



文章目录
前言
一、zookeeper服务
1.1 zookeeper的概念
ZooKeeper 是 Apache 基金会旗下的一款分布式协调服务,专为分布式系统提供一致性、可靠性的核心支撑能力。它常用于分布式锁、配置管理、服务注册与发现、集群选举等场景,是 Hadoop、HBase、Kafka 等大数据框架的核心依赖组件,专门为分布式应用提供高效可靠的协调、同步、配置管理和故障恢复等功能。它的设计目的是简化分布式系统的管理,保证多个节点之间的数据一致性和协调工作。Zookeeper 提供了类似文件系统的层次化命名空间,用来存储和管理元数据,确保分布式应用的高可用性和强一致性。
1.2 Zookeeper 数据结构
Zookeeper 的数据结构类似于一个层次化的文件系统。
ZNode:是 Zookeeper 中存储数据的基本单元,每个 ZNode 都可以存储少量的数据,并且可以有子节点,形成树状结构。
持久节点:该类型的 ZNode 会一直存在,直到手动删除。
临时节点:客户端会话断开时,临时节点会自动删除,适用于实现分布式锁等功能。
顺序节点:在创建 ZNode 时,Zookeeper 可以自动为其添加递增的编号,常用于实现分布式队列或顺序任务处理。
1.3 Zookeeper 应用场景
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
统一命名服务
在分布式环境下,经常需要对应用/服务进行统一命名,便于识别。例如:IP不容易记住,而域名容易记住。
1、统一配置管理
(1)分布式环境下,配置文件同步非常常见。一般要求一个集群中,所有节点的配置信息是一致的,比如Kafka集群。对配置文件修改后,希望能够快速同步到各个节点上。
(2)配置管理可交由ZooKeeper实现。可将配置信息写入ZooKeeper上的一个Znode。各个客户端服务器监听这个Znode。一旦 Znode中的数据被修改,ZooKeeper将通知各个客户端服务器。
2、统一集群管理
(1)分布式环境中,实时掌握每个节点的状态是必要的。可根据节点实时状态做出一些调整。
(2)ZooKeeper可以实现实时监控节点状态变化。可将节点信息写入ZooKeeper上的一个ZNode。监听这个ZNode可获取它的实时状态变化。
