




 本文深入探讨了Anchorhead损失函数的实现细节,包括基于Anchor的损失计算、回归任务的处理,以及在fasterr-cnn模型中的应用。文章详细介绍了如何通过多层卷积进行分类与回归,Anchor生成的过程,以及如何计算正负样本的损失。
本文深入探讨了Anchorhead损失函数的实现细节,包括基于Anchor的损失计算、回归任务的处理,以及在fasterr-cnn模型中的应用。文章详细介绍了如何通过多层卷积进行分类与回归,Anchor生成的过程,以及如何计算正负样本的损失。
0.简介
Anchor head主要是为了计算基于Anchor的损失函数,以及简单的回归。其中含有两个单层卷积,一个用来分类,一个用来回归,可以添加多层, 例如Retina head。
以下代码的解读均依靠断点调试获得,使用的模型为faster r-cnn
1.self.loss
def loss(self,
cls_scores,
bbox_preds,
gt_bboxes,
gt_labels,
img_metas,
cfg,
gt_bboxes_ignore=None):
featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
assert len(featmap_sizes) == len(self.anchor_generators)
anchor_list, valid_flag_list = self.get_anchors(
featmap_sizes, img_metas)
label_channels = self.cls_out_channels if self.use_sigmoid_cls else 1
cls_reg_targets = anchor_target(
anchor_list,
valid_flag_list,
gt_bboxes,
img_metas,
self.target_means,
self.target_stds,
cfg,
gt_bboxes_ignore_list=gt_bboxes_ignore,
gt_labels_list=gt_labels,
label_channels=label_channels,
sampling=self.sampling)
if cls_reg_targets is None:
return None
(labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
num_total_pos, num_total_neg) = cls_reg_targets
num_total_samples = (
num_total_pos + num_total_neg if self.sampling else num_total_pos)
losses_cls, losses_bbox = multi_apply(
self.loss_single,
cls_scores,
bbox_preds,
labels_list,
label_weights_list,
bbox_targets_list,
bbox_weights_list,
num_total_samples=num_total_samples,
cfg=cfg)
return dict(loss_cls=losses_cls, loss_bbox=losses_bbox)
img_meta:
- ori_shape:原始图片的shape:(480*640)
- img_shape:缩放后的shape:(800*1067)
- scale_factor:缩放因子:1.667
- flip:是否翻转?
featuremap_sizes:
根据cls_scores的大小获得
0:200* 272(stride = 4)
1:100* 136(stride = 8)
。。。
4:13* 17(stride=16*4=64)
self.anchor_base_sizes:保存了stride的大小:
[4, 8, 16, 32, 64]
self.anchor_scales:[8],代表了anchor的大小吧,因为是RPN,只有一个。
self.anchor_ratios:[0.5, 1, 2],代表了anchor的长宽比。
self.anchor_generators:anchor生成器,使用上面三个量进行生成。因为有5个layer,所以generator共有五个。
1.1. AnchorGenerator
在初始化的时候,base_size = 4(基础长宽),scales = [8](放大倍数),ratios=[0.5, 1, 2](长宽比),scale_major = True(排列方式,前m个代表m种scale还是m种ratio)
base_anchor有三个,这时因为有三个ratio,一个scale,中心在base_size / 2处。是以左上右下表示的。
生成方式在 self.gen_base_anchors中
1.1.2. self.gen_base_anchors
- w, h 为基础长宽。x_ctr = y_ctr = self.base_size / 2,代表中心。由于base_size是用stride赋值的,如果anchor的大小是base_size/2的话,那么这些anchor构成了一个划分(不相交)。
- h_ratios = sqrt(ratios), w_ratios = 1 / sqrt(ratios)。ratio指的是高 / 宽。取一个根号。
- scale_major与否:如果是scale_major,那么ratios变为3*1的矩阵,scale变为1 * 1(scale个数)的矩阵。最后相乘,以基础长宽为基础,最后拉长,得到w_s。假设scale的个数为2,那么ws的前2个为ratios[0]乘上两个scales的w,之后两个为ratios[1]乘上两个scale的w。
- 最终返回的是左上角和右下角,并且取整。
返回anchor_head
原始代码如下:
def gen_base_anchors(self):
w = self.base_size
h = self.base_size
if self.ctr is None:
x_ctr = 0.5 * (w - 1)
y_ctr = 0.5 * (h - 1)
else:
x_ctr, y_ctr = self.ctr
h_ratios = torch.sqrt(self.ratios)
w_ratios = 1 / h_ratios
if self.scale_major:
ws = (w * w_ratios[:, None] * self.scales[None, :]).view(-1)
hs = (h * h_ratios[:, None] * self.scales[None, :]).view(-1)
else:
ws = (w * self.scales[:, None] * w_ratios[None, :]).view(-1)
hs = (h * self.scales[:, None] * h_ratios[None, :]).view(-1)
# yapf: disable
base_anchors = torch.stack(
[
x_ctr - 0.5 * (ws - 1), y_ctr - 0.5 * (hs - 1),
x_ctr + 0.5 * (ws - 1), y_ctr + 0.5 * (hs - 1)
],
dim=-1).round()
# yapf: enable
return base_anchors
