




 本文介绍了使用sklearn中的决策树模型,特别是ID3和CART算法,进行泰坦尼克乘客生存预测的过程。内容包括数据探索、数据清洗、特征选择、模型训练和模型评估。在特征选择中,选择了如Pclass、Sex、Age等关键特征,并通过DictVectorizer将类别特征转换为数值。最后,通过K折交叉验证评估模型的准确率。
本文介绍了使用sklearn中的决策树模型,特别是ID3和CART算法,进行泰坦尼克乘客生存预测的过程。内容包括数据探索、数据清洗、特征选择、模型训练和模型评估。在特征选择中,选择了如Pclass、Sex、Age等关键特征,并通过DictVectorizer将类别特征转换为数值。最后,通过K折交叉验证评估模型的准确率。
1. sklearn 中的决策树模型
首先,我们需要掌握 sklearn 中自带的决策树分类器 DecisionTreeClassifier,方法如下:
clf = DecisionTreeClassifier(criterion='entropy')
到目前为止,sklearn 中只实现了 ID3 与 CART 决策树,所以我们暂时只能使用这两种决策树,在构造 DecisionTreeClassifier 类时,其中有一个参数是 criterion,意为标准。它决定了构造的分类树是采用 ID3 分类树,还是 CART 分类树,对应的取值分别是 entropy 或者 gini:
- entropy: 基于信息熵,也就是 ID3 算法,实际结果与 C4.5 相差不大;
- gini:默认参数,基于基尼系数。CART 算法是基于基尼系数。CART 算法是基于基尼系数做属性划分的所以 criterion=gini 时,实际上执行的是 CART 算法。
我们通过设置 criterion='entropy’可以创建一个 ID3 决策树分类器,然后打印下 clf,看下决策树在 sklearn 中是个什么东西?
DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best')
这里我们看到了很多参数,除了设置 criterion 采用不同的决策树算法外,一般建议使用默认的参数,默认参数不会限制决策树的最大深度,不限制叶子节点数,认为所有分类的权重都相等等。当然你也可以调整这些参数,来创建不同的决策树模型。
我整理了这些参数代表的含义:
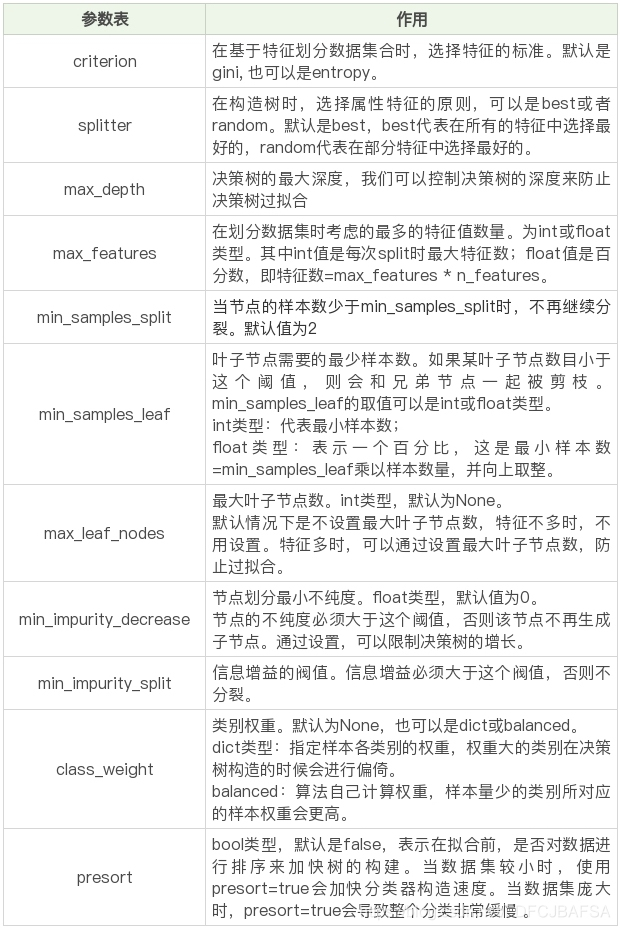
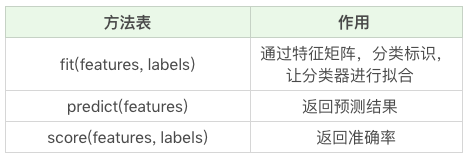
在构造决策树分类器后,我们可以使用 fit 方法让分类器进行拟合,使用 predict 方法对新数据进行预测,得到预测的分类结果,也可以使用 score 方法得到分类器的准确率。
下面这个表格是 fit 方法、predict 方法和 score 方法的作用。
2. Titanic 乘客生存预测
- 问题描述:
泰坦尼克海难是著名的十大灾难之一,究竟多少人遇难,各方统计的结果不一。现在我们可以得到部分的数据,具体数据你可以从 Kaggle 上下载:
Titanic_Data下载
其中数据集格式为 csv,一共有两个文件:
- train.csv 是训练数据集,包含特征信息和存活与否的标签;
- test.csv: 测试数据集,只包含特征信息。
现在我们需要用决策树分类对训练集进行训练,针对测试集中的乘客进行生存预测,并告知分类器的准确率。
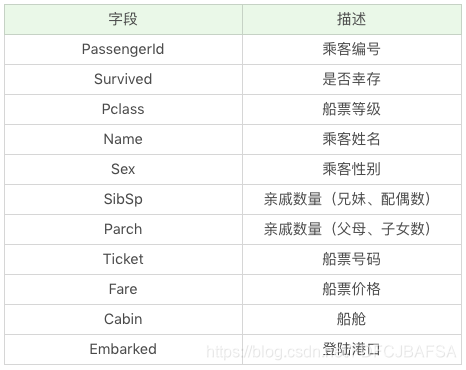
在训练集中,包括了以下字段,它们具体为:
生存预测的关键流程
我们要对训练集中乘客的生存进行预测,这个过程可
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2942
2942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









