










1.为什么要使用sleuth?
在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的的服务节点调用来协同产生最后的请求结果,每一个次请求都会形成一条复杂的分布式服务调用链路,链路中的任何一环出现高延时或错误都会引起整个请求最后的失败。sleuth则将服务之间的调用记录起来,使服务之间的调用关系清晰明了,方便排查问题(主要是生成一个traceId,表示这次请求的id)
2.sleuth是怎么做的?
将跟踪和跨度 ID 添加到 Slf4J,因此您可以从日志聚合器中的给定跟踪或跨度中提取所有日志。
检测来自 Spring 应用程序的公共入口和出口点(servlet filter, rest template, scheduled actions, message channels, feign client)。
如果spring-cloud-sleuth-zipkin可用,则应用程序将通过 HTTP生成和报告与Zipkin兼容的跟踪。默认情况下,它将它们发送到 localhost(端口 9411)上的 Zipkin 收集器服务。使用spring.zipkin.baseUrl配置Zipkin 服务的位置。
3.zipkin是做什么的?
Spring Cloud Sleuth对于分布式链路的跟踪仅仅是生成一些数据,这些数据不便于人类阅读,所以我们一般把这种跟踪数据上传给Zipkin Server,由Zipkin通过UI页面统一进行数据的展示。
4.使用
三个子模块,consumer provider, consumer调用provider
父pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.levi</groupId>
<artifactId>sleuth</artifactId>
<packaging>pom</packaging>
<version>1.0-SNAPSHOT</version>
<modules>
<module>provider</module>
<module>consumer</module>
<module>third</module>
</modules>
<properties>
<java.version>1.8</java.version>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<springboot.version>2.6.8</springboot.version>
<springcloud.version>2021.0.3</springcloud.version>
<lombok.version>1.18.24</lombok.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${springboot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${springcloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<finalName>${project.artifactId}</finalName>
<resources>
<resource>
<directory>src/main/resources</directory>
<filtering>true</filtering>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