1.2 self.get_anchors
Get anchors according to feature map sizes.
Args:
featmap_sizes (list[tuple]): Multi-level feature map sizes.
img_metas (list[dict]): Image meta info.
Returns:
tuple: anchors of each image, valid flags of each image
num_imgs:多少张图片
num_levels:FPN的level个数(5)
对于每一个level,使用self.anchor_generator的grid_anchors 获得anchors
1.2.1. grid_anchors
输入:特征图尺寸,stride
比如说[200, 272],4
- 生成meshgrid,以(0, 0)为左上角起点生成grid的(x, y)坐标,距离为stride。shift_xx,shift_yy
- shifts为[200 * 272 = 54400, 4] shape的向量,4是因为左上角,右下角,有4个值。
- shift加上才能base_anchors,得到了all_anchors,大小为[54400 * 3 = 163200, 4],排列方式为前3个为base_anchor,之后这三个base anchor向右移动。得到接下来的3个anchor。
grid_anchors获得的anchor按照level从低到高append起来,得到anchor_list。
1.3 anchor_target(anchor_target文件中)
Compute regression and classification targets for anchors.
Args:
anchor_list (list[list]): Multi level anchors of each image.
valid_flag_list (list[list]): Multi level valid flags of each image.
gt_bboxes_list (list[Tensor]): Ground truth bboxes of each image.
img_metas (list[dict]): Meta info of each image.
target_means (Iterable): Mean value of regression targets.
target_stds (Iterable): Std value of regression targets.
cfg (dict): RPN train configs.
Returns:
tuple
- 将每张图片的gt_bboxes都cat到一起。以及valid_flag_list。
- 对每一张图片调用anchor_target_simple
1.3.1. anchor_target_simple
- 利用inside_flags筛选掉在边界外的框,191012个
- 调用assign_and_samplem
def assign_and_sample(bboxes, gt_bboxes, gt_bboxes_ignore, gt_labels, cfg):
bbox_assigner = build_assigner(cfg.assigner)
bbox_sampler = build_sampler(cfg.sampler)
assign_result = bbox_assigner.assign(bboxes, gt_bboxes, gt_bboxes_ignore,
gt_labels)
sampling_result = bbox_sampler.sample(assign_result, bboxes, gt_bboxes,
gt_labels)
return assign_result, sampling_result
- 构建一个assigner,一个sampler,
assigner的构造如下:
{‘type’: ‘MaxIoUAssigner’, ‘pos_iou_thr’: 0.7, ‘neg_iou_thr’: 0.3, ‘min_pos_iou’: 0.3, ‘ignore_iof_thr’: -1}。
之后依次assign、sampling。 - assign_result中包含max_overlaps、gt_inds,num_gts。其中overlap代表的应该是分配的IOU,而gt_inds是一个和anchor_list同样大小的数组,1代表pos,0代表忽略,-1代表反例。
- sampling_result中包含的信息就多了
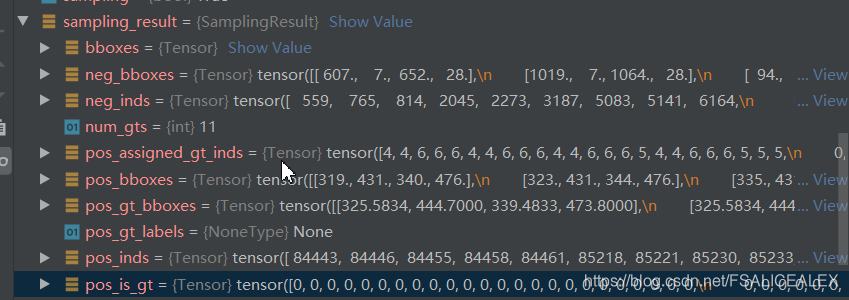
- 这个时候,anchor、gt都是在图(原图放大之后)上,通过bbox2delta将bbox转换成pos_bbox_targets:
pos_bbox_targets = bbox2delta(sampling_result.pos_bboxes,
sampling_result.pos_gt_bboxes,
target_means, target_stds)
- 接下来的代码:
# 将bbox装回所有的bbox列表中
bbox_targets[pos_inds, :] = pos_bbox_targets
# weights设置为1
bbox_weights[pos_inds, :] = 1.0
# 主要是区分Retina和RPN吧,两者的label不同。
if gt_labels is None:
labels[pos_inds] = 1
else:
labels[pos_inds] = gt_labels[sampling_result.pos_assigned_gt_inds]
# 设置权重,为1,或者是指定的值
if cfg.pos_weight <= 0:
label_weights[pos_inds] = 1.0
else:
label_weights[pos_inds] = cfg.pos_weight
# 设置neg的权重
if len(neg_inds) > 0:
label_weights[neg_inds] = 1.0
# map up to original set of anchors
if unmap_outputs:
num_total_anchors = flat_anchors.size(0)
labels = unmap(labels, num_total_anchors, inside_flags)
label_weights = unmap(label_weights, num_total_anchors, inside_flags)
bbox_targets = unmap(bbox_targets, num_total_anchors, inside_flags)
bbox_weights = unmap(bbox_weights, num_total_anchors, inside_flags)
return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
neg_inds)

















&spm=1001.2101.3001.5002&articleId=100739514&d=1&t=3&u=7cd42634c21449128cdb021e4632e95a)
 5195
5195





 到【灌水乐园】发言
到【灌水乐园】发言







