



💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文内容如下:🎁🎁🎁
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥第一部分——内容介绍
面向制造业的鲁棒机器学习集成计算流程研究
摘要:本文针对制造业中多变且复杂的工业场景,提出了一种鲁棒机器学习流程选择与适配的新方法。通过引入基于贝叶斯潜空间模型(Bayesian Latent Space Model, BLSM)的加权集成机制(Weighted Ensemble - BLSM, WE - BLSM)推荐系统,将数据集与机器学习流程共同投影到共享的低维潜空间嵌入。在该框架下,流程在数据集上的性能得分被建模为随机变量,其分布由二者在潜空间中的兼容性决定。利用性能得分的后验分布,优化兼顾精度(后验均值)与波动性(后验方差)的目标函数,自动获取集成权重。通过在熔融沉积成型(FDM)、气溶胶喷射打印(AJP)以及 Tecator 数据集三个应用场景中的案例研究,验证了所提方法的有效性与鲁棒性。
关键词:制造业;鲁棒机器学习;贝叶斯潜空间模型;加权集成机制;流程选择与适配
一、引言
1.1 研究背景与意义
制造业作为国家经济的重要支柱产业,正面临着日益复杂多变的生产环境和市场需求。在智能制造的推动下,机器学习技术在制造业中的应用愈发广泛,涵盖了生产过程监控、质量控制、预测性维护等多个关键环节。然而,制造业的工业场景具有高度的多样性和不确定性,不同生产批次、设备状态、原材料特性等因素都会导致数据分布和特征发生显著变化。这使得单一的机器学习流程往往难以在不同场景下保持稳定且优异的性能,如何选择和适配鲁棒的机器学习流程成为制造业智能化升级面临的重大挑战。
1.2 国内外研究现状
目前,国内外学者在机器学习流程选择与适配方面开展了大量研究。一些研究聚焦于通过特征工程和模型选择来提高单个模型的泛化能力,但这些方法在面对极端复杂和多变的数据分布时,性能提升有限。另一部分研究尝试采用集成学习的方法,通过组合多个模型的预测结果来提高整体性能。然而,现有的集成学习方法大多基于简单的平均或投票策略,未能充分考虑不同模型在不同数据场景下的兼容性和性能波动性,导致集成效果不够理想。此外,针对制造业特定场景的鲁棒机器学习流程研究相对较少,缺乏系统性的理论和方法指导。
1.3 研究目标与内容
本文旨在提出一种适用于多变工业场景的鲁棒机器学习流程选择与适配方法,通过引入基于贝叶斯潜空间模型的加权集成机制推荐系统,实现自动、高效地选择和组合机器学习流程,以提高在制造业复杂场景下的预测精度和鲁棒性。具体研究内容包括:构建贝叶斯潜空间模型,将数据集与机器学习流程投影到共享的低维潜空间;建模流程性能得分的随机分布;优化兼顾精度与波动性的目标函数以获取集成权重;通过多个制造业应用场景的案例研究验证方法的有效性。