3、服务器动态上下线
客户端能实时洞察到服务器上下线的变化。
4、软负载均衡
在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请求。
1.4 zookeeper原理
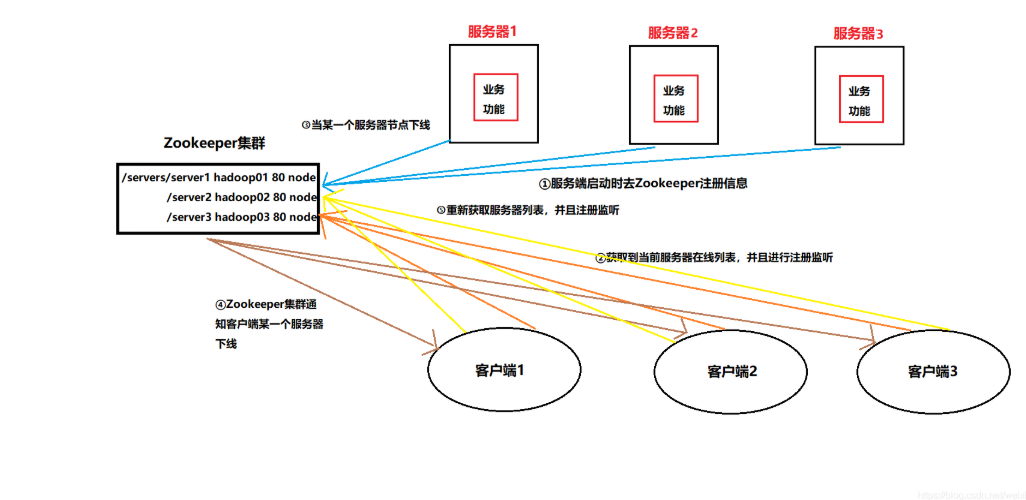
简单来说:zookeeper不仅可以存储文件数据也可以实时监控数据的变化并通知,如果数据发生改变,zookeeper就会发送数据改变通知给已经在zookeeper上注册了的用户。
1.5 Zookeeper 选举机制
1.5.1 第一次启动选举机制
票数过半者当选leader,过程中没有出现leader,则先前投票的节点可以继续进行投票,出现票数过半的情况则,先前投票的节点不可以继续更改投票对象(也就是投票固定)
投票规则:谁myid高投给谁,且每个节点第一次投票会投给自己。
投过一次票代表进行了一次事务。
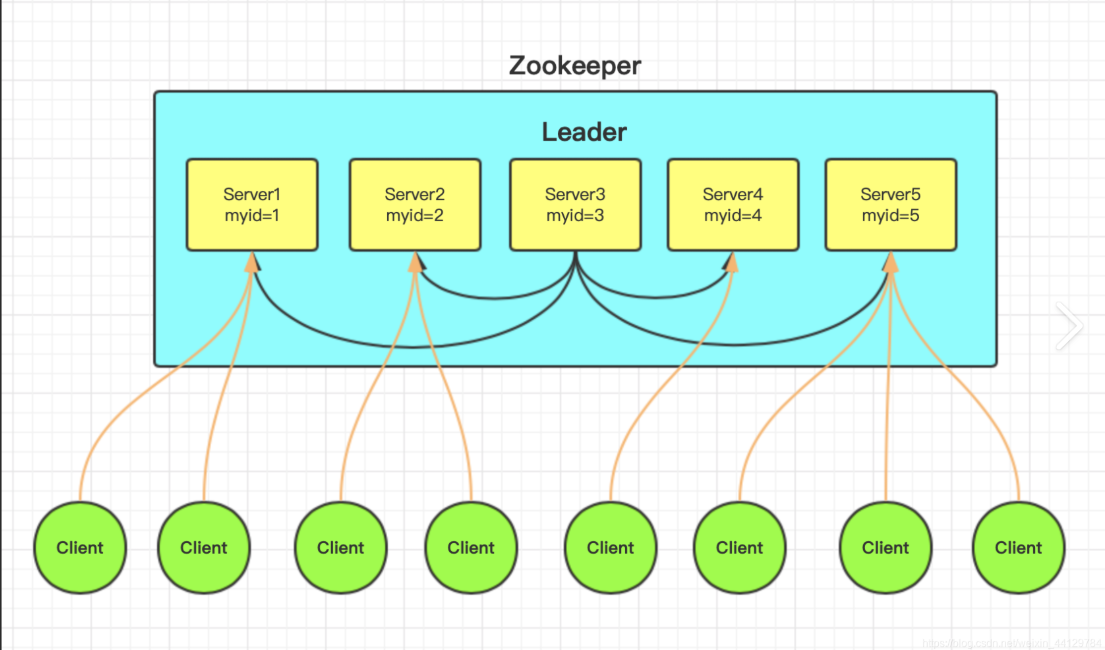
轮流竞选(一个一个上台竞选)大致流程为:班级竞选班长,myid就比喻成人气值,一号选手先来投票并且投给自己,此时,1号选手票数为1没有过半,因此下一次投票还可以投,第二个选手来投票也投给自己,1号选手发现自己人气值没有2号选手高,因此1号选手也投2号,此时2号选手获得两票,投票数没过半,因此1、2号选手下次还要投票,三号选手进行投票并且投给自己,1、2号选手发现3号选手的人气值比自己高,所以也把票投给3号,此时3号获得3票,票数过半,1、2、3号选手不能更改投票,四号选手进行投票并且投给自己,虽然人气比3号高,但是票数只有1票,三号选手有3票,因此竞选失败,并且下次投票会把票投给3号,五号选手进行选举并把票投给自己,只有1票,3号有4票,因此3号最终成为leader。
同时竞选(全部选手站在台上,同时进行投票)大致流程为:班级竞选班长,myid比喻为人气值,五位选手会将票投给人气值最高的选手,因此五号选手当选leader。
1.5.2 非第一次启动选举机制
当ZooKeeper 集群中的一台服务器出现以下两种情况之一时,就会开始进入Leader选举:
1、服务器初始化启动(重新竞选班长)
2、服务器运行期间无法和Leader保持连接(班长生病了,找其他同学当班长)
