






 探讨在MATLAB中使用CNN进行图像分类时遇到的验证集精度陡降问题。分析了BatchNormalizationStatistics训练选项对模型精度的影响,特别是'population'模式导致的验证集精度变化。
探讨在MATLAB中使用CNN进行图像分类时遇到的验证集精度陡降问题。分析了BatchNormalizationStatistics训练选项对模型精度的影响,特别是'population'模式导致的验证集精度变化。
开坑 关于MATLAB 使用CNN进行图像分类时,训练输出的验证集精度会陡降的问题
问题描述
如图所示,蓝色线代表训练集精度,黑色圆点是验证集精度,在训练的时候二者精度都比较高,但是最后输出的模型(图中红框所示)是这样的,抖降到了84.8%,这个就很奇怪。
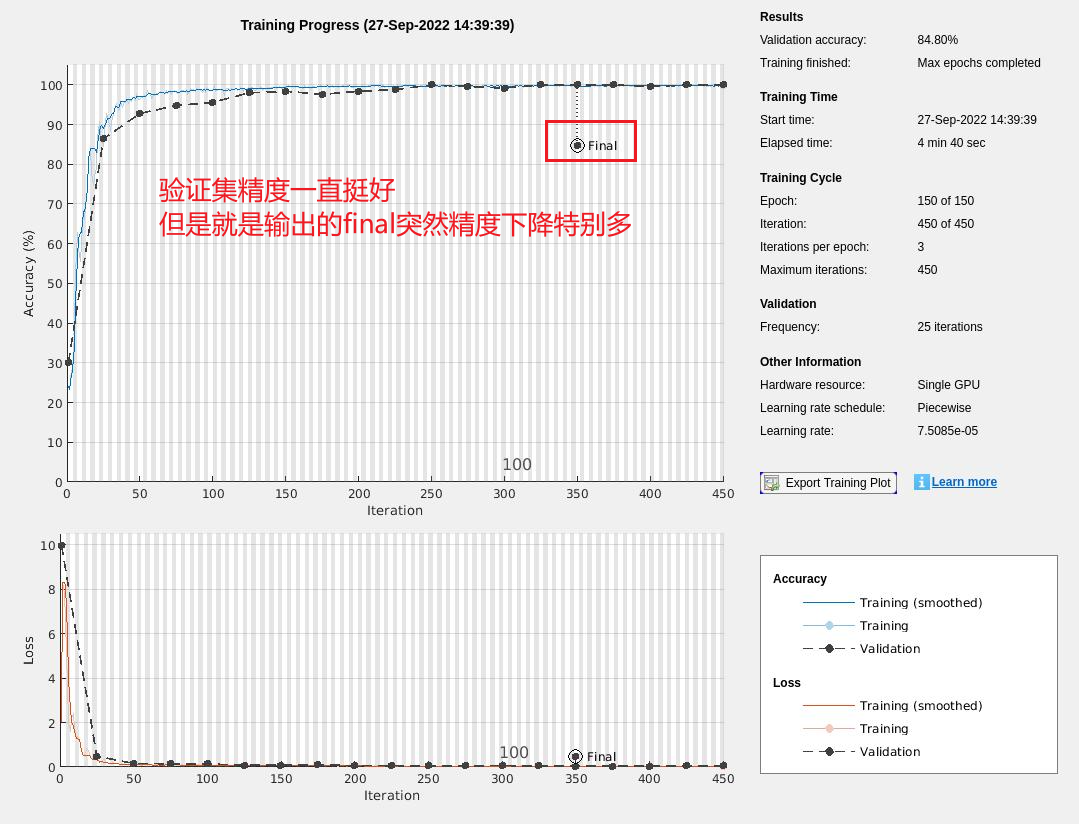
原因探究
对于这个问题我暂时还没找到原因,所以记录一下阶段性的研究结果。
MATLAB官方文档查阅
通过查阅MATLAB官方文档trainNetwork词条页面中的Output Argument - info词条,发现有如下描述:
For networks containing batch normalization layers, if the BatchNormalizationStatistics training option is ‘population’ then the final validation metrics are often different from the validation metrics evaluated during training. This is because batch normalization layers in the final network perform different operations than during training. For more information, see batchNormalizationLayer.
翻译过来就是:
对于就有BN层的网络,如果BatchNormalizationStatistics这个训练选项设置为’population’,那么最终验证集的度量时常会与训练时的验证度量评估不同。这是因为BN层在最终网络中与在训练时相比,进行了不同的操作。对于更多的信息,查看batchNormalizationLayer词条。
我对这句话的理解的大致意思就是这个训练选项影响了最终输出的模型验证集精度,但是具体怎么影响的没有具体说明。
我们下面查看MATLAB官方文档trainingOptions中Solver Options部分对于BatchNormalizationStatistics训练选项的描述

