






要搭建高效的工作流,首先需要理解各个节点的功能和作用。只有掌握了每个节点的用途,才能灵活运用ComfyUI进行个性化配置。
开始基础工作流拆解之前,先介绍下SD基础的转化流程
【输入】—(转换)—【潜在空间】—(转换)—【输出】
无论是文生图还是图生图,提示词/图片作为输入基础信息传递给AI,AI并不认识这些,这里需要转化成计算机认识的内容到潜在空间中
所有的运算和生成过程也都是在潜在空间,当完成图片后,需要再从潜在空间次转化出来,转化成我们看得懂的像素图像
从零搭建文生图
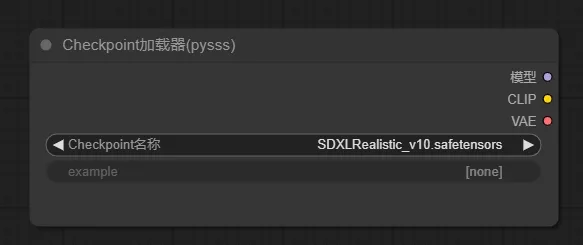
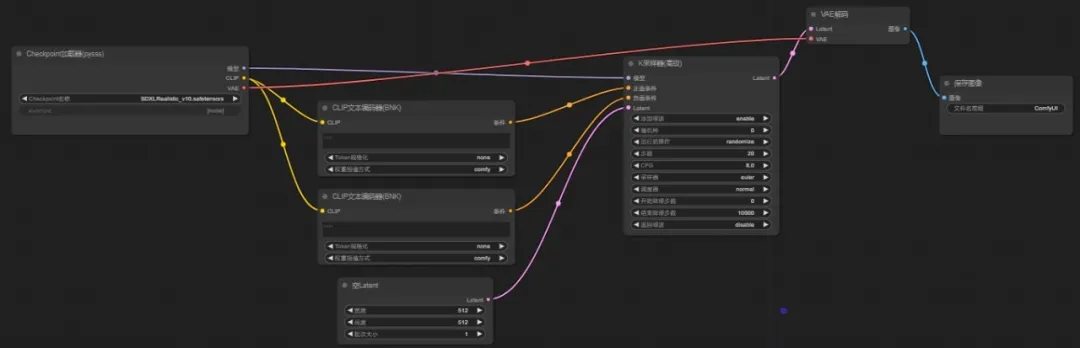
1、加载器
首先添加大模型的加载器,通过加载器这一个节点来延伸出整个工作流的节点
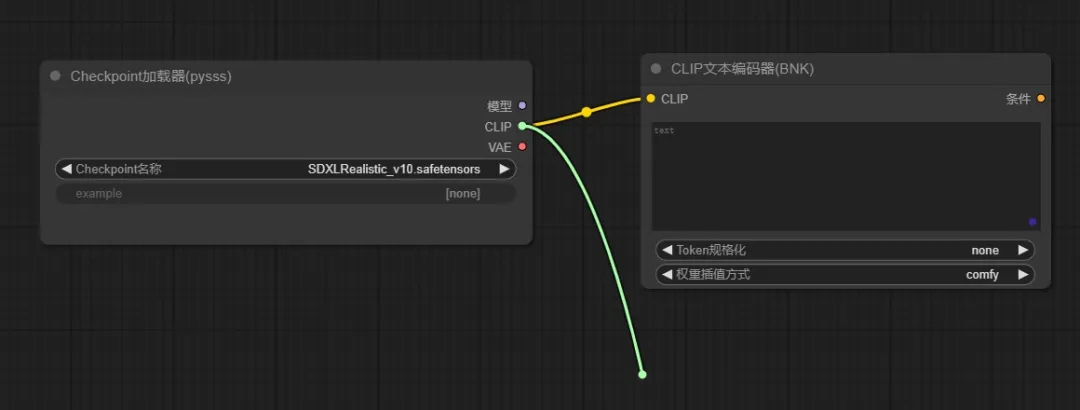
2、正反向提示词节点
可以看到这里有三个延伸点,首先是CLIP文本编码器,将节点延伸就可以看到常用的基本节点,也可以【搜索】插件节点,延伸出的CLIP节点会自动连上(再连接一个负向提示词文本编码器)
这里对应的是文本部分的【输入】—(转换)—【潜在空间】
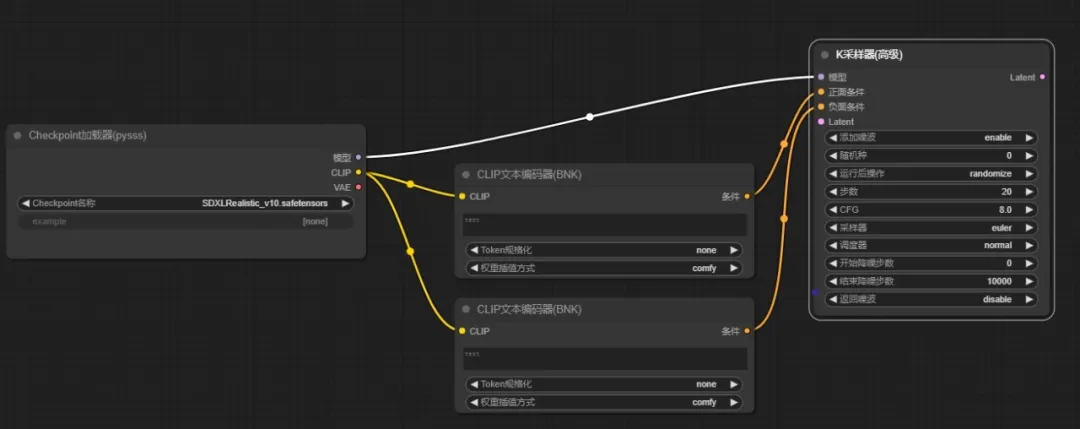
3、模型
同样的,从模型节点拖出一个K采样器,可以看到,K采样器上正负提示词与CLIP文本节点上的颜色是相同的,将相对应的节点相连即可
