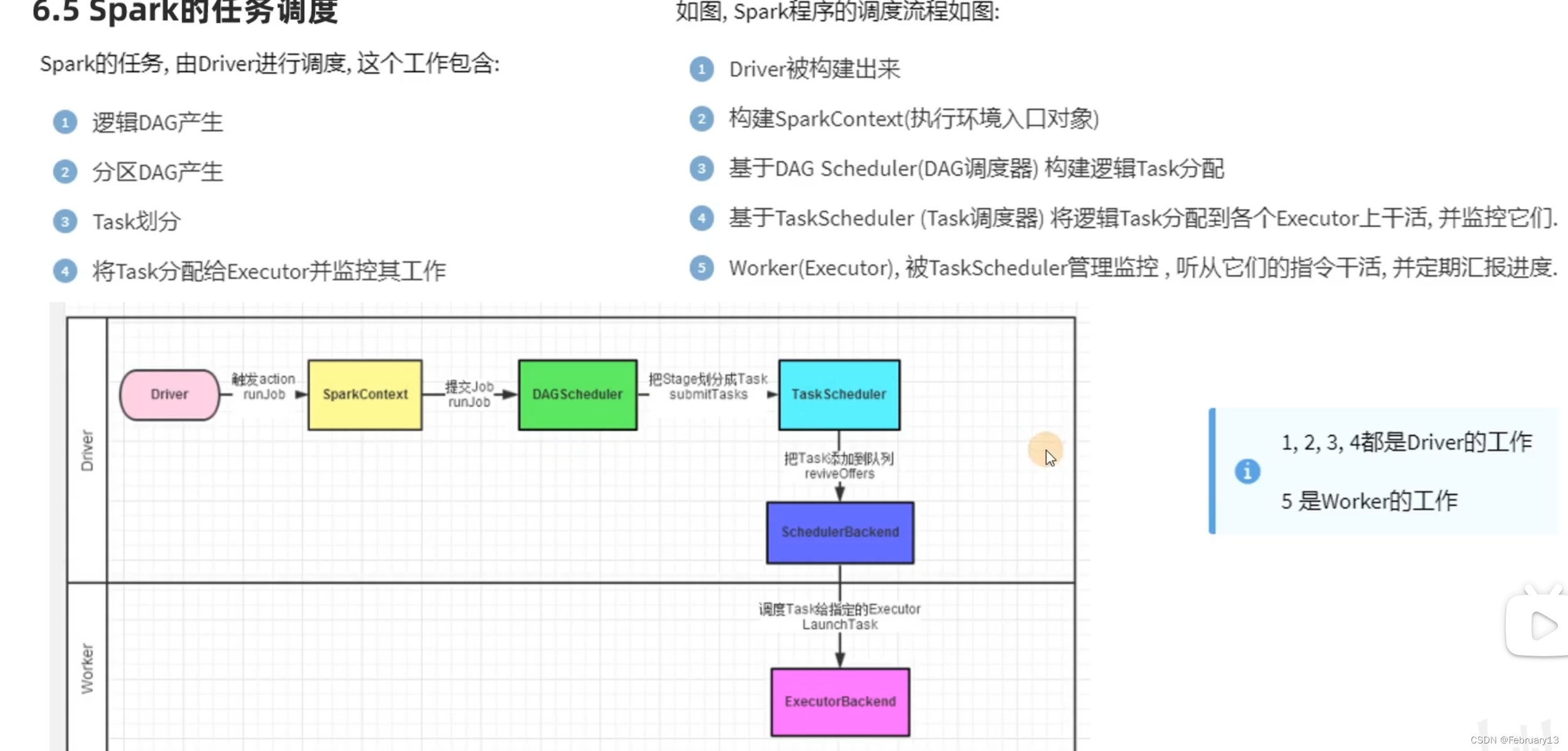
executor之间通信(进程间通信)进程间通信无法通过内存进行
不同主机通信需要网络,RPC
同主机通信,经过内核,也是网络,本地回环网络 127.0.0.1
各进程拥有的内存地址空间相互独立
一个进程不能直接访问另一个进程的地址空间

















 1943
1943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