翻译过来:
评估BN层中统计数据的模式,指定为一下一种:
‘population’ - 使用population统计数据,在训练之后,软件通过再次pass through训练数据并使用结果均值和方差来最终确定统计数据。
‘moving’ - 使用更新步骤给出的运行估算,近似训练期间的统计数据,并且按照下式更新
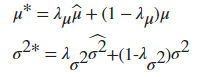
到这里还是有点迷糊这两个模式有啥区别,我们再往下看,看MATLAB官方文档中对batchNormalizationLayer的说明,
在 TrainedMean 和 TrainedVariance 两个词条的介绍中有两段对于BatchNormalizationStatistics这个训练选项的说明
(TrainedMean 和 TrainedVariance 应该指的就是一个batch中每个通道的平均值和方差,注意:这两个不是可训练参数,可训练参数是scale 和 offset)
If the BatchNormalizationStatistics training option is ‘moving’, then the software approximates the batch normalization statistics during training using a running estimate and, after training, sets the TrainedMean and TrainedVariance properties to the latest values of the moving estimates of the mean and variance, respectively.
If the BatchNormalizationStatistics training option is ‘population’, then after network training finishes, the software passes through the data once more and sets the TrainedMean and TrainedVariance properties to the mean and variance computed from the entire training data set, respectively.
翻译过来
如果BatchNormalizationStatistics训练选项是’moving’,软件在训练期间使用“滑动估算”来近似BN的统计数据,并且,在训练过后,将TrainedMean和TrainedVariance特征分别设置为方差和均值滑动估计的最新值。
如果BatchNormalizationStatistics训练选项是’population’,那么在网络训练结束之后,软件再次pass through数据,并把TrainedMean和TrainedVariance特征分别设置为整个训练集中计算得到的均值和方差。
再往下看
在 MeanDecay 和 VarianceDecay 词条下也有两段对于BatchNormalizationStatistics的说明

意思是当 BatchNormalizationStatistics 的训练选项为 ‘moving’ 时,在每个iteration,层使用下面这两个式子更新滑动平均值和滑动方差值。
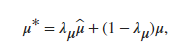
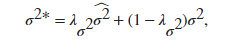
而当 BatchNormalizationStatistics 的训练选项为 ‘population’ 时,MeanDecay和VarianceDecay选项不起作用。
个人理解
那也就是说,当训练选项是’moving’的时候,每一个iteration都会对mean和variance进行一次额外的计算,这个计算叫做滑动平均,下面以均值为例(方差道理一样)
λ
μ
\lambda_\mu
λμ —— 是上文中的MeanDecay,
1
−
λ
μ
1-\lambda_\mu
1−λμ貌似也叫动量参数
μ
^
\widehat{\mu}
μ
—— 是层输入的均值
μ
\mu
μ —— 是最新的滑动平均值
μ
∗
\mu^\ast
μ∗ —— 更新过后的平均值
在这种模式下应该是以
μ
∗
\mu^\ast
μ∗作为BN层归一化时候的平均值。
如果使用’population’模式,那么就应该是直接计算batch每一个通道的平均值作为归一化时候的平均值。
两种模式的不同就体现在平均值和方差的不同计算方法上。
两种模式与输出验证集精度的关系
搞清楚了两种模式的不同,那么这些设置和一开始提出的输出验证集精度下降有什么关系呢?
如果BatchNormalizationStatistics训练选项是’population’,那么在网络训练结束之后,软件再次pass through数据,并把TrainedMean和TrainedVariance特征分别设置为整个训练集中计算得到的均值和方差。
从官方文档的这句话可以看出,训练结束之后,输出的BN层的均值和方差和最后一次验证的验证集的BN层的均值和方差不一样,因为输出的均值和方差是再次利用了整个训练集的数据计算得来的均值和方差。这应该就是使用’population’模式最终输出的验证集有可能会陡降的原因。
验证
我将BatchNormalizationStatistics训练选项设置为’moving’,貌似是情况好了一点,但实际上跑几次程序还是会出现陡降的问题,暂时不知道怎么回事。

















 1395
1395





 到【灌水乐园】发言
到【灌水乐园】发言







