




 博客聚焦目标检测方向,指出当前检测存在网络不友好、正负样本失衡等问题。介绍了RetinaNet和Mask R-CNN等代表性成果,分析one-stage和two-stage检测器区别。还提出可改进点,如针对检测任务设计骨干网络、加速two-stage网络等,同时探讨了anchor-based和anchor-free算法的优缺点。
博客聚焦目标检测方向,指出当前检测存在网络不友好、正负样本失衡等问题。介绍了RetinaNet和Mask R-CNN等代表性成果,分析one-stage和two-stage检测器区别。还提出可改进点,如针对检测任务设计骨干网络、加速two-stage网络等,同时探讨了anchor-based和anchor-free算法的优缺点。
目标检测方向
- 大佬们都提到的当前检测遇到的问题
- 当前网络对检测不太友好,预训练一般在ImageNet等用来分类的数据库上
- 正负样本的失衡
- learning everything(anchor,NMS)
- anchor-based 和 anchor-free
- 检测的细节(小尺度物体和物体堆等)
- 俞刚《Beyond RetinaNet and Mask R-CNN》
参考:https://www.megvii.com/newscenter/e2da1146-7209-44b1-aac5-1f4aab6d091a- 目标检测本质上同时在做定位和分类两个任务。
- 目标检测的目的在于又快又准,快在于实时性,准体现在定位准和分类准。
- 当前主要的检测的细节仍需完善,如小物体检测、物体堆识别等。
- RetinaNet 和 Mask R-CNN 是 2017 年出现的两个非常有代表性的成果, 两者分别是 one-stage 和 two-stage 的,共同奠定了目标检测框架的基调。
RetinaNet:https://arxiv.org/abs/1708.02002
《Mask R-CNN》:https://arxiv.org/abs/1703.06870 - one-stage 和 two-stage 检测器之间的本质区别在于检出率(recall)与定位(localization)之间的权衡(tradeoff)。