二、基于贝叶斯潜空间模型的加权集成机制推荐系统
2.1 贝叶斯潜空间模型构建
贝叶斯潜空间模型的核心思想是将高维的数据集特征和机器学习流程参数映射到一个低维的潜空间中,在这个共享的空间中捕捉它们之间的内在关系和兼容性。设数据集集合为 D={d1,d2,⋯,dn},机器学习流程集合为 P={p1,p2,⋯,pm}。对于每个数据集 di 和流程 pj,我们分别定义它们在潜空间中的嵌入表示为 zdi∈Rk 和 zpj∈Rk,其中 k 为潜空间的维度。
为了学习这些嵌入表示,我们假设存在一个潜在函数 f(zdi,zpj),该函数能够衡量数据集 di 和流程 pj 在潜空间中的兼容性,并且与流程 pj 在数据集 di 上的实际性能得分 sij 相关。我们采用贝叶斯框架来建模这个关系,假设性能得分 sij 服从一个以 f(zdi,zpj) 为均值的概率分布,例如正态分布 sij∼N(f(zdi,zpj),σ2),其中 σ2 为已知或需要估计的方差参数。
通过最大化所有观测到的性能得分的联合后验概率,我们可以学习到数据集和流程在潜空间中的最优嵌入表示以及潜在函数 f 的参数。具体来说,联合后验概率可以表示为:

2.2 流程性能得分的随机分布建模
在得到数据集和流程在潜空间中的嵌入表示后,我们可以利用潜在函数 f(zdi,zpj) 来预测流程 pj 在数据集 di 上的性能得分。然而,由于制造业场景的不确定性,性能得分并非一个确定的值,而是一个随机变量。因此,我们将性能得分 sij 建模为服从上述提到的正态分布 N(f(zdi,zpj),σ2)。
通过贝叶斯推断,我们可以得到性能得分 sij 的后验分布。具体来说,给定观测到的部分性能得分数据,我们可以利用马尔可夫链蒙特卡洛(MCMC)方法或变分推断等近似推断算法来估计后验分布的参数,从而得到性能得分的完整概率描述。这个后验分布不仅包含了性能得分的期望值(即精度信息),还反映了性能得分的波动性(即方差信息),为我们后续的集成权重优化提供了丰富的信息。
2.3 兼顾精度与波动性的目标函数优化
为了获得鲁棒的机器学习集成流程,我们希望集成后的预测结果既具有较高的精度(即后验均值较大),又具有较低的波动性(即后验方差较小)。因此,我们定义了一个兼顾精度与波动性的目标函数来优化集成权重。


其中 α∈[0,1] 为一个权衡参数,用于控制精度和波动性在目标函数中的相对重要性。当 α=0 时,目标函数仅考虑精度,即最大化集成预测的后验均值;当 α=1 时,目标函数仅考虑波动性,即最小化集成预测的后验方差。通过调整 α 的值,我们可以在精度和波动性之间取得平衡,获得满足不同应用场景需求的鲁棒集成流程。
