



 本文介绍如何通过优维监控平台的故障工单功能,追踪复杂告警,实现告警转工单,自动获取上下文信息,协同多角色处理故障,以及工单历史追溯,提升故障处理效率和闭环管理。
本文介绍如何通过优维监控平台的故障工单功能,追踪复杂告警,实现告警转工单,自动获取上下文信息,协同多角色处理故障,以及工单历史追溯,提升故障处理效率和闭环管理。

监控系统的首要任务是利用特定指标来反映系统内部的健康状态,当指标异常时,会触发告警。对于简单告警的处理,基于告警轨迹可清晰记录和观察告警的状态变化过程。
然而,对于一个复杂告警的处理,可能需要多角色多部门协同解决。
本期EasyOps产品使用最佳实践,我们将为您揭晓:
-
1. 如何利用故障工单的高级能力去追踪每一次告警?
-
2. 如何在工单流程中嵌入自动化的方式推动故障的修复?
「 背 景 」
监控系统的首要任务是追踪资源对象的运行状况,利用特定指标来反映系统内部的健康状态。当这些指标出现异常时,系统会触发告警,通知管理员需要关注,并且提供异常指标的上下文信息以支持后续的分析、处理和验证。因此,告警的生命周期对于及时而有效地处理系统异常情况至关重要。
对于简单故障的处理,我们基于事件轨迹可以清晰记录和观察告警的状态变化过程。
然而,对于一个复杂故障的处理可能会涉及如下流程
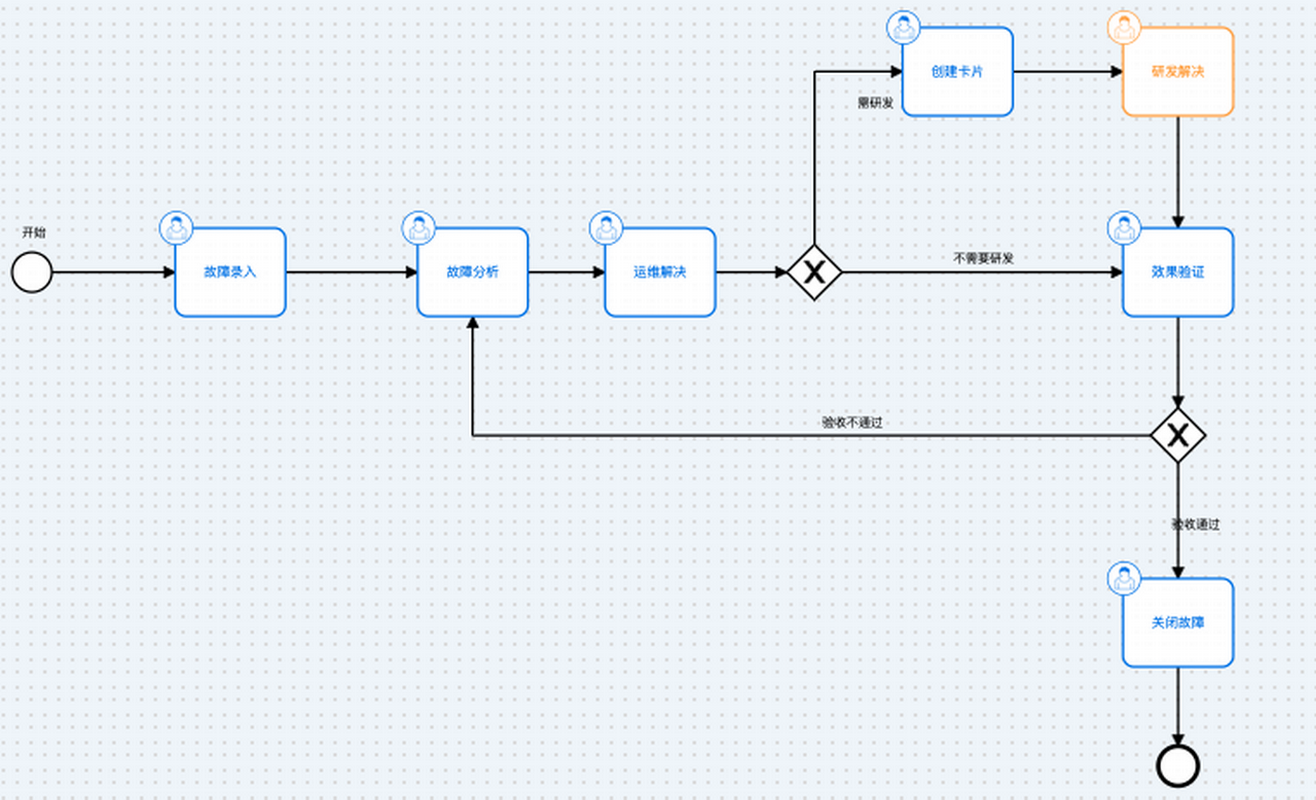
这个流程需要协同多个角色的参与,以解决故障。显然,单纯依赖事件中心的事件轨迹无法满足复杂故障的需要,尤其是在多用户和多部门需要协同合作的情况下。因此,将告警转化为故障工单的方式来追踪和处理将成为明智的选择。
「 配 置 说 明 」
