




 本文通过两个案例介绍如何使用深度学习进行图像分类:一是手写数字识别,二是猫狗图片分类。文章详细展示了模型构建、数据预处理、训练及评估等关键步骤。
本文通过两个案例介绍如何使用深度学习进行图像分类:一是手写数字识别,二是猫狗图片分类。文章详细展示了模型构建、数据预处理、训练及评估等关键步骤。
深度学习用于计算机视觉,从零开始使用CPU训练模型
- 实例化一个小型的卷积神经网络
from keras import layers
from keras import models
import numpy as np
import matplotlib.pyplot as plt
Using TensorFlow backend.
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3), activation='relu', input_shape=(28,28,1))) ##(3*3+1)*32=320
model.add(layers.MaxPool2D((2,2)))
model.add(layers.Conv2D(64, (3,3), activation='relu')) ## 3*3*32*64+64
model.add(layers.MaxPool2D((2, 2)))
model.add(layers.Conv2D(64, (3,3), activation='relu')) ## 3*3*64*64+64
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10,activation='softmax')) ## 64*10 +10
WARNING:tensorflow:From D:\Anaconda3\envs\tfcpu\lib\site-packages\tensorflow\python\framework\op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 11, 11, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 5, 5, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 3, 3, 64) 36928
_________________________________________________________________
flatten_1 (Flatten) (None, 576) 0
_________________________________________________________________
dense_1 (Dense) (None, 64) 36928
_________________________________________________________________
dense_2 (Dense) (None, 10) 650
=================================================================
Total params: 93,322
Trainable params: 93,322
Non-trainable params: 0
_________________________________________________________________
- 导入MNIST数据,开始训练模型
from keras.datasets import mnist
from keras.utils import to_categorical
#(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
def load_data(filename):
f = np.load('mnist.npz')
return (f['x_train'], f['y_train']), (f['x_test'], f['y_test'])
(train_images, train_labels), (test_images, test_labels) = load_data('mnist.npz')
train_images = train_images.reshape((60000,28,28,1))
train_images = train_images.astype('float32')/255
train_labels = to_categorical(train_labels)
test_images = test_images.reshape((10000,28,28,1))
test_images = test_images.astype('float32')/255
test_labels = to_categorical(test_labels)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5, batch_size=64)
WARNING:tensorflow:From D:\Anaconda3\envs\tfcpu\lib\site-packages\tensorflow\python\ops\math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
Epoch 1/5
60000/60000 [==============================] - 44s 727us/step - loss: 0.1656 - acc: 0.9480
Epoch 2/5
60000/60000 [==============================] - 42s 707us/step - loss: 0.0444 - acc: 0.9863
Epoch 3/5
60000/60000 [==============================] - 43s 722us/step - loss: 0.0308 - acc: 0.9902
Epoch 4/5
60000/60000 [==============================] - 43s 717us/step - loss: 0.0237 - acc: 0.9929
Epoch 5/5
60000/60000 [==============================] - 43s 712us/step - loss: 0.0193 - acc: 0.9940
<keras.callbacks.History at 0x27c299ff550>
test_loss, test_acc = model.evaluate(test_images, test_labels)
10000/10000 [==============================] - 2s 223us/step
print(test_loss, ' ', test_acc)
0.02517861635509216 0.9931
从头开始训练一个猫狗分类器
1、准备数据集
import os , shutil
train_dir = r"F:\Data_Set\train_dir"
validation_dir = r"F:\Data_Set\validation_dir"
test_dir = r"F:\Data_Set\test_dir"
train_cats_dir = r"F:\Data_Set\train_dir\train_cats_dir"
train_dogs_dir = r"F:\Data_Set\train_dir\train_dogs_dir"
validation_cats_dir = r"F:\Data_Set\validation_dir\validation_cats_dir"
validation_dogs_dir = r"F:\Data_Set\validation_dir\validation_dogs_dir"
test_cats_dir = r"F:\Data_Set\test_dir\test_cats_dir"
test_dogs_dir = r"F:\Data_Set\test_dir\test_dogs_dir"
# 查看各个文件夹内的文件数量
print("猫的训练样本总共有:{}张图像".format(len(os.listdir(train_cats_dir))))
print("狗的训练样本总共有:{}张图像".format(len(os.listdir(train_dogs_dir))))
print("猫的验证样本总共有:{}张图像".format(len(os.listdir(validation_cats_dir))))
print("狗的验证样本总共有:{}张图像".format(len(os.listdir(validation_cats_dir))))
print("猫的测试样本总共有:{}张图像".format(len(os.listdir(test_cats_dir))))
print("狗的测试样本总共有:{}张图像".format(len(os.listdir(test_cats_dir))))
猫的训练样本总共有:1000张图像
狗的训练样本总共有:1000张图像
猫的验证样本总共有:500张图像
狗的验证样本总共有:500张图像
猫的测试样本总共有:500张图像
狗的测试样本总共有:500张图像
2、 构建模型
from keras import layers
from keras import models
import numpy as np
import matplotlib.pyplot as plt
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)))#3*3*32*3+32
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3), activation='relu'))#3*3*64*32+64
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
Using TensorFlow backend.