- 当前可改进的点:
- 当前主干网络多基于ImageNet分类任务来设计,所以可以考虑针对检测任务设计骨干网络,朝着兼得感受野和空间分辨率的方向而努力。
- 对于two-stage网络,当前主要的目标是加速,可以通过减小骨干网络,把head变为轻量级等方式。
- 检测中物体尺寸差异较大,如何在尺寸变化与推断速度之间实现一个很好的权衡,结合了anchor-based和anchor-free的方法,
- 物体检测的batchsize都比较小,MegDet
- 真实场景中 crowd 情况非常多,引入了一个新数据集——CrowdHuman。
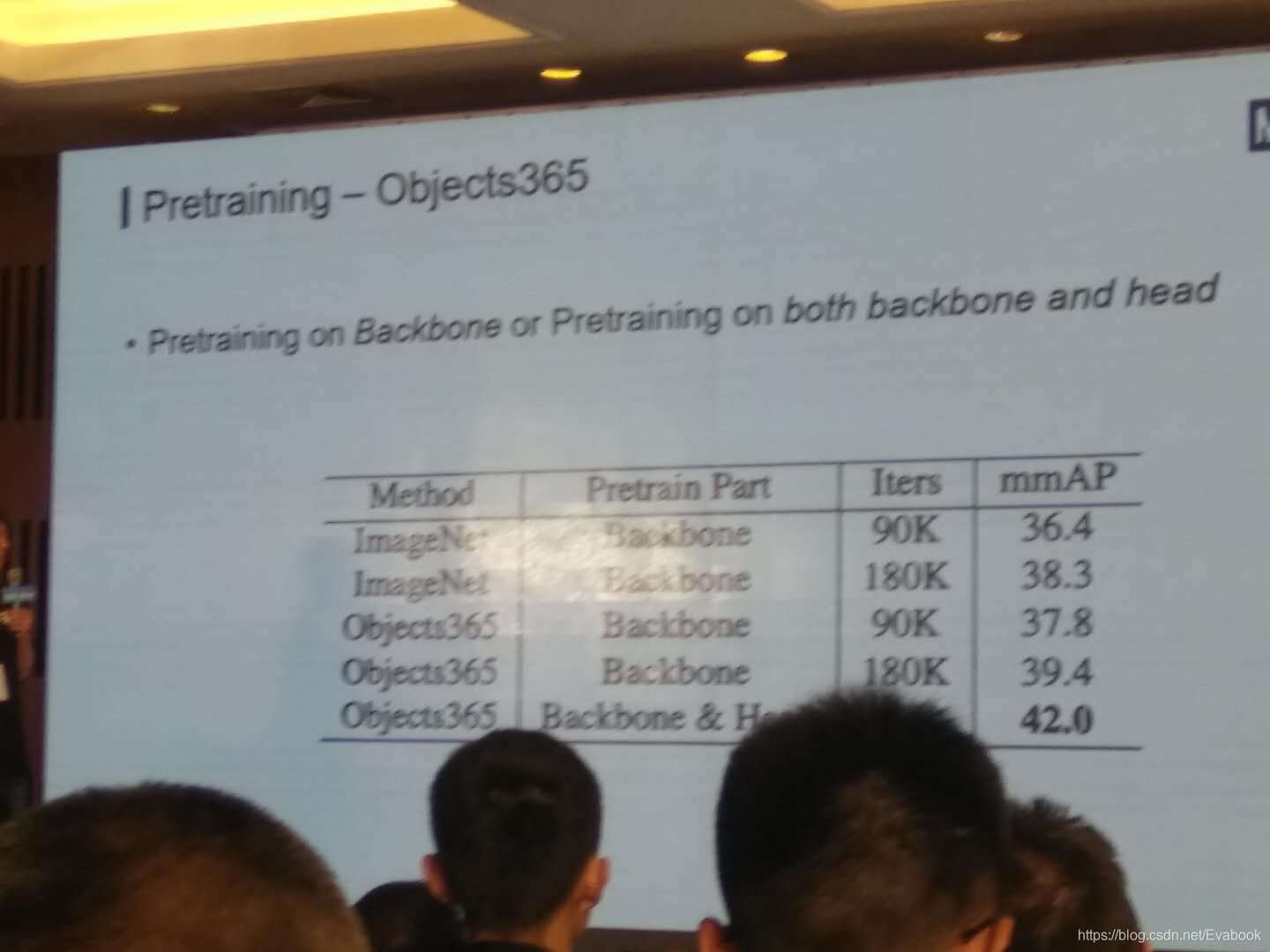
- 新增-pretraining

预训练可以节省训练时间,且提出了名为Objects365的数据库用来预训练效果会比ImageNet更好,更适合于检测问题。
目标检测算法总结博客:https://www.cnblogs.com/guoyaohua/p/8994246.html