<encoding>${project.build.sourceEncoding}</encoding>
</configuration>
</plugin>
</plugins>
</build>
</project>
每个子模块的依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
<version>2.2.8.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<!-- 引入 rabbitmq 依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
yml配置文件,注意修改应用名称和端口,sleuth给zipkin发送数据使用的是http,并发量大的话可能会占用大量线程,这里使用rabbitmq,sleuth先把数据发送到rabbitmq,zipkin从rabbitmq进行消费
server:
port: 8082
spring:
application:
name: sleuth-consumer
zipkin:
base-url: http://ip:9411/ # 指定zipkin地址
sender:
type: rabbit #指定sleuth发送到rabbitmq,zipkin从rabbitmq进行消费
sleuth:
sampler:
# 采样率值介于 0 到 1 之间,1 则表示全部采集
probability: 1
# 每秒采集的数量,默认是10,通过设置这个可以有效的避免消息过大
rate: 10
rabbitmq:
host: ip
port: 5672
username: admin
password: admin
listener: # 这里配置了重试策略
direct:
retry:
enabled: true
logging:
level:
org.springframework.web.servlet.DispatcherServlet: DEBUG
provider
@SpringBootApplication
@RestController
@Slf4j
@EnableFeignClients
public class ProviderApplication {
public static void main(String[] args) {
SpringApplication.run(ProviderApplication.class, args);
}
@GetMapping("/provider")
public String provider() {
log.info("provider");
return "provider";
}
}
consumer
@SpringBootApplication
@RestController
@EnableFeignClients
@Slf4j
public class ConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(ConsumerApplication.class, args);
}
@Autowired
private ProviderService providerService;
@GetMapping("/consumer")
public String consumer() {
providerService.provider();
log.info("consumer>>>>>>>>>>>");