WARNING:tensorflow:From D:\Anaconda3\envs\tfcpu\lib\site-packages\tensorflow\python\framework\op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 148, 148, 32) 896
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 74, 74, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 72, 72, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 34, 34, 128) 73856
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 17, 17, 128) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 15, 15, 128) 147584
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 7, 7, 128) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 6272) 0
_________________________________________________________________
dense_1 (Dense) (None, 512) 3211776
_________________________________________________________________
dense_2 (Dense) (None, 1) 513
=================================================================
Total params: 3,453,121
Trainable params: 3,453,121
Non-trainable params: 0
_________________________________________________________________
3、模型编译
from keras import optimizers
model.compile(optimizer=optimizers.RMSprop(lr=1e-4),
loss='binary_crossentropy',
metrics=['acc'])
4、数据预处理
- 数据是以JPEG文件格式保存在硬盘中,所以需要将数据预处理,主要步骤如下:
- 读取图像文件
- 将JPEG的文件编码解码为RGB像素网格
- 将这些像素网格转化为浮点数张量
- 将0-255的像素值压缩到0-1的区间
- 上述步骤可以使用keras自带的图像预处理工具完成
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255)#将所有图像像素值缩放
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir,
target_size=(150,150),#将目标文件调整为150*150
batch_size=20,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(validation_dir,
target_size=(150,150),
batch_size=20,
class_mode='binary')
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
#查看一下生成器的结果
for data_batch, labels_batch in train_generator:
print("data batch shape: ", data_batch.shape)
print('labels batch shape: ', labels_batch.shape)
break
data batch shape: (20, 150, 150, 3)
labels batch shape: (20,)
5、训练模型
- 这里使用fit_generator方法来训练
history = model.fit_generator(train_generator,
steps_per_epoch=100,
epochs=20,
validation_data=validation_generator,
validation_steps=50)
WARNING:tensorflow:From D:\Anaconda3\envs\tfcpu\lib\site-packages\tensorflow\python\ops\math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
Epoch 1/20
100/100 [==============================] - 102s 1s/step - loss: 0.6853 - acc: 0.5335 - val_loss: 0.6714 - val_acc: 0.6020
Epoch 2/20
100/100 [==============================] - 96s 961ms/step - loss: 0.6578 - acc: 0.6115 - val_loss: 0.6510 - val_acc: 0.6080
Epoch 3/20
100/100 [==============================] - 93s 932ms/step - loss: 0.6101 - acc: 0.6710 - val_loss: 0.6068 - val_acc: 0.6730
Epoch 4/20
100/100 [==============================] - 94s 939ms/step - loss: 0.5634 - acc: 0.7170 - val_loss: 0.6187 - val_acc: 0.6730
Epoch 5/20
100/100 [==============================] - 97s 973ms/step - loss: 0.5351 - acc: 0.7270 - val_loss: 0.5684 - val_acc: 0.7040
Epoch 6/20
100/100 [==============================] - 94s 944ms/step - loss: 0.5001 - acc: 0.7635 - val_loss: 0.5691 - val_acc: 0.7050
Epoch 7/20
100/100 [==============================] - 97s 974ms/step - loss: 0.4772 - acc: 0.7710 - val_loss: 0.5990 - val_acc: 0.6840
Epoch 8/20
100/100 [==============================] - 94s 941ms/step - loss: 0.4466 - acc: 0.7950 - val_loss: 0.5641 - val_acc: 0.7190
Epoch 9/20
100/100 [==============================] - 96s 962ms/step - loss: 0.4199 - acc: 0.8020 - val_loss: 0.5600 - val_acc: 0.7120
Epoch 10/20
100/100 [==============================] - 96s 960ms/step - loss: 0.3993 - acc: 0.8235 - val_loss: 0.6151 - val_acc: 0.7100
Epoch 11/20
100/100 [==============================] - 94s 943ms/step - loss: 0.3813 - acc: 0.8230 - val_loss: 0.5362 - val_acc: 0.7320
Epoch 12/20