优维监控平台直接支持对接到故障工单模块,当告警产生时,可以直接转故障工单去跟进整个事件的处理和流转。如下图所示:

当点击转故障工单后,会跳转到【发起工单】的步骤,此时根据系统内置的流程和表单,可以动态获取告警的上下文信息并回填到表单中。
当然,您也可以自定义流程和表单,以符合实际的业务环境。
>> 表单回填
当告警发生时,通过转故障工单,可以通过关联脚本的方式获取告警的上下文信息,并回填到表单中。例如:
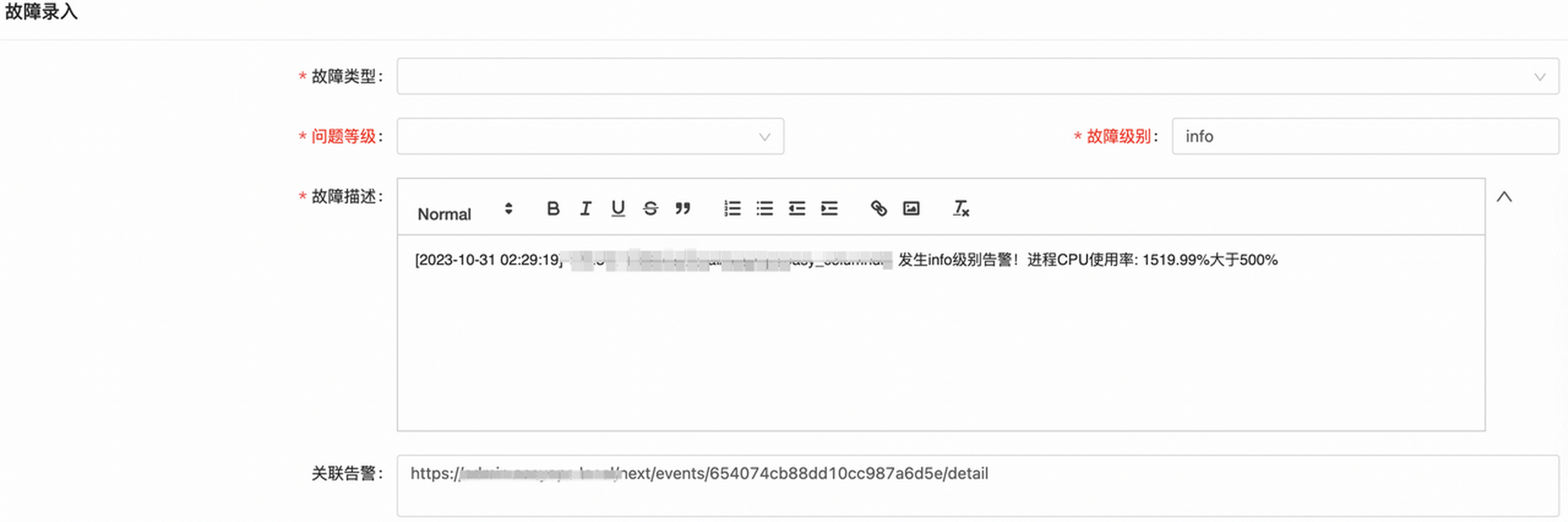
您可以在故障录入这个节点把所有表单项都使用事件上下文去填充,也可以人为去填写一些内容。
提交工单后,工单就根据设定好的流程流转到相关部门或相关人员中以进一步处理。
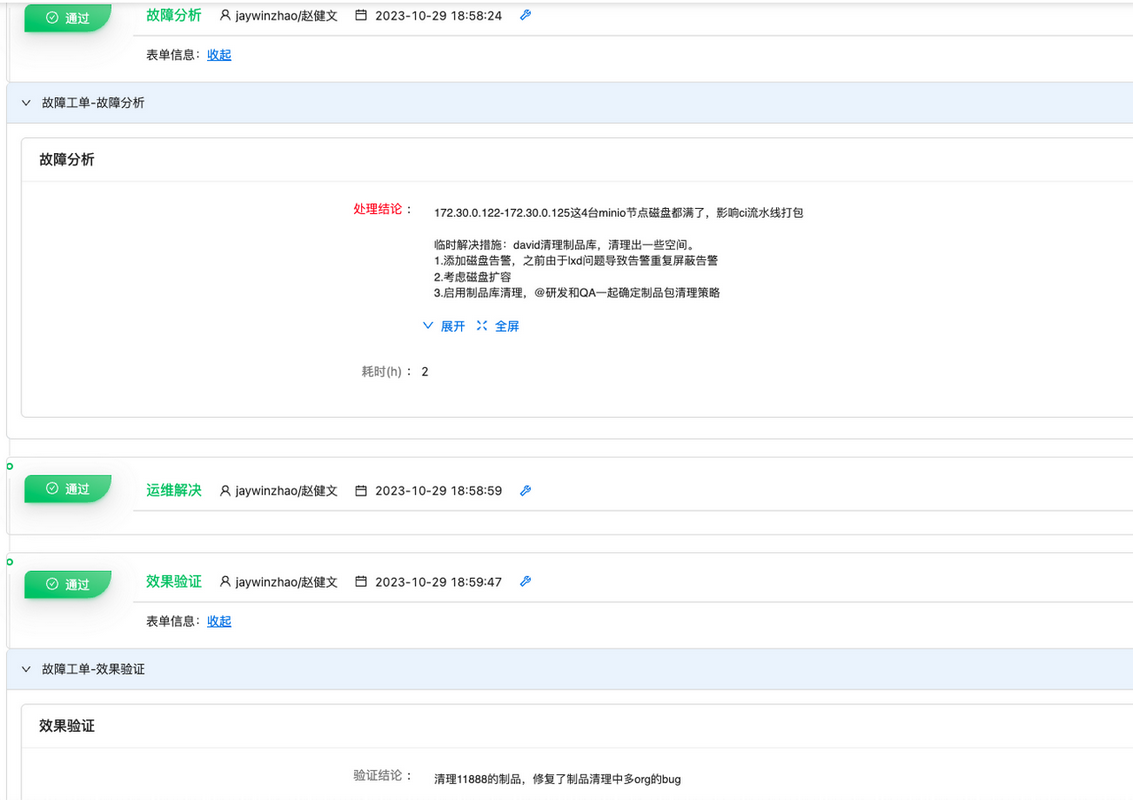
>> 历史追溯