为了求解上述优化问题,我们可以采用拉格朗日乘数法将其转化为无约束优化问题,然后利用梯度下降等优化算法来寻找最优的集成权重 w1,⋯,wm。
三、案例研究
3.1 熔融沉积成型(FDM)应用场景
熔融沉积成型是一种常见的 3D 打印技术,在制造业中广泛应用于原型制作和小批量生产。然而,FDM 打印过程中受到多种因素的影响,如打印温度、层厚、填充密度等,导致打印质量存在较大的波动。我们收集了不同参数设置下的 FDM 打印数据集,包含多个样本的特征信息(如打印参数、材料特性等)以及对应的质量指标(如尺寸精度、表面粗糙度等)。
我们将所提出的 WE - BLSM 方法应用于该数据集,首先利用贝叶斯潜空间模型学习数据集和多个候选机器学习流程(如支持向量机、随机森林、神经网络等)在潜空间中的嵌入表示。然后,建模每个流程在不同数据子集上的性能得分后验分布,并通过优化目标函数获得集成权重。实验结果表明,与单一机器学习流程和传统的集成学习方法相比,WE - BLSM 方法能够显著提高预测精度,同时降低预测结果的波动性,为 FDM 打印质量的控制和优化提供了更可靠的预测模型。
3.2 气溶胶喷射打印(AJP)应用场景
气溶胶喷射打印是一种新兴的微纳制造技术,可用于制造高精度的电子器件和传感器。在 AJP 过程中,气溶胶的生成、传输和沉积等环节受到多种因素的影响,导致打印图案的尺寸和形状存在不确定性。我们构建了 AJP 实验数据集,包含不同工艺条件下的打印样本特征和对应的图案尺寸测量数据。
应用 WE - BLSM 方法对该数据集进行分析,通过潜空间建模和性能得分分布建模,我们能够自动选择和组合适合不同工艺条件的机器学习流程。优化后的集成流程在预测 AJP 打印图案尺寸方面表现出更高的精度和鲁棒性,能够有效应对工艺参数变化带来的数据分布变化,为 AJP 工艺的优化和质量控制提供了有力的支持。
3.3 Tecator 数据集应用场景
Tecator 数据集是一个经典的制造业相关数据集,包含了近红外光谱数据和对应的肉类成分(如水分、脂肪、蛋白质等)含量测量值。该数据集常用于测试机器学习算法在回归问题上的性能。我们将其作为第三个应用场景来验证所提方法的有效性。
在 Tecator 数据集上,我们同样应用 WE - BLSM 方法进行机器学习流程的选择与适配。通过与多种基准方法进行对比实验,结果表明我们的方法能够在不同的数据划分和噪声水平下保持稳定的预测性能,在精度和波动性方面均优于传统方法,进一步证明了所提方法在制造业数据分析和建模中的通用性和鲁棒性。
四、结论与展望
4.1 研究结论
本文提出了一种面向制造业多变工业场景的鲁棒机器学习流程选择与适配方法,通过引入基于贝叶斯潜空间模型的加权集成机制推荐系统,实现了数据集与机器学习流程在共享潜空间中的兼容性建模和性能得分分布估计。通过优化兼顾精度与波动性的目标函数,自动获得了具有鲁棒性的集成权重。案例研究在熔融沉积成型、气溶胶喷射打印和 Tecator 数据集三个应用场景中验证了所提方法的有效性和优越性,能够显著提高预测精度并降低预测结果的波动性,为制造业的智能化升级提供了有力的技术支持。
