








📝个人主页🌹:Eternity._
🌹🌹期待您的关注 🌹🌹


概述
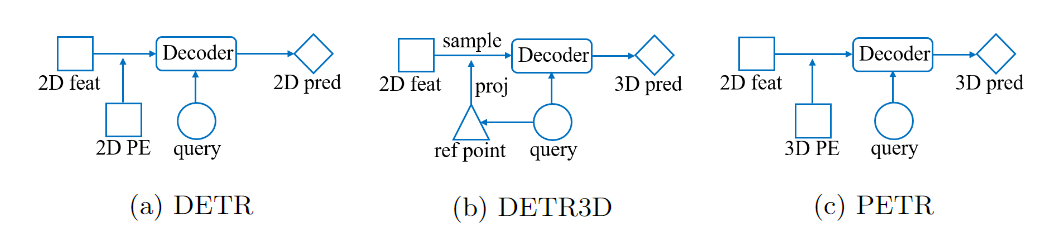
多视角图像中的3D目标检测由于其在自动驾驶系统中的低成本而具有吸引力。
- 在DETR中,每个对象查询表示一个对象,与Transformer解码器中的2D特征交互以产生预测的结果。
- 在DETR3D中,由对象查询预测的3D参考点通过相机参数投影回图像空间,并对2D特征进行采样,以与解码器中的对象查询进行交互。
- PETR通过将3D位置嵌入编码到2D图像特征中生成3D位置感知特征,对象查询直接与3D位置感知特征交互,并输出3D检测结果。
PETR体系结构具有许多优点,它既保留了原始DETR的端到端的方式,又避免了复杂的2D到3D投影和特征采样。
本文所涉及的所有资源的获取方式:这里
模型结构
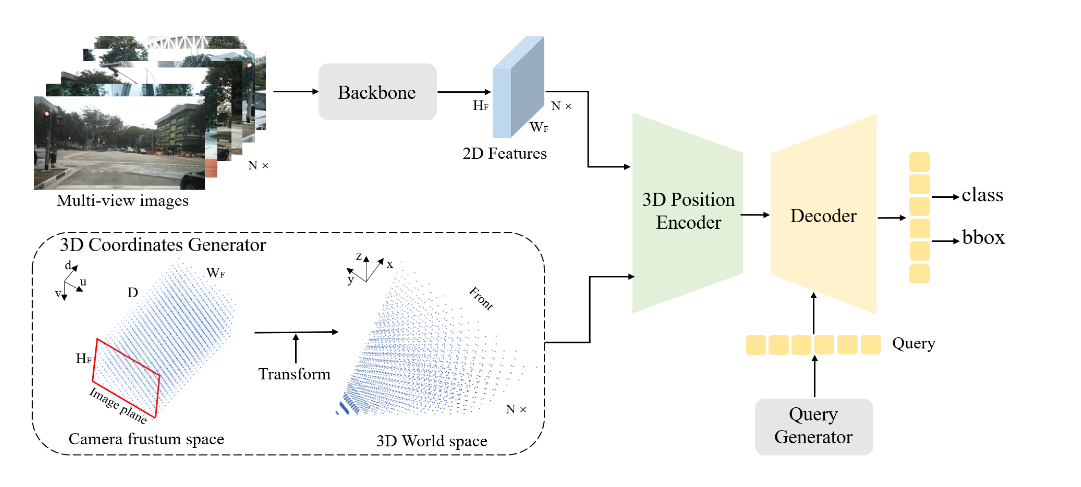

