




【多模态-1】 Transformers简介
大模型在自然语言处理、视觉-语言融合、少样本学习、跨模态任务等方面已取得显著进展。随着计算能力的提升和模型优化技术的发展,未来大模型将更加高效、精确和具备更强的跨领域能力。同时,伦理、安全等问题仍需关注,以确保大模型能够安全、负责任地应用于各种实际场景。
在使用到大语言模型的时候,经常会接触到一个叫做transformer的库,尤其是当你的任务涉及到文本方面的处理的时候。Transformers 提供了可以轻松地下载并且训练先进的预训练模型的 API 和工具。使用预训练模型可以减少计算消耗和碳排放,并且节省从头训练所需要的时间和资源。这些模型支持不同模态中的常见任务,比如:
📝 自然语言处理:文本分类、命名实体识别、问答、语言建模、摘要、翻译、多项选择和文本生成。
🖼️ 机器视觉:图像分类、目标检测和语义分割。
🗣️ 音频:自动语音识别和音频分类。
🐙 多模态:表格问答、光学字符识别、从扫描文档提取信息、视频分类和视觉问答。
安装
我们的演示将会在windows的电脑上运行,安装之前请务必先安装好anaconda和pycharm
如果是初学的小伙伴请先看这里的教程学会这两个软件的安装和使用。
第零步,创建虚拟环境。
Transformers 已在 Python 3.6+、PyTorch 1.1.0+、TensorFlow 2.0+ 以及 Flax 上进行测试。但是为了让我们的教程的持续时间更长,本次我们直接激进的使用python的3.9版本,以及torch的2.0+的版本进行教程内容的开发。
执行下列命令进行虚拟环境的创建和激活。
conda create -n transformers_env python==3.10.15
y
conda activate transformers_env
激活之后在左侧将会看到一个括号,括号里面的内容表示你目前所处的虚拟环境。
第一步,先安装torch。
因为我们的项目的后端需要深度学习框架的支持,所以在transformers库安装之前需要先进行torch的安装。我们直接进行最新的库的安装。
# CUDA 11.8
conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=11.8 -c pytorch -c nvidia
# CUDA 12.1
conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=12.1 -c pytorch -c nvidia
# CPU Only
conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 cpuonly -c pytorch
执行完毕,如果直接引入可能导致出现numpy的问题,这里我们需要重新安装一下numpy。
pip install numpy==1.23.1
然后,我们可以测试一下GPU是否可用。出现下面的内容这样说明我们的库是可以使用的。
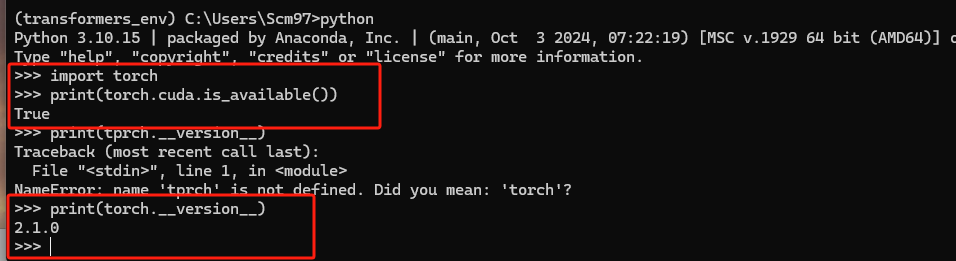
如果需要退出解释器,请执行exit()
第二步,安装其他库。
执行下面的指令完成其他库的安装。
pip install transformers datasets evaluate accelerate
为了后面来看的朋友能够和自己的任务进行匹配,我们这里将库的版本进行固定。
transformers==4.32.0
datasets==3.2.0
evaluate==0.4.3
accelerate==1.2.1
tiktoken==0.8.0
blobfile==3.0.0
sentencepiece==0.2.0
protobuf==5.29.2
然后执行一下简单的测试,这个是一个情感分类的测试。这个任务的目的是给定一段话,来判断这段话是积极的还是消极的,或者说是正面的还是负面的。
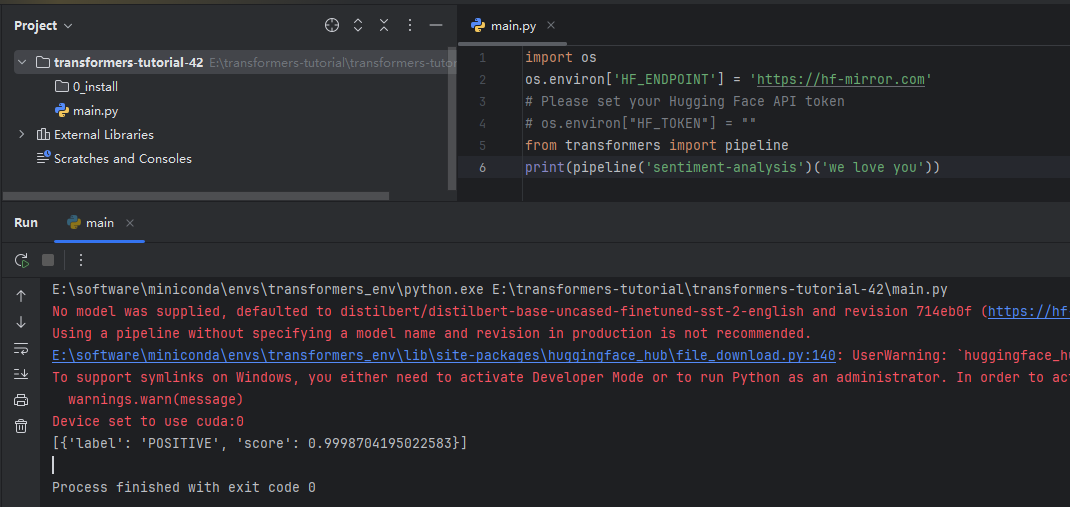
如上面所示,当前输入了这段代码之后,他输出了对应的下面的类别和分数,则表明你的库的安装是没有问题的。
