




 本文详细介绍了PaddleOCR的安装及使用流程,包括环境搭建、模型下载与使用等关键步骤,帮助读者快速上手文本检测与识别任务。
本文详细介绍了PaddleOCR的安装及使用流程,包括环境搭建、模型下载与使用等关键步骤,帮助读者快速上手文本检测与识别任务。
PaddleOCR学习笔记01-PaddleOCR的基本使用
paddleocr目前支持paddle2.0.0,2.0.0引入了动态图,并且api变得更加的简洁,非常nice,推荐大家用用看。
参考文档如下:
PaddleOCR/installation.md at release/2.0 · PaddlePaddle/PaddleOCR (github.com)
PaddleOCR/quickstart.md at release/2.0 · PaddlePaddle/PaddleOCR (github.com)
PaddleOCR/inference.md at release/2.0 · PaddlePaddle/PaddleOCR (github.com)
创建Paddle虚拟环境
执行下列命令创建并激活Python3.7.3的虚拟环境
conda create -n paddleocr python==3.7.3
conda activate paddleocr
在虚拟环境下安装paddle2.0.0,以我的电脑为例,我的显卡型号为RTX2070,安装前我已经提前配置好了显卡的驱动,在命令行中输入nvidia-smi可以正确输出显卡的信息,我电脑的操作系统为Windows。所以这里我安装的是GPU版本的Paddle,这里我是使用conda进行安装,conda可以自动检查依赖,执行的命令如下:
conda install paddlepaddle-gpu==2.0.1 cudatoolkit=10.2 -c paddle
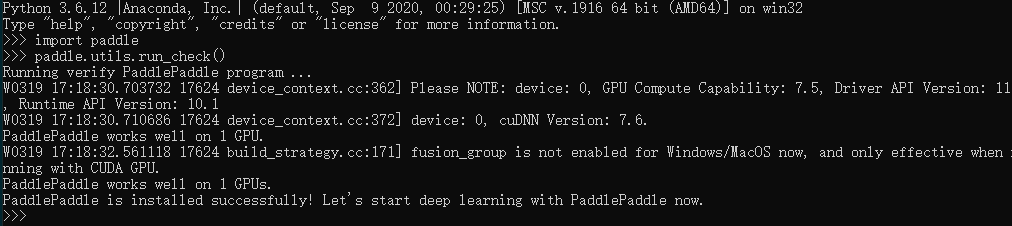
运行下列命令来检查是否安装成功,没有报错表示安装成功。
import paddle
paddle.utils.run_check()
下载PaddleOCR并安装相关依赖
在CMD窗口中执行下列命令把PaddleOCR下载到本地,这里使用码云的地址进行下载,速度比较快,但是可能会和github有一定的延迟。
git clone https://gitee.com/paddlepaddle/PaddleOCR
安装第三方库
cd PaddleOCR
pip install -r requirements.txt
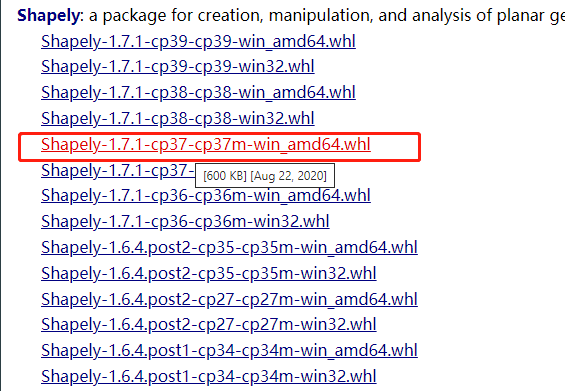
在windows平台下执行代码可能会出现[winRrror 126] 找不到指定模块的问题,需要从https://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely 网站上下载whl文件进行安装,安装之前记得把当前的shapely卸载,比如我这里的python环境是3.7,系统为64位,我应该下载下图红框中的whl文件。
下载好的whl文件放置在PaddleOCR项目目录下,执行下列命令重装shapely
pip uninstall Shapely
pip install Shapely-1.7.1-cp37-cp37m-win_amd64.whl
下载Inference模型
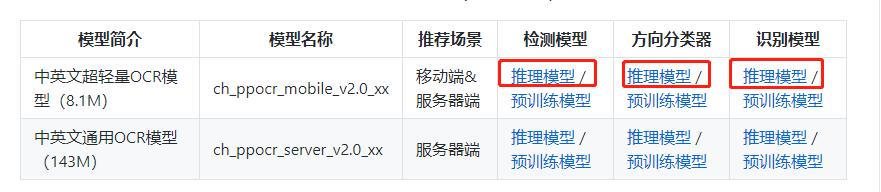
Paddle提供了已经训练好的推理模型,模型下载地址为:
PaddleOCR/quickstart.md at release/2.0 · PaddlePaddle/PaddleOCR (github.com)
我们下载红色部分的模型并进行解压
解压后的文件结构为:
├── ch_ppocr_mobile_v2.0_cls_infer
│ ├── inference.pdiparams
│ ├── inference.pdiparams.info
│ └── inference.pdmodel