100/100 [==============================] - 94s 935ms/step - loss: 0.3498 - acc: 0.8425 - val_loss: 0.5774 - val_acc: 0.7310
Epoch 13/20
100/100 [==============================] - 92s 920ms/step - loss: 0.3236 - acc: 0.8605 - val_loss: 0.5733 - val_acc: 0.7340
Epoch 14/20
100/100 [==============================] - 95s 953ms/step - loss: 0.3032 - acc: 0.8660 - val_loss: 0.5799 - val_acc: 0.7390
Epoch 15/20
100/100 [==============================] - 92s 923ms/step - loss: 0.2848 - acc: 0.8825 - val_loss: 0.5906 - val_acc: 0.7270
Epoch 16/20
100/100 [==============================] - 105s 1s/step - loss: 0.2635 - acc: 0.8890 - val_loss: 0.6196 - val_acc: 0.7280
Epoch 17/20
100/100 [==============================] - 101s 1s/step - loss: 0.2432 - acc: 0.8985 - val_loss: 0.6222 - val_acc: 0.7290
Epoch 18/20
100/100 [==============================] - 101s 1s/step - loss: 0.2154 - acc: 0.9160 - val_loss: 0.6501 - val_acc: 0.7230
Epoch 19/20
100/100 [==============================] - 98s 978ms/step - loss: 0.2024 - acc: 0.9235 - val_loss: 0.6579 - val_acc: 0.7320
Epoch 20/20
100/100 [==============================] - 104s 1s/step - loss: 0.1818 - acc: 0.9340 - val_loss: 0.6598 - val_acc: 0.7260
model.save_weights("cats_and_dogs_small_1.h5")
6、绘制训练过程中的损失和精度曲线
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epoches = range(1, len(acc) + 1)
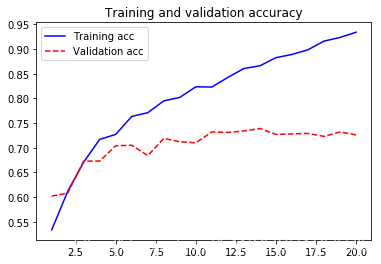
plt.plot(epoches, acc, 'b-', label='Training acc')
plt.plot(epoches, val_acc, 'r--',label='Validation acc')
plt.title("Training and validation accuracy")
plt.legend()
plt.show()
plt.plot(epoches, loss, 'b-', label='Training loss')
plt.plot(epoches, val_loss, 'r--',label='Validation loss')
plt.title("Training and validation loss")
plt.legend()
plt.show()
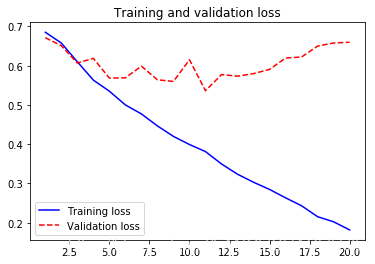
- 从上图中可以看出,大概在第5轮迭代开始便产生了过拟合。原因之一便是训练的数据太少了
7、数据增强
datagen = ImageDataGenerator(rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode= 'nearest'
)
from keras.preprocessing import image
fnames = [os.path.join(train_cats_dir, fname) for fname in os.listdir(train_cats_dir)]
img_path = fnames[3]
img = image.load_img(img_path, target_size=(150,150)) #读取图像并调整大小
x = image.img_to_array(img)
print(x.shape)
x = x.reshape((1,)+x.shape)# 将其转变为(1,150,150,3)
print(x.shape)
i = 0
plt.figure()
for batch in datagen.flow(x, batch_size=1):
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 ==0:
break
plt.show()
(150, 150, 3)
(1, 150, 150, 3)




8、使用Dropout技术
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
#重新定义一个包含dropout的模型
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)))#3*3*32*3+32
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3), activation='relu'))#3*3*64*32+64
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))#####################################
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
#编译模型
model.compile(optimizer=optimizers.RMSprop(lr=1e-4),
loss='binary_crossentropy',
metrics=['acc'])
#准备数据,使用数据增强生成器
# 对训练数据增强
datagen = ImageDataGenerator(rotation_range=40,
rescale=1./255,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode= 'nearest'
)
test_datagen = ImageDataGenerator(rescale=1./255)## 不可以对测试数据增强
train_generator = train_datagen.flow_from_directory(train_dir,
target_size=(150,150),#将目标文件调整为150*150
batch_size=32,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(validation_dir,
target_size=(150,150),
batch_size=32,
class_mode='binary')
history = model.fit_generator(train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
#model.save('cats_and_dogs_small2.h5')
说明
- 给实验在训练的过程中,在本人电脑上大概需要六个小时,因为中间电脑卡住,所以重新搭建了一个GPU的环境
- 使用GPU大概每轮只需要12s,100轮大概需要20分钟
- 只能说GPU真香

















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