而当一台机器进入Leader选举流程时,当前集群也可能会处于以下两种状态:
1、集群中本来就已经存在一个Leader。
对于已经存在Leader的情况,机器试图去选举Leader时,会被告知当前服务器的Leader信息,对
于该机器来说,仅仅需要和 Leader机器建立连接,并进行状态同步即可。
2、集群中确实不存在Leader。
假设ZooKeeper由5台服务器组成,SID分别为1、2、3、4、5,ZXID分别为8、8、8、7、7,并
且此时SID为3的服务器是Leader。某一时刻,3和5服务器出现故障,因此开始进行Leader选举。
选举Leader规则:
① EPOCH大的直接胜出(参加一次竞选EPOCH加1)
② EPOCH相同,事务id大的胜出(每投一次票事务id加1)
③ 事务id相同,服务器id大的胜出(服务器id为myid)
举例:班级竞选班长,3号选手为旧班长,五号选手和三号选手都生病,因此只有1、2、4号选手进行竞选,因为前面1号选手进行了5次投票,2号为4次,4号为2次,因此1号选手当选,如果三者的事务id相同,则人气值高的4号当选。
二、zookeeper配置实战
2.1 配置环境
10.0.0.100 一号zookeeper
10.0.0.3 二号zookeeper
10.0.0.4 三号zookeeper
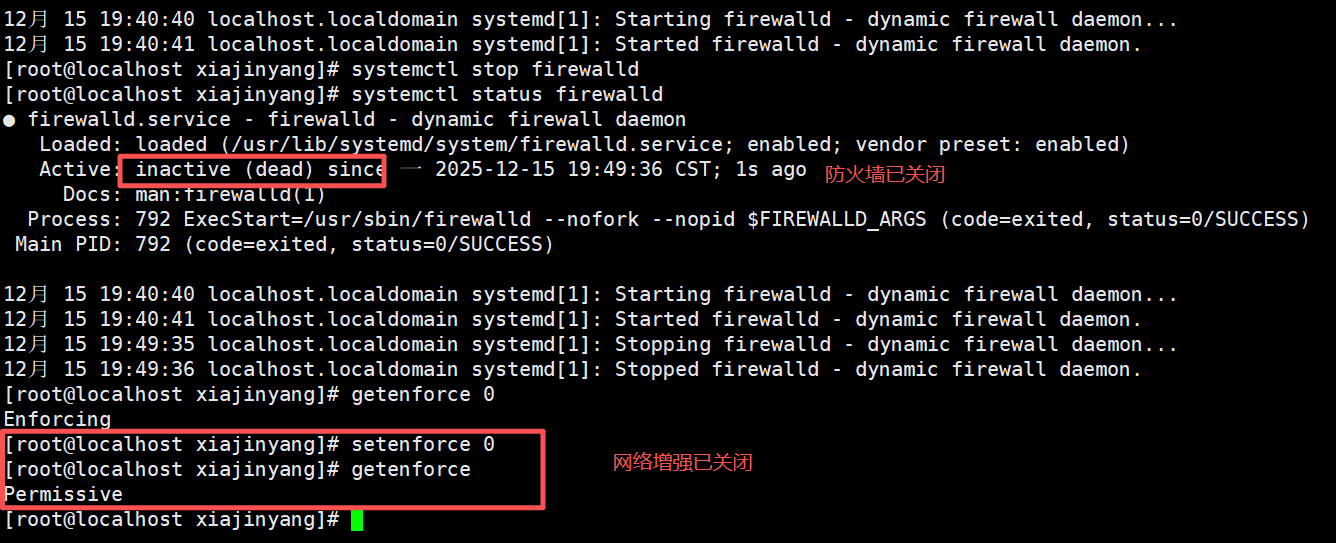
第一步 关闭防火墙和网络增强服务
systemctl stop firewalld ————————关闭防火墙
setenforce 0 ————————关闭网络增强服务
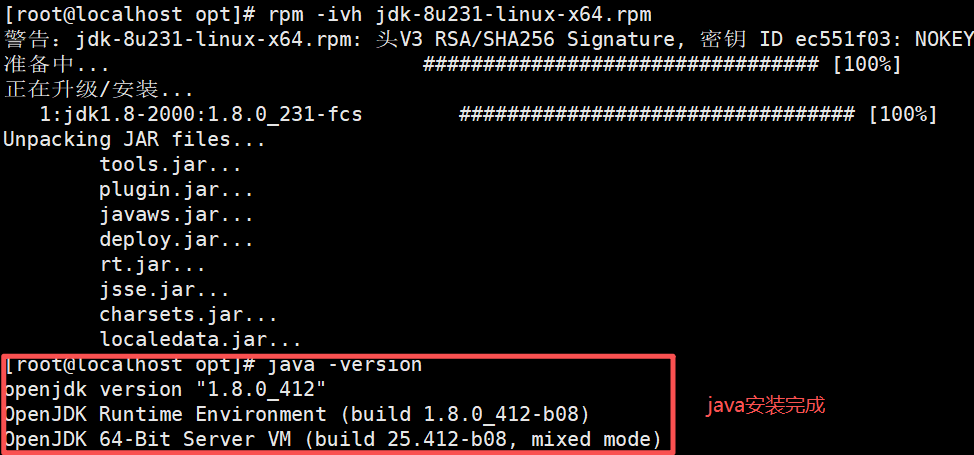
第二步 安装java环境
rpm -ivh jdk-8u231-linux-x64.rpm -C /opt ————————将java压缩到opt下
第三步 配置jdk环境变量
vim /etc/profile.d/java.sh ——————————编辑java配置文件
export JAVA_HOME=/usr/java/jdk-8u91-linux
export CLASSPATH=.:
J
A
V
A
H
O
M
E
/
l
i
b
/
t
o
o
l
s
.