Transformers中的pipeline
pipeline是transformer中一个重要的概念,通过流水线,可以把这些深度学习的任务看作是一个黑盒,他又输入和输出,由于强大的社区支持,你不需要从头开始数据集的处理和模型的训练,只需要指定任务的类型,给定输入的内容,即可得到输出的内容。来看看它支持的任务列表:
| 任务 | 描述 | 模态 | Pipeline |
|---|---|---|---|
| 文本分类 | 为给定的文本序列分配一个标签 | NLP | pipeline(task=“sentiment-analysis”) |
| 文本生成 | 根据给定的提示生成文本 | NLP | pipeline(task=“text-generation”) |
| 命名实体识别 | 为序列里的每个 token 分配一个标签(人, 组织, 地址等等) | NLP | pipeline(task=“ner”) |
| 问答系统 | 通过给定的上下文和问题, 在文本中提取答案 | NLP | pipeline(task=“question-answering”) |
| 掩盖填充 | 预测出正确的在序列中被掩盖的token | NLP | pipeline(task=“fill-mask”) |
| 文本摘要 | 为文本序列或文档生成总结 | NLP | pipeline(task=“summarization”) |
| 文本翻译 | 将文本从一种语言翻译为另一种语言 | NLP | pipeline(task=“translation”) |
| 图像分类 | 为图像分配一个标签 | Computer vision | pipeline(task=“image-classification”) |
| 图像分割 | 为图像中每个独立的像素分配标签(支持语义、全景和实例分割) | Computer vision | pipeline(task=“image-segmentation”) |
| 目标检测 | 预测图像中目标对象的边界框和类别 | Computer vision | pipeline(task=“object-detection”) |
| 音频分类 | 给音频文件分配一个标签 | Audio | pipeline(task=“audio-classification”) |
| 自动语音识别 | 将音频文件中的语音提取为文本 | Audio | pipeline(task=“automatic-speech-recognition”) |
| 视觉问答 | 给定一个图像和一个问题,正确地回答有关图像的问题 | Multimodal | pipeline(task=“vqa”) |
如果想知道支持的任务的完整列表,可以查阅 pipeline API 参考。
这里,我们主要使用一个情感分类的案例来进行举例。我们执行的代码和注释如下,为了方便,我们需要对当前的代码添加国内的加速站点,并且通过设置缓存目录的形式让模型保存在d盘的目录下,反正c盘空间过满。
在这个案例中,我们只需要指定好任务的类型,就能自动加载对应的模型文件来进行推理,并且支持批量的推理,非常方便。
# 导入os模块,用于与操作系统进行交互
import os
# 设置Hugging Face的API端点,使用镜像地址以提高访问速度或应对网络限
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 设置Hugging Face Hub的缓存目录,以便在本地缓存模型和数据集
os.environ['HF_HUB_CACHE'] = '../../hf_caches'
# 从transformers库中导入pipeline工具,用于简化模型的使用流程
from transformers import pipeline
# 初始化情感分析的pipeline,这将加载预训练的情感分析模型
classifier = pipeline("sentiment-analysis")
# 定义一个句子进行情感分析测试
sentence_1 = "We love bilibili!"