- 张士峰《物体检测算法的对比探索以及展望》
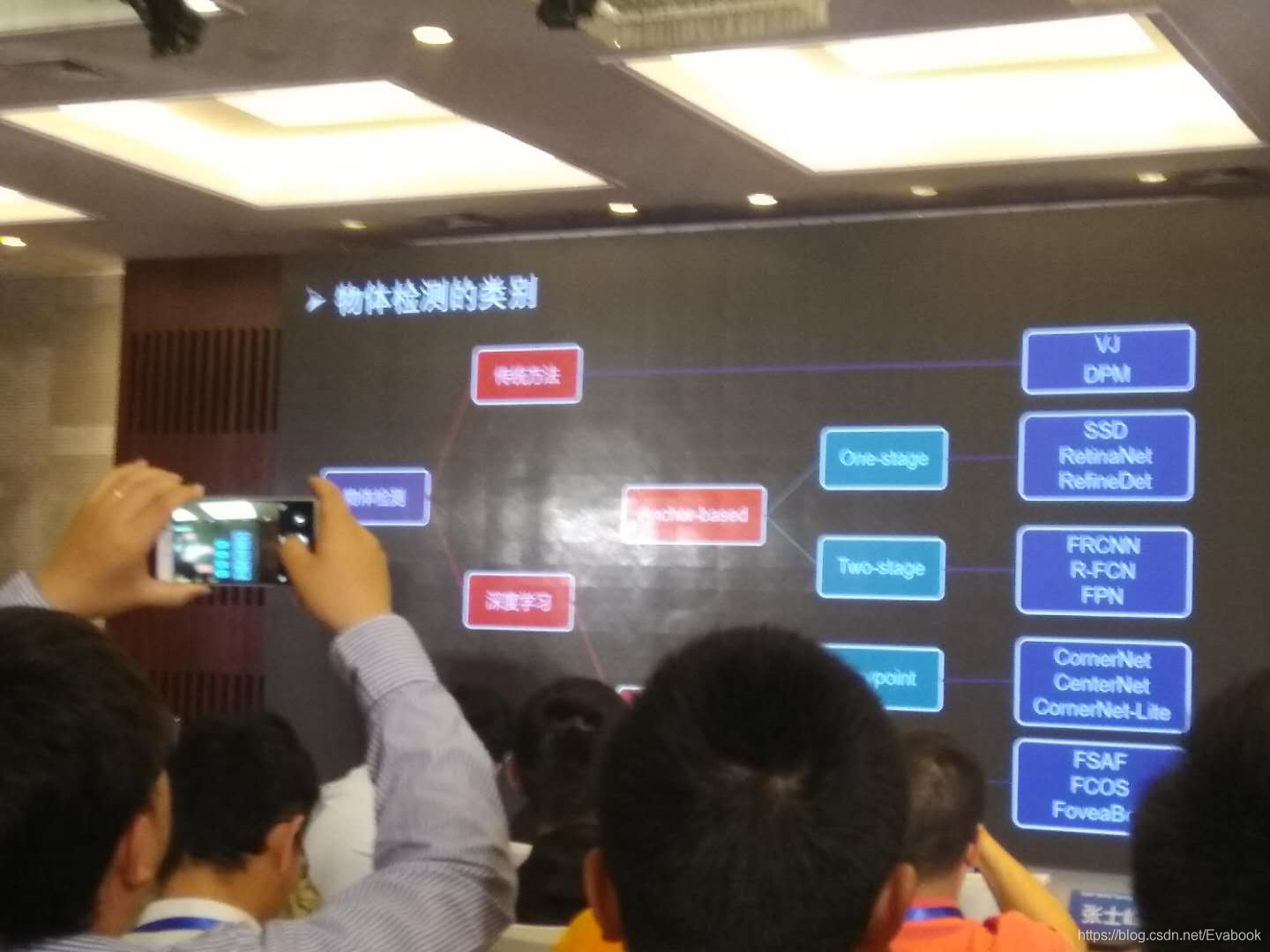
- 物体检测的分类
- RefineDet演变
anchor-based里one-stage和two-stage各有优缺点,two stage的优势在于它有两次的特征,分类和检测,所以精度较高,但one-stage的速度较高
基于此,就提出来RefineDet,结合两种模式的优缺点,ARM部分负责用来得到bbox(类似Faster R-CNN中的ROI或proposal)和去除一些负样本,ODM采用ARM产生的refined anchors作为输入,进一步改善回归和预测多类标签。
 后发现浅层网络的ODM模块,浅层更适合用来分类,深层部分更适合用来回归框架结构,因此提出SRN
后发现浅层网络的ODM模块,浅层更适合用来分类,深层部分更适合用来回归框架结构,因此提出SRN

- anchor-based 算法缺点