j
a
r
:
JAVA_HOME/lib/tools.jar:
JAVAHOME/lib/tools.jar:JAVA_HOME/lib/dt.jar
export PATH=
J
A
V
A
H
O
M
E
/
b
i
n
:
JAVA_HOME/bin:
JAVAHOME/bin:PATH

source /etc/profile.d/java.sh ——————————刷新配置文件
2.2 安装zookeeper
tar zxvf apache-zookeeper-3.5.7-bin.tar.gz ————————解压zookeeper压缩包
mv apache-zookeeper-3.5.7-bin /usr/local/zookeeper ————————将apache-zookeeper-3.5.7-bin移动至/usr/local下并改名为zookeeper

cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg —————————复制配置文件模板

2.3 编辑zookeeper配置文件
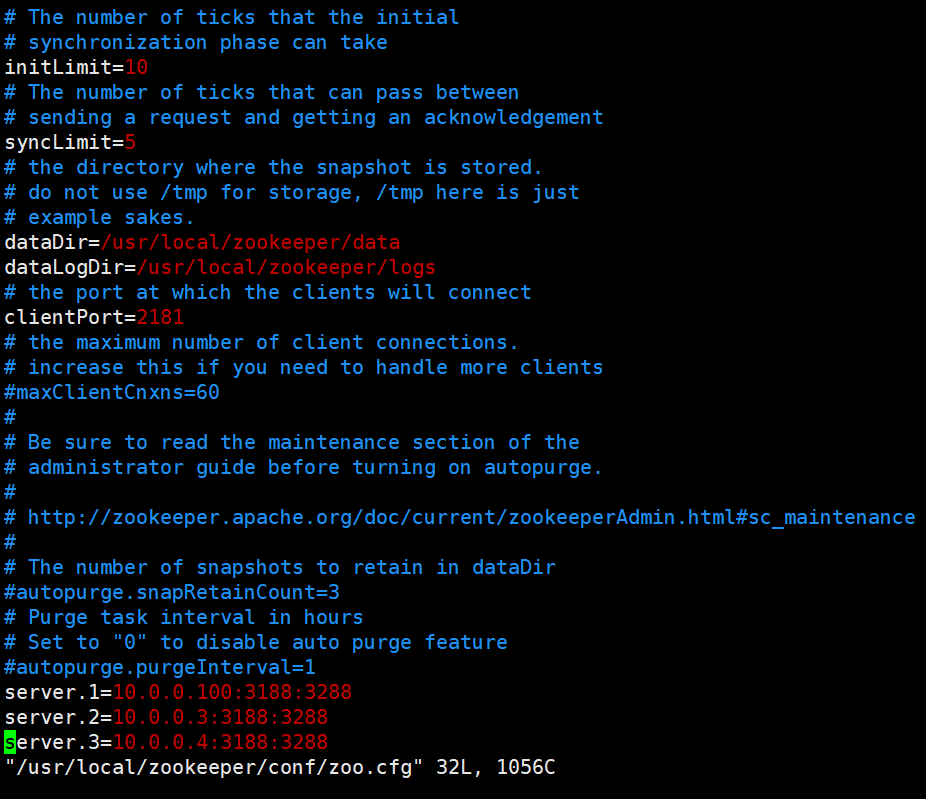
vim /usr/local/zookeeper/conf/zoo.cfg ——————————编辑zookeeper配置文件
tickTime=2000 —————————通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
initLimit=10 ——————————Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量),这里表示为10*2s
syncLimit=5 ————————Leader和Follower之间同步通信的超时时间,这里表示如果超过5*2s,Leader认为Follwer死掉,并从服务器列表中删除Follwer