3D坐标生成器

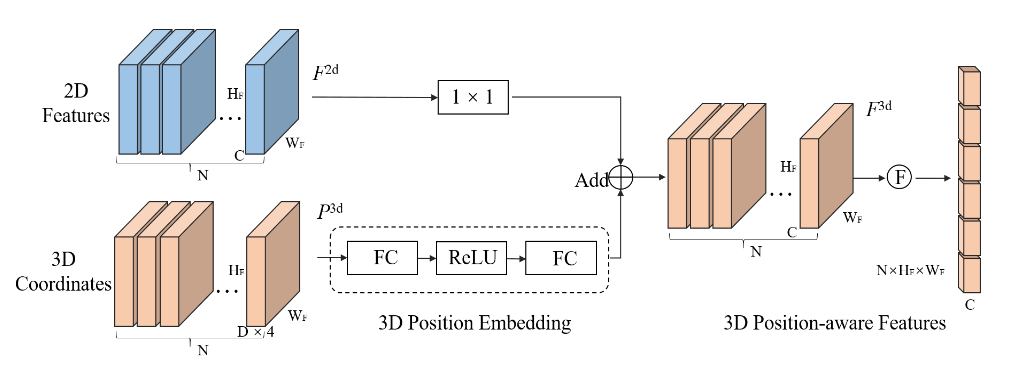
3D位置编码器

查询生成器和解码器

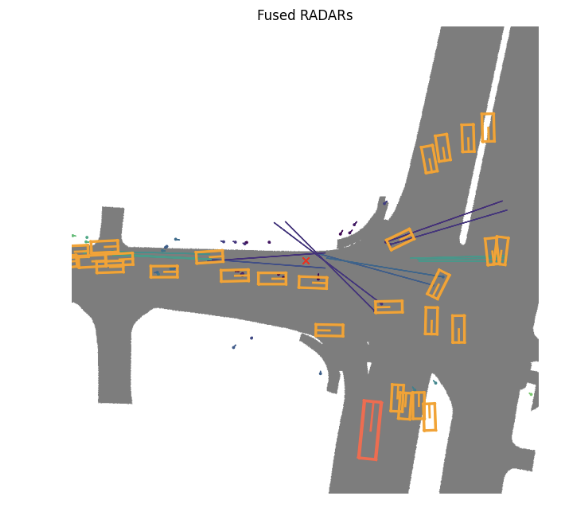
演示效果
其中红色边界框表示自车车辆
Radar结果
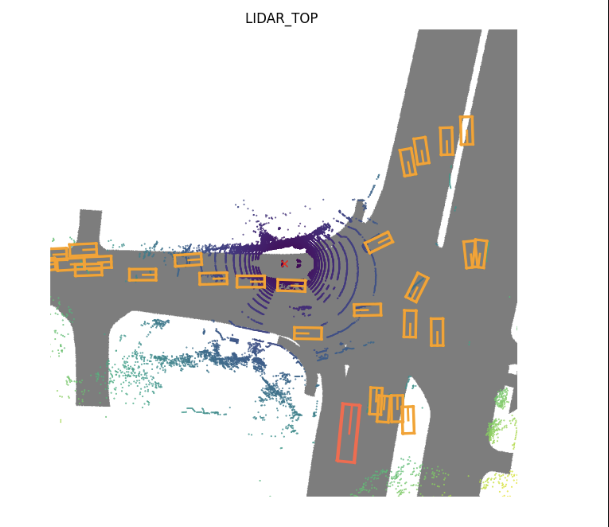
lidar 结果
6个相机的结果

