



 本文深入解析Keras框架,介绍其简洁高效的特点,强调Keras在深度学习模型快速实验与开发中的重要角色。文章涵盖了Keras的基本概念、关键特性、架构、工作流程以及模型的编译和训练方法。
本文深入解析Keras框架,介绍其简洁高效的特点,强调Keras在深度学习模型快速实验与开发中的重要角色。文章涵盖了Keras的基本概念、关键特性、架构、工作流程以及模型的编译和训练方法。
Keras基本概念
Keras —— 简洁高效的深度神经网络工具
Keras 是一个python深度学习框架,可以方便定义和训练几乎所有类型的深度学习模型
Keras 最开始是为研究人员 开发的,目的是为了能够快速实验
Keras 的重要特性
- 相同 的代码可以在CPU 和 GPU上无缝的切换运行
- 具有友好的api ,便于快速开发深度学习模型的原理
- 内置支持卷积网络(用于机器视觉),循环网络(用于序列处理) 以及二者的任意组合
- 支持任意架构网络,多输入或者多层输出模型,层共享,模型共享,也就是说,Keras能构建任意深度学习模型
- Keras 基于宽松的MIT许可认证办法,在商业项目中可以免费使用,并且所有python版本都兼容
Keras 架构
Keras是一个模型级(model—level)的库,为开发深度学习模块提供了高层次的构建模型。
Keras是依赖于一个专门的,高度优化的张量库来完成运算,这个张量库就是Keras的后端引擎。目前Keras有三个后端实现: Tensorflow,Theano ,和微软认知工具包
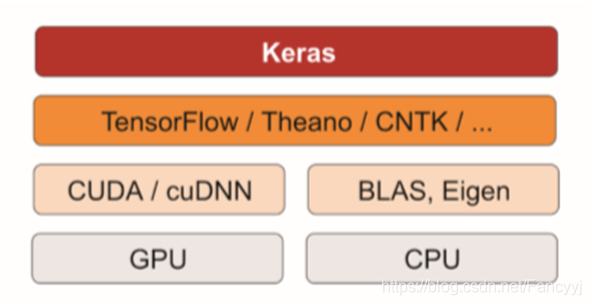
Keras工作流
(1)定义训练数据: 输入张量和目标张量
(2)定义层组成的网络(或者模型),将输入映射到目标
(3)配置学习过程:选择损失函数,优化器和需要监控的指标
(4)调用模型的fit方法在训练数据上进行迭代
定义模型的方法:
(1)使用Sequential类(仅用于层的线性堆叠,这是目前最常见的网络构架)

(2)函数式API 用于层组成的 有向无环图,可以构建任意形式的架构

Keras的编译和训练
Keras的编译: 编译也就是配置学习过程,可以指定模型使用的优化器和损失函数以及训练过程中想要监控的指标

Keras的训练:
通过fit() 方法将输入数据的numpy数组(和对应的目标数据)传入模型,这个做法和Stick—learn 及其他机器学习库类似


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