4.2 研究展望
尽管本文提出的方法在多个应用场景中取得了良好的效果,但仍存在一些可以进一步改进和拓展的方向。未来的研究可以考虑引入更多的先验知识和领域信息来进一步优化潜空间模型,提高模型对复杂工业场景的适应能力。此外,可以探索更加高效的近似推断算法和优化方法,以降低计算复杂度,提高方法的实时性和可扩展性。同时,将所提方法应用于更多的制造业领域和实际生产场景,开展大规模的实证研究,也是未来研究的重要方向。
📚第二部分——运行结果
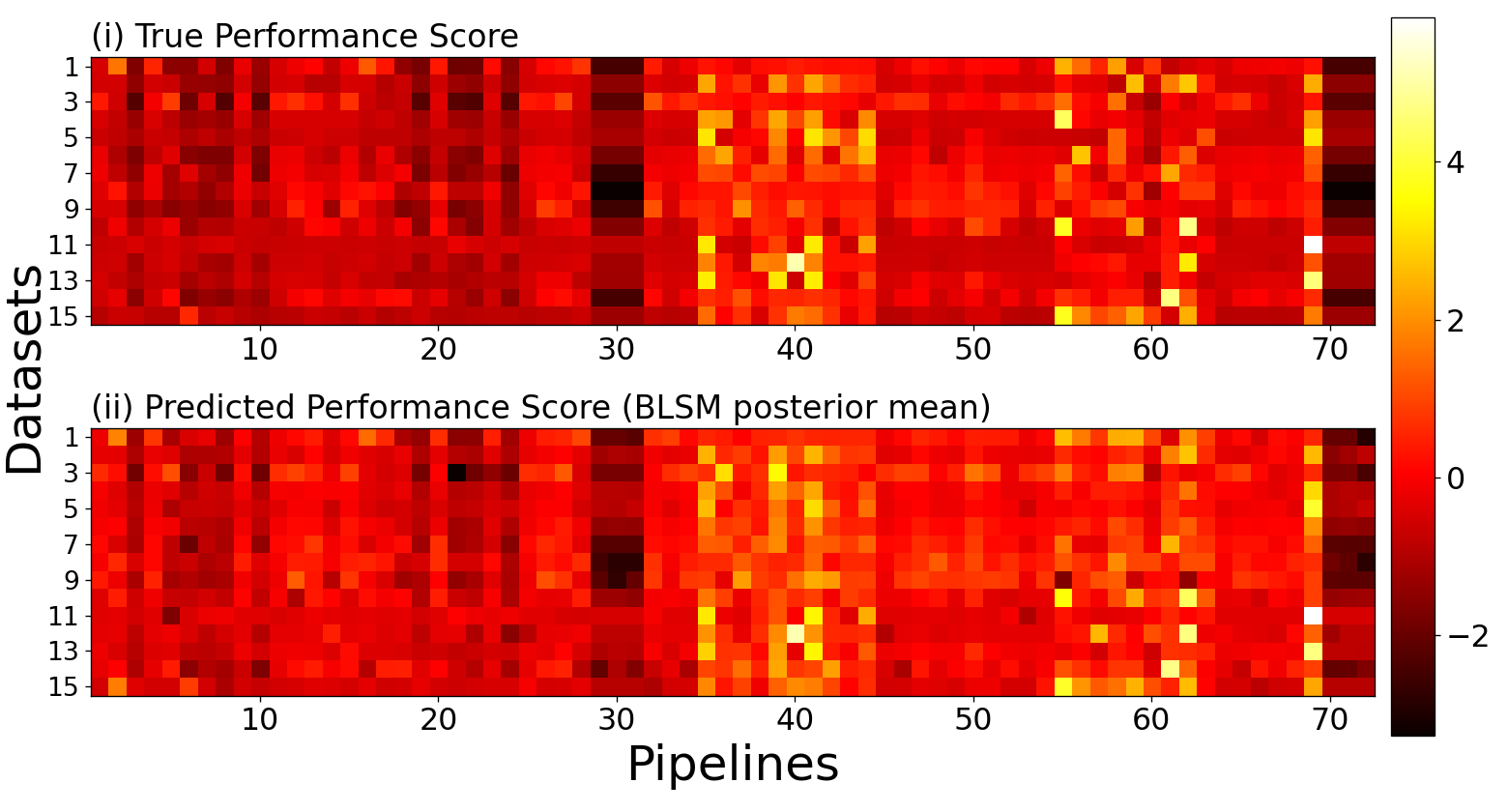
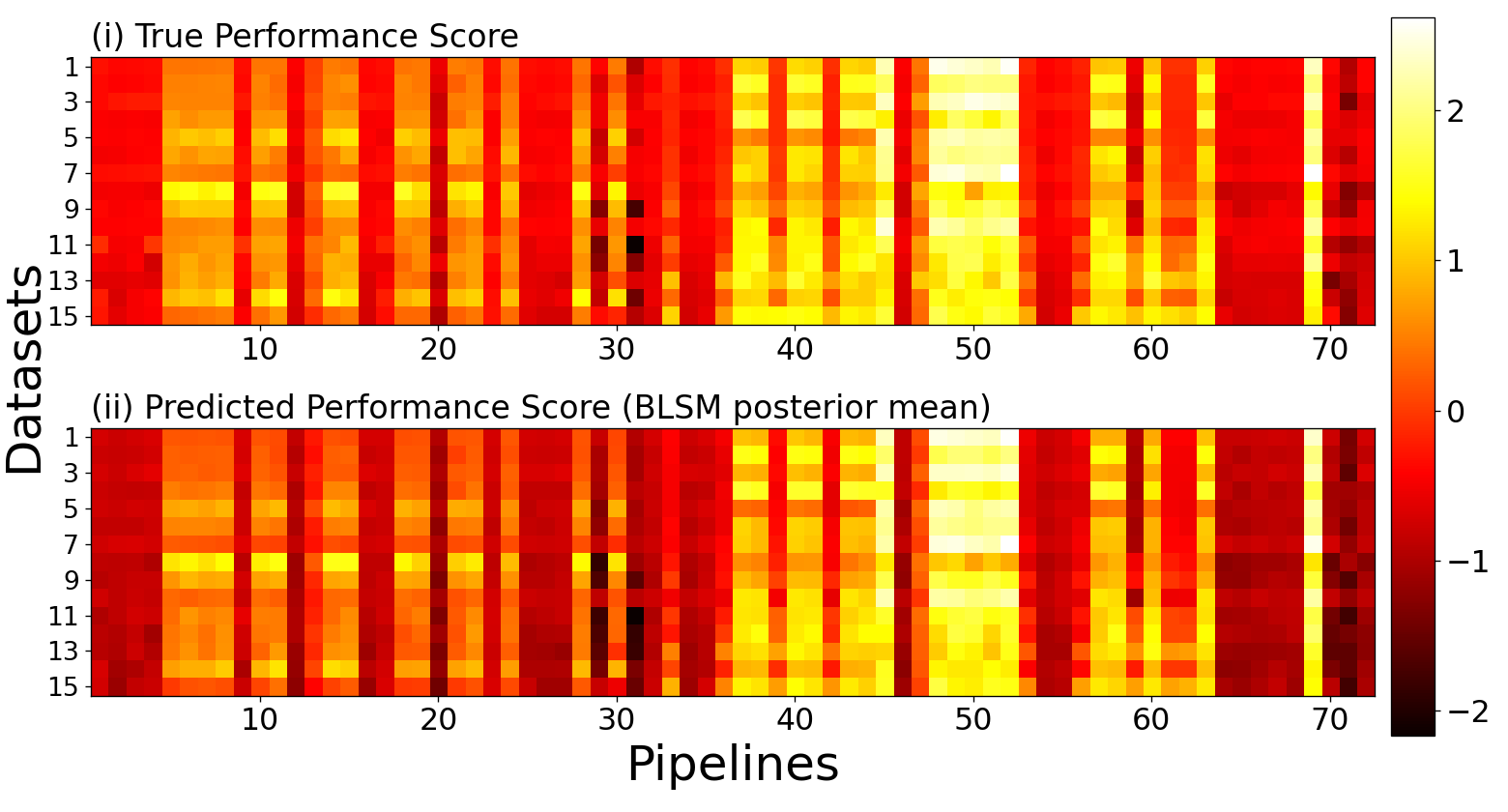
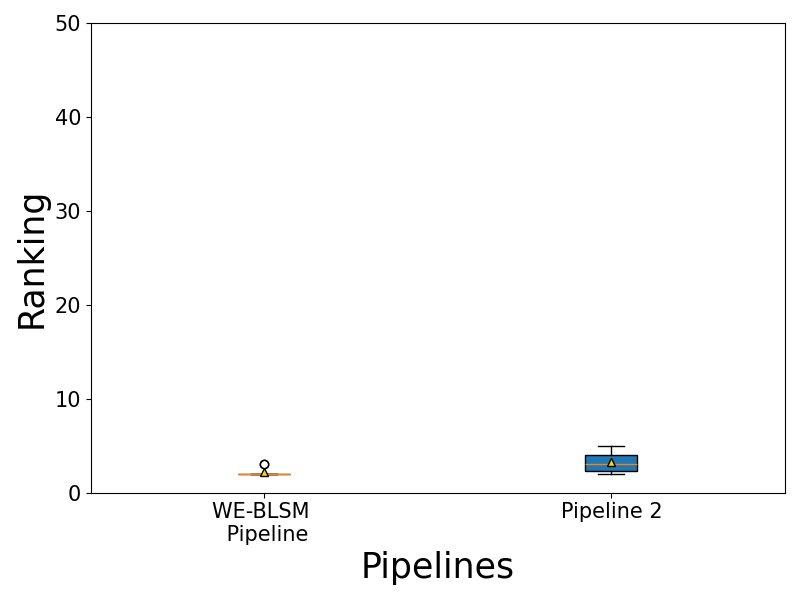
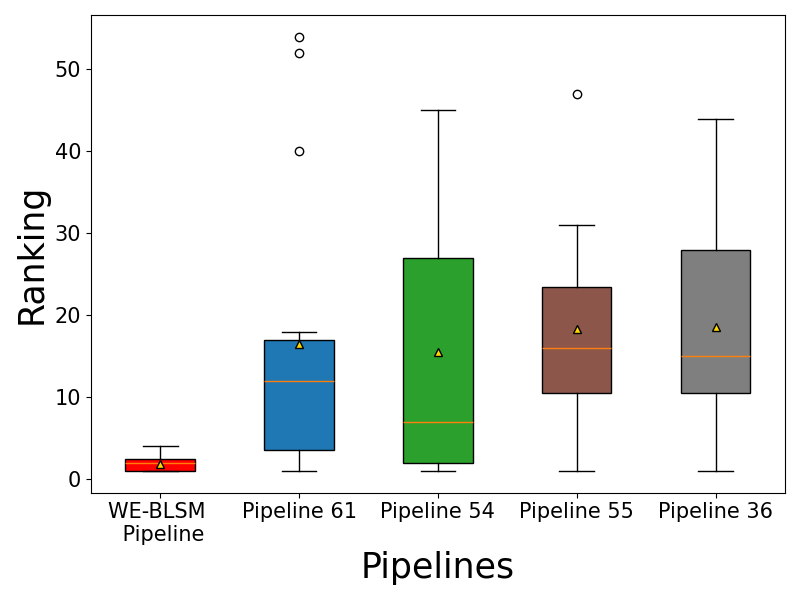
主函数代码:
import matplotlib.pyplot as plt
import numpy as np
from cvxopt.modeling import op, dot
from cvxopt.modeling import variable
from cvxopt import matrix, solvers
import logging
import json
from matplotlib.colors import ListedColormap
from utils import cond_dist, cond_dist_g, predict_blsm, get_ranking, get_ptp
from plot import plot_heatmap, plot_3d_bar, ptp_color_map, plot_ptp_ranking, plot_ranking_all_methods_v2
from scipy.io import loadmat
import os
import argparse
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--data', type=str, default='tec', help='data source')
parser.add_argument('--p_train', type=float, default=0.5, help='proportion of evaluation matrix observed (1-missing rate)')