核心逻辑
生成3D位置坐标
def position_embeding(self, img_feats, img_metas, masks=None):
eps = 1e-5
# 首先将所有的特征图都填充到原始图像的大小
pad_h, pad_w, _ = img_metas[0]['pad_shape'][0]
# 在特征图较大的情况下来获取它的位置信息
B, N, C, H, W = img_feats[self.position_level].shape
# 32但是每个间隔维16,因此定义每个图像放大的倍数为16的形式
coords_h = torch.arange(H, device=img_feats[0].device).float() * pad_h / H
coords_w = torch.arange(W, device=img_feats[0].device).float() * pad_w / W
if self.LID:
# 此时定义的是深度信息,目的是为了转换吗
index = torch.arange(start=0, end=self.depth_num, step=1, device=img_feats[0].device).float()
index_1 = index + 1
# 获得每个网格的深度箱的大小,但是为什么还要除以65
bin_size = (self.position_range[3] - self.depth_start) / (self.depth_num * (1 + self.depth_num))
# 此时的结果也是64,但是此时深度箱的大小用来表示什么
coords_d = self.depth_start + bin_size * index * index_1
else:
index = torch.arange(start=0, end=self.depth_num, step=1, device=img_feats[0].device).float()
bin_size = (self.position_range[3] - self.depth_start) / self.depth_num
coords_d = self.depth_start + bin_size * index
D = coords_d.shape[0]
# [3,88,32,64]->[88,32,64,3] 通过将特征图进行离散化形成坐标来生成网格和视锥的形式
coords = torch.stack(torch.meshgrid([coords_w, coords_h, coords_d])).permute(1, 2, 3, 0) # W, H, D, 3
# 生成齐次坐标系,获得[x,y,z,1]形式的坐标
coords = torch.cat((coords, torch.ones_like(coords[..., :1])), -1)
# [88,32,64,2] x,y处也包含了深度的信息torch.tensor
coords[..., :2] = coords[..., :2] * torch.maximum(coords[..., 2:3], torch.ones_like(coords[..., 2:3])*eps)
img2lidars = []
for img_meta in img_metas:
img2lidar = []
# 针对6副图像,使用np将旋转矩阵的逆求解处出来
for i in range(len(img_meta['lidar2img'])):
img2lidar.append(np.linalg.inv(img_meta['lidar2img'][i]))
# 将一个batch内的图像到雷达的数据计算出来
img2lidars.append(np.asarray(img2lidar))
# [1,6,4,4]
img2lidars = np.asarray(img2lidars)
# 使img2lidars获得coords相同的类型和device情况
img2lidars = coords.new_tensor(img2lidars) # (B, N, 4, 4)
# [1,1,88,32,64,4,1]->[1,6,88,32,64,4,1]
coords = coords.view(1, 1, W, H, D, 4, 1).repeat(B, N, 1, 1, 1, 1, 1)
# [1,6,1,1,1,4,4,4]->[1,6,88,32,64,4,4]
img2lidars = img2lidars.view(B, N, 1, 1, 1, 4, 4).repeat(1, 1, W, H, D, 1, 1)
# 6个图像分别进行相乘形成新的坐标系,从相机视锥空间生成6个视图现实空间的坐标。
# 并且只选取x,y,z三个数据
coords3d = torch.matmul(img2lidars, coords).squeeze(-1)[..., :3]
# 位置坐标来进行归一化处理,pos_range是3D感兴趣区域,先前都设置好了
coords3d[..., 0:1] = (coords3d[..., 0:1] - self.position_range[0]) / (self.position_range[3] - self.position_range[0])
coords3d[..., 1:2] = (coords3d[..., 1:2] - self.position_range[1]) / (self.position_range[4] - self.position_range[1])
coords3d[..., 2:3] = (coords3d[..., 2:3] - self.position_range[2]) / (self.position_range[5] - self.position_range[2])
# 除去不再目标范围内的数据
coords_mask = (coords3d > 1.0) | (coords3d < 0.0)
# [1,6,88,32,64,3]->[1,6,88,32,192]->[1,6,88,32] 设定一个阈值,超过该阈值我们不再需要
coords_mask = coords_mask.flatten(-2).sum(-1) > (D * 0.5)
# 当取值为1的时候,此时是我们希望屏蔽的数据
coords_mask = masks | coords_mask.permute(0, 1, 3, 2)
# [1,6,88,32,64,3]->[1,6,64,3,32,88]->[6,192,32,88]
coords3d = coords3d.permute(0, 1, 4, 5, 3, 2).contiguous().view(B*N, -1, H, W)
# 将其转换为现实世界的坐标
coords3d = inverse_sigmoid(coords3d)
# embedding_dim是depth的四倍
coords_position_embeding = self.position_encoder(coords3d)
return coords_position_embeding.view(B, N, self.embed_dims, H, W), coords_mask
PETR主体部分
def forward(self, mlvl_feats, img_metas):
"""Forward function.
Args:
mlvl_feats (tuple[Tensor]): Features from the upstream
network, each is a 5D-tensor with shape
(B, N, C, H, W).
Returns:
all_cls_scores (Tensor): Outputs from the classification head, \
shape [nb_dec, bs, num_query, cls_out_channels]. Note \
cls_out_channels should includes background.
all_bbox_preds (Tensor): Sigmoid outputs from the regression \
head with normalized coordinate format (cx, cy, w, l, cz, h, theta, vx, vy). \
Shape [nb_dec, bs, num_query, 9].
"""
# 因为此时两者的结构式一致的,因此选择第一个,且选择特征图较大的情况、
x = mlvl_feats[0]
batch_size, num_cams = x.size(0), x.size(1)
# batch为1,且6个相机视角,每个视角下的大小都一致,因此选取第一个的形式
input_img_h, input_img_w, _ = img_metas[0]['pad_shape'][0]
masks = x.new_ones( # [1,6,512,1408] 不太确定此时的mask用来遮挡什么物体
(batch_size, num_cams, input_img_h, input_img_w))
for img_id in range(batch_size):
for cam_id in range(num_cams):
img_h, img_w, _ = img_metas[img_id]['img_shape'][cam_id]
masks[img_id, cam_id, :img_h, :img_w] = 0