当这个流程结束后,也意味着故障生命周期的结束。此时,您可以通过工单历史非常方面了解在处理故障时每一个步骤的具体过程,这为故障的历史回溯和归档提供了非常便捷的工具。
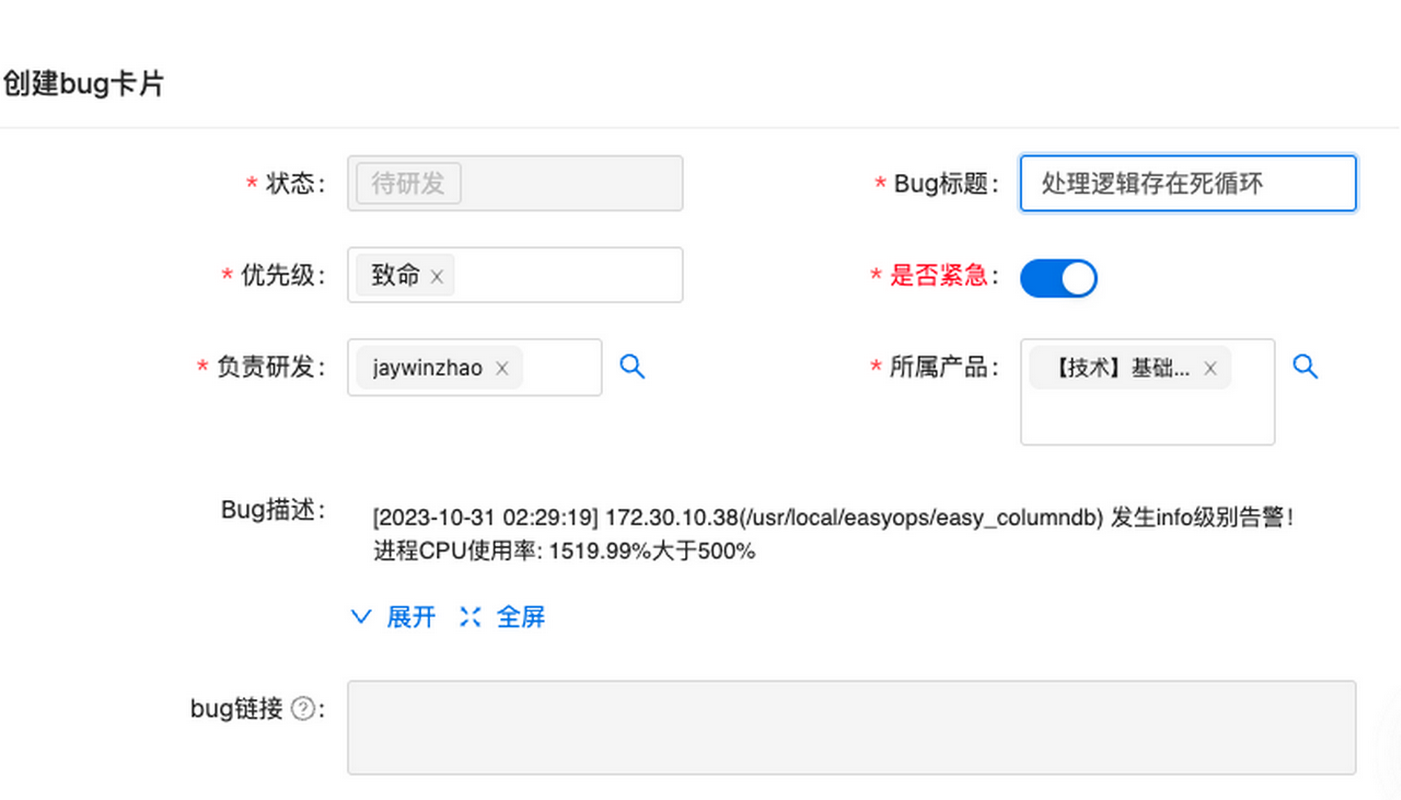
另外,当故障的处理需要多部门协调时,比如需要研发参与以修复bug,可以在表单中填写bug的相关信息,而后触发后置脚本去自动创建bug卡片,以触发后续的研发修复流程。
总的来说,故障转事件中心为您提供了一个强大,灵活和高效的故障跟进和处理过程,以流程的方式去记录和追踪故障的每一个处理步骤,以实现故障的闭环和为后续的故障复盘提供支撑。

















 272
272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