- 与锚点相关的超参(scale、aspect ratio、IOU Threshold)必须被小心选择,否则会较明显的影响最终预测效果
- 预置的锚点大小、比例在检测差异较大物体时不够灵活,且在迁移数据后需要重新设计
- 较高召回率,多个锚点box被紧密排列,而绝大多数锚点都被标定为negative,这样会导致正负样本比例失衡
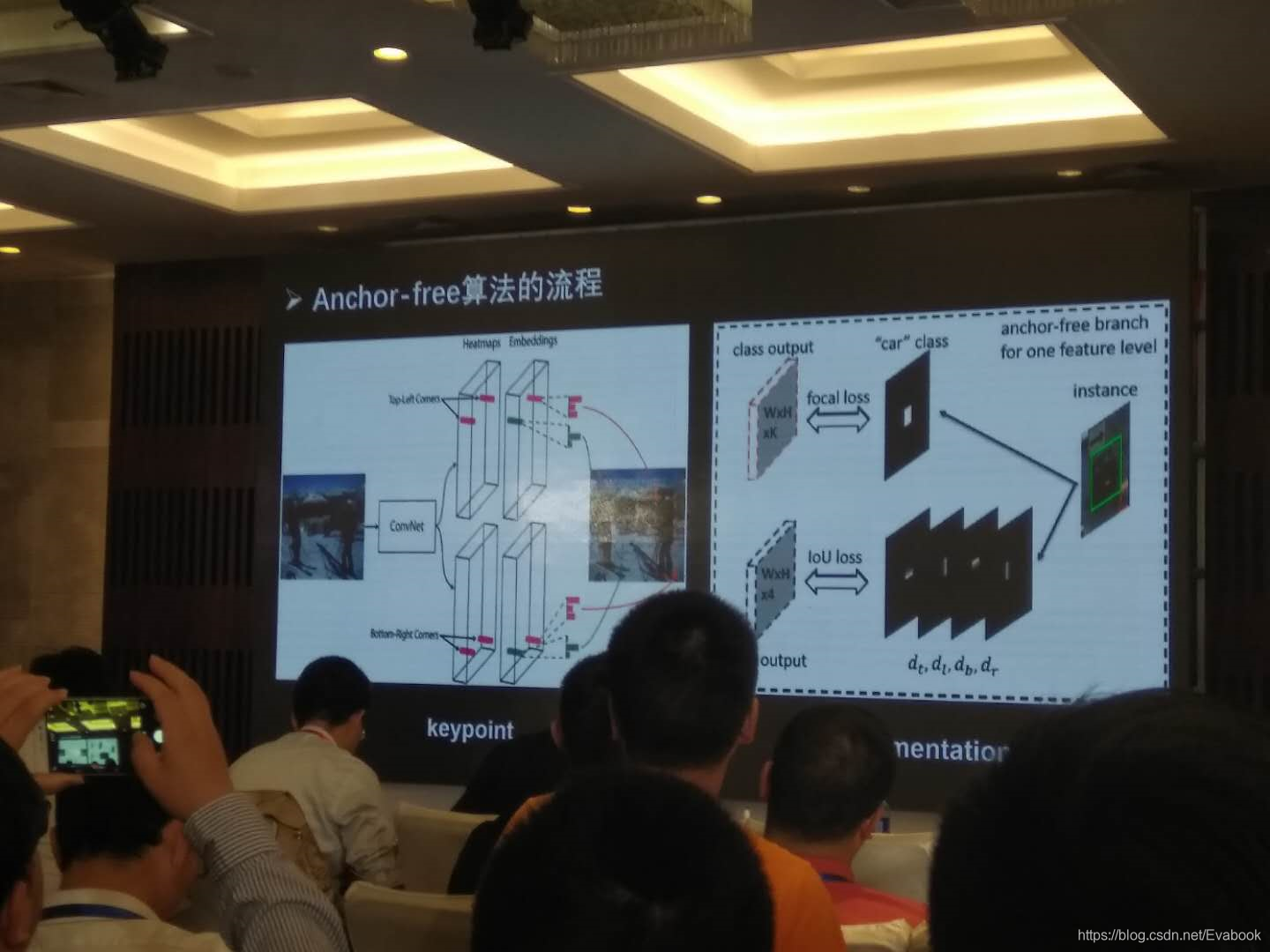
- anchor-free的算法:基于keypioint和基于segmentation
但anchor-free也存在自身的问题,如如何配对keypoint等
- 物体检测的分类
- 程明明《开放环境下的自适应视觉感知》
- 富尺度空间深度神经网络通用架构,层内分层分组递进残差连接。

- 通用视觉基元属性感知(基元属性:显著性、边缘、对比度等一系列图像中的固有属性,该属性不具有针对某种特定任务的性质)
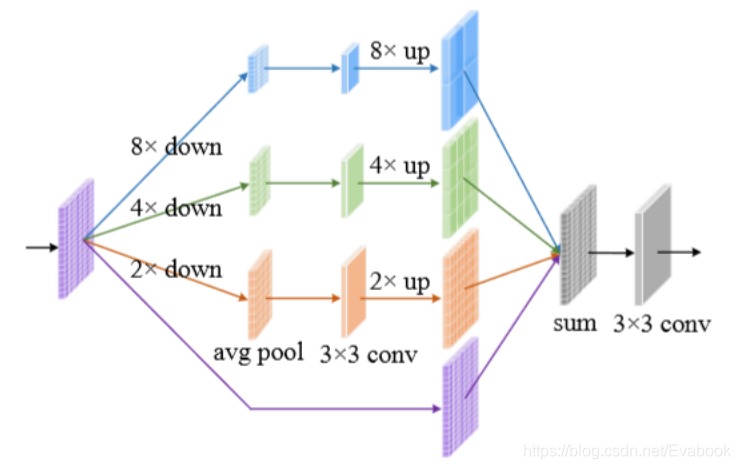