├── ch_ppocr_mobile_v2.0_det_infer
│ ├── inference.pdiparams
│ ├── inference.pdiparams.info
│ └── inference.pdmodel
├── ch_ppocr_mobile_v2.0_rec_infer
├── inference.pdiparams
├── inference.pdiparams.info
└── inference.pdmodel
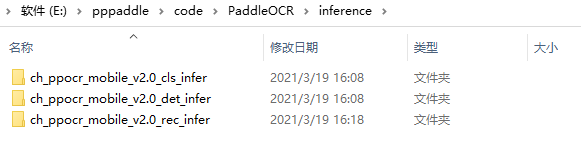
新建inference文件夹把解压之后的三个文件夹放在inference文件夹下,如下所示:
使用模型进行推理
运行过程中可能会出现一个OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.的bug,解决方案是在tools/infer/predict_system.py文件的头部,添加os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'的代码即可运行
【这里我就直接复制原始的话了】以下代码实现了文本检测、方向分类器和识别串联推理,在执行预测时,需要通过参数image_dir指定单张图像或者图像集合的路径、参数det_model_dir指定检测inference模型的路径、参数rec_model_dir指定识别inference模型的路径、参数use_angle_cls指定是否使用方向分类器、参数cls_model_dir指定方向分类器inference模型的路径、参数use_space_char指定是否预测空格字符。可视化识别结果默认保存到./inference_results文件夹里面。
# 预测image_dir指定的单张图像
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True
# 预测image_dir指定的图像集合
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True
# 如果想使用CPU进行预测,需设置use_gpu参数为False
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True --use_gpu=False
-
通用中文OCR模型
请按照上述步骤下载相应的模型,并且更新相关的参数,示例如下:
# 预测image_dir指定的单张图像 python3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_server_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_server_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True -
注意
- 如果希望使用不支持空格的识别模型,在预测的时候需要注意:请将代码更新到最新版本,并添加参数
--use_space_char=False。 - 如果不希望使用方向分类器,在预测的时候需要注意:请将代码更新到最新版本,并添加参数
--use_angle_cls=False。
- 如果希望使用不支持空格的识别模型,在预测的时候需要注意:请将代码更新到最新版本,并添加参数
下图是我的执行结果。
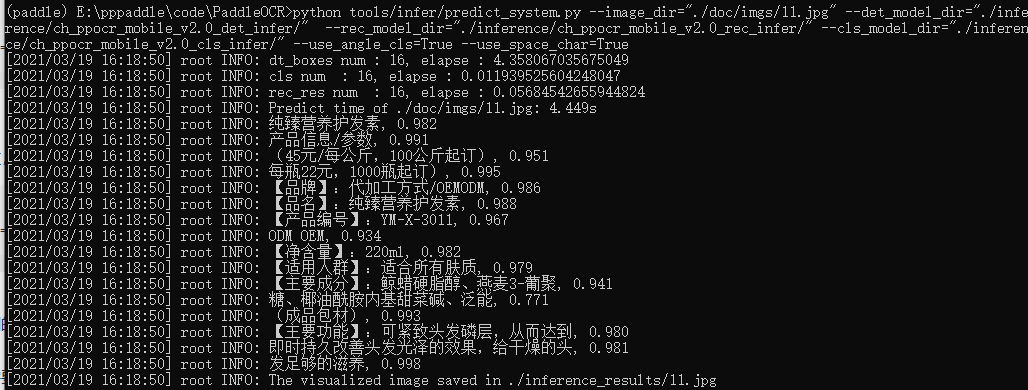

Paddle提供了多个文本检测和文字识别的模型,大家可以自行下载尝试
PaddleOCR/inference.md at release/2.0 · PaddlePaddle/PaddleOCR (github.com)
Thanks
如果你觉得这个文章帮助了你,可以请我喝杯咖啡😊

有问题的小伙伴可以在群里提问


















 1822
1822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