# x.flatten(0,1)将第0维到第1维拍成第0维,其余保持不变
# x: [1,6,256,32,88]->[6,256,32,88]->[6,256,32,88] 不理解input的目的,是为了多加一个非线性吗
x = self.input_proj(x.flatten(0,1))
x = x.view(batch_size, num_cams, *x.shape[-3:])
# interpolate masks to have the same spatial shape with x [1,6,512,1408]->[1,6,32,88]
# 在mask上进行采样,生成新的mask的形式,但此时mask的作用是什么呢
masks = F.interpolate(
masks, size=x.shape[-2:]).to(torch.bool)
if self.with_position:
# pos_embedding是PETR的重点,包含了坐标系的转换等一系列 此时生成的是3D位置嵌入
coords_position_embeding, _ = self.position_embeding(mlvl_feats, img_metas, masks)
pos_embed = coords_position_embeding
# 如果具有多个视角,那么不同的视角也需要使用位置编码来进行操作
if self.with_multiview:
# [1,6,32,88]->[1,6,384,32,88]->[1,6,256,32,88]
sin_embed = self.positional_encoding(masks)
sin_embed = self.adapt_pos3d(sin_embed.flatten(0, 1)).view(x.size())
pos_embed = pos_embed + sin_embed
else:
pos_embeds = []
for i in range(num_cams):
xy_embed = self.positional_encoding(masks[:, i, :, :])
pos_embeds.append(xy_embed.unsqueeze(1))
sin_embed = torch.cat(pos_embeds, 1)
sin_embed = self.adapt_pos3d(sin_embed.flatten(0, 1)).view(x.size())
pos_embed = pos_embed + sin_embed
else:
if self.with_multiview:
pos_embed = self.positional_encoding(masks)
pos_embed = self.adapt_pos3d(pos_embed.flatten(0, 1)).view(x.size())
else:
pos_embeds = []
for i in range(num_cams):
pos_embed = self.positional_encoding(masks[:, i, :, :])
pos_embeds.append(pos_embed.unsqueeze(1))
pos_embed = torch.cat(pos_embeds, 1)
# [900,3] pos2posemb3d: [900,384]
reference_points = self.reference_points.weight
# 针对每个query形成一个嵌入的形式[900,256],线形层来生成查询
query_embeds = self.query_embedding(pos2posemb3d(reference_points))
# query是直接从Embedding生成 [1,900,3]
reference_points = reference_points.unsqueeze(0).repeat(batch_size, 1, 1) #.sigmoid()
# 利用transformer架构来获取query填充后的信息,之后用于计算class和bbox
outs_dec, _ = self.transformer(x, masks, query_embeds, pos_embed, self.reg_branches)
# 通过nan_to_num()将NaN转换为可处理的数字 [6,1,900,256]
outs_dec = torch.nan_to_num(outs_dec)
outputs_classes = []
outputs_coords = []
for lvl in range(outs_dec.shape[0]):
reference = inverse_sigmoid(reference_points.clone())
assert reference.shape[-1] == 3
outputs_class = self.cls_branches[lvl](outs_dec[lvl])
tmp = self.reg_branches[lvl](outs_dec[lvl])
tmp[..., 0:2] += reference[..., 0:2]
tmp[..., 0:2] = tmp[..., 0:2].sigmoid()
tmp[..., 4:5] += reference[..., 2:3]
tmp[..., 4:5] = tmp[..., 4:5].sigmoid()
outputs_coord = tmp
outputs_classes.append(outputs_class)
outputs_coords.append(outputs_coord)
all_cls_scores = torch.stack(outputs_classes)
all_bbox_preds = torch.stack(outputs_coords)
# 转换为3D场景下的数据
all_bbox_preds[..., 0:1] = (all_bbox_preds[..., 0:1] * (self.pc_range[3] - self.pc_range[0]) + self.pc_range[0])
all_bbox_preds[..., 1:2] = (all_bbox_preds[..., 1:2] * (self.pc_range[4] - self.pc_range[1]) + self.pc_range[1])
all_bbox_preds[..., 4:5] = (all_bbox_preds[..., 4:5] * (self.pc_range[5] - self.pc_range[2]) + self.pc_range[2])
outs = {
'all_cls_scores': all_cls_scores,
'all_bbox_preds': all_bbox_preds,
'enc_cls_scores': None,
'enc_bbox_preds': None,
}
return outs
部署方式
# 新建一个虚拟环境
conda activate petr
# 下载cu111 torch1.9.0 python=3.7 linux系统
wget https://download.pytorch.org/whl/cu111/torch-1.9.0%2Bcu111-cp37-cp37m-linux_x86_64.whl
pip install 'torch下载的位置'
wget https://download.pytorch.org/whl/cu111/torchvision-0.10.0%2Bcu111-cp37-cp37m-linux_x86_64.whl
pip install 'torchvison下载的地址'
# 安装MMCV
pip install mmcv-full==1.4.0 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.html
# 安装MMDetection
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection
git checkout v2.24.1
sudo pip install -r requirements/build.txt
sudo python3 setup.py develop
cd ..
# 安装MMsegmentation
sudo pip install mmsegmentation==0.20.2
# 安装MMdetection 3D
git clone https://github.com/open-mmlab/mmdetection3d.git
cd mmdetection3d
git checkout v0.17.1
sudo pip install -r requirements/build.txt
sudo python3 setup.py develop
cd ..
# 安装PETR
git clone https://github.com/megvii-research/PETR.git
cd PETR
mkdir ckpts ###pretrain weights
mkdir data ###dataset
ln -s ../mmdetection3d ./mmdetection3d
ln -s /data/Dataset/nuScenes ./data/nuscenes
参考文件
编程未来,从这里启航!解锁无限创意,让每一行代码都成为你通往成功的阶梯,帮助更多人欣赏与学习!
更多内容详见:这里

















 173
173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