dataDir=/usr/local/zookeeper-3.5.7/data ————————指定保存Zookeeper中的数据的目录,目录需要单独创建
dataLogDir=/usr/local/zookeeper-3.5.7/logs ———————指定存放日志的目录,目录需要单独创建
clientPort=2181 ——————————————客户端连接端口
在文本末尾加上添加集群信息
server.1=10.0.0.100:3188:3288
server.2=10.0.0.2:3188:3288
server.3=10.0.0.3:3188:3288
(3188代表zookeeper之间的通信端口,3288代表选举端口)
mkdir /usr/local/zookeeper/data ————————穿建存放数据日志的目录
mkdir /usr/local/zookeeper/logs ————————创建存放日志文件的目录

分别在三台服务节点上输入,定义每个节点的myid
echo 1 > /usr/local/zookeeper-3.5.7/data/myid ————————10.0.0.100的myid=1
echo 2 > /usr/local/zookeeper-3.5.7/data/myid ————————10.0.0.2的myid=2
echo 3 > /usr/local/zookeeper-3.5.7/data/myid ————————10.0.0.3的myid=3

2.4 配置启动脚本
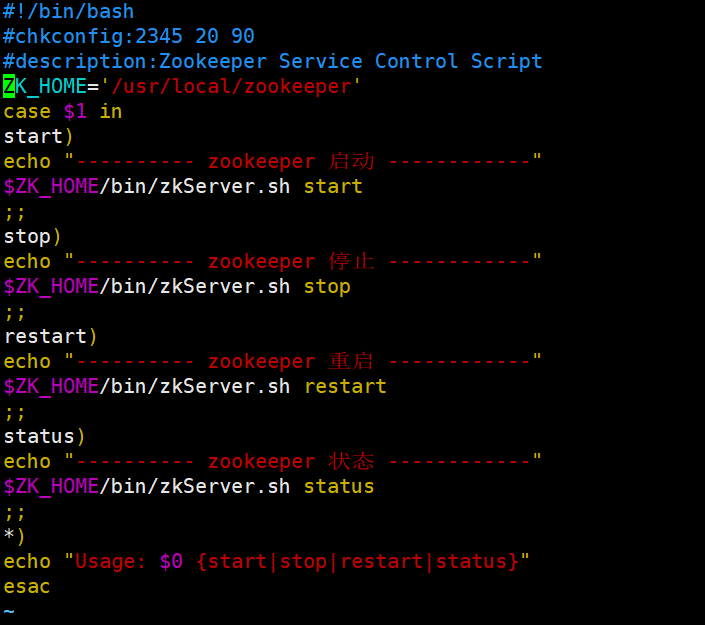
vim /etc/init.d/zookeeper ————————编辑脚本文件
#!/bin/bash
#chkconfig:2345 20 90
#description:Zookeeper Service Control Script
zk=/usr/local/zookeeper/bin