return "consumer";
}
}
rpc接口
@FeignClient(value = "providerService",url = "http://localhost:8081")
public interface ProviderService {
@GetMapping("/provider")
String provider();
}
启动zipkin服务,这里使用docker启动,把数据持久化到es(指定es的地址),不然的话zipkin服务重启之后数据就没了
注意:zipkin,rabbitmq,es要在同一个docker网络下
docker run \
--network mynet \
--name zipkin-server -d \
--restart=always \
-p 9411:9411 \
-e RABBIT_ADDRESSES=rabbitMQ:5672 \
-e RABBIT_USER=admin \
-e RABBIT_PASSWORD=admin \
-e STORAGE_TYPE=elasticsearch \
-e ES_HOSTS=elasticsearch:9200 \
openzipkin/zipkin:2.21.7
启动成功
访问zipkin的ui界面,http://ip:9411/zipkin/(云服务器要要在安全组吧9411端口放开),这时候没有数据
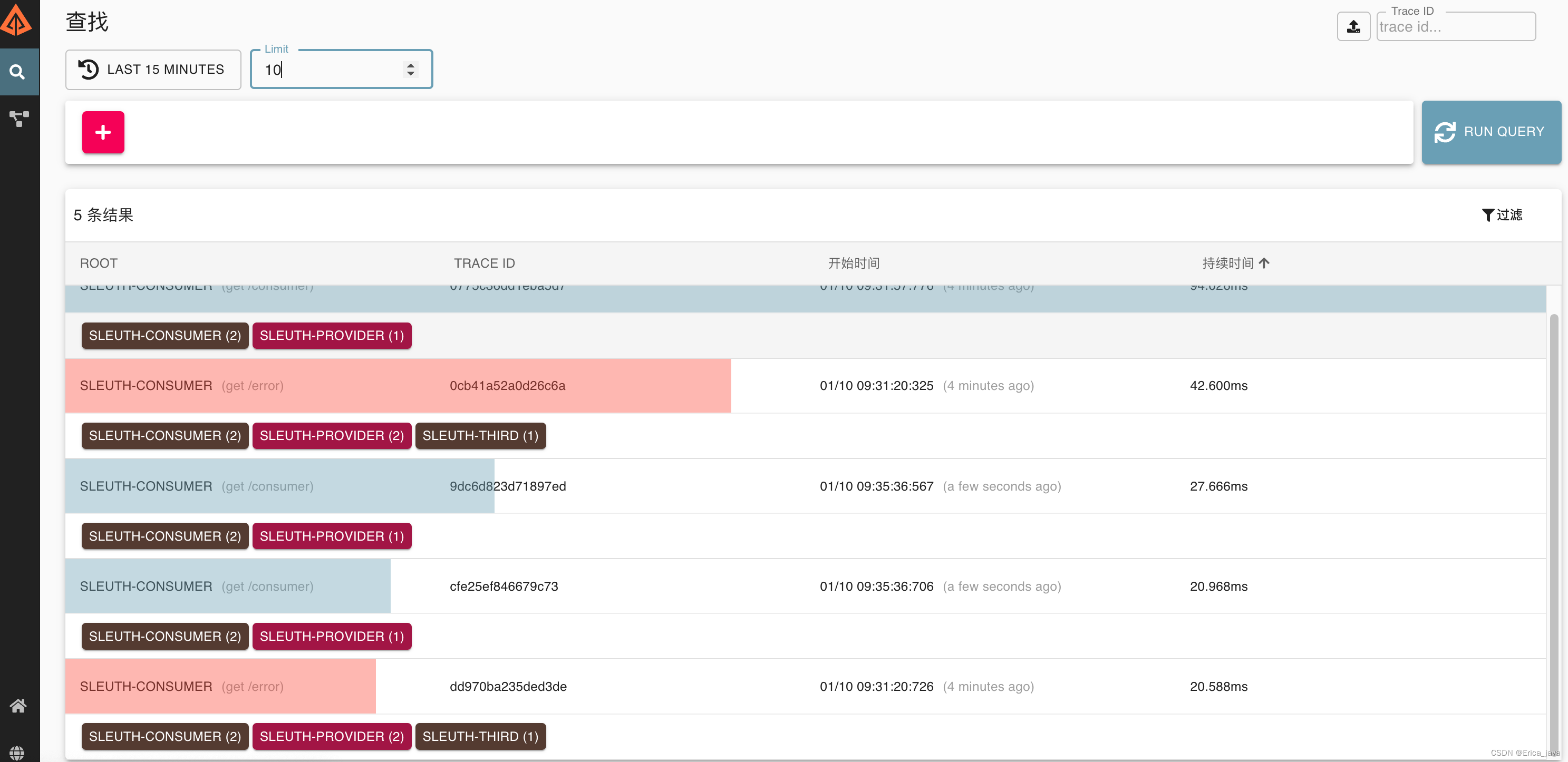
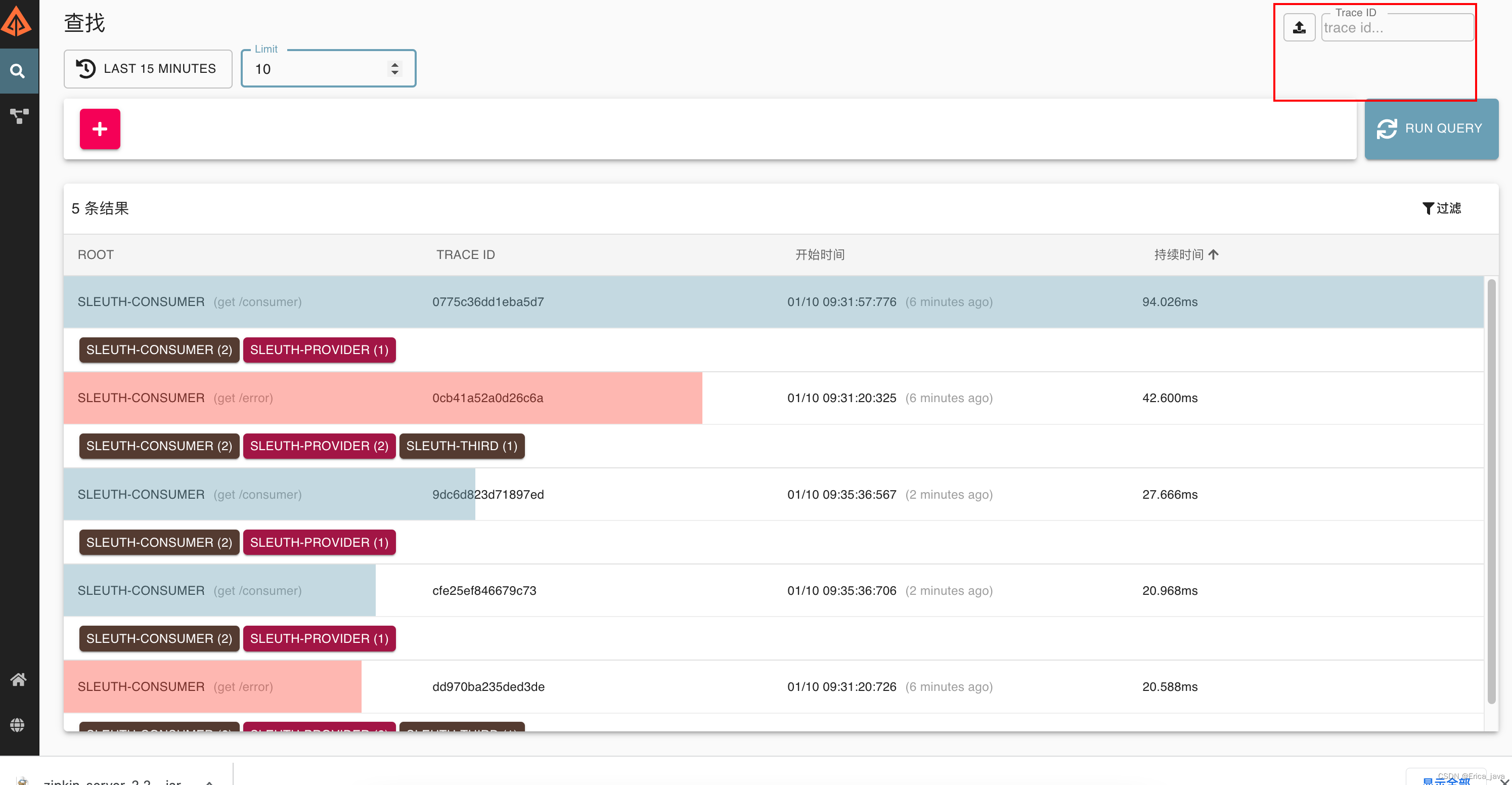
访问几次consumer接口 http://localhost:8082/consumer,在zipkin的ui界面点击run query就会有数据
随便点击一个,会显示服务之间的调用链,
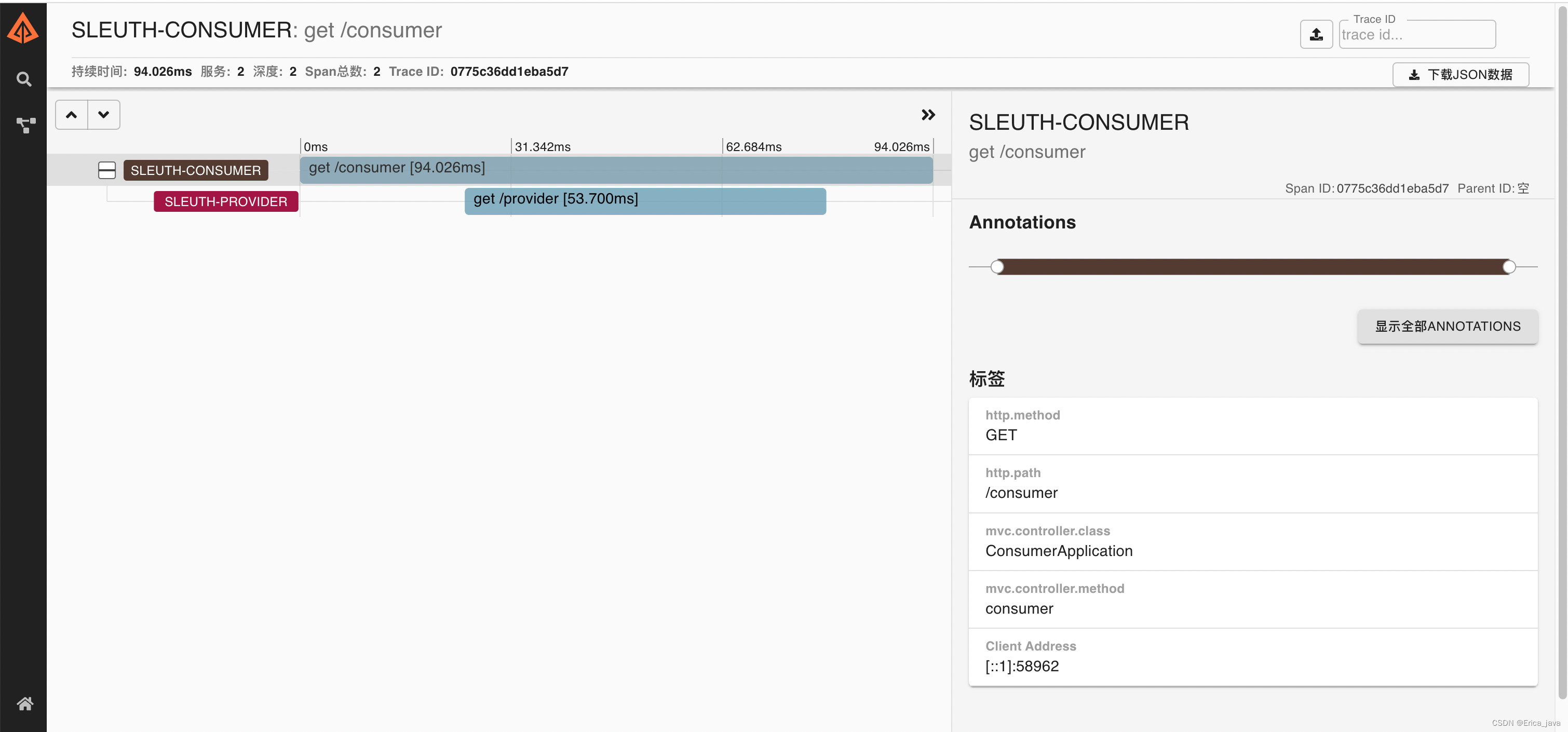
也可以通过右上角traceId搜索
使用logback打印traceId
logback配置文件
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="60 seconds" debug="false">
<!-- 参考SpringBoot默认的logback配置,增加了error日志文件 -->
<!-- org/springframework/boot/logging/logback/base.xml -->
<conversionRule conversionWord="clr" converterClass="org.springframework.boot.logging.logback.ColorConverter" />
<conversionRule conversionWord="wex" converterClass="org.springframework.boot.logging.logback.WhitespaceThrowableProxyConverter" />
<conversionRule conversionWord="wEx" converterClass="org.springframework.boot.logging.logback.ExtendedWhitespaceThrowableProxyConverter" />
<property name="LOG_PATH" value="./logs"/>