single_result = classifier(sentence_1)
# 打印出单个句子的情感分析结果
print(single_result)
# 定义一个包含多个句子的列表,用于批量情感分析测试
sentence_list = ["We love bilibili.", "I hate monster!"]
results = classifier(sentence_list)
# 遍历分析结果,打印出每个句子及其对应的情感标签和得分
for i, result in enumerate(results):
# 打印每个句子的情感分析结果,包括原始句子、情感标签和置信度得分
print(f"sentence_list: {sentence_list[i]}, label: {result['label']}, with score: {round(result['score'], 4)}")
另外,你还可以通过代码来查看transformers库中支持的代码库。

演示完毕基本的任务之后,我们来学习一下transformers库是如何来进行模型的加载的。首先你可以在Models - Hugging Face搜索你想要的模型,但是实际来看,你需要对这些模型有比较多的了解,搜索起来才会方便,找到想要的模型之后复制模型的地址,地址一般包含两个内容,一个是这模型仓库的位置,一个是这个模型的实际名称,找到之后即可加载此模型,transformers会自动从云将这个模型下载到本地,使用的就是from_pretrained函数。AutoClass 是一个能够通过预训练模型的名称或路径自动查找其架构的快捷方式。你只需要为你的任务选择合适的 AutoClass 和它关联的预处理类。
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
os.environ['HF_HUB_CACHE'] = '../../hf_caches'
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
最后一个案例中,我们将会首先通过from_pretrained将模型从云端拉到本地,如下图所示,里面包含了字典文件和对应的模型权重文件,这里是模型是以bin的方式进行存储的。
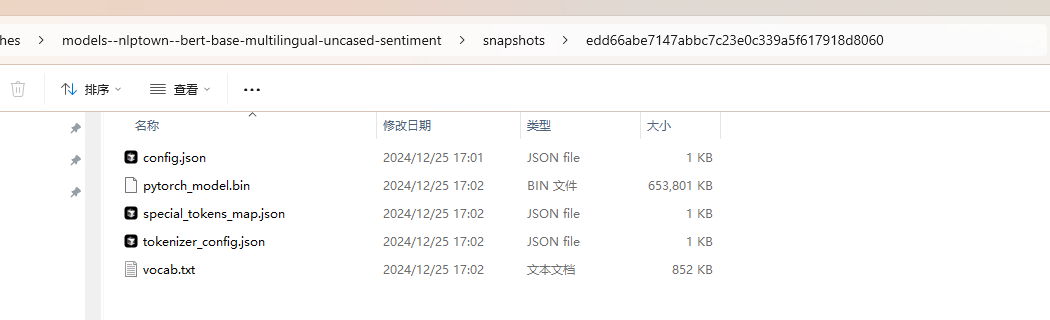
拉到本地之后,我们只需要指定本地的路径,即可完成我们的任务,如下图所示。
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
os.environ['HF_HUB_CACHE'] = '../../hf_caches'
# 可以使用from pretrained进行直接的预训练模型加载,或者是提前从网站将对应的模型下载下来,下载之后指定模型的路径即可
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from transformers import pipeline
# model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
model_name = r"E:\transformers-tutorial\hf_caches\models--nlptown--bert-base-multilingual-uncased-sentiment\snapshots\edd66abe7147abbc7c23e0c339a5f617918d8060"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
# tokenizer = AutoTokenizer.from_pretrained(model_name)
classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
# result = classifier("原神,启动!")
result = classifier("原神,关闭!")
print(result)
下期,我们将一起来说说自然语言处理中的分词技术。


















 1152
1152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