args = parser.parse_args()
logging.basicConfig(filename='../results/ensemble.log', level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
np.set_printoptions(suppress=True)
pre_run = False
data_source = args.data #'tec'
logging.info(f"Load NRMSE matrix from 72 pipelines evaluated on 15 {data_source} datasets")
print(f"Load NRMSE matrix from 72 pipelines evaluated on 15 {data_source} datasets")
with open(f"../data/{data_source}_boot_results.json", "r") as file: #fdm_boot_results_07.json
fdm_results = json.load(file)
# NRMSE matrix
dat_true = np.array(fdm_results['nrmse'])
# use Inverse NRMSE if regression (FDM, TEC), otherwise (AJP) use classification accuray
if data_source == 'ajp':
dat = dat_true.copy()
else:
dat = 1/dat_true
N = dat.shape[0] # num datasets
M = dat.shape[1] # num pipelines
logging.info("Standardize each row of performance score matrix")
# standardize each row of performance score matrix
for i in range(N):
dat[i,:] = (dat[i,:]-dat[i,:].mean())/dat[i,:].std()
# vectorize standardized matrix
dat_vec=dat.copy().reshape(-1,1)
# random introduce missing (nan) entries
p_train = args.p_train #0.5
results_path = '../results/' #f'../data/{data_source}{(1-p_train):.1f}/'