<property name="CONSOLE_LOG_PATTERN" value="${CONSOLE_LOG_PATTERN:-%clr(%d{${LOG_DATEFORMAT_PATTERN:-yyyy-MM-dd HH:mm:ss.SSS}}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}"/>
<property name="FILE_LOG_PATTERN" value="${FILE_LOG_PATTERN:-%d{${LOG_DATEFORMAT_PATTERN:-yyyy-MM-dd HH:mm:ss.SSS}} ${LOG_LEVEL_PATTERN:-%5p} ${PID:- } --- [%t] %-40.40logger{39} : %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}"/>
<!-- 控制台日志 -->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
</encoder>
</appender>
<!--获取比info级别高(包括info级别)但除error级别的日志-->
<appender name="file_info" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_PATH}/sys-info.log</file>
<!-- 循环政策:基于时间创建日志文件 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 日志文件名格式 -->
<fileNamePattern>${LOG_PATH}/sys-info.%d{yyyy-MM-dd}.log</fileNamePattern>
<!-- 日志最大的历史 60天 -->
<maxHistory>60</maxHistory>
</rollingPolicy>
<encoder>
<pattern>${FILE_LOG_PATTERN}</pattern>
</encoder>
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>ERROR</level>
<onMatch>DENY</onMatch>
<onMismatch>ACCEPT</onMismatch>
</filter>
</appender>
<appender name="file_error" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_PATH}/sys-error.log</file>
<!-- 循环政策:基于时间创建日志文件 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 日志文件名格式 -->
<fileNamePattern>${LOG_PATH}/sys-error.%d{yyyy-MM-dd}.log</fileNamePattern>
<!-- 日志最大的历史 60天 -->
<maxHistory>60</maxHistory>
</rollingPolicy>
<encoder>
<pattern>${FILE_LOG_PATTERN}</pattern>
</encoder>
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<!-- 过滤的级别 -->
<level>ERROR</level>
<!-- 匹配时的操作:接收(记录) -->