模型的【输入】—(转换)—【潜在空间】
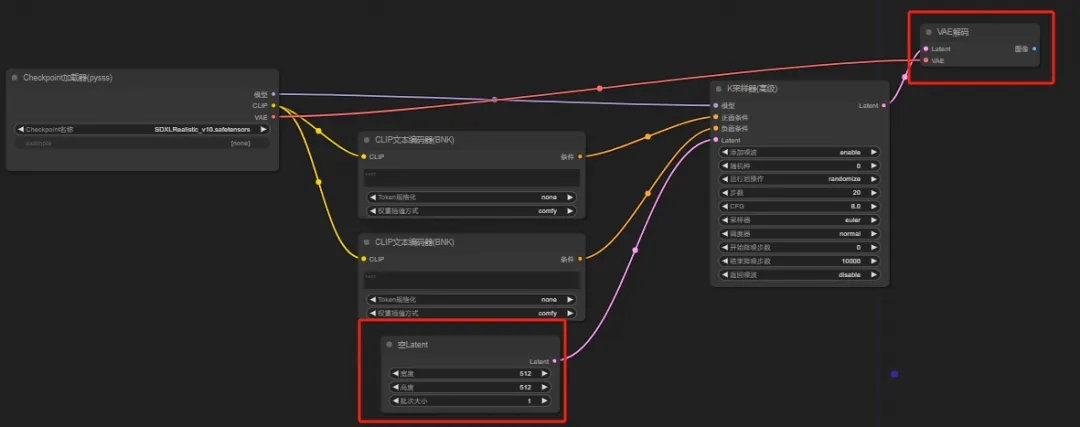
4、Latent
可以看到,这时采样器左边缺少一个Latent节点,延伸出来是个空Latent,这个空Latent就是分辨率的输入
(分辨率的【输入】—(转换)—【潜在空间】)
右边的Laten延伸出来,就是VAE的解码,就是从潜在空间的内容通过VAE的解码转化成像素
(这里不要忘记VAE和大模型的VAE相连,或者单独连接一个VAE加载器,VAE解码没有对应大模型是无法完成的)
【潜在空间】—(转换)—【输出】
5、保存图像
从VAE延伸出保存图像节点,这样文生图的基本工作流就搭建完成了
正因为每个节点所连接的节点不是唯一的,这使得ComfyUI的自由度比WebUI高得多,在理解
【输入】—(转换)—【潜在空间】—(转换)—【输出】
这个基本逻辑下,知道每个节点可以链接什么,对发散自定义工作流就非常有帮助了
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!

零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 9773
9773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