np.random.seed(123456)
randid = np.random.permutation(N*M)
dat_vec[randid[int(N*M*p_train):]] = np.nan
# reshape to NxM performance score matrix (with missing/nan entries)
S_na = dat_vec.reshape(N,M)
# NRMSE/Accuracy matrix with missing (nan) entries
dat_true_na = dat_true.copy().reshape(-1)
dat_true_na[randid[int(N*M*p_train):]] = 100.
dat_true_na = dat_true_na.reshape(N,M)
nrmse_base_all = np.load(os.path.join(results_path, 'nrmse_base_all.npy'))
en_nrmse_tune = np.load(os.path.join(results_path, 'en_nrmse_tune.npy'))
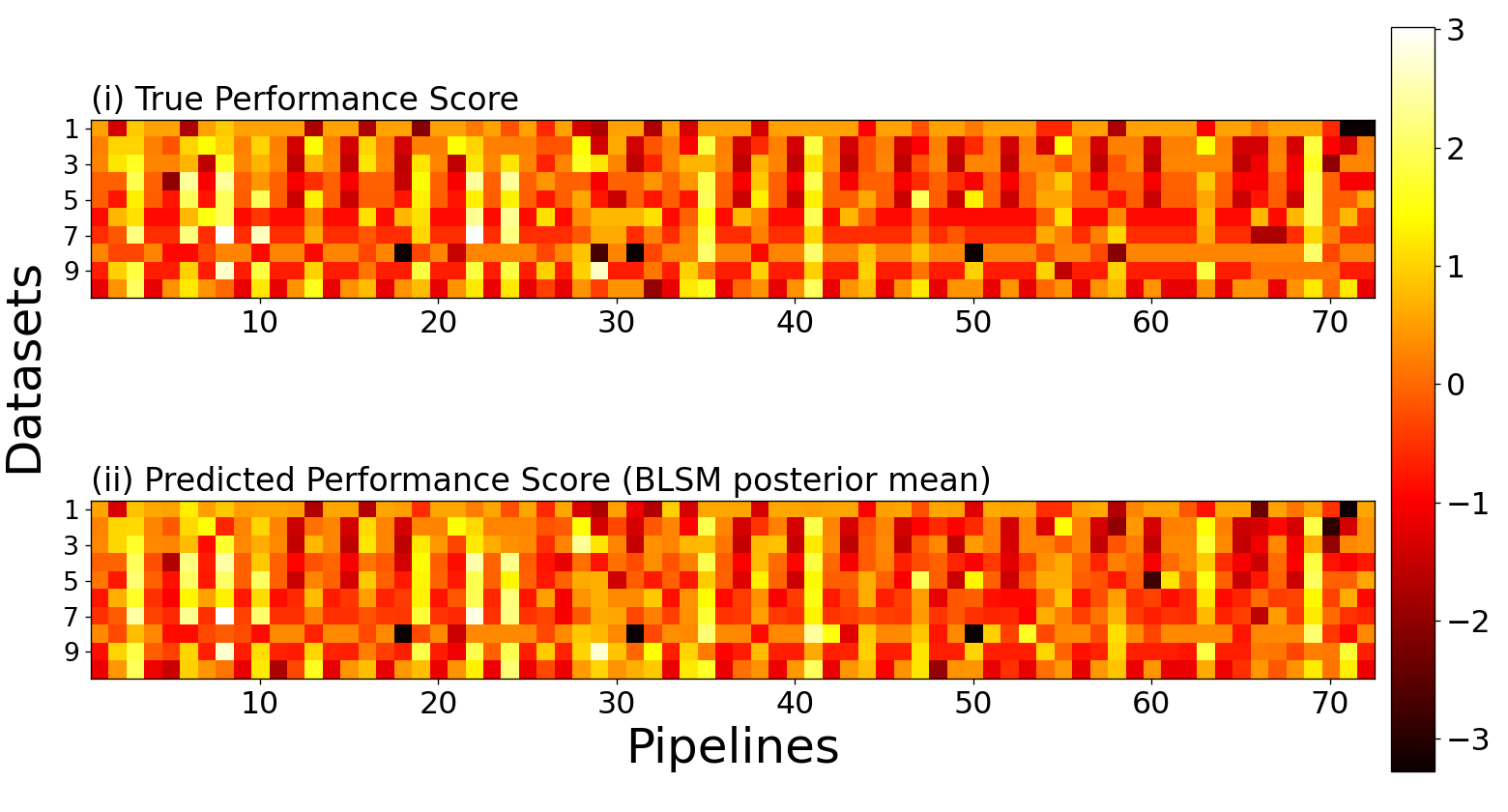
yhat = np.load(os.path.join(results_path, 'blsm_pred_score.npy'))
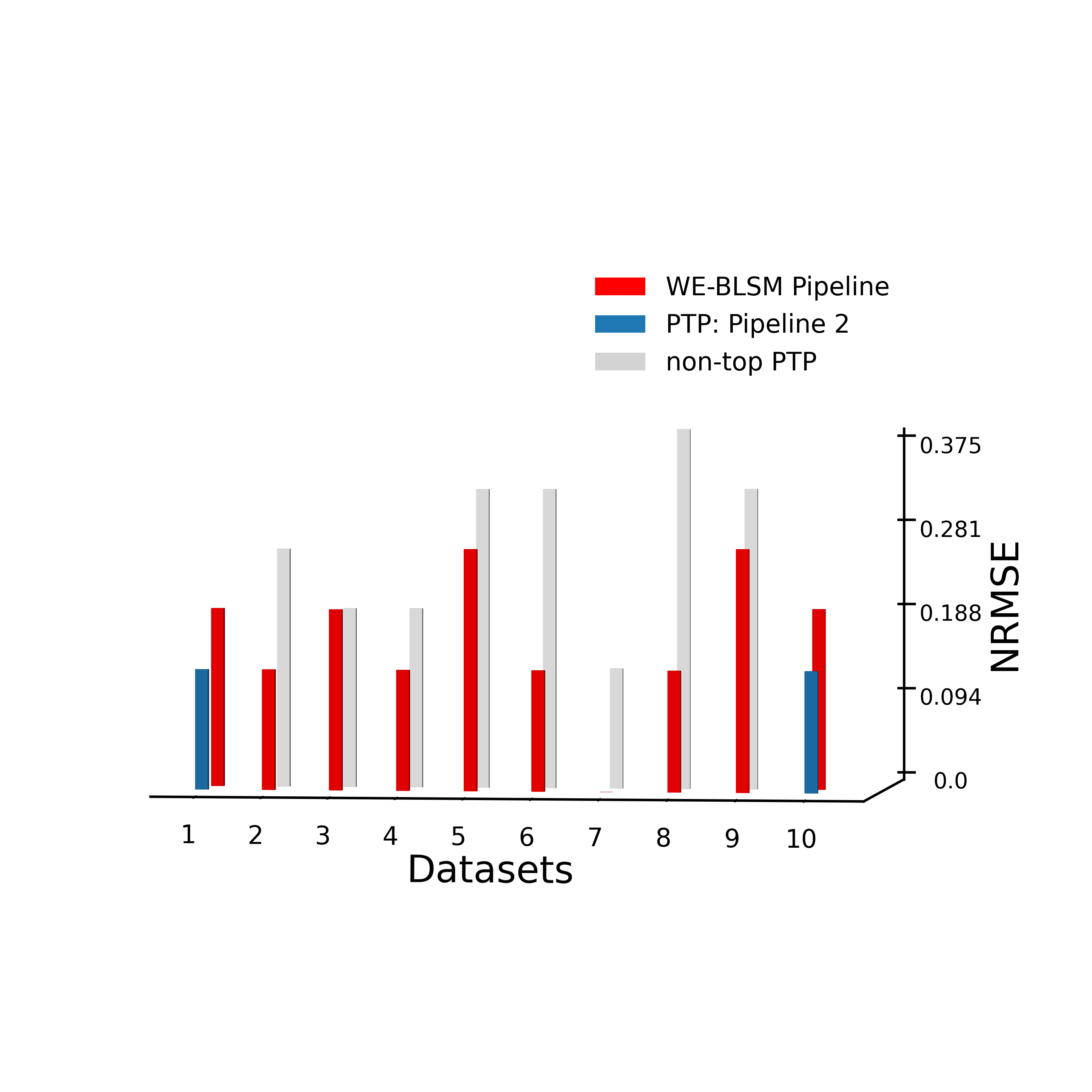
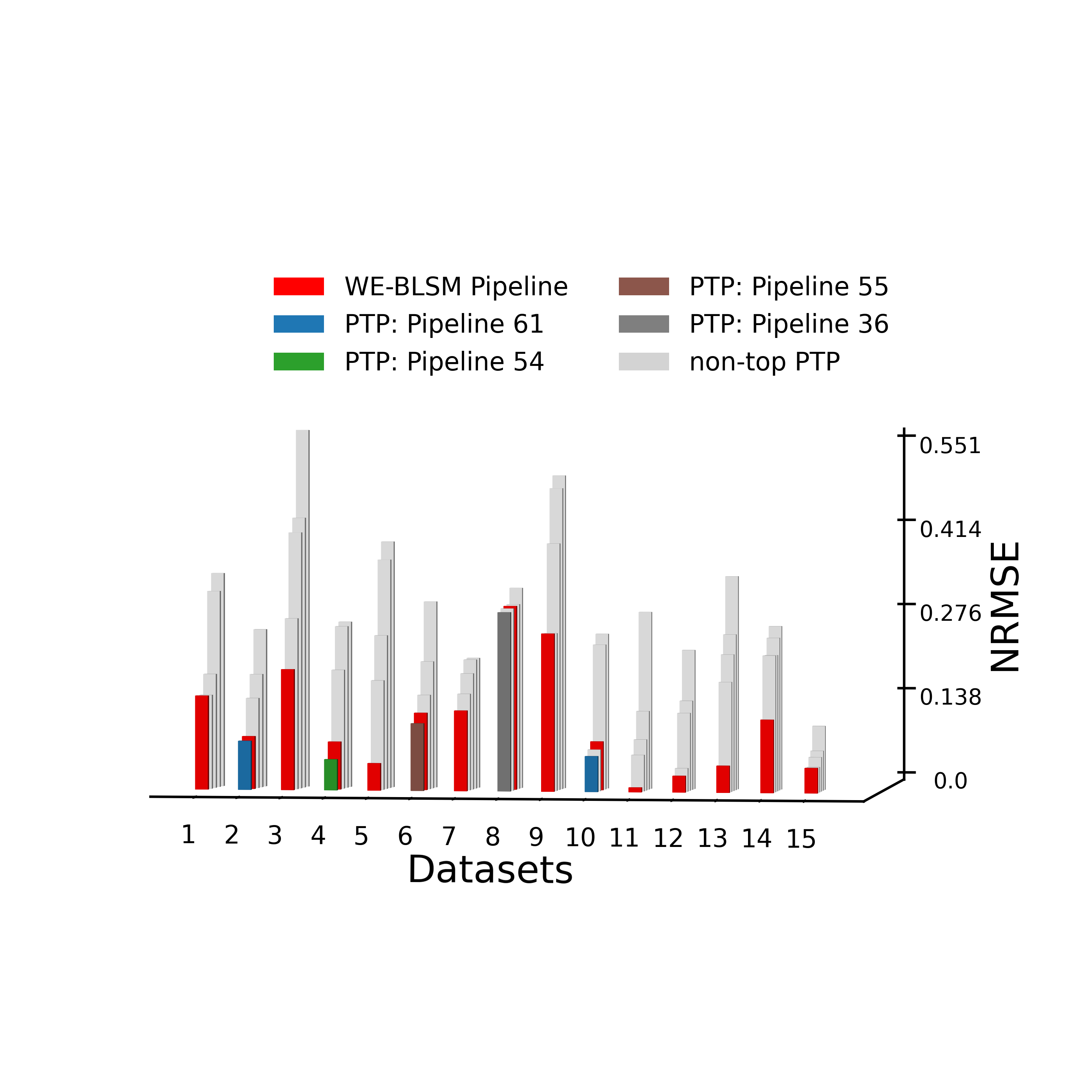
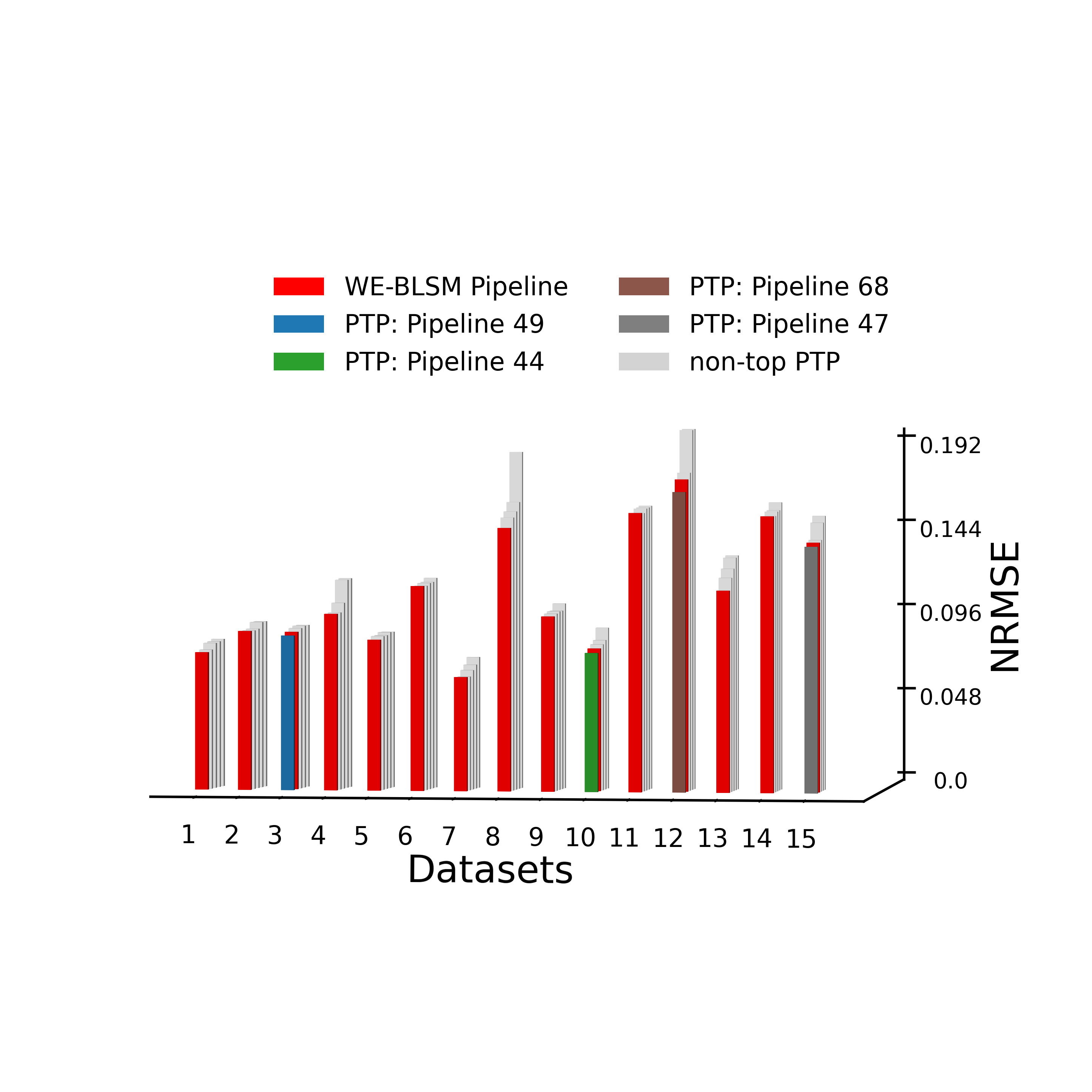
logging.info("Reproduce Figure 6(a): 3D bar plot of NRMSEs of PTP and WE-BLSM pipelines")
print("Reproduce Figure 6(a): 3D bar plot of NRMSEs of PTP and WE-BLSM pipelines")
if data_source == 'ajp':
dat_true_orig = dat_true.copy()
en_nrmse_tune_orig = en_nrmse_tune.copy()
dat_true = 1 - dat_true
en_nrmse_tune = 1 - np.array(en_nrmse_tune)
uniq_bpipe = get_ptp(en_nrmse_tune, dat_true, tol=0.001)
else:
uniq_bpipe = get_ptp(en_nrmse_tune, dat_true, tol=0.01)