case $a in ———————————定义 $a为第一个参数,执行脚本文件时可以输入一个参数包括(satrt、stop、restart、status)
start)
echo “---------- zookeeper 启动 ------------”
$zk/zkServer.sh start
;;
stop)
echo “---------- zookeeper 停止 ------------”
$zk/zkServer.sh stop
;;
restart)
echo “---------- zookeeper 重启 ------------”
$zk/zkServer.sh restart
;;
status)
echo “---------- zookeeper 状态 ------------”
$zk/zkServer.sh status
;;
*)
echo “Usage: $0 {start|stop|restart|status}” ————————参数必须选择里面四种
esac
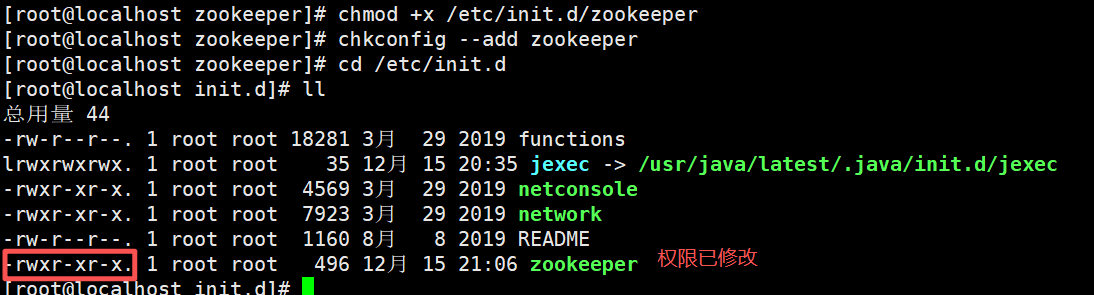
chmod +x /etc/init.d/zookeeper ————————给脚本文件添加执行权限
chkconfig --add zookeeper
service zookeeper start ——————————开启zookeeper服务
service zookeeper status ——————————查看zookeeper服务信息
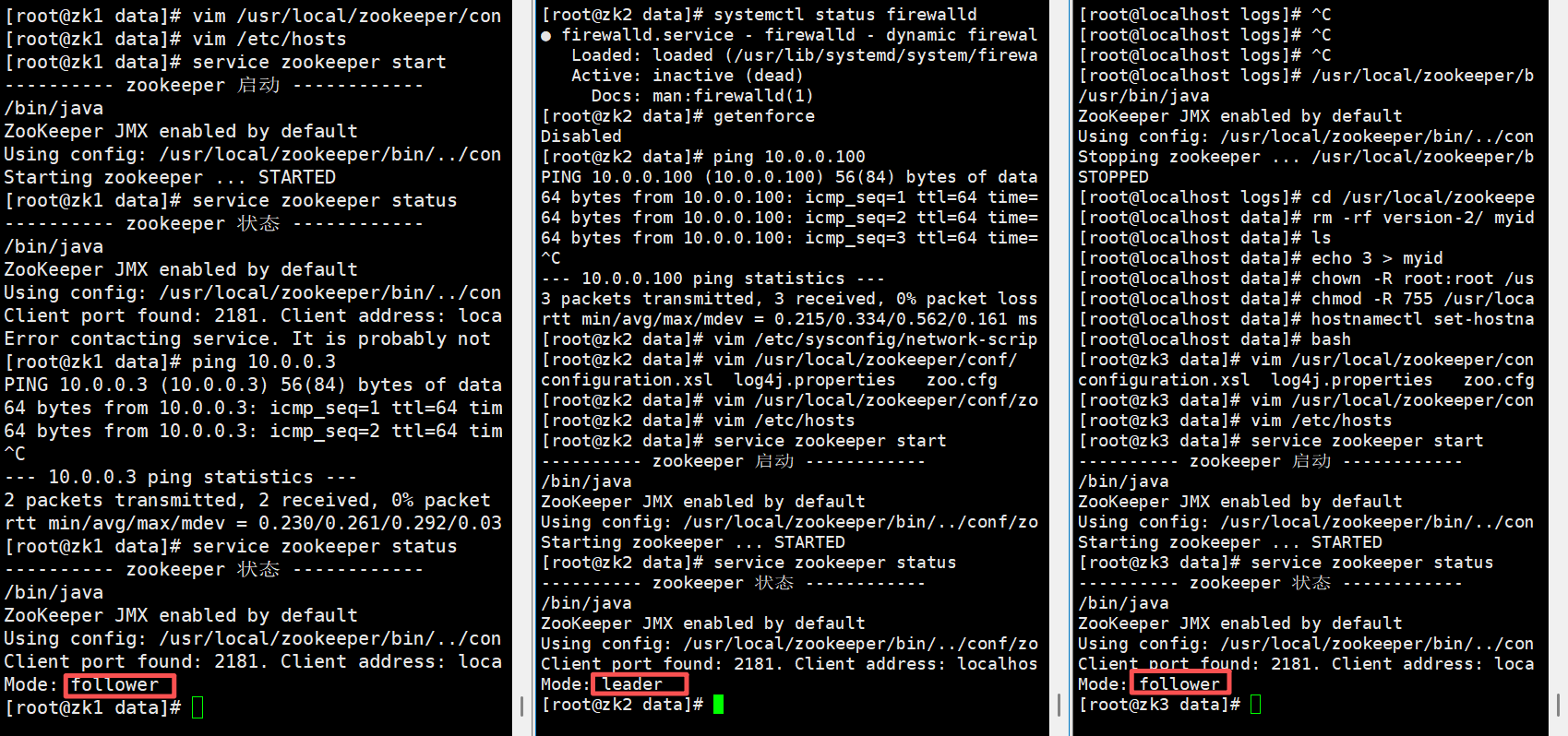
2号zk成为leader,实验成功,感兴趣的宝子们可以试试同时开启zookeeper服务,看看是不是3号节点成为leader。
总结
本文讲述了zookeeper的概念、选举原理以及配置操作,希望本文对您有所帮助,谢谢观看😜

















 1163
1163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