显著性物体检测(A Simple Pooling-Based Design for Real-Time Salient Object Detection)
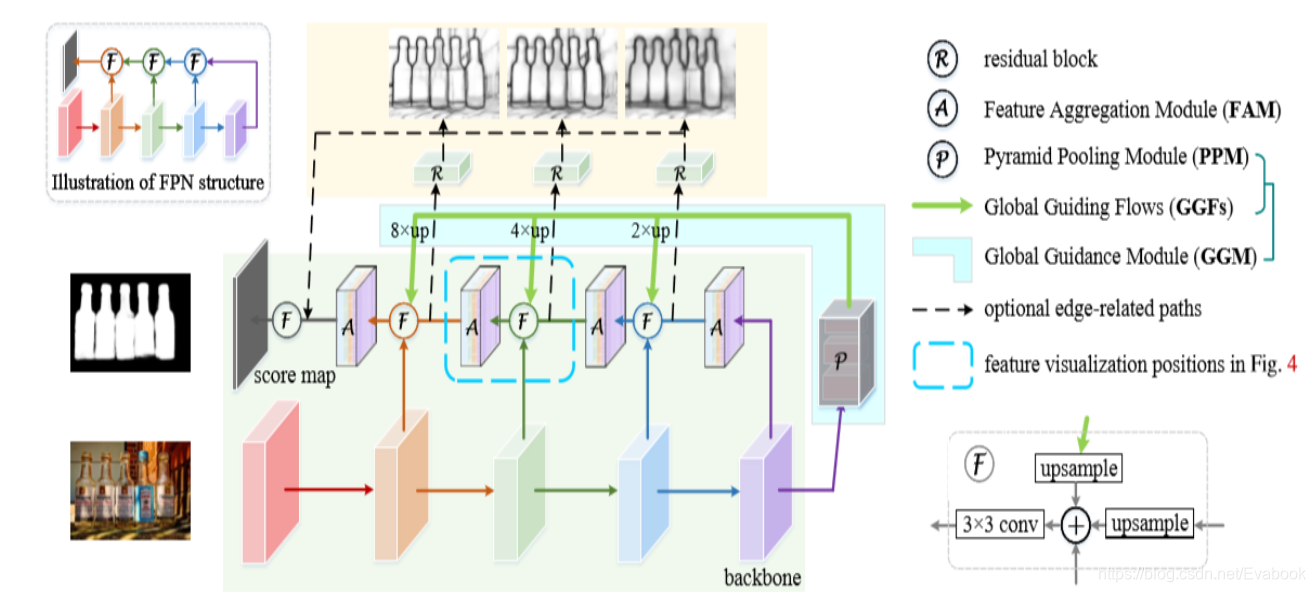
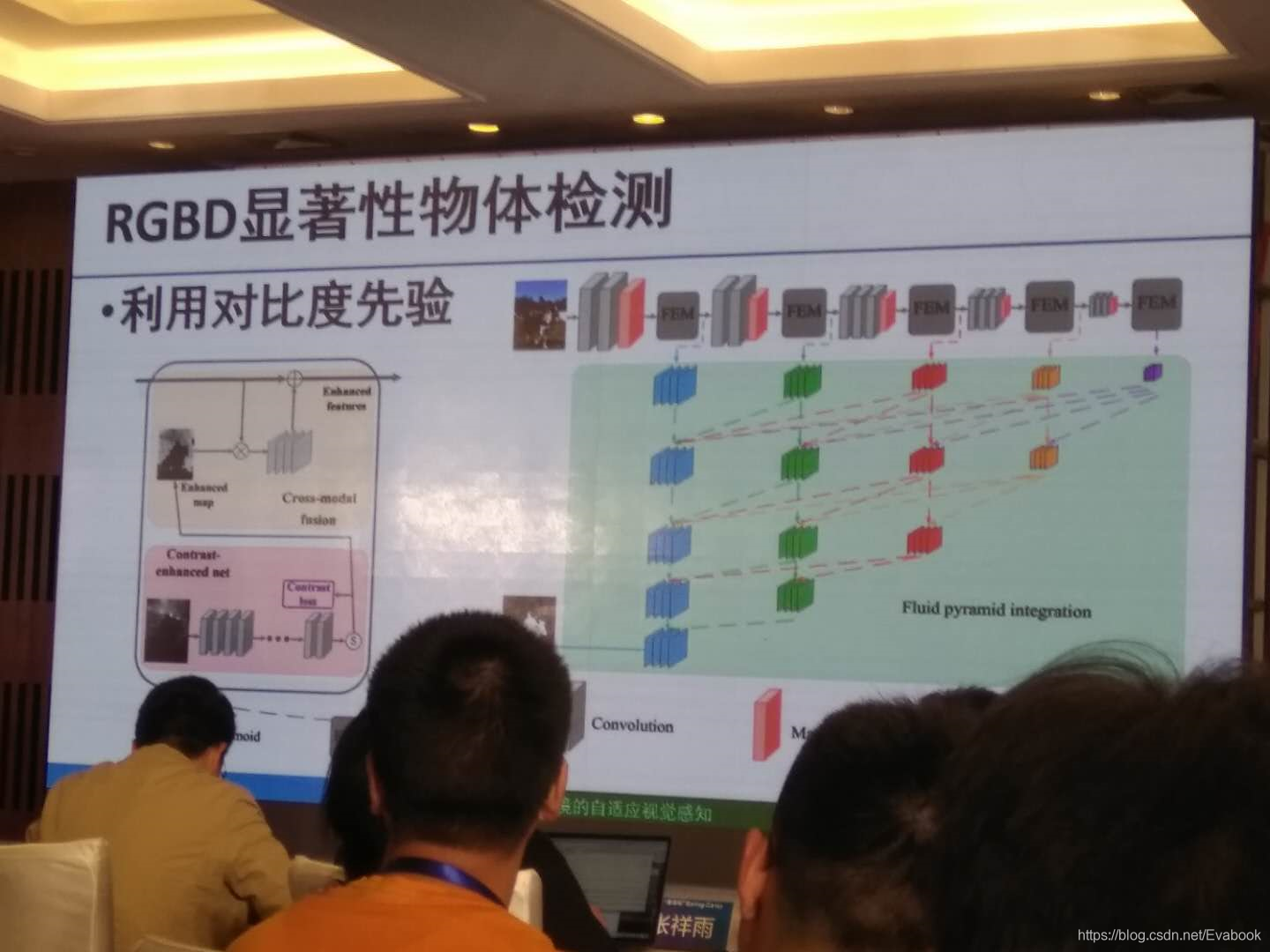
 Contrast Prior and Fluid Pyramid Integration for RGBD Salient Object Detection(RGBD显著性物体检测)
Contrast Prior and Fluid Pyramid Integration for RGBD Salient Object Detection(RGBD显著性物体检测)
- 关键机器学习算法到多种行业应用

- 总结

- 富尺度空间深度神经网络通用架构,层内分层分组递进残差连接。

















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