npipe = len(uniq_bpipe) + 1
colors = ptp_color_map(uniq_bpipe)
plot_3d_bar(en_nrmse_tune, dat_true, uniq_bpipe, colors, outpath=f'../results/bar3d_{data_source}_m{(1-p_train)*100:.0f}.png')
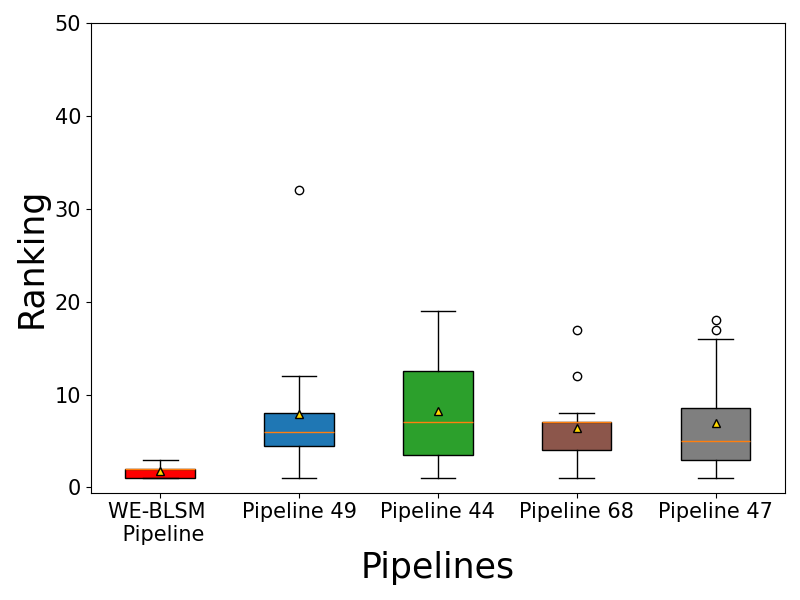
logging.info("Reproduce Figure 6(b): PTP ranking box plot")
print("Reproduce Figure 6(b): PTP ranking box plot")
if data_source == 'ajp':
plot_ptp_ranking(en_nrmse_tune_orig, dat_true_orig, uniq_bpipe, colors, outpath=f'../results/ptp_ranking_{data_source}_m{(1-p_train)*100:.0f}.png', cls=True)
else:
plot_ptp_ranking(en_nrmse_tune, dat_true, uniq_bpipe, colors, outpath=f'../results/ptp_ranking_{data_source}_m{(1-p_train)*100:.0f}.png')
logging.info("Collect ranking of pipelines by five methods")
print("Collect ranking of pipelines by five methods")
bpmf_pred = loadmat(os.path.join(results_path, 'bpmf_pred_results_final.mat'))['nrmse_pred']
ncf_pred = loadmat(os.path.join(results_path, 'ncf_predicted_matrix.mat'))['predicted_matrix']
nrmse_all_pipe = np.zeros([N,M+2])
nrmse_all_pipe[:,:M] = dat_true_orig if data_source == 'ajp' else dat_true
nrmse_all_pipe[:,M] = nrmse_base_all
nrmse_all_pipe[:,M+1] = en_nrmse_tune_orig if data_source == 'ajp' else en_nrmse_tune