<onMatch>ACCEPT</onMatch>
<!-- 不匹配时的操作:拒绝(不记录) -->
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!-- 异步输出 -->
<appender name="ASYNC-INFO" class="ch.qos.logback.classic.AsyncAppender">
<!-- 不丢失日志.默认的,如果队列的80%已满,则会丢弃TRACT、DEBUG、INFO级别的日志 -->
<discardingThreshold>0</discardingThreshold>
<!-- 更改默认的队列的深度,该值会影响性能.默认值为256 -->
<queueSize>512</queueSize>
<!-- 添加附加的appender,最多只能添加一个 -->
<appender-ref ref="file_info"/>
</appender>
<appender name="ASYNC-ERROR" class="ch.qos.logback.classic.AsyncAppender">
<!-- 不丢失日志.默认的,如果队列的80%已满,则会丢弃TRACT、DEBUG、INFO级别的日志 -->
<discardingThreshold>0</discardingThreshold>
<!-- 更改默认的队列的深度,该值会影响性能.默认值为256 -->
<queueSize>512</queueSize>
<!-- 添加附加的appender,最多只能添加一个 -->
<appender-ref ref="file_error"/>
</appender>
<!-- 日志总开关 -->
<root level="INFO">
<appender-ref ref="CONSOLE" />
<appender-ref ref="ASYNC-INFO" />
<appender-ref ref="ASYNC-ERROR" />
</root>
<!-- 日志过滤 -->
<logger name="org.apache.catalina.startup.DigesterFactory" level="ERROR"/>
<logger name="org.apache.catalina.util.LifecycleBase" level="ERROR"/>
<logger name="org.apache.coyote.http11.Http11NioProtocol" level="WARN"/>
<logger name="org.apache.sshd.common.util.SecurityUtils" level="WARN"/>
<logger name="org.apache.tomcat.util.net.NioSelectorPool" level="WARN"/>
<logger name="org.eclipse.jetty.util.component.AbstractLifeCycle" level="ERROR"/>
<logger name="org.hibernate.validator.internal.util.Version" level="WARN"/>
</configuration>

服务名,traceId,spanId都打印出来了


















 339
339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