yrank_en = get_ranking(nrmse_all_pipe, cls=True if data_source == 'ajp' else False)+1
bpmf_rk_l=[]
for i in range(N):
bpmf_rk_l.append(yrank_en[i,bpmf_pred[i,:].argmax()].item())
ncf_rk_l=[]
for i in range(N):
ncf_rk_l.append(yrank_en[i,ncf_pred[i,:].argmax()].item())
blsm_rk_l=[]
for i in range(N):
blsm_rk_l.append(yrank_en[i,yhat[i,:].argmax()])
blsm_rk = np.array(blsm_rk_l)
bpmf_rk = np.array(bpmf_rk_l)
ncf_rk = np.array(ncf_rk_l)
vanilla_rk = yrank_en[:,-2]
en_rk = yrank_en[:,-1]
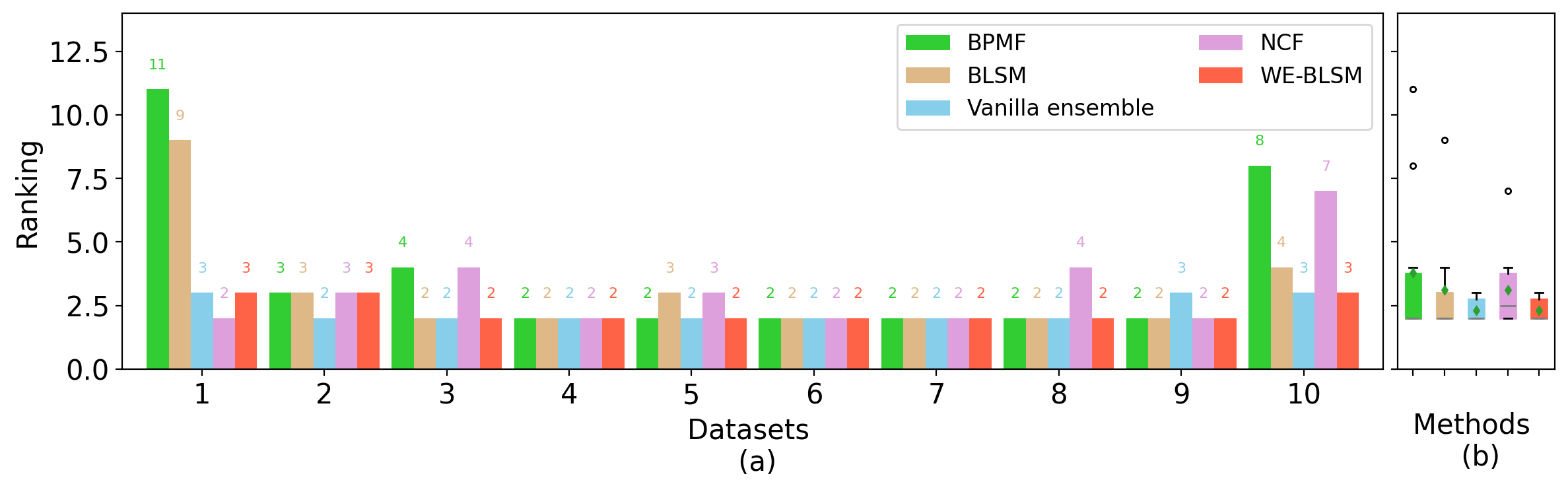
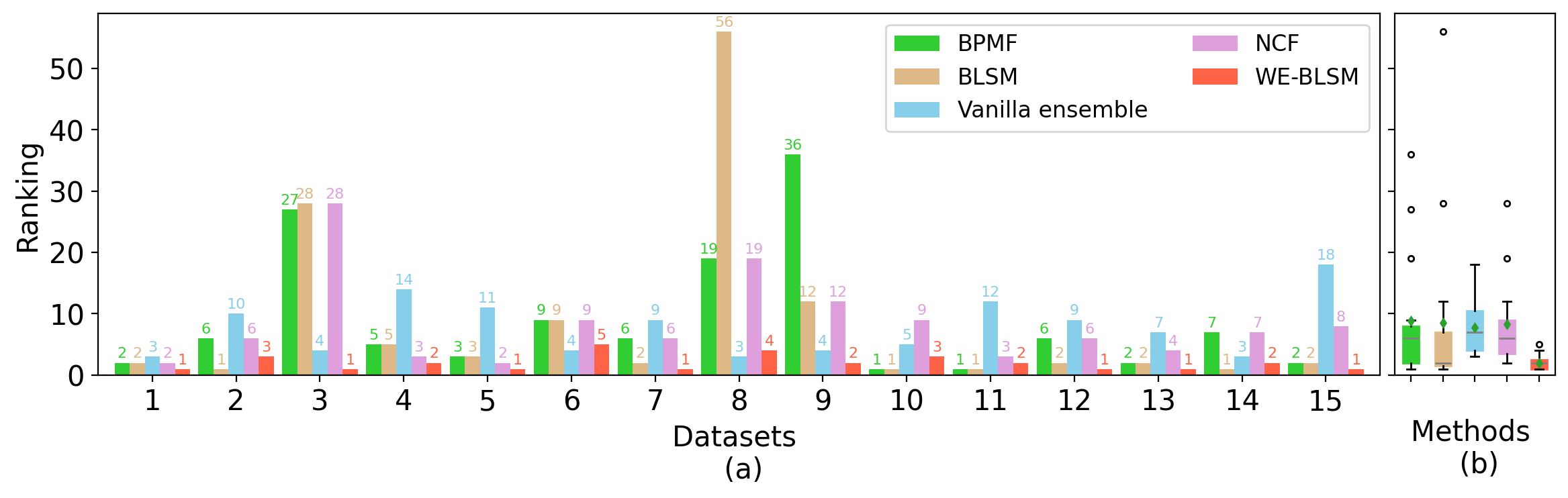
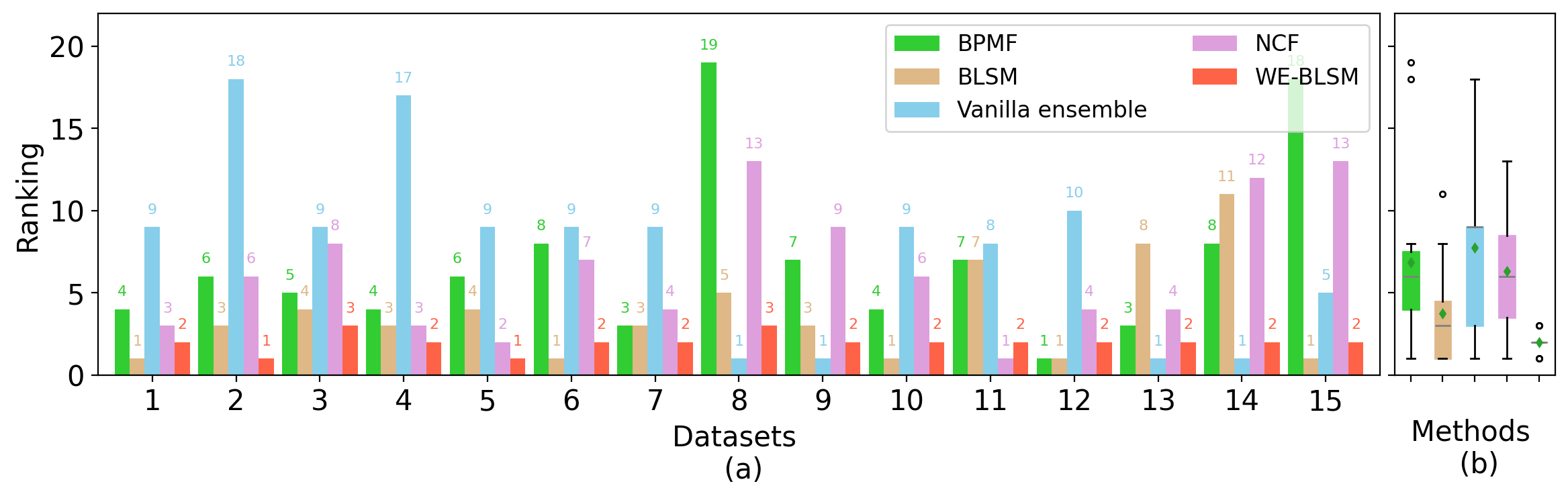
logging.info("Reproduce Figure 7: Bar plot and boxplots of rankings by four methods")
print("Reproduce Figure 7: Bar plot and boxplots of rankings by four methods")
plot_ranking_all_methods_v2(bpmf_rk, blsm_rk, vanilla_rk, ncf_rk, en_rk, outpath=f'../results/bar_box_ranking_{data_source}_m{(1-p_train)*100:.0f}.png')
if __name__ == '__main__':
main()
🎉第三部分——参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)
🌈第四部分——Python代码、数据下载
资料获取,更多粉丝福利,MATLAB|Simulink|Python资源获取


















 861
861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









